Как построить эффективные функции вознаграждения с AWS Lambda для настройки Amazon Nova

Построение эффективных reward functions помогает адаптировать модели Amazon Nova под конкретные задачи, а AWS Lambda дает для этого масштабируемую и экономичную основу. Серверless-архитектура Lambda позволяет сосредоточиться на критериях качества, пока она берет на себя вычислительную инфраструктуру.
Amazon Nova предлагает несколько подходов к кастомизации, и особенно выделяется Reinforcement fine-tuning (RFT), который обучает модели желаемому поведению через итеративную обратную связь. В отличие от Supervised fine-tuning (SFT), где нужны тысячи размеченных примеров с аннотированными цепочками рассуждений, RFT учится на сигналах оценки финальных ответов. В основе RFT лежит reward function — механизм оценки, который направляет модель к лучшим ответам.
В этом материале показано, как Lambda помогает строить масштабируемые и экономичные reward functions для кастомизации Amazon Nova. Вы узнаете, как выбирать между Reinforcement Learning via Verifiable Rewards (RLVR) для объективно проверяемых задач и Reinforcement Learning via AI Feedback (RLAIF) для субъективной оценки, как проектировать многомерные системы наград, чтобы избежать reward hacking, как оптимизировать Lambda-функции под масштаб обучения и как отслеживать распределение наград с помощью Amazon CloudWatch. Также приведены рабочие примеры кода и рекомендации по развертыванию, чтобы вы могли начать экспериментировать.
Building code-based rewards using AWS Lambda
Для кастомизации foundation models существует несколько путей, и каждый подходит для своих сценариев. SFT особенно хорош, когда у вас есть четкие примеры входов и выходов и нужно обучить конкретным шаблонам ответов — это особенно полезно для задач классификации, распознавания именованных сущностей или адаптации моделей к доменной терминологии и правилам форматирования. SFT хорошо работает там, где желаемое поведение можно показать на примерах, поэтому он идеален для обучения единому стилю, структуре или переноса фактических знаний. Однако некоторые задачи кастомизации требуют другого подхода. Когда приложения должны одновременно балансировать