Как Amazon Bedrock дообучает Amazon Nova: SFT, RFT и дистилляция моделей

Искусственный интеллект
Сегодня мы рассказываем о том, как Amazon Bedrock упрощает настройку моделей Amazon Nova под ваши конкретные бизнес-задачи. По мере масштабирования ИИ-развертываний клиентам нужны модели, отражающие внутренние знания и рабочие процессы компании — будь то единый фирменный стиль в коммуникациях с клиентами, обработка сложных отраслевых сценариев или точная классификация намерений в системе бронирования авиабилетов с высоким потоком запросов. Такие техники, как prompt engineering и Retrieval-Augmented Generation (RAG), дают модели дополнительный контекст, чтобы улучшить качество выполнения задачи, но они не формируют у модели внутреннее понимание.
Amazon Bedrock поддерживает три подхода к настройке моделей Nova: supervised fine-tuning (SFT), которое обучает модель на размеченных примерах «вход-выход»; reinforcement fine-tuning (RFT), которое использует функцию вознаграждения для направления обучения к целевому поведению; и model distillation, которое переносит знания от более крупной модели-учителя к меньшей и более быстрой модели-ученику. Каждый из этих методов встраивает новые знания непосредственно в веса модели, а не подает их во время инференса через промпты или извлеченный контекст. Благодаря этим подходам вы получаете более быстрый инференс, более низкие затраты на токены и более высокую точность на тех задачах, которые важнее всего для вашего бизнеса. Amazon Bedrock автоматически управляет процессом обучения: достаточно загрузить данные в Amazon Simple Storage Service (Amazon S3) и запустить задание через консоль управления AWS, CLI или API. Глубокая экспертиза в машинном обучении не требуется. Модели Nova поддерживают on-demand-вызов кастомизированных моделей в Amazon Bedrock. Это означает, что вы платите только за каждый вызов по стандартной ставке модели, а не покупаете более дорогую выделенную мощность (Provisioned Throughput).
В этом материале мы пошагово покажем полную реализацию дообучения модели в Amazon Bedrock с использованием моделей Amazon Nova, на примере классификатора намерений, который демонстрирует более высокую производительность на специализированной предметной задаче. В ходе этого руководства вы узнаете, как подготовить качественные обучающие данные, которые действительно улучшают модель, как настроить гиперпараметры для оптимизации обучения без переобучения и как развернуть дообученную модель для повышения точности и снижения задержки. Мы покажем, как оценивать результаты с помощью метрик обучения и кривых потерь.
Понимание дообучения и когда его использовать
Техники контекстной инженерии, такие как prompt engineering или Retrieval-Augmented Generation (RAG), помещают информацию в промпт модели. У этих подходов есть важные преимущества: они начинают работать сразу, без обучения, позволяют динамически обновлять информацию и работают с несколькими foundation-моделями без модификации. Однако при каждом вызове они потребляют токены контекстного окна, что со временем может увеличивать совокупные затраты и задержку. Что еще важнее, они плохо обобщаются. Модель каждый раз просто читает инструкции, а не усваивает знания внутренне, поэтому ей может быть сложно справляться с новыми формулировками, крайними случаями или задачами, требующими рассуждения за пределами того, что явно задано в промпте. Методы настройки, напротив, встраивают новые знания прямо в модель, добавляя матрицу адаптера с дополнительными весами и настраивая их («parameter-efficient fine-tuning», или PEFT). В результате настроенная модель приобретает новые навыки в конкретной предметной области. Настройка позволяет более быстрым и эффективным небольшим моделям достигать качества, сопоставимого с более крупными моделями, в конкретной обучающей области.
Когда стоит дообучать: рассматривайте дообучение, если у вас есть высоконагруженная, четко определенная задача, для которой можно собрать качественные размеченные примеры или функцию вознаграждения. Примеры сценариев: обучение модели корректно отображать логотип вашей компании, внедрение фирменного тона и корпоративных политик в модель или замена традиционного ML-классификатора на небольшой LLM. Например, Amazon Customer Service настроила Nova Micro для специализированной поддержки клиентов, чтобы повысить точность и снизить задержку, улучшив точность на 5,4% по отраслевым вопросам и на 7,3% по общим вопросам.
Небольшие дообученные LLM, такие как Nova Micro, все чаще заменяют традиционные ML-классификаторы в задачах вроде распознавания намерений. Они дают гибкость и накопленные знания LLM на скорости и по стоимости легкой модели. В отличие от классификаторов, LLM справляются с естественными вариациями формулировок, сленгом и контекстом без переобучения, а дообучение дополнительно повышает точность именно для конкретной задачи. Позже в этом блоге мы покажем это на примере классификатора намерений.
Когда НЕ стоит дообучать: дообучение требует подготовки качественных размеченных данных или функции вознаграждения и запуска обучающего задания, что связано с первоначальными затратами времени и денег. Однако эти начальные вложения могут снизить стоимость инференса на запрос и задержку для приложений с высоким трафиком.
Подходы к настройке
Amazon Bedrock предлагает три подхода к настройке моделей Nova:
- Supervised fine-tuning (SFT) — настраивает модель на обучение закономерностям по размеченным данным, которые вы предоставляете. В этом материале этот метод показан на практике.
- Reinforcement fine-tuning (RFT) — использует обучающие данные в сочетании с функцией вознаграждения, либо с пользовательским кодом, либо с LLM, выступающей в роли судьи, чтобы направлять процесс обучения.
- Model distillation — для сценариев, где требуется перенос знаний, позволяет сжать идеи крупных моделей-учителей в более компактные и эффективные модели-ученики, подходящие для устройств с ограниченными ресурсами.
Amazon Bedrock автоматически использует подходящие для модели техники parameter efficient fine-tuning (PEFT) при настройке моделей Nova. Это уменьшает требования к памяти и ускоряет обучение по сравнению с полным дообучением, сохраняя качество модели. Теперь, когда мы определили, когда и зачем использовать дообучение, рассмотрим, как Amazon Bedrock упрощает процесс реализации и какие модели Nova поддерживают этот подход.
