Интеллектуальный поиск по аудио с Amazon Nova Embeddings: семантическое понимание звука

Artificial Intelligence
Интеллектуальный поиск по аудио с Amazon Nova Embeddings: глубокое погружение в семантическое понимание звука
Если вы хотите улучшить понимание контента и возможности поиска, audio embeddings — мощное решение. В этом материале вы узнаете, как использовать Amazon Nova Multimodal Embeddings, чтобы преобразовать аудиоконтент в данные, по которым можно выполнять поиск и которые учитывают акустические признаки — тон, эмоции, музыкальные характеристики и звуки окружающей среды.
Поиск конкретного фрагмента в таких библиотеках связан с серьезными техническими сложностями. Традиционные методы, такие как ручная расшифровка, тегирование метаданных и преобразование речи в текст, хорошо подходят для поиска произнесенных слов. Однако текстовые подходы фокусируются на лингвистическом содержании, а не на акустических свойствах — тоне, эмоциях, музыкальных характеристиках и фоновых звуках. Именно этот пробел и закрывают audio embeddings. Они представляют аудио в виде плотных числовых векторов в высокоразмерном пространстве, которые кодируют и семантические, и акустические свойства. Такие представления позволяют выполнять семантический поиск по естественно-языковым запросам, находить похожие по звучанию аудиофрагменты и автоматически классифицировать контент по тому, как он звучит, а не только по метаданным. Amazon Nova Multimodal Embeddings, анонсированная 28 октября 2025 года, — это мультимодальная модель эмбеддингов, доступная в Amazon Bedrock [1]. Это единая модель эмбеддингов, которая поддерживает текст, документы, изображения, видео и аудио в одном решении для кроссмодального поиска с высокой точностью.
В этой статье мы разберем, как работают audio embeddings, как реализовать Amazon Nova Multimodal Embeddings и как построить практическую систему поиска по аудиоконтенту. Вы узнаете, как embeddings представляют аудио в виде векторов, познакомитесь с техническими возможностями Amazon Nova и увидите примеры кода для индексации и запроса по аудиобиблиотекам. К концу материала у вас будет понимание, как развернуть production-ready возможности поиска по аудио.
Понимание audio embeddings: основные концепции
Векторные представления аудиоконтента
Представьте audio embeddings как систему координат для звука. Так же как GPS-координаты указывают местоположение на Земле, embeddings сопоставляют аудиоконтенту определенные точки в высокоразмерном пространстве. Amazon Nova Multimodal Embeddings предлагает четыре варианта размерности: 3 072 (по умолчанию), 1 024, 384 или 256 [1]. Каждый embedding — это массив float32. Отдельные измерения кодируют акустические и семантические признаки — ритм, высоту звука, тембр, эмоциональный тон и смысл — все они изучаются нейросетевой архитектурой модели в ходе обучения. Amazon Nova использует Matryoshka Representation Learning (MRL) — технику, которая иерархически структурирует embeddings [1]. Представьте MRL как матрешку. Embedding размером 3 072 содержит всю информацию, но вы можете взять только первые 256 измерений и все равно получить точный результат. Сгенерируйте embeddings один раз, а затем выбирайте размер, который балансирует точность и стоимость хранения. Нет необходимости заново обрабатывать аудио при смене размерности — иерархическая структура позволяет обрезать embedding до нужного размера.
Как измеряется сходство: Когда нужно найти похожее аудио, вычисляют косинусное сходство между двумя embeddings v₁ и v₂ [1]:
similarity = (v₁ · v₂) / (||v₁|| × ||v₂||)
Косинусное сходство измеряет угол между векторами и дает значения от -1 до 1. Значения, близкие к 1, означают более высокое семантическое сходство. Когда embeddings хранятся в векторной базе данных, она использует метрики расстояния (distance = 1 – similarity) для выполнения поиска k-nearest neighbor (k-NN) и возвращает топ-k наиболее похожих embeddings для запроса.
Пример из реального мира: Допустим, у вас есть два аудиофрагмента — «скрипка играет мелодию» и «виолончель играет похожую мелодию», — которые порождают embeddings v₁ и v₂. Если их косинусное сходство равно 0,87, они будут располагаться близко друг к другу в векторном пространстве, что указывает на сильную акустическую и семантическую близость. Другой аудиофрагмент, например «рок-музыка с барабанами», даст v₃ с косинусным сходством 0,23 к v₁ и окажется далеко в пространстве embeddings.
Архитектура обработки аудио и модальности
Понимание end-to-end workflow: Прежде чем углубляться в технические детали, посмотрим, как audio embeddings работают на практике. Есть два основных потока обработки:
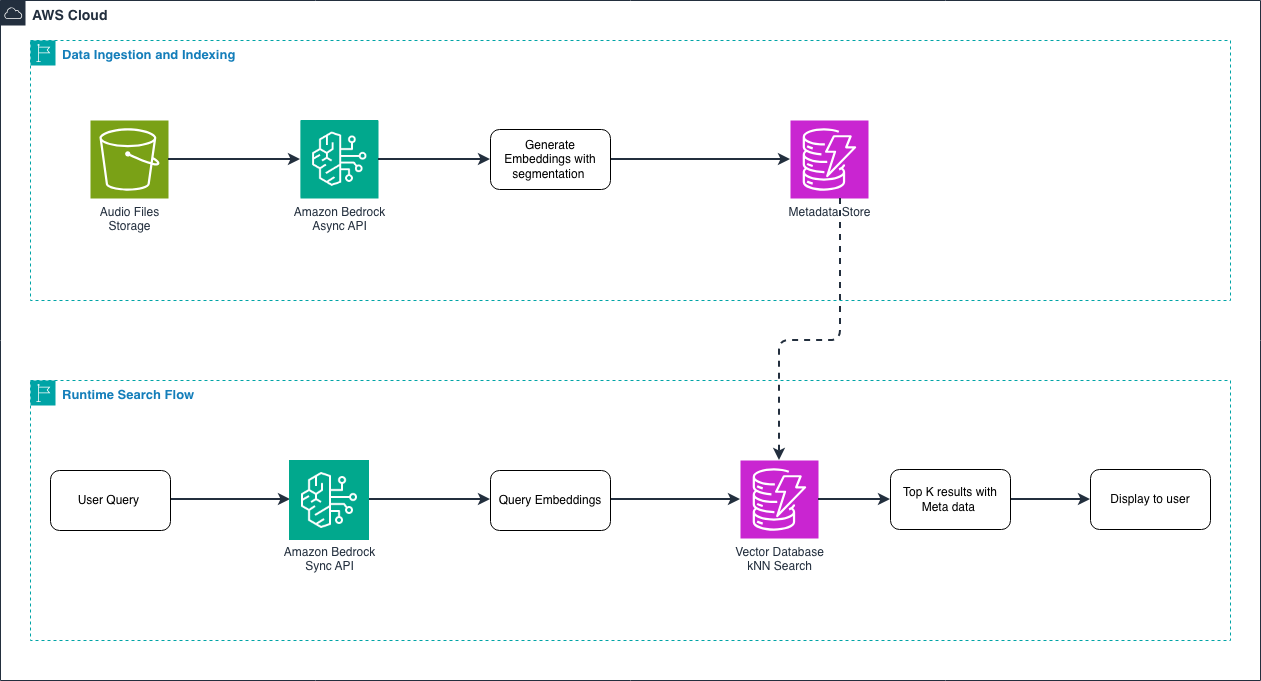
Рисунок 1 — End-to-end workflow для audio embeddings
Поток загрузки данных и индексации: На этапе ingestion вы обрабатываете аудиобиблиотеку пакетно. Вы загружаете аудиофайлы в Amazon S3, а затем используете асинхронный API для генерации embeddings. Для длинных аудиофайлов (свыше 30 секунд) модель автоматически сегментирует их на более мелкие фрагменты с временными метаданными. Эти embeddings вы храните в векторной базе данных вместе с метаданными, такими как имя файла, длительность и жанр. Это выполняется один раз для всей вашей аудиобиблиотеки.
Поток поиска во время работы: Когда пользователь выполняет поиск, вы используете синхронный API для генерации embedding по запросу — будь то текст вроде «upbeat jazz piano» или другой аудиоклип. Поскольку запросы короткие, а пользователи ожидают быстрого ответа, синхронный API обеспечивает низкую задержку. Векторная база данных выполняет поиск k-NN, чтобы найти наиболее похожие audio embeddings, и возвращает результаты вместе с соответствующими метаданными. Весь поиск занимает миллисекунды.
Когда вы передаете только аудиовходы, temporal convolutional networks или архитектуры на основе transformer анализируют акустический сигнал в поисках спектро-временных закономерностей. Вместо работы с сырыми waveforms Amazon Nova использует аудиопредставления, такие как mel-spectrograms или извлеченные аудиопризнаки, что позволяет эффективно обрабатывать аудио с высокой частотой дискретизации [1]. Аудио — это последовательные данные, которым требуется временной контекст. Ваши аудиосегменты (до 30 секунд) проходят через архитектуры с временными receptive fields, которые захватывают акустические паттерны во времени [1]. Такой подход фиксирует ритм, cadence, prosody и дальние акустические зависимости, растянутые на несколько секунд, сохраняя всю полноту аудиоконтента.
Операции API и структуры запросов
Когда использовать синхронную генерацию embeddings: Используйте API invoke_model для поиска во время работы, когда вам нужны embeddings для приложений в реальном времени, где важна задержка [1]. Например, когда пользователь отправляет поисковый запрос, текст запроса короткий и вы хотите обеспечить быстрый пользовательский опыт — в таком случае синхронный API идеально подходит:
import boto3
import json
# Создаем клиент Bedrock Runtime.
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
# Определяем тело запроса для поискового запроса.
request_body = {
"taskType": "SINGLE_EMBEDDING", # Используйте для единичных объектов
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL", # Для запросов используйте GENERIC_RETRIEVAL
"embeddingDimension": 1024, # Выберите размерность
"text": {
"truncationMode": "END", # Как обрабатывать длинные входные данные
"value": "jazz piano music" # Ваш поисковый запрос
}
}
}
# Вызываем модель Nova Embeddings.
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
contentType="application/json"
)
# Извлекаем embedding из ответа.
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"] # массив float32
Понимание параметров запроса:
- taskType: выбирайте
SINGLE_EMBEDDINGдля отдельных объектов илиSEGMENTED_EMBEDDINGдля обработки по фрагментам [1, 2] - embeddingPurpose: оптимизирует embeddings под ваш сценарий —
GENERIC_INDEXдля индексации контента,GENERIC_RETRIEVALдля запросов,DOCUMENT_RETRIEVALдля поиска по документам [1] - embeddingDimension: выбранная размерность выходных данных (3072, 1024, 384, 256) [1]
- truncationMode: как обрабатывать входы, превышающие длину контекста —
ENDобрезает с конца, START — с начала [1]
Что возвращается: API возвращает JSON-объект, содержащий ваш embedding:
{
"embeddings": [
{
"embedding": [0.123, -0.456, 0.789, ...], // массив float32
"embeddingLength": 1024
}
]
}
Когда использовать асинхронную обработку: Amazon Nova Multimodal Embeddings поддерживает два подхода для обработки больших объемов контента: асинхронный API и batch API. Понимание того, когда использовать каждый из них, помогает оптимизировать workflow.
Асинхронный API: Используйте API start_async_invoke, когда нужно обработать большие отдельные аудио- или видеофайлы, превышающие ограничения синхронного API [1]. Это идеально подходит для:
- обработки одного большого файла (многочасовые записи, полноформатные видео)
- файлов, требующих сегментации (более 30 секунд)
- случаев, когда результаты нужны в течение нескольких часов, но не немедленно
response = bedrock_runtime.start_async_invoke(
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {"s3Uri": "s3://amzn-s3-demo-bucket/output/"}
}
)
invocation_arn = response["invocationArn"]
# Проверяем статус задачи
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"] # "InProgress" | "Completed" | "Failed"
Когда задача завершится, результат будет записан в Amazon S3 в формате JSONL (один JSON-объект на строку). Для режима AUDIO_VIDEO_COMBINED вы найдете результат в embedding-audio-video.jsonl [1].