несколько качественных характеристик — например, ответы службы поддержки должны быть точными, эмпатичными, краткими и соответствовать бренду — или когда подготовка тысяч аннотированных траекторий рассуждений оказывается непрактичной, более подходящим вариантом становятся reinforcement-based методы. RFT решает такие сценарии, обучаясь на сигналах оценки, а не на исчерпывающих размеченных демонстрациях правильного процесса рассуждения.
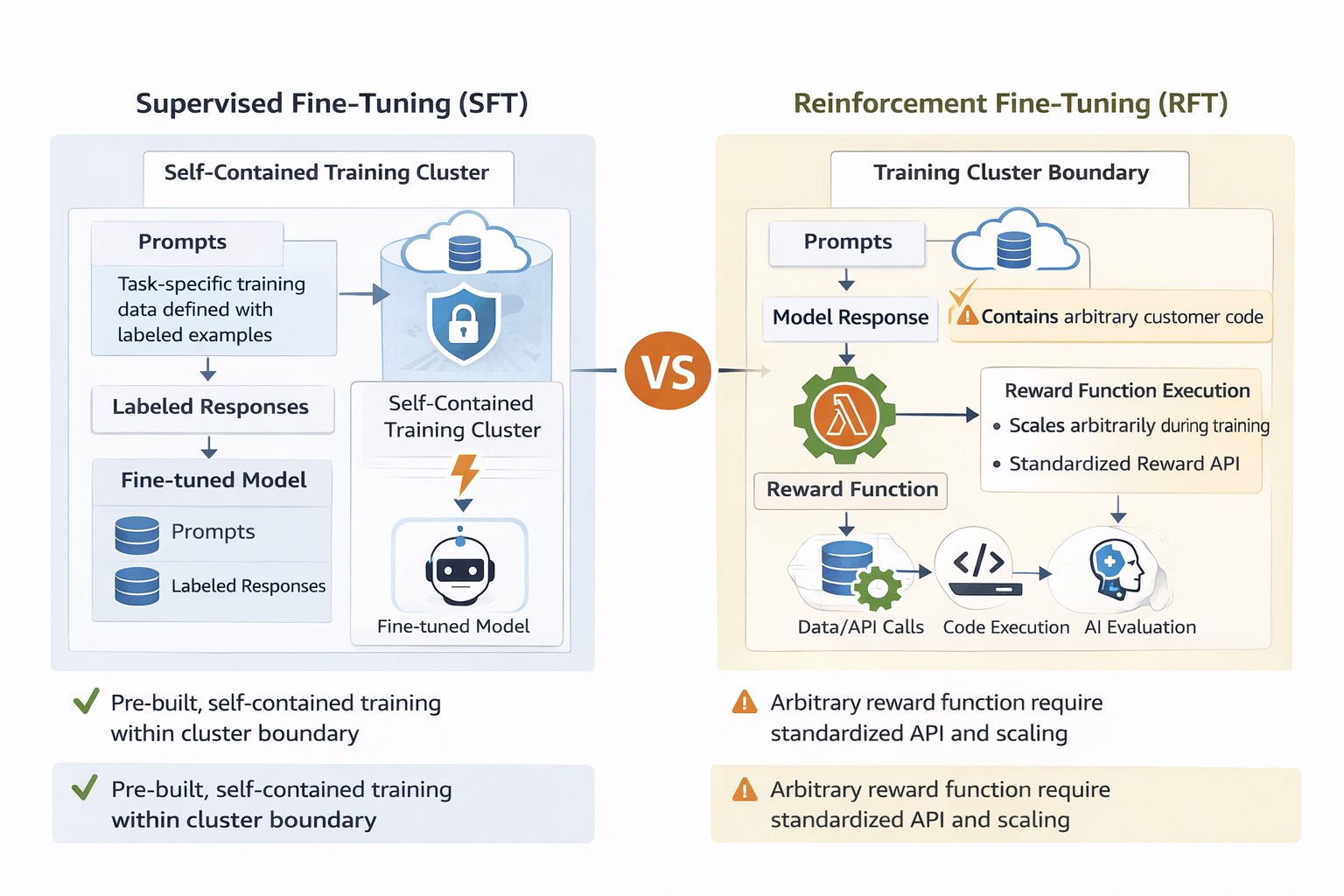
AWS Lambda-based reward functions упрощает это за счет обучения на обратной связи. Вместо того чтобы показывать модели тысячи эффективных примеров, вы задаете промпты и определяете логику оценки, которая выставляет баллы ответам — а затем модель учится улучшаться через итеративную обратную связь. Такой подход требует меньше размеченных примеров, но дает точный контроль над желаемым поведением. Многомерное оценивание помогает учитывать тонкие критерии качества и не позволяет модели эксплуатировать простые обходные пути, а serverless-архитектура Lambda берет на себя переменную нагрузку обучения без управления инфраструктурой. В результате кастомизация Nova становится доступной разработчикам без глубокой экспертизы в машинном обучении, но при этом остается достаточно гибкой для сложных production-сценариев.
How AWS Lambda based rewards work
Архитектура RFT использует AWS Lambda как serverless-оценщик reward, интегрированный с training pipeline Amazon Nova, и формирует feedback loop, который направляет обучение модели. Процесс начинается тогда, когда задача обучения генерирует кандидаты ответов от модели Nova для каждого training prompt. Эти ответы поступают в вашу Lambda-функцию, которая оценивает их по таким параметрам, как корректность, безопасность, форматирование и краткость. Затем функция возвращает скалярные числовые оценки — как best practice обычно в диапазоне от -1 до 1. Более высокие оценки помогают модели закреплять поведения, которые их вызвали, а более низкие — отдаляют ее от паттернов, приводивших к слабым ответам. Этот цикл повторяется тысячи раз на протяжении обучения, постепенно формируя модель так, чтобы она стабильно получала более высокие награды.
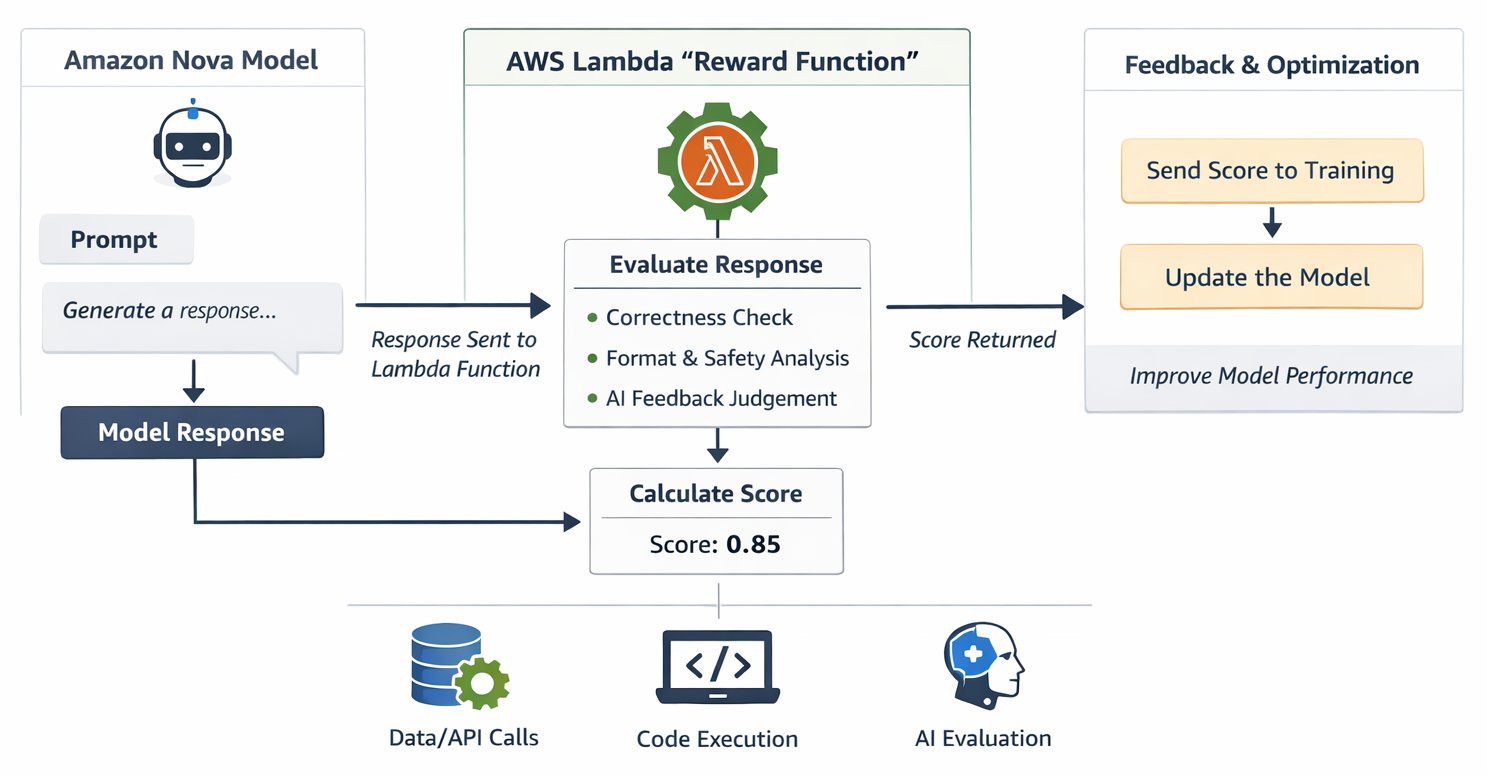
Архитектура объединяет несколько сервисов AWS в едином решении для кастомизации. Lambda выполняет логику оценки наград с автоматическим масштабированием, которое справляется с переменной нагрузкой обучения без необходимости поднимать и обслуживать инфраструктуру. Amazon Bedrock предоставляет полностью управляемый опыт RFT с интегрированной поддержкой Lambda, а также AI judge models для реализаций RLAIF через простой API (Application Programming Interface). Для команд, которым нужен более тонкий контроль обучения, Amazon SageMaker AI предлагает варианты через Amazon SageMaker AI Training Jobs и Amazon SageMaker AI HyperPod, и оба поддерживают те же reward functions на базе Lambda. Amazon CloudWatch отслеживает производительность Lambda в реальном времени, ведет детальные журналы для отладки распределения наград и хода обучения, а также запускает оповещения при возникновении проблем. В основе всего лежит Amazon Nova — модели с recipes кастомизации, оптимизированными под широкий спектр сценариев использования и хорошо реагирующими на сигналы обратной связи от ваших reward functions.
Такой serverless-подход делает кастомизацию Nova экономичной. Lambda автоматически масштабируется от обработки 10 одновременных оценок в секунду на этапе первичных экспериментов до 400+ оценок во время production training без настройки инфраструктуры и планирования емкости. Одна Lambda-функция может одновременно проверять несколько критериев качества, обеспечивая тонкую многомерную обратную связь, которая не дает моделям эксплуатировать упрощенные схемы оценки. Архитектура поддерживает как объективную проверку через RLVR — запуск кода на тестовых случаях или валидацию структурированных выходов, — так и субъективную оценку через RLAIF, где AI-модели оценивают тон, полезность и другие качества. Вы платите только за фактическое время вычислений во время оценки с поминутной или миллисекундной биллинг-гранулярностью, что делает эксперименты доступными, а production-затраты — пропорциональными интенсивности обучения. Особенно полезно для итеративной разработки то, что Lambda-функции можно сохранять как повторно используемые assets типа “Evaluator” в Amazon SageMaker AI Studio, сохраняя единообразие измерения качества по мере доработки стратегии кастомизации в нескольких training runs.
Choosing the right rewards mechanism
Основа успешного RFT — правильный выбор механизма обратной связи. Два взаимодополняющих подхода подходят для разных задач: RLVR и RLAIF — это две техники, которые используют для дообучения large language models (LLMs) после первоначального обучения. Их главное различие — в том, как они дают обратную связь модели.
RLVR (Reinforcement Learning via Verifiable Rewards)
RLVR использует детерминированный код для проверки объективной корректности. RLVR предназначен для областей, где «правильный» ответ можно математически или логически проверить, например при решении математической задачи. RLVR использует детерминированные функции для оценки результатов вместо обученной reward model. RLVR плохо подходит для задач вроде creative writing или brand voice, где не существует абсолютной истины.
- Лучше всего подходит для: генерации кода, математического рассуждения, задач со структурированным выводом
- Пример: запуск сгенерированного кода на тестовых случаях, проверка API-ответов, сверка точности вычислений
- Преимущество: надежное, аудируемое и детерминированное оценивание
Функции RLVR программно проверяют корректность относительно ground truth. В этом примере рассматривается sentiment analysis.
from typing import List
import json
import random
from dataclasses import asdict, dataclass
import re
from typing import Optional
def extract_answer_nova(solution_str: str) -> Optional[str]:
"""Извлечь полярность сентимента из ответа в формате Nova для chABSA."""
# Сначала пытаемся извлечь из блока решения
solution_match = re.search(r'<\|begin_of_solution\|>(.*?)<\|end_of_solution\|>', solution_str, re.DOTALL)
if solution_match:
solution_content = solution_match.group(1)
# Ищем boxed-формат внутри блока решения
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_content)
if boxed_matches:
return boxed_matches[-1].strip()
# Запасной вариант: ищем boxed-формат в любом месте
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
return boxed_matches[-1].strip()
# Последняя попытка: ищем ключевые слова сентимента
solution_lower = solution_str.lower()
for sentiment in ['positive', 'negative', 'neutral']:
if sentiment in solution_lower:
return sentiment
return None
def normalize_answer(answer: str) -> str:
"""Нормализовать ответ для сравнения."""
return answer.strip().lower()
def compute_score(
solution_str: str,
ground_truth: str,
format_score: float = 0.0,
score: float = 1.0,
data_source: str = 'chabsa',
extra_info: Optional[dict] = None
) -> float:
"""Функция оценки chABSA с сигнатурой, совместимой с VeRL."""
answer = extract_answer_nova(solution_str)
if answer is None:
return 0.0
# Разбираем JSON ground_truth, чтобы получить ответ
gt_answer = ground_truth.get("answer", ground_truth)
clean_answer = normalize_answer(answer)
clean_ground_truth = normalize_answer(gt_answer)
return score if clean_answer == clean_ground_truth else format_score
@dataclass
class RewardOutput:
"""Reward service."""
id: str
aggregate_reward_score: float
def lambda_handler(event, context):
scores: List[RewardOutput] = []
samples = event
for sample in samples:
# Извлекаем ключ ground truth. В текущем датасете это answer
print("Sample: ", json.dumps(sample, indent=2))
ground_truth = sample["reference_answer"]
idx = "no id"
# print(sample)
if not "id" in sample:
print(f"ID is None/empty for sample: {sample}")
else:
idx = sample["id"]
ro = RewardOutput(id=idx, aggregate_reward_score=0.0)
if not "messages" in sample:
print(f"Messages is None/empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
# Извлекаем ответ из словаря ground truth
if ground_truth is None:
print(f"No answer found in ground truth for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
# Берем completion из последнего сообщения (assistant message)
last_message = sample["messages"][-1]
completion_text = last_message["content"]
if last_message["role"] not in ["assistant", "nova_assistant"]:
print(f"Last message is not from assistant for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
if not "content" in last_message:
print(f"Completion text is empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
continue
random_score = compute_score(solution_str=completion_text, ground_truth=ground_truth)
ro = RewardOutput(id=idx, aggregate_reward_score=random_score)
print(f"Response for id: {idx} is {ro}")
scores.append(ro)
return [asdict(score) for score in scores]
Ваша функция RLVR должна включать три критически важных элемента проектирования, чтобы обучение было эффективным. Во-первых, создайте плавный reward landscape, начисляя частичные баллы — например, выдавая points за правильную структуру ответа даже тогда, когда финальный ответ неверен. Это предотвращает резкие бинарные cliffs, мешающие обучению. Во-вторых, реализуйте хорошую логику извлечения ответа с несколькими стратегиями парсинга, которые корректно обрабатывают разные форматы ответов. В-третьих, проверяйте входные данные на каждом шаге, используя defensive coding, чтобы не допустить падений из-за некорректных входов.