Модели Amazon Nova в Amazon Bedrock
Amazon Bedrock полностью автоматизирует подготовку инфраструктуры, управление вычислительными ресурсами и оркестрацию обучения. Вы загружаете данные в S3 и запускаете обучение одной командой API, без управления кластерами и GPU или настройки распределенных пайплайнов обучения. Сервис предоставляет понятную документацию по подготовке данных, включая спецификации формата и требования к схеме, разумные значения гиперпараметров по умолчанию, такие как epochCount и learningRateMultiplier, а также видимость процесса обучения через кривые потерь, которые помогают отслеживать сходимость в реальном времени.
Модели Nova: несколько моделей Nova позволяют выполнять дообучение (см. документацию). После завершения обучения вы можете размещать настроенные модели Nova в Amazon Bedrock с использованием экономичного On Demand-инференса по той же низкой цене, что и у ненастроенной модели.
Nova 2 Lite, например, — это быстрая и экономичная reasoning-модель. Будучи мультимодальной foundation-моделью, она обрабатывает текст, изображения и видео в контекстном окне на 1 миллион токенов. Такое окно позволяет анализировать документы объемом более 400 страниц или видео длительностью 90 минут в одном промпте. Модель хорошо подходит для обработки документов, понимания видео, генерации кода и agentic workflows. Nova 2 Lite поддерживает как SFT, так и RFT.
Самая маленькая модель Nova, Nova Micro, также особенно полезна, поскольку обеспечивает быстрый и недорогой инференс с интеллектом LLM. Nova Micro идеально подходит для задач промежуточной обработки в составе более крупной системы, например для исправления адресов или извлечения полей данных из текста. В этом материале мы показываем пример настройки Nova Micro для задачи сегментации вместо создания собственной модели data science. Эта таблица показывает reasoning-модели Nova 1 и Nova 2 и их текущую доступность на момент публикации, а также какие модели сейчас позволяют RFT или SFT. Эти возможности могут меняться; см. онлайн-документацию для актуальной информации о доступности моделей и настройках, а также руководство пользователя Nova для подробностей о моделях.
| Модель | Возможности | Вход | Выход | Статус | Дообучение в Bedrock |
| Nova Premier | Самая мощная модель для сложных задач и модель-учитель для model distillation | Текст, изображения, видео (без аудио) | Текст | Обычно доступна | Может использоваться как учитель для model distillation |
| Nova Pro | Мультимодальная модель с лучшим сочетанием точности, скорости и стоимости для широкого круга задач | Текст, изображения, видео | Текст | Обычно доступна | SFT |
| Nova 2 Lite | Недорогая мультимодальная модель с быстрой обработкой | Текст, изображения, видео | Текст | Обычно доступна | RFT, SFT |
| Nova Lite | Недорогая мультимодальная модель с быстрой обработкой | Текст, изображения, видео | Текст | Обычно доступна | SFT |
| Nova Micro | Ответы с минимальной задержкой при низкой стоимости. | Текст | Текст | Обычно доступна | SFT |
Теперь, когда вы понимаете, как модели Nova поддерживают дообучение через управляемую инфраструктуру Amazon Bedrock, давайте рассмотрим реальный сценарий, демонстрирующий эти возможности на практике.
Пример использования — определение намерений (замена традиционных ML-моделей)
Определение намерений устанавливает категорию ожидаемого взаимодействия пользователя по входному примеру. Например, в системе помощи авиапассажирам пользователь может пытаться получить информацию о ранее забронированном рейсе или задавать вопрос об услугах авиакомпании, например о перевозке питомца. Часто системе нужно маршрутизировать запрос к конкретным агентам в зависимости от намерения. Системы определения намерений должны работать быстро и экономично при больших объемах.
Традиционным решением для такой системы было обучение модели машинного обучения. Хотя это эффективно, разработчики все чаще переходят на небольшие LLM для таких задач. LLM дают больше гибкости, их можно быстро модифицировать через изменение промпта, и они уже содержат обширные знания о мире. Их понимание сокращенных форм, сленга из сообщений, синонимов и контекста может улучшить пользовательский опыт, а сам процесс разработки LLM знаком AI-инженерам.
В нашем примере мы настроим модель Nova Micro на открытом наборе данных Airline Travel Information System (ATIS) — отраслевом эталонном наборе для систем, основанных на намерениях. Без настройки Nova Micro достигает 41,4% на ATIS, но мы можем настроить ее под конкретную задачу, повысив точность до 97% с помощью простого обучающего задания.
Техническая реализация: процесс дообучения
Два критически важных фактора, определяющих успех дообучения модели, — это качество данных и выбор гиперпараметров. То, насколько хорошо вы с ними справитесь, определяет, сойдется ли модель эффективно или потребует дорогостоящего переобучения. Давайте рассмотрим каждый компонент процесса реализации, начав с подготовки обучающих данных.
Подготовка данных
Amazon Bedrock требует формат JSONL (JavaScript Object Notation Lines), потому что он обеспечивает эффективную потоковую обработку больших наборов данных во время обучения, позволяя обрабатывать данные постепенно без ограничений по памяти. Этот формат также упрощает валидацию: каждую строку можно проверять на ошибки независимо. Убедитесь, что каждая строка в файле JSONL является корректным JSON. Если формат файла неверен, задание по созданию модели в Amazon Bedrock завершится ошибкой. Подробнее см. документацию по дообучению моделей Nova. Мы использовали скрипт, чтобы преобразовать набор данных ATIS в JSONL. Nova Micro принимает отдельный набор валидации, поэтому мы отложили 10% данных в набор валидации (модели Nova 2 делают это автоматически в процессе настройки). Мы также выделили тестовый набор записей, на которых модель не обучалась, чтобы обеспечить чистые результаты тестирования.
В нашем примере классификатора намерений входные данные — только текст. Однако при дообучении мультимедийных моделей убедитесь, что вы используете только поддерживаемые форматы изображений (PNG, JPEG и GIF). Убедитесь, что ваши обучающие примеры охватывают важные случаи. Проверьте набор данных вместе с командой и удалите неоднозначные или противоречивые ответы до начала дообучения.
{"schemaVersion": "bedrock-conversation-2024", "system": [{"text": "Классифицируйте намерение авиазапросов. Выберите одно намерение из этого списка: abbreviation, aircraft, aircraft+flight+flight_no, airfare, airfare+flight_time, airline, airline+flight_no, airport, capacity, cheapest, city, distance, flight, flight+airfare, flight_no, flight_time, ground_fare, ground_service, ground_service+ground_fare, meal, quantity, restriction\n\nОтвечайте только названием намерения, без какого-либо другого текста."}], "messages": [{"role": "user", "content": [{"text": "покажите мне утренние рейсы из бостона в филадельфию"}]}, {"role": "assistant", "content": [{"text": "flight"}]}]}
Подготовленная строка в примере обучающих данных (обратите внимание, что хотя она выглядит перенесенной, формат JSONL на самом деле представляет собой одну строку на пример)
Важно: обратите внимание, что системный промпт присутствует в обучающих данных. Крайне важно, чтобы системный промпт, используемый для обучения, совпадал с системным промптом, используемым на этапе инференса, поскольку модель усваивает системный промпт как контекст, запускающий ее дообученное поведение.
Вопросы конфиденциальности данных:
При дообучении на чувствительных данных:
- Анонимизируйте или маскируйте PII (имена, адреса электронной почты, номера телефонов, платежные данные) перед загрузкой в Amazon S3.
- Учитывайте требования к размещению данных для соблюдения нормативных требований.
- Amazon Bedrock не использует ваши обучающие данные для улучшения базовых моделей.
- Для усиления безопасности рассмотрите использование конечных точек Amazon Virtual Private Cloud (VPC) для частного соединения между S3 и Amazon Bedrock, чтобы исключить выход в публичный интернет.
Ключевые гиперпараметры
Гиперпараметры управляют обучающим заданием. Amazon Bedrock задает разумные значения по умолчанию, и часто их можно использовать без изменений, но для достижения целевой точности может потребоваться их подстройка. Ниже приведены гиперпараметры для моделей Nova understanding — для других моделей см. документацию:
Три гиперпараметра определяют поведение обучающего задания, и хотя Amazon Bedrock задает разумные значения по умолчанию, понимание этих параметров помогает оптимизировать результат. Правильная настройка этих значений может сэкономить вам часы обучения и уменьшить вычислительные затраты.
Первый гиперпараметр, epochCount, задает, сколько полных проходов модель сделает по вашему набору данных. Представьте, что вы несколько раз перечитываете книгу, чтобы лучше ее понять. После первого прочтения можно усвоить 60% материала; второй проход повышает понимание до 80%. Однако после того, как вы уже понимаете 100% материала, дальнейшие чтения только тратят время обучения без прироста качества. Модели Amazon Nova поддерживают от 1 до 5 эпох при значении по умолчанию 2. Большие наборы данных обычно сходятся за меньшее число эпох, а небольшие выигрывают от большего числа итераций. Для нашего примера классификатора намерений ATIS с примерно 5000 объединенных примеров мы установили epochCount равным 3.
learningRateMultiplier определяет, насколько агрессивно модель учится на ошибках. По сути, это размер шага исправлений. Если скорость обучения слишком высока, можно упустить детали и прийти к неверным выводам. Если она слишком низкая, выводы формируются медленно. Для примера ATIS мы используем 1e-5 (0,00001), что обеспечивает стабильное и постепенное обучение. Параметр learningRateWarmupSteps постепенно увеличивает скорость обучения до указанного значения в течение заданного числа итераций, смягчая нестабильность на старте обучения. В нашем примере мы используем значение по умолчанию 10.
Почему это важно: правильный выбор числа эпох позволяет избежать напрасной траты времени и денег на обучение. Каждая эпоха — это еще один проход по полному обучающему набору, а значит, большее количество обработанных токенов, что и является основной статьей расходов при обучении модели — см. раздел «Стоимость и время обучения» далее в статье. Слишком малое число эпох означает, что модель может недостаточно хорошо выучить обучающие данные. Ранний поиск этого баланса экономит и время, и бюджет. Скорость обучения напрямую влияет на точность модели и эффективность тренировки, и это может быть разницей между моделью, сходящейся за часы, и моделью, которая так и не достигает приемлемого качества.
Запуск задания дообучения
Необходимое условие для дообучения — создать S3 bucket с обучающими данными.
Настройка S3 bucket
Создайте S3 bucket в том же регионе, что и ваше задание Amazon Bedrock, со следующими настройками безопасности:
- Включите шифрование на стороне сервера (SSE-S3 или SSE-KMS), чтобы защитить обучающие данные в состоянии покоя.
- Запретите публичный доступ к bucket, чтобы исключить несанкционированное раскрытие.
- Включите версионирование S3, чтобы защитить обучающие данные от случайной перезаписи и отслеживать изменения между итерациями обучения.
Примените те же механизмы шифрования и контроля доступа к выходному S3 bucket. Загрузите файл JSONL в новый S3 bucket и организуйте его с префиксом /training-data. Версионирование S3 помогает защитить обучающие данные от случайной перезаписи и позволяет отслеживать изменения между итерациями обучения. Это особенно важно, когда вы экспериментируете с разными версиями набора данных, чтобы оптимизировать результаты.
Чтобы создать задание supervised fine-tuning
- В консоли управления AWS выберите Amazon Bedrock.
- Выберите Test, Chat/Text playground и убедитесь, что Nova Micro отображается в выпадающем списке выбора модели.
- В разделе Custom model выберите Create, а затем Supervised fine-tuning job.