Batch API: Используйте batch inference API, когда нужно обработать тысячи аудиофайлов за одну задачу [3].
Это особенно удобно для:
- пакетной обработки всей аудиобиблиотеки (от тысяч до миллионов файлов)
- оптимизации затрат за счет batch pricing
- индексирования, не чувствительного ко времени, когда можно подождать 24–48 часов
- эффективной обработки большого числа файлов малого и среднего размера
Batch API обеспечивает лучшую экономичность для крупномасштабных операций и автоматически управляет заданиями. Вы отправляете manifest-файл со всеми входными файлами, а сервис параллельно обрабатывает их и записывает результаты в S3.
Как выбрать между async и batch:
- Один большой файл или требуется сегментация в реальном времени? → используйте async API
- Нужно обработать тысячи файлов пакетно? → используйте batch API
- Результаты нужны в течение нескольких часов? → используйте async API
- Можете подождать 24–48 часов ради экономии? → используйте batch API
Подробнее о batch inference см. в документации Amazon Bedrock по batch inference.[3]
Сегментация и временные метаданные
Зачем нужна сегментация: Если ваши аудиофайлы длиннее 30 секунд, их нужно сегментировать [1]. Представьте двухчасовой подкаст, в котором нужно найти конкретный 30-секундный фрагмент, где ведущий обсуждает ИИ — сегментация делает это возможным.
Вы управляете разбиением на фрагменты с помощью параметра segmentationConfig:
"segmentationConfig": {
"durationSeconds": 15 # Генерировать один embedding каждые 15 секунд
}
Эта конфигурация обрабатывает 5-минутный аудиофайл (300 секунд) как 20 сегментов (300 ÷ 15 = 20), создавая 20 embeddings [1]. Каждый сегмент получает временные метаданные, которые отмечают его положение в исходном файле.Понимание результата сегментации: Асинхронный API записывает сегментированные embeddings в JSONL вместе с временными метаданными [1]:
{"startTime": 0.0, "endTime": 15.0, "embedding": [...]}
{"startTime": 15.0, "endTime": 30.0, "embedding": [...]}
{"startTime": 30.0, "endTime": 45.0, "embedding": [...]}
Как разобрать сегментированный результат:
import json
from boto3 import client
s3 = client("s3", region_name="us-east-1")
# Читаем JSONL-файл из S3
response = s3.get_object(Bucket="bucket", Key="output/embedding-audio-video.jsonl")
content = response['Body'].read().decode('utf-8')
segments = []
for line in content.strip().split('\n'):
if line:
segment = json.loads(line)
segments.append({
'start': segment['startTime'],
'end': segment['endTime'],
'embedding': segment['embedding'],
'duration': segment['endTime'] - segment['startTime']
})
print(f"Processed {len(segments)} segments")
print(f"First segment: {segments[0]['start']:.1f}s - {segments[0]['end']:.1f}s")
print(f"Embedding dimension: {len(segments[0]['embedding'])}")
Практический сценарий — temporal search: Вы можете хранить сегментированные embeddings вместе с временными метаданными в векторной базе данных. Когда кто-то ищет «жалоба клиента по поводу биллинга», вы извлекаете конкретные 15-секундные сегменты с временными метками, получая точную навигацию к нужным моментам в многочасовых записях звонков. Прослушивать всю запись не нужно.
Стратегии хранения векторов и индексации
Ссылка на архитектуру: В разделе 2.2 мы показали вам схему end-to-end workflow. Теперь мы глубже рассматриваем компонент Vector Database — слой хранения, где embeddings живут и на этапе ingestion, и на этапе поиска во время работы. Это критически важный компонент, который связывает проиндексированные аудио-embeddings с быстрыми поисковыми запросами.
Понимание требований к хранению: Embeddings — это массивы float32, которым требуется 4 байта на измерение. Вот что вам понадобится:
- 3 072 измерения: 12 288 байт (12 КБ) на один embedding
- 1 024 измерения: 4 096 байт (4 КБ) на один embedding
- 384 измерения: 1 536 байт (1,5 КБ) на один embedding
- 256 измерений: 1 024 байта (1 КБ) на один embedding
Пример расчета: Для 1 миллиона аудиоклипов с embeddings размерности 1 024 потребуется 4 ГБ векторного хранилища (без учета метаданных и структур индекса).
Выбор размерности: Большая размерность дает более детализированные представления, но требует больше памяти и вычислений. Меньшая размерность обеспечивает практичный баланс между качеством поиска и эффективностью использования ресурсов. Начните с 1 024 измерений — это дает отличную точность для большинства сценариев при приемлемой стоимости.
Использование Amazon S3 Vectors: Вы можете хранить и запрашивать embeddings с помощью Amazon S3 Vectors [2]:
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# Создаем векторный индекс
s3vectors.create_index(
vectorBucketName="audio-vectors",
indexName="audio-embeddings",
dimension=1024,
dataType="float32",
distanceMetric="cosine"
)
# Сохраняем embedding вместе с метаданными
s3vectors.put_vectors(
vectorBucketName="audio-vectors",
indexName="audio-embeddings",
vectors=[{
"key": "audio:track_12345",
"data": {"float32": embedding},
"metadata": {
"filename": "track_12345.mp3",
"duration": 180.5,
"genre": "jazz",
"upload_date": "2025-10-28"
}
}]
)
Как метаданные усиливают поиск: Атрибуты метаданных работают вместе с embeddings, обеспечивая более богатые результаты поиска. Когда вы получаете результаты из векторной базы данных, метаданные помогают фильтровать, сортировать и показывать информацию пользователям. Например, поле genre позволяет отфильтровать только джазовые записи, duration помогает находить треки в определенном диапазоне длительности, а filename указывает путь к реальному аудиофайлу для воспроизведения. Поле upload_date помогает выделять более свежий контент или отслеживать актуальность данных. Такое сочетание семантического сходства (из embeddings) и структурированных метаданных создает мощный поисковый опыт.
Запрос к векторам: Поиск k-NN извлекает top-k наиболее похожих векторов [2]:
vectorBucketName="audio-vectors",
indexName="audio-embeddings",
queryVector={"float32": query_embedding},
topK=10, # Возвращаем 10 наиболее похожих результатов
returnDistance=True,
returnMetadata=True
)
for result in response["vectors"]:
print(f"Key: {result['key']}")
print(f"Distance: {result['distance']:.4f}") # Чем меньше, тем похожее
print(f"Metadata: {result['metadata']}")
Использование Amazon OpenSearch Service: OpenSearch предоставляет нативный поиск k-NN с индексами HNSW (Hierarchical Navigable Small World) для сублинейной сложности запроса [1]. Это означает, что поиск остается быстрым даже по мере роста вашей аудиобиблиотеки до миллионов файлов.
Конфигурация индекса:
"mappings": {
"properties": {
"audio_embedding": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw",
"space_type": "cosinesimil",
"engine": "nmslib",
"parameters": {"ef_construction": 512, "m": 16}
}
},
"metadata": {"type": "object"}
}
}
}
Пакетная оптимизация и production-паттерны
Почему пакетная обработка важна: Когда вы обрабатываете несколько аудиофайлов, batch inference повышает throughput за счет снижения накладных расходов на сетевую задержку [1]. Вместо того чтобы делать отдельные API-вызовы для каждого файла, вы можете обрабатывать их эффективнее.
Пример batch-паттерна:
texts = ["jazz music", "rock music", "classical music"]
vectors = []
for text in texts:
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": 1024,
"text": {"truncationMode": "END", "value": text}
}
}),
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
contentType="application/json"
)
embedding = json.loads(response["body"].read())["embeddings"][0]["embedding"]
vectors.append(embedding)
# Пакетная запись в vector store
s3vectors.put_vectors(
vectorBucketName="audio-vectors",
indexName="audio-embeddings",
vectors=[
{"key": f"text:{text}", "data": {"float32": emb}}
for text, emb in zip(texts, vectors)
]
)
Поддержка нескольких языков: Модель поддерживает текстовые входы более чем на 200 языках [1]. Это открывает возможности для мощного cross-modal поиска: ваши пользователи могут искать на испанском контент, проиндексированный на английском, и наоборот. Embeddings сохраняют семантический смысл между языками.
Глубокий разбор Amazon Nova Audio Multimodal Embeddings
Технические характеристики
Архитектура модели: Amazon Nova Multimodal Embeddings построена на foundation model, обученной понимать связи между разными модальностями — текстом, изображениями, документами, видео и аудио — в едином embedding space.
Гибкие размерности embeddings: Доступны четыре варианта выходной размерности: 3 072, 1 024, 384 и 256. Большая размерность дает более детализированные представления, но требует больше памяти и вычислений. Меньшая размерность обеспечивает практичный баланс между качеством поиска и эффективностью ресурсов. Такая гибкость помогает оптимизировать решение под конкретное приложение и требования к стоимости.
Возможности обработки медиа: Для видео- и аудиовходов модель поддерживает сегменты длиной до 30 секунд и автоматически сегментирует более длинные файлы [1]. Эта возможность особенно полезна при работе с крупными медиафайлами — модель разбивает их на управляемые части и создает embeddings для каждого сегмента. Выходные данные включают embeddings для видео- и аудиофайлов с временными метаданными.
Гибкость API: Получить доступ к модели можно через синхронные и асинхронные API. Синхронные API используйте для запросов, где важна задержка. Асинхронные API применяйте для ingestion и индексации данных, где допустимо более длительное время обработки. Асинхронный API поддерживает пакетную сегментацию/разбиение на фрагменты для текстовых, аудио- и видеофайлов. Сегментация — это разбиение длинного файла на более мелкие фрагменты, каждый из которых создает уникальный embedding, что позволяет выполнять более точный и детализированный поиск.
Способы передачи данных: Передать контент для embedding можно, указав S3 URI или встроив его в виде base64-строки. Это дает гибкость при интеграции embeddings в ваш workflow.
Как работает workflow:
- Вы используете Amazon Nova Multimodal Embeddings для генерации embeddings для ваших видео- или аудиоклипов
- Вы сохраняете embeddings в векторной базе данных
- Когда конечный пользователь ищет контент, вы используете Amazon Nova для генерации embedding по его запросу
- Ваше приложение сравнивает, насколько embedding поискового запроса похож на embeddings проиндексированного контента
- Ваше приложение извлекает контент, который лучше всего соответствует запросу, на основе метрики сходства (например, cosine similarity)
- Вы показываете соответствующий контент конечному пользователю
Поддерживаемые входы: Входы для генерации embeddings могут быть в формате текста, изображения, изображения документа, видео или аудио. Под входами понимаются и элементы, с которых вы создаете индекс, и поисковые запросы конечного пользователя. Модель возвращает embeddings, которые вы используете, чтобы извлечь объекты, лучше всего соответствующие запросу, и показать их пользователю.
Поддержка аудиоформатов: Amazon Nova Multimodal Embedding currently supports mp3, wav, and ogg как входные форматы. Эти форматы покрывают большинство распространенных сценариев использования аудио — от музыки до речевых записей.
Ключевые возможности
Поиск audio-to-audio: Находите в библиотеке акустически похожий контент. Например, можно найти все записи с похожими музыкальными характеристиками или стилем речи.
Поиск text-to-audio: Используйте запросы на естественном языке, чтобы находить релевантные аудиосегменты. Ищите «upbeat jazz piano» или «customer expressing frustration» и получайте соответствующие аудиоклипы.
Кроссмодальный поиск: Ищите одновременно по изображениям, аудио, видео и тексту. Такой единый подход означает, что одним запросом можно искать по всей библиотеке контента независимо от формата.
Понимание времени: Модель распознает действия и события внутри аудио во времени. Это позволяет искать конкретные моменты в длинных записях.
Когда выбирать Amazon Nova
Amazon Nova Multimodal Embeddings предназначена для production-приложений, которым нужны масштабируемая производительность, быстрое развертывание и минимальная операционная нагрузка.
Почему стоит выбрать Amazon Nova:
- Быстрый выход на рынок: развертывание за часы или дни, а не за месяцы
- Управляемый сервис: не нужно поддерживать инфраструктуру или обучать модели
- Кроссмодальные возможности: одна модель для всех типов контента с поддержкой enterprise-level deployment
- Постоянные улучшения: получайте обновления модели без миграционных работ
Факторы для принятия решения:
- Требования к масштабу: сколько аудиофайлов и запросов нужно обрабатывать
- Time-to-market: как быстро нужно получить рабочее решение
- Наличие экспертизы: есть ли у вас инженерная команда для поддержки кастомных моделей
- Потребности в интеграции: нужна ли бесшовная интеграция с сервисами AWS
Основные области применения: Amazon Nova Multimodal Embeddings подходит для широкого круга задач, оптимизированных под multimodal RAG, semantic search и clustering:
- Agentic Retrieval-Augmented Generation (RAG): Amazon Nova Multimodal Embeddings можно использовать в RAG-приложениях, где модель выступает в роли embeddings для задачи retrieval. Входом могут быть текст из документов, изображения или изображения документов, где текст сочетается с инфографикой, видео и аудио. Embedding позволяет извлекать наиболее релевантную информацию из базы знаний и передавать ее LLM-системе для более качественных ответов.
- Semantic Search: Вы можете генерировать embeddings из текста, изображений, изображений документов, видео и аудио, чтобы поддерживать поисковые приложения, хранящиеся в vector index. Vector index — это специализированное embedding space, которое сокращает число сравнений, необходимых для получения эффективных результатов. Поскольку модель улавливает нюансы пользовательского запроса внутри embedding, она поддерживает продвинутые поисковые запросы, не зависящие от keyword matching. Пользователи могут искать концепции, а не только точные слова.
- Clustering: Amazon Nova Multimodal Embeddings можно использовать для генерации embeddings из текста, изображений, изображений документов, видео и аудио. Алгоритмы clustering могут группировать объекты, находящиеся близко друг к другу по расстоянию или сходству. Например, если вы занимаетесь управлением медиа и хотите классифицировать медиа-активы по похожим темам, embeddings помогут автоматически сгруппировать похожие объекты без необходимости отдельного метаданных для каждого из них. Модель автоматически понимает сходство контента.
Заключение
В этой статье мы рассмотрели, как Amazon Nova Multimodal Embeddings обеспечивает семантическое понимание аудио, выходящее за пределы традиционных текстовых подходов. Представляя аудио как высокоразмерные векторы, которые улавливают и акустические, и семантические свойства, вы можете строить поисковые системы, понимающие тон, эмоции и контекст, а не только произнесенные слова. Мы разобрали end-to-end workflow для построения системы поиска по аудио, включая: — генерацию embeddings с помощью синхронного и асинхронного API — сегментацию длинных аудиофайлов с временными метаданными — хранение embeddings в векторной базе данных — выполнение k-NN-поиска для извлечения релевантных аудиосегментов. Такой подход позволяет превращать большие аудиобиблиотеки в поисковые интеллектуальные наборы данных для сценариев вроде анализа колл-центров, поиска по медиа и обнаружения контента.
В нашей реализации мы взяли реальный сценарий с embedding записей колл-центра и использовали модель Amazon Nova Multimodal Embeddings, чтобы сделать их доступными для поиска и по настроению, и по содержанию. Вместо ручного тегирования звонков мы использовали текстовые запросы вроде: «Найди звонок, где голос звучит раздраженно» или «Покажи разговор о проблемах с биллингом». Это сработало: система по запросу извлекала нужные аудиоклипы. Иными словами, мы превратили аудиоархивы в опыт поиска и по тону, и по теме без лишних сложностей. Тем, кто хочет углубиться, доступны примеры кода и фрагменты в финальном разделе.
Ссылки
[1] Блог о Amazon Nova Multimodal Embeddings
[2] Nova Embeddings
[3] Поддерживаемые регионы и модели для batch inference
Материал — перевод статьи с английского.