RLAIF (Reinforcement Learning via AI Feedback)
RLAIF использует AI-модели как судей для субъективной оценки. RLAIF достигает производительности, сопоставимой с RLHF (Reinforcement Learning via Human Feedback), но при этом работает заметно быстрее и стоит дешевле. Ниже приведен пример кода Lambda-функции RLVR для sentiment classification.
- Лучше всего подходит для: creative writing, summarization, согласования с brand voice, полезности
- Пример: оценка тона ответа, анализ качества контента, определение соответствия намерению пользователя
- Преимущество: масштабируемое человечески-подобное суждение без затрат на ручную разметку
RLAIF-функции передают оценивание способным AI-моделям, как показано в примере кода ниже.
import json
import re
import time
import boto3
from typing import List, Dict, Any, Optional
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1')
JUDGE_MODEL_ID = "<jude_model_id>" # Замените на ID judge model, которая вам нужна
SYSTEM_PROMPT = "Вы должны выводить ТОЛЬКО число от 0.0 до 1.0. Никаких объяснений, никакого текста, только число."
JUDGE_PROMPT_TEMPLATE = """Сравните следующие два ответа и оцените, насколько они похожи по шкале от 0.0 до 1.0, где:
- 1.0 означает, что ответы семантически эквивалентны (одно и то же значение, даже если формулировка разная)
- 0.5 означает, что ответы частично похожи
- 0.0 означает, что ответы полностью различны или противоречивы
Ответ A: {response_a}
Ответ B: {response_b}
Выведите ТОЛЬКО число от 0.0 до 1.0. Никаких объяснений."""
def extract_solution_nova(solution_str: str, method: str = "strict") -> Optional[str]:
"""Извлечь решение из ответа в формате Nova."""
assert method in ["strict", "flexible"]
if method == "strict":
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
final_answer = boxed_matches[-1].replace(",", "").replace("$", "")
return final_answer
return None
elif method == "flexible":
boxed_matches = re.findall(r'\\boxed\{([^}]+)\}', solution_str)
if boxed_matches:
numbers = re.findall(r"(\\-?[0-9\\.\\,]+)", boxed_matches[-1])
if numbers:
return numbers[-1].replace(",", "").replace("$", "")
answer = re.findall(r"(\\-?[0-9\\.\\,]+)", solution_str)
if len(answer) == 0:
return None
else:
invalid_str = ["", "."]
for final_answer in reversed(answer):
if final_answer not in invalid_str:
break
return final_answer
def lambda_graded(id: str, response_a: str, response_b: str, max_retries: int = 50) -> float:
"""Вызвать Bedrock для сравнения ответов и вернуть score similarity."""
prompt = JUDGE_PROMPT_TEMPLATE.format(response_a=response_a, response_b=response_b)
for attempt in range(max_retries):
try:
response = bedrock_runtime.converse(
modelId=JUDGE_MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
system=[{"text": SYSTEM_PROMPT}],
inferenceConfig={"temperature": 0.0, "maxTokens": 10}
)
output = response['output']['message']['content'][0]['text'].strip()
score = float(output)
return max(0.0, min(1.0, score))
except Exception as e:
if "ThrottlingException" in str(e) and attempt < max_retries - 1:
time.sleep(2 ** attempt)
else:
return 0.0
return 0.0
def compute_score(id: str, solution_str: str, ground_truth: str) -> float:
"""Вычислить score для формата train.jsonl."""
answer = extract_solution_nova(solution_str=solution_str, method="flexible")
if answer is None:
return 0.0
clean_answer = str(answer)
clean_ground_truth = str(ground_truth)
score = lambda_graded(id, response_a=clean_answer, response_b=clean_ground_truth)
return score
def lambda_grader(samples: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""
Обработать samples из формата train.jsonl и вернуть scores.
Args:
samples: список словарей с messages и метаданными
Returns:
Список словарей с reward scores
"""
results = []
for sample in samples:
sample_id = sample.get("id", "unknown")
# Извлекаем reference answer из metadata или верхнего уровня
metadata = sample.get("metadata", {})
reference_answer = metadata.get("reference_answer", sample.get("reference_answer", {}))
if isinstance(reference_answer, dict):
ground_truth = reference_answer.get("answer", "")
else:
ground_truth = str(reference_answer)
# Получаем ответ ассистента из messages
messages = sample.get("messages", [])
assistant_response = ""
for message in reversed(messages):
if message.get("role") in ["assistant", "nova_assistant"]:
assistant_response = message.get("content", "")
break
if not assistant_response or not ground_truth:
results.append({
"id": sample_id,
"aggregate_reward_score": 0.0
})
continue
# Вычисляем score
score = compute_score(
id=sample_id,
solution_str=assistant_response,
ground_truth=ground_truth
)
results.append({
"id": sample_id,
"aggregate_reward_score": score,
"metrics_list": [
{
"name": "semantic_similarity",
"value": score,
"type": "Reward"
}
]
})
return results
def lambda_handler(event, context):
return lambda_grader(event)
При реализации RLAIF-функции учитывайте инициализацию клиента через глобальные переменные, чтобы снизить общую задержку при вызовах. Обрабатывайте throttling exceptions аккуратно, чтобы не прерывать обучение. Используйте temperature 0.0 для детерминированных оценок judge, это повышает стабильность модели. И задавайте ясную rubric, чтобы judge выдавал калиброванные оценки.
Considerations for writing good reward functions
Чтобы писать хорошие reward functions для RFT, начинайте с простого, создавайте плавный reward landscape, а не binary cliffs, следите, чтобы награды соответствовали реальной цели и не допускали hacking, используйте dense/shaped rewards для сложных задач, давайте четкие сигналы и делайте их verifiable и consistent.
- Определите цель явно: точно знайте, как выглядит успех для вашей модели.
- Плавный reward landscape: вместо простого pass/fail (0 или 1) используйте smooth, dense
reward signals, которые дают частичную награду за то, что ответ движется в правильном направлении. Такая granular feedback помогает модели учиться на постепенных улучшениях, а не ждать идеального ответа. Для сложных многошаговых задач давайте награды за промежуточный прогресс (shaping), а не только за итоговый результат (sparse).
- Делайте награды многомерными: одна scalar reward слишком легко поддается взлому.
Награда должна оценивать качество модели по нескольким измерениям: например, корректность, соответствие входу, безопасность/политике, форматирование и краткость и так далее.
- Предотвращайте reward hacking: не позволяйте модели получать высокий балл за счет обходных путей
(например, случайных угадываний или повторяющихся действий); сделайте задачу устойчивой к угадыванию.
- Используйте verifiable rubrics: для объективных задач вроде генерации кода или математики используйте автоматические
grader-ы, которые выполняют код или разбирают специальные теги ответа (например, <answer>), чтобы проверять корректность без человека в loop.
- Используйте LLM Judges для субъективных задач: когда программный код не может оценить
ответ (например, summary), используйте отдельную, достаточно мощную модель в роли “LLM Judge”. Сначала нужно оценить и сам этот judge, чтобы убедиться, что его оценки стабильны и согласованы с human preferences.
Optimizing your reward function execution within the training loop
Когда reward function начинает работать корректно, оптимизация помогает ускорить обучение и контролировать затраты. В этом разделе рассматриваются техники, которые стоит учитывать для ваших workloads. Эффекты оптимизации складываются: хорошо настроенная Lambda-функция с подходящим batch sizing, concurrency settings, mitigation cold start и обработкой ошибок может оценивать ответы в десять раз быстрее наивной реализации, стоить заметно дешевле и обеспечивать более надежное обучение. Вложенные на раннем этапе усилия по оптимизации окупаются на протяжении всего обучения за счет сокращения времени итераций, снижения вычислительных затрат и обнаружения проблем до того, как они потребуют дорогостоящего переобучения.
- Убедитесь, что IAM permissions корректно настроены до начала обучения
Управление зависимостями и permissions
- Как добавлять зависимости: их можно либо включить прямо в код в deployment package (.zip file), либо использовать Lambda layers, чтобы хранить зависимости отдельно от основной логики.
- Доступ Amazon Bedrock для RLAIF: execution role для Lambda-функции должен иметь доступ к Amazon Bedrock для вызова LLM API.
Используйте layers для зависимостей, которыми пользуются несколько функций. Используйте deployment packages для логики, специфичной для конкретной функции. Назначайте AWS Identity and Access Management (IAM) permissions роли выполнения Lambda для реализаций RLAIF. Следуя принципу least privilege, ограничивайте Resource ARN конкретной foundation model, которую вы используете в качестве judge, а не применяйте wildcard.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": "arn:aws:bedrock:<region>:<account-id>:foundation-model/<model-id>"
}
]
}
- Понимание различий платформ и того, какая платформа может лучше подойти для ваших задач
Оптимизация reward functions на базе Lambda требует понимания того, как разные training environments взаимодействуют с serverless-оценкой и как архитектурные решения влияют на throughput, latency и cost. Ландшафт оптимизации существенно отличается между synchronous и asynchronous processing models, поэтому настройка под конкретную среду критически важна для production-scale кастомизации.
Amazon SageMaker AI Training Jobs используют synchronous processing: сначала генерируются rollouts, а затем они оцениваются параллельными batches. Эта архитектура создает отдельные возможности оптимизации вокруг batch sizing и управления concurrency. Параметр lambda_batch_size, по умолчанию равный 64, определяет, сколько samples Lambda оценивает за один вызов — увеличивайте его для быстрых reward functions, которые завершаются за миллисекунды, и уменьшайте для сложных оценок, приближающихся к таймауту. Параметр lambda_concurrency управляет параллельным выполнением, и стандартное значение 12 concurrent invocations часто оказывается слишком консервативным для production workloads. Быстрые reward functions выигрывают от значительно более высокой concurrency, иногда достигающей 50 и более одновременных запусков, хотя нужно следить за account-level Lambda concurrency limits, которые ограничивают общее число одновременных выполнений всех ваших функций в регионе.
Amazon SageMaker AI HyperPod использует принципиально иной подход через asynchronous processing, когда samples генерируются и оцениваются по отдельности, а не большими batches. Такая sample-by-sample архитектура естественно поддерживает более высокий throughput: конфигурации по умолчанию обрабатывают 400 transactions per second через Lambda без специальной настройки. Выход за пределы этого уровня требует согласованной корректировки параметров HyperPod recipe — в частности, proc_num и rollout_worker_replicas, которые управляют параллелизмом worker-ов. При агрессивном масштабировании worker-ов стоит пропорционально увеличивать generation_replicas, чтобы генерация не стала узким местом, пока вычислительная мощность оценки простаивает.
- Оптимизация reward function с помощью concurrency Lambda
Конфигурация Lambda напрямую влияет на скорость и надежность обучения:
-
- Настройка timeout: установите timeout на 60 секунд (по умолчанию всего 3 секунды), это дает запас для вызовов judge в RLAIF или сложной логики RLVR
- Выделение памяти: установите memory на 512 MB (по умолчанию 128 MB), ускорение CPU улучшает время ответа
- Снижение влияния cold start
Снижение влияния cold start предотвращает скачки задержки, которые могут замедлять обучение и увеличивать стоимость. Держите deployment packages меньше 50MB, чтобы минимизировать время инициализации — часто это означает исключение ненужных зависимостей и использование Lambda layers для крупных общих библиотек. Переиспользуйте соединения между вызовами, инициализируя clients вроде Amazon Bedrock runtime client в global scope, а не внутри handler function, чтобы среда выполнения Lambda могла сохранять эти соединения между вызовами. Профилируйте функцию с помощью Lambda Insights, чтобы находить узкие места. Кэшируйте часто используемые данные, такие как evaluation rubrics, rules валидации или параметры конфигурации, в global scope, чтобы Lambda загружала их один раз на контейнер, а не при каждом вызове. Такой шаблон глобальной инициализации с выполнением логики на уровне handler особенно эффективен для Lambda-функций, обрабатывающих тысячи оценок во время обучения.
# Держите deployment package меньше 50MB
# Переиспользуйте соединения между вызовами
bedrock_client = boto3.client('bedrock-runtime') # Global scope
# Кэшируйте часто используемые данные
EVALUATION_RUBRICS = {...} # Load once
def lambda_handler(event, context):
# Clients и cached data сохраняются между вызовами
return evaluate_responses(event, bedrock_client, EVALUATION_RUBRICS)
- Оптимизация RLAIF judge models
Для реализаций RLAIF, использующих модели Amazon Bedrock в роли judges, есть важный компромисс. Более крупные модели дают более надежные оценки, но имеют меньший throughput, тогда как более маленькие модели работают быстрее, но могут быть менее способными — выбирайте самую маленькую judge model, которая достаточна для вашей задачи, чтобы максимизировать throughput. Перед масштабированием на полное обучение проверьте consistency judge-модели.
Управление throughput:
-
- Следите за throttling limits Amazon Bedrock на уровне региона
- Рассмотрите Amazon SageMaker AI endpoints для judge models. Они обеспечивают более высокий throughput, но сейчас ограничены open weight и Nova models
- По возможности объединяйте несколько оценок в один API call
- Учитывайте, что параллельные training jobs делят quota Amazon Bedrock
- Обеспечение устойчивости и исправляемости Lambda reward function к ошибкам
Реальные системы сталкиваются со сбоями — сетевыми проблемами, временной недоступностью сервиса или occasional Lambda timeouts. Вместо того чтобы позволить одной ошибке сорвать весь training job, мы встроили надежные retry-механизмы, которые автоматически обрабатывают timeout-ы, Lambda failures и transient errors. Система интеллектуально повторяет неудачные вычисления награды с exponential backoff, давая временным проблемам время на восстановление. Если вызов не удается даже после трех попыток, вы получите понятное и полезное сообщение об ошибке, указывающее на конкретную проблему — timeout, проблему с permissions или баг в логике reward. Такая прозрачность помогает быстро находить и исправлять ошибки без разбора крипичных логов.
def robust_evaluation(sample, max_retries=3):
"""Оценка с полным обработчиком ошибок."""
for attempt in range(max_retries):
try:
score = compute_score(sample)
return score
except ValueError as e:
# Ошибки парсинга - вернуть 0 и залогировать
print(f"Parse error for {sample['id']}: {str(e)}")
return 0.0
except Exception as e:
# Временные ошибки - повтор с backoff
if attempt < max_retries - 1:
time.sleep(2 ** attempt)
else:
print(f"Failed after {max_retries} attempts: {str(e)}")
return 0.0
return 0.0
- Итеративная отладка в CloudWatch и раннее обнаружение признаков ошибок
Наблюдаемость процесса обучения критически важна и для мониторинга прогресса, и для отладки проблем. Мы автоматически записываем в CloudWatch полную информацию о каждом этапе training pipeline: метрики каждого шага обучения — включая step wise training reward scores и подробные execution traces для каждого компонента pipeline. Такая granular logging позволяет легко отслеживать ход обучения в реальном времени, проверять, что reward function оценивает ответы так, как ожидается, и быстро диагностировать возникающие проблемы. Например, если вы видите, что обучение не улучшается, можно изучить распределение наград в CloudWatch и понять, возвращает ли функция в основном нули или сигнал слишком слаб.
CloudWatch дает полную видимость работы reward function. Вот несколько полезных Amazon CloudWatch Insights Queries для решения:
-- Найти samples с нулевыми reward
SOURCE '/aws/lambda/my-reward-function'
| fields @timestamp, id, aggregate_reward_score
| filter aggregate_reward_score = 0.0
| sort @timestamp desc
-- Посчитать распределение reward
SOURCE '/aws/lambda/my-reward-function'
| fields aggregate_reward_score
| stats count() by bin(aggregate_reward_score, 0.1)
-- Выявить медленные оценки
SOURCE '/aws/lambda/my-reward-function'
| fields @duration, id
| filter @duration > 5000
| sort @duration desc
-- Отслеживать многомерные метрики
SOURCE '/aws/lambda/my-reward-function'
| fields @timestamp, correctness, format, safety, conciseness
| stats avg(correctness) as avg_correctness,
avg(format) as avg_format,
avg(safety) as avg_safety,
avg(conciseness) as avg_conciseness
by bin(5m)
Conclusion
Reward functions на базе Lambda открывают кастомизацию Amazon Nova для организаций, которым нужен точный контроль поведения без огромных размеченных датасетов и улучшенное reasoning. Такой подход дает заметные преимущества за счет гибкости, масштабируемости и экономичности, которые упрощают процесс кастомизации моделей. Архитектура позволяет RLVR решать задачи объективной проверки, а RLAIF — субъективного суждения для тонких качественных оценок. Организации могут использовать их по отдельности или комбинировать для комплексной оценки, которая учитывает как фактическую точность, так и стилистические предпочтения. Масштабируемость естественно вытекает из serverless-основы, автоматически обрабатывающей переменную нагрузку обучения — от ранних экспериментов до кастомизации промышленного масштаба. Экономичность напрямую следует из этой конструкции: организации платят только за фактические вычисления при оценке, а training jobs завершаются быстрее благодаря оптимизированной concurrency Lambda и эффективному вычислению наград. Сочетание foundation models Amazon Nova, serverless-масштабируемости Lambda и управляемой инфраструктуры кастомизации Amazon Bedrock делает reinforcement fine-tuning доступнее независимо от масштаба организации. Начните экспериментировать с примерами кода из этого блога и создавайте модели Amazon Nova, которые точно демонстрируют нужное поведение ваших приложений.
Acknowledgements
Отдельная благодарность Eric Grudzien и Anupam Dewan за рецензию и вклад в этот материал.
Материал — перевод статьи с английского.
Оригинал: How to build effective reward functions with AWS Lambda for Amazon Nova model customization