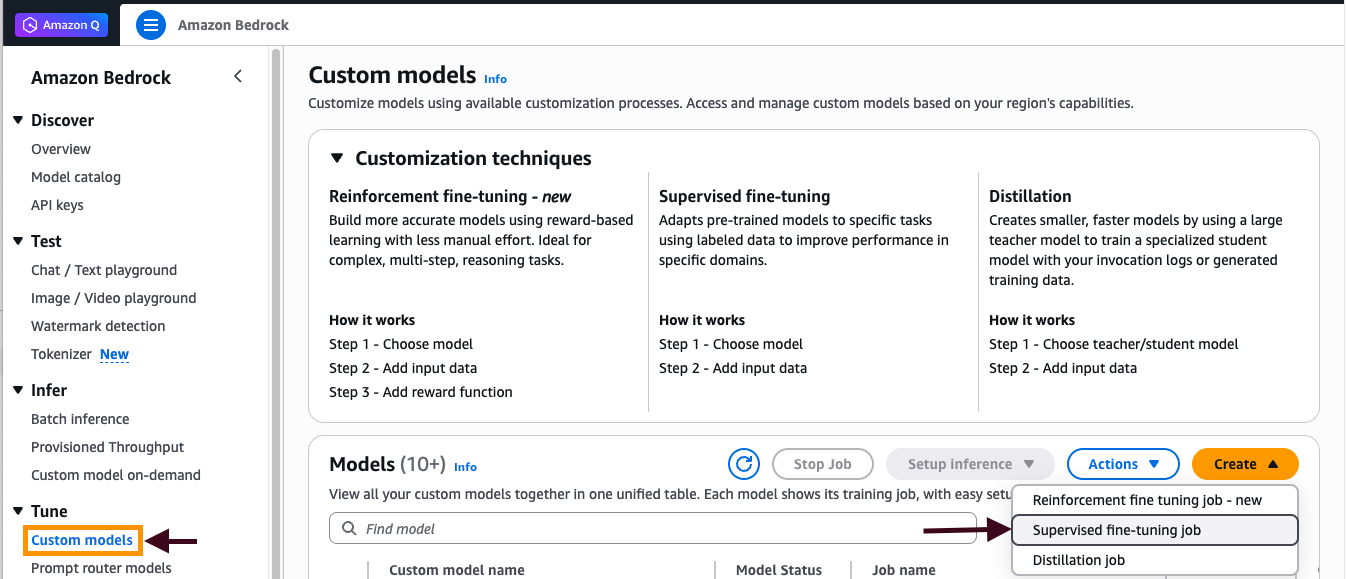
Рисунок 1: Создание задания supervised fine-tuning
- Укажите модель Nova Micro в качестве исходной модели.
- В разделе Training data введите путь S3 URI к вашему обучающему JSONL-файлу (например,
s3://amzn-s3-demo-bucket/training-data/focused-training-data-v2.jsonl). - В разделе Output data укажите путь S3 URI, где будут храниться результаты обучения (например,
s3://amzn-s3-demo-bucket/output-data/). - Разверните раздел Hyperparameters и задайте следующие значения:
epochCount: 3,learningRateMultiplier: 1e-5,learningRateWarmupSteps: 10 - Выберите IAM role с минимально необходимыми разрешениями на доступ к S3 или создайте такую роль. Роль должна иметь:
- Ограниченные разрешения только на конкретные действия (
s3:GetObjectиs3:PutObject) для конкретных путей bucket, напримерarn:aws:s3:::your-bucket-name/training-data/*иarn:aws:s3:::your-bucket-name/output-data/* - Избегайте избыточного предоставления прав и включайте ключи условий IAM.
- Подробные рекомендации по лучшим практикам разрешений S3 и настройкам безопасности см. в документации AWS IAM Best Practices.
- Ограниченные разрешения только на конкретные действия (
- Выберите Create job.
Мониторинг статуса задания
Чтобы отслеживать статус и сходимость обучающего задания:
- Отслеживайте статус задания на панели Custom models.
- Дождитесь завершения этапа Data validation, затем этапа Training (время выполнения варьируется от минут до часов в зависимости от размера набора данных и модальности).
- После завершения обучения выберите имя задания, чтобы открыть вкладку Training metrics и убедиться, что кривая потерь демонстрирует корректную сходимость.
- После завершения обучения, если задание успешно, создается пользовательская модель, готовая к инференсу. Вы можете развернуть настроенную модель Nova для on-demand-инференса.
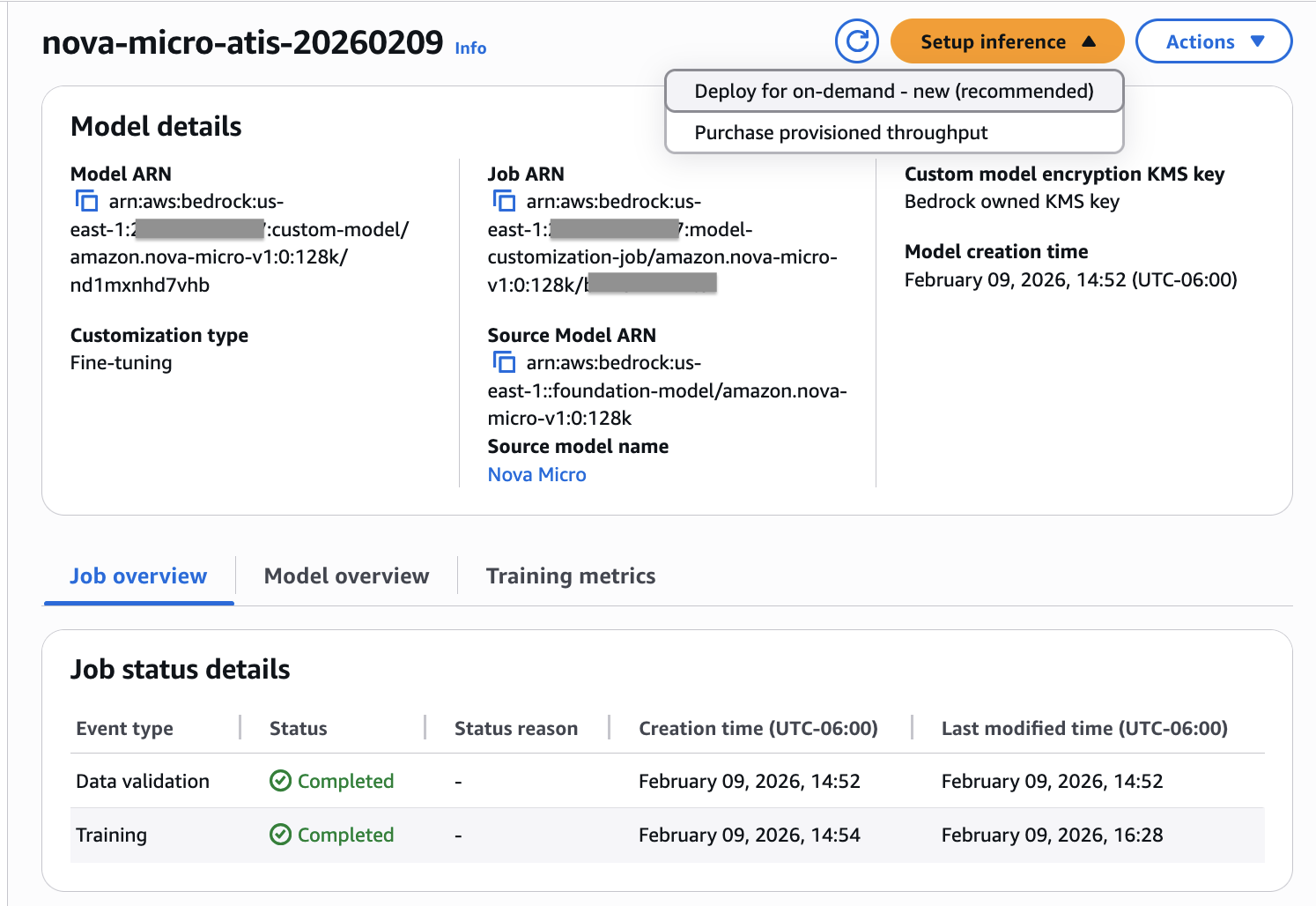
Рисунок 2: Проверка статуса задания
Оценка успешности обучения
В Amazon Bedrock вы можете оценить эффективность дообучения с помощью метрик обучения и кривых потерь. Анализируя изменение training loss по шагам и эпохам, можно понять, насколько эффективно обучается модель, и определить, нужны ли изменения гиперпараметров для оптимальной производительности. Amazon Bedrock customization автоматически сохраняет артефакты обучения, включая результаты валидации, метрики, логи и обучающие данные, в указанный вами S3 bucket, обеспечивая полную прозрачность процесса обучения. Данные метрик обучения позволяют отслеживать, как модель ведет себя при конкретных гиперпараметрах, и принимать обоснованные решения по настройке.
Рисунок 3: Пример метрик обучения в формате CSV
Вы можете визуализировать процесс обучения модели прямо из консоли Amazon Bedrock Custom Models. Выберите настроенную модель, чтобы получить доступ к подробным метрикам, включая интерактивную кривую training loss, показывающую, насколько эффективно модель усвоила обучающие данные с течением времени. Кривая потерь дает представление о ходе обучения и о том, нужно ли менять гиперпараметры для эффективного обучения. На вкладке Amazon Bedrock Custom Models выберите настроенную модель, чтобы увидеть ее детали, включая кривую training loss (рисунок 4).
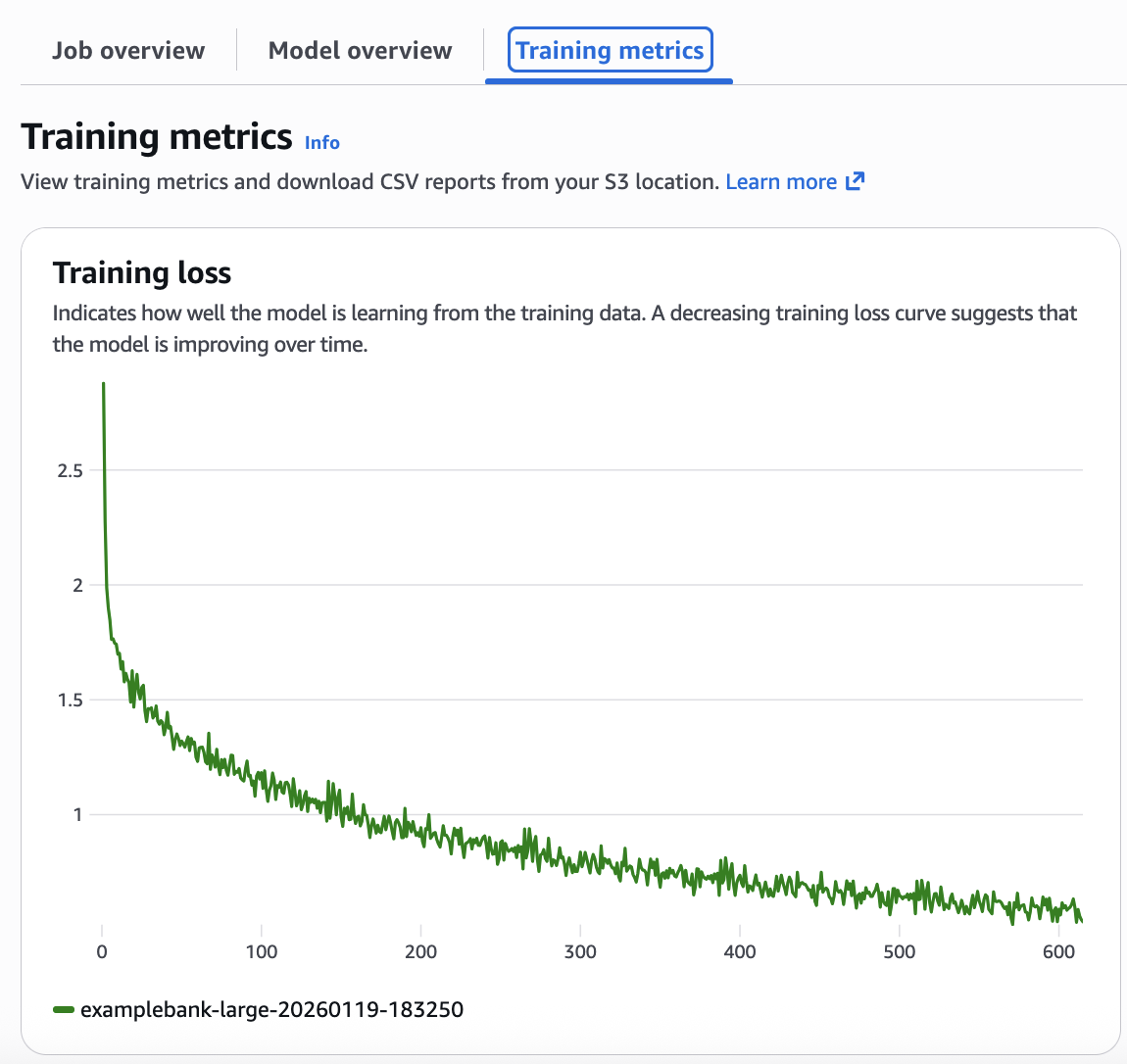
Рисунок 4: Анализ кривой потерь по метрикам обучения
Эта кривая потерь показывает, что модель работает хорошо. Снижающаяся кривая потерь, видимая в метриках, подтверждает, что модель успешно обучилась на ваших данных. В идеале по мере обучения training loss и validation loss должны идти примерно синхронно. Хорошо настроенная модель демонстрирует устойчивую сходимость — loss снижается плавно, без резких колебаний. Если вы видите колеблющийся график потерь (резкие скачки вверх и вниз), уменьшите learningRateMultiplier на 50% и перезапустите обучение. Если loss снижается слишком медленно (плоская или едва убывающая кривая), увеличьте learningRateMultiplier в 2 раза. Если loss рано выходит на плато (выравнивается до достижения хорошей точности), увеличьте epochCount на 1–2 эпохи.
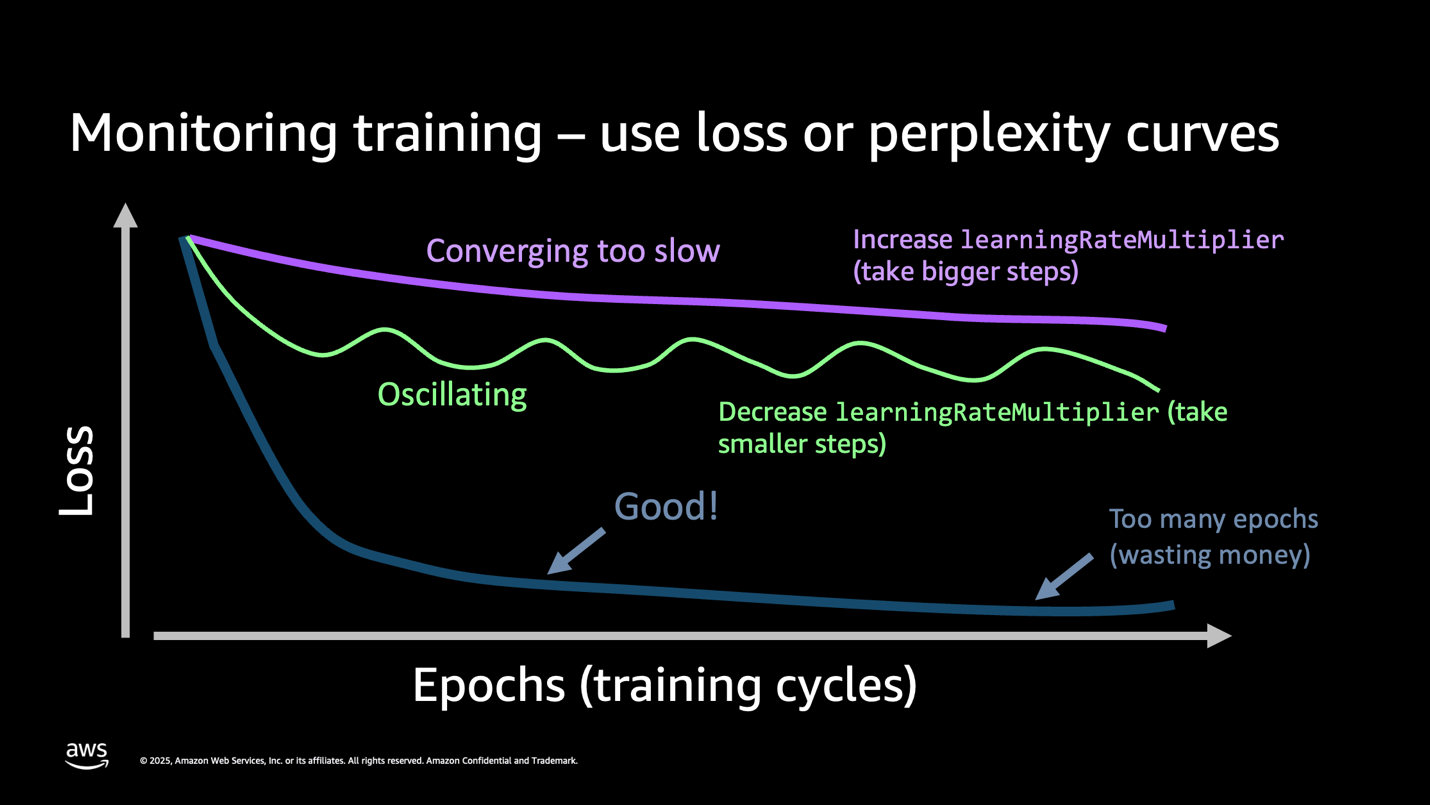
Рисунок 5: Понимание кривой потерь
Ключевой вывод: кривая потерь рассказывает всю историю. Плавный нисходящий тренд означает успех. Сильные колебания означают, что скорость обучения слишком высока. Плоская линия означает, что вам нужно больше эпох или лучшие данные. Отслеживайте этот один показатель, чтобы избежать дорогостоящего переобучения.
Лучшие практики настройки
Максимизация успеха дообучения начинается с качества данных. Небольшие, но качественные наборы данных стабильно превосходят большие и шумные. Сосредоточьтесь на подготовке размеченных примеров, точно отражающих целевую предметную область, а не на сборе огромных объемов посредственных данных. Каждый обучающий пример должен быть правильно сформатирован и проверен перед использованием, поскольку чистые данные напрямую улучшают качество модели. Не забудьте указать подходящий системный промпт.
Распространенные ошибки, которых стоит избегать, — это переобучение (слишком много эпох после достижения сходимости), неудачный формат данных (непоследовательные структуры JSON/JSONL) и настройки гиперпараметров, которые требуют корректировки. Мы рекомендуем проверить формат обучающих данных перед стартом и активно отслеживать кривые потерь во время обучения. Следите за признаками того, что модель сошлась. Продолжение обучения после этого момента тратит ресурсы без улучшения результата.
Стоимость и время обучения
Обучение настроенной модели Nova Micro для нашего примера ATIS с 4 978 объединенными примерами и 3 тренировочными эпохами (~1,75 млн токенов) заняло около 1,5 часа и стоило всего $2,18, плюс ежемесячную плату за хранение модели в размере $1,75. On-Demand-инференс с использованием настроенных моделей Amazon Nova тарифицируется по той же ставке, что и ненастроенные модели. Для справки см. страницу цен Amazon Bedrock. Управляемое дообучение, предоставляемое Amazon Bedrock и моделями Amazon Nova, делает дообучение доступным для большинства организаций с точки зрения бюджета. Простота использования и экономическая эффективность открывают новые возможности для настройки моделей, чтобы получать лучшие и более быстрые результаты без поддержки длинных промптов или баз знаний, специфичных для вашей организации.
Развертывание и тестирование дообученной модели
Рассмотрите on-demand-инференс для непредсказуемых или малонагруженных рабочих нагрузок. Используйте более дорогой provisioned throughput, когда это необходимо для стабильных, высоконагруженных production-сценариев, требующих гарантированной производительности и более низкой стоимости на токен.
Вопросы безопасности модели:
- Ограничьте вызов модели с помощью IAM resource policies, чтобы контролировать, какие пользователи и приложения могут вызывать вашу пользовательскую модель.
- Реализуйте аутентификацию и авторизацию для API-клиентов, обращающихся к on-demand endpoint инференса, с помощью IAM roles и policies.
Безопасность сети:
- Настройте VPC endpoints для Amazon Bedrock, чтобы трафик оставался внутри вашей AWS-сети.
- Ограничьте сетевой доступ к обучающим и инференс-пайплайнам с помощью security groups и network ACLs.
- Рассмотрите размещение ресурсов внутри VPC для дополнительных сетевых контролей.
Имя развертывания должно быть уникальным, а описание должно подробно объяснять, для чего используется пользовательская модель.
Чтобы развернуть модель, введите имя развертывания, описание и выберите Create (рисунок 6).
Рисунок 6:
Развертывание пользовательской модели с on-demand-инференсом
После того как статус изменится на «Active», модель будет готова к использованию вашим приложением и ее можно будет протестировать через Amazon Bedrock playground. Выберите Test in playground (рисунок 7).
Рисунок 7: Тестирование модели через развернутую конечную точку инференса
Логирование и мониторинг:
Включите следующие механизмы для аудита безопасности и реагирования на инциденты:
- AWS CloudTrail для логирования вызовов API Amazon Bedrock
- Amazon CloudWatch для метрик вызова модели и мониторинга производительности
- Логи доступа S3 для отслеживания шаблонов доступа к данным.
Тестирование модели в playground:
Чтобы протестировать инференс с пользовательской моделью, мы используем Amazon Bedrock playground, передавая следующий пример промпта: system:
Классифицируйте намерение авиазапросов. Выберите одно намерение из этого списка: abbreviation, aircraft, aircraft+flight+flight_no, airfare, airfare+flight_time, airline, airline+flight_no, airport, capacity, cheapest, city, distance, flight, flight+airfare, flight_no, flight_time, ground_fare, ground_service, ground_service+ground_fare, meal, quantity, restriction
Отвечайте только названием намерения, без какого-либо другого текста. Я хотел бы найти рейс из шарлотта в лас-вегас с остановкой в сент-луисеЕсли вызвать базовую модель, тот же промпт вернет менее точный ответ.
Важно: обратите внимание, что системный промпт, предоставленный в обучающих данных для дообучения, должен быть включен в ваш промпт при вызове для получения лучших результатов. Поскольку в playground нет отдельного поля для системного промпта для нашей пользовательской модели, мы включаем его в предыдущую строку промпта.
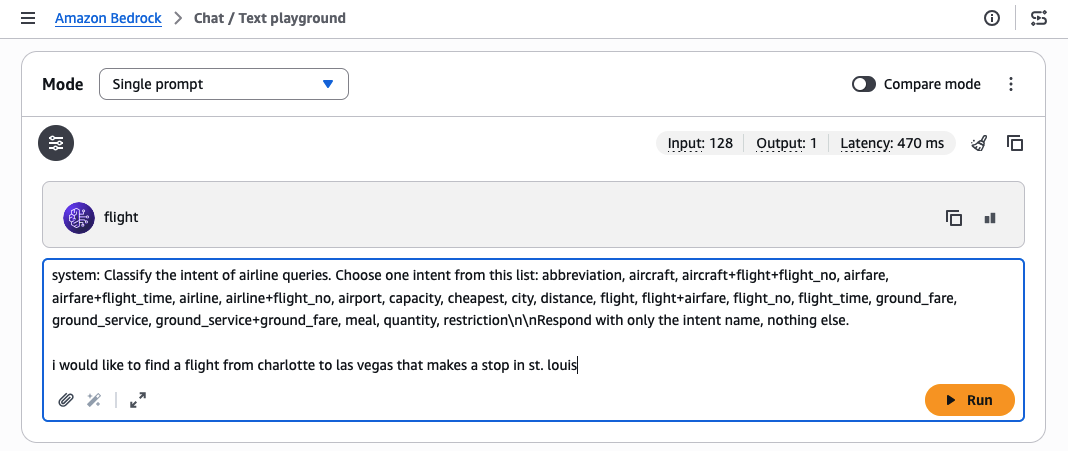
Рисунок 8: Ручная оценка настроенной модели в тестовом playground
Оценка вашей настроенной модели
После обучения модели необходимо оценить ее реальную производительность. Распространенный подход — «LLM как судья», когда более крупная и умная модель с доступом к полной RAG-базе оценивает ответы обученной модели, сравнивая их с ожидаемыми ответами. Для этого Amazon Bedrock предоставляет сервис Amazon Bedrock Evaluations (или вы можете использовать собственный фреймворк). Для рекомендаций см. статью LLM-as-a-judge on Amazon Bedrock Model Evaluation.
Оценка должна использовать тестовый набор вопросов и ответов, подготовленный тем же способом, что и обучающие данные, но хранящийся отдельно, чтобы модель не видела сами вопросы. На рисунке 9 показано, что дообученная модель достигает точности 97% на тестовом наборе данных — это улучшение на 55% по сравнению с базовой моделью Nova Micro.
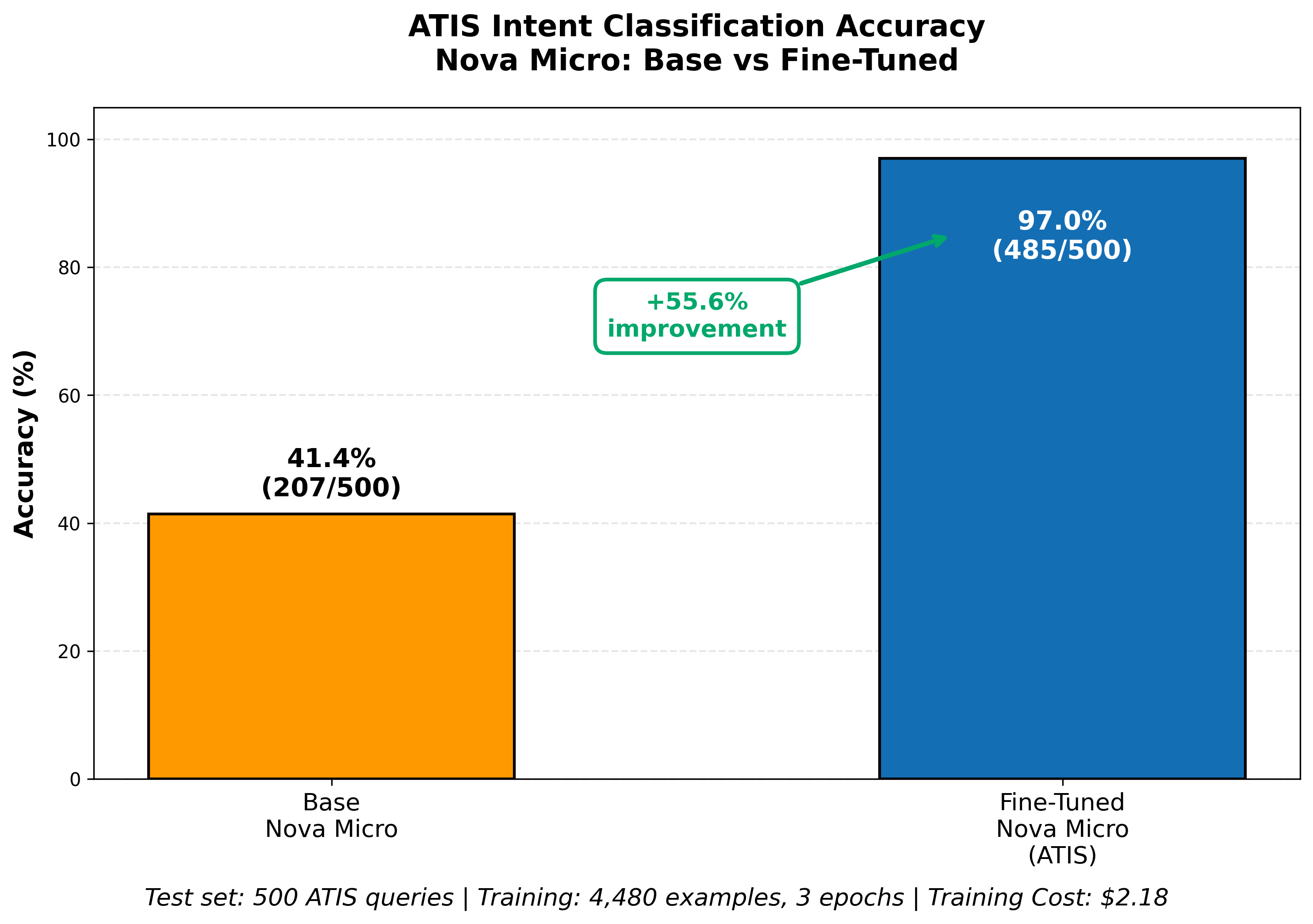
Рисунок 9: Оценка результатов дообучения по сравнению с базовой моделью
За пределами настройки в Amazon Bedrock
Упрощенный опыт настройки в Amazon Bedrock закроет потребности многих клиентов. Если вам нужен более широкий контроль над настройкой, Amazon SageMaker AI предоставляет более широкий набор типов customization и более детальный контроль над гиперпараметрами — подробнее см. статью Announcing Amazon Nova customization in Amazon SageMaker AI.
Для случаев, когда требуется еще более глубокая настройка, Amazon Nova Forge предлагает стратегическую альтернативу созданию foundation-моделей с нуля. Если дообучение учит конкретному поведению в задаче на размеченных примерах, то Nova Forge использует продолженное предварительное обучение, чтобы построить более полное знание предметной области, погружая модель в миллионы и миллиарды токенов неразмеченных, проприетарных данных. Такой подход идеален для организаций с массивными собственными наборами данных, узкоспециализированных областей, требующих глубокой экспертизы, или для тех, кто создает долгосрочные стратегические foundation-модели, которые будут служить организационными активами.
Nova Forge выходит за рамки стандартного дообучения, предлагая расширенные возможности, включая data mixing для снижения catastrophic forgetting при full-rank supervised fine-tuning, выбор checkpoint для оптимальной производительности модели и bring-your-own-optimizer (BYOO) для многошагового reinforcement fine-tuning. Хотя это требует больших инвестиций в виде годовой подписки и более длительных циклов обучения, Forge может обеспечить существенно более экономичный путь, чем обучение foundation-моделей с нуля. Такой подход идеален для создания стратегических ИИ-активов, дающих долгосрочные конкурентные преимущества. Примеры настройки Nova Forge см. в Amazon Nova Customization Hub на GitHub.
Заключение
Как мы показали на примере классификатора намерений, управляемые возможности дообучения в Amazon Bedrock вместе с моделями Nova и Nova 2 делают настройку ИИ доступной при низкой стоимости и минимальных усилиях. Такой упрощенный подход требует минимальной подготовки данных и управления гиперпараметрами, снижая потребность в специализированных навыках data science. Вы можете настраивать модели, чтобы улучшить задержку и снизить стоимость инференса за счет уменьшения объема контекстной информации, которую модели нужно обрабатывать. Дообучение моделей Nova в Amazon Bedrock превращает универсальные foundation-модели в мощные инструменты, ориентированные на конкретную предметную область, обеспечивая более высокую точность и меньшую задержку при низкой стоимости обучения. Возможность Amazon Bedrock размещать модели Nova с использованием On-Demand inference позволяет запускать модель по той же цене за токен, что и базовую модель Nova. Актуальные тарифы см. на странице цен Bedrock.
Чтобы начать собственный проект дообучения с использованием Amazon Bedrock, изучите документацию по дообучению Amazon Bedrock и ознакомьтесь с примерами ноутбуков в репозитории AWS Samples на GitHub.
Материал — перевод статьи с английского.
Оригинал: Customize Amazon Nova models with Amazon Bedrock fine-tuning