Как построить агентного ИИ-ассистента для гибридного поиска с Amazon Bedrock и OpenSearch
Искусственный интеллект
Агентные генеративные AI-ассистенты представляют собой значительный шаг вперед в области искусственного интеллекта: это динамические системы на базе больших языковых моделей (LLM), которые ведут открытый диалог и решают сложные задачи. В отличие от обычных чат-ботов, такие реализации обладают более широким интеллектом, поддерживают многошаговые разговоры, адаптируются к потребностям пользователя и выполняют необходимые задачи на бэкенде.
Эти системы в реальном времени получают бизнес-данные через вызовы API и обращения к базам данных, встраивая эту информацию в ответы, сгенерированные LLM, либо выводя ее рядом с ними с использованием заранее определенных стандартов. Такое сочетание возможностей LLM и динамического получения данных называется Retrieval-Augmented Generation (RAG).
Например, агентный ассистент для бронирования отелей сначала выполнит запрос к базе данных, чтобы найти объекты, соответствующие конкретным требованиям гостя. Затем ассистент сделает вызовы API, чтобы получить актуальную информацию о доступности номеров и текущих тарифах. Эти данные можно обработать двумя способами: либо LLM сформирует на их основе развернутый ответ, либо данные будут показаны рядом с кратким резюме, созданным LLM. Оба подхода позволяют гостю получать точную и актуальную информацию, встроенную в текущий диалог с ассистентом.
В этом материале мы показываем, как реализовать генеративного AI-ассистента с агентной логикой, который использует и семантический, и текстовый поиск с Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents и Amazon OpenSearch.
Подходы к извлечению информации в RAG-системах
В целом извлечение информации, поддерживающее RAG-возможности в агентных генеративных AI-реализациях, сводится к запросам к бэкенд-источникам данных в реальном времени или к взаимодействию с API. Полученные ответы затем учитываются в последующих шагах, выполняемых системой. С точки зрения общей архитектуры и реализации этот шаг не является специфичным для решений на базе генеративного ИИ: базы данных, API и системы, опирающиеся на интеграцию с ними, существуют уже давно. Однако вместе с агентными AI-реализациями появились и некоторые новые подходы к извлечению информации, прежде всего методы семантического поиска. Они находят данные по смыслу поисковой фразы, а не по лексическому сходству ключевых слов или шаблонов. Векторные эмбеддинги заранее вычисляются и хранятся в векторных базах данных, что позволяет эффективно выполнять вычисления сходства во время запроса. Основной принцип Vector Similarity Search (VSS) заключается в поиске наиболее близких совпадений между этими числовыми представлениями с использованием метрик расстояния, таких как косинусное сходство или евклидово расстояние. Эти математические функции особенно эффективны при поиске по большим корпусам данных, потому что векторные представления уже предварительно вычислены. В этом процессе обычно используются bi-encoder-модели. Они отдельно кодируют запрос и документы в векторы, что позволяет масштабно и эффективно сравнивать сходство без необходимости одновременно обрабатывать пары «запрос-документ». Когда пользователь отправляет запрос, система преобразует его в вектор и ищет в высокоразмерном пространстве векторный контент, расположенный ближе всего к нему. Это означает, что даже если точные ключевые слова не совпадают, поиск может найти релевантные результаты на основе концептуального семантического сходства. Более того, в ситуациях, когда поисковые термины лексически близки к записям в наборе данных, но не близки семантически, семантический поиск будет «предпочитать» семантически похожие записи.
Например, для векторизованного набора данных: [«строительные материалы», «сантехнические принадлежности», «результат умножения 2×2»], поисковая строка «доска 2×4 из пиломатериалов» с наибольшей вероятностью вернет в качестве лучшего совпадения «строительные материалы». Сочетание семантического поиска с агентами, управляемыми LLM, обеспечивает естественное согласование между пользовательской частью решения и компонентами извлечения данных на бэкенде. LLM обрабатывают естественный язык, введенный пользователем, а возможности семантического поиска позволяют извлекать данные на основе естественно-языкового ввода, сформулированного LLM, в зависимости от ритма взаимодействия между конечным пользователем и агентом.
Проблема: когда одного семантического поиска недостаточно
Рассмотрим реальный сценарий: клиент ищет гостиничный объект и хочет найти «роскошный отель с видом на океан в Майами, Флорида». Семантический поиск отлично понимает такие понятия, как «роскошный» и «вид на океан», но может испытывать трудности с точным сопоставлением местоположения. Поиск может вернуть очень релевантные роскошные прибрежные отели на основе семантического сходства, но они могут находиться в Калифорнии, Карибском регионе или где угодно еще у океана, а не именно в Майами, как было запрошено. Это ограничение возникает потому, что семантический поиск ставит концептуальное сходство выше точного сопоставления атрибутов. В случаях, когда пользователю нужны и семантическое понимание (роскошь, вид на океан), и точная фильтрация (Майами, Флорида), опора только на семантический поиск дает неоптимальные результаты. Именно здесь становится необходимым гибридный поиск. Он объединяет семантическое понимание естественно-языковых описаний с точностью текстовой фильтрации по структурированным атрибутам, таким как местоположение, даты или конкретные метаданные. Чтобы решить эту задачу, мы предлагаем гибридный подход к поиску, который выполняет оба вида поиска:
- Семантический поиск — чтобы понять естественно-языковое описание и найти семантически похожий контент
- Текстовый поиск — чтобы обеспечить точное совпадение по структурированным атрибутам, таким как местоположение, даты или идентификаторы
Когда пользователь вводит поисковую фразу, LLM сначала анализирует запрос, чтобы выделить конкретные атрибуты (например, местоположение) и сопоставить их с поисковыми значениями (например, «Northern Michigan» → «MI»). Затем эти извлеченные атрибуты используются как фильтры вместе с оценкой семантического сходства, что позволяет гарантировать, что результаты будут и концептуально релевантными, и точно соответствующими требованиям пользователя. В следующих таблицах показан упрощенный взгляд на поток семантического поиска с текстовыми описаниями отелей для контекста:
Данные в векторном хранилище:
| hotel-1 |
Description: Отель Artisan Loft занимает угол улиц Green и Randolph в оживленном Southwest Loop в Big City, располагаясь в тщательно отреставрированном кирпичном складе 1920-х годов, который подчеркивает индустриальное наследие района. Гости находятся всего в нескольких шагах от знаменитой Restaurant Row, а вокруг кварталов — признанные рестораны и модные бутики. Description Vector: […] Location: Big City, USA |
| hotel-2 |
Description: Расположенный на суровой скале с видом на драматическое побережье Big Sur, The Cypress Haven словно высечен из самой земли. Этот камерный приют на 42 номера органично вписывается в окружающий ландшафт благодаря живым зеленым крышам, панорамным окнам от пола до потолка и природным материалам, включая местный камень и переработанную древесину красного дерева. В каждом просторном номере есть приватная терраса, нависающая над Тихим океаном, где гости могут наблюдать за мигрирующими китами, погружаясь в ванны офуро из японского кедра. Description Vector: […] Location: Beach City, USA |
| hotel-3 |
Description: Спрятанный в многовековом кленовом лесу неподалеку от Berkshires, Woodland Haven Lodge предлагает камерный отдых, где роскошь сочетается с осознанной простотой. Этот переоборудованный особняк XIX века располагает 28 тщательно обустроенными номерами, размещенными в главном здании и четырех отдельных коттеджах, каждый из которых имеет веранды по периметру и окна от пола до потолка, открывающие вид на окружающий лес. Description Vector: […] Location: Quiet City, USA |
| hotel-4 |
Description: Расположенный в самом центре оживленного делового района Central City, отель Skyline Oasis является символом роскоши и современности. Эта 45-этажная стеклянно-стальная башня предлагает захватывающие панорамные виды на знаковый городской горизонт и расположенную неподалеку реку Central River. Отель с 500 элегантно оформленными номерами и люксами ориентирован как на деловых путешественников, так и на туристов, ищущих премиальный городской опыт. В отеле есть бассейн-инфинити на крыше, ресторан, отмеченный звездой Michelin, и современный фитнес-центр. Его выгодное расположение позволяет гостям добраться пешком до главных достопримечательностей Central City, включая Museum of Modern Art, Central City Opera House и оживленный район Riverfront District. Description Vector: […] Location: Central City, USA |
| Search Phrase | Ищу отель у океана |
| Search Results | hotel-2 |
Пример поиска:
- Поисковая фраза: «Ищу отель у океана»
- Результат семантического поиска: hotel-2 (The Cypress Haven)
Пример гибридного поиска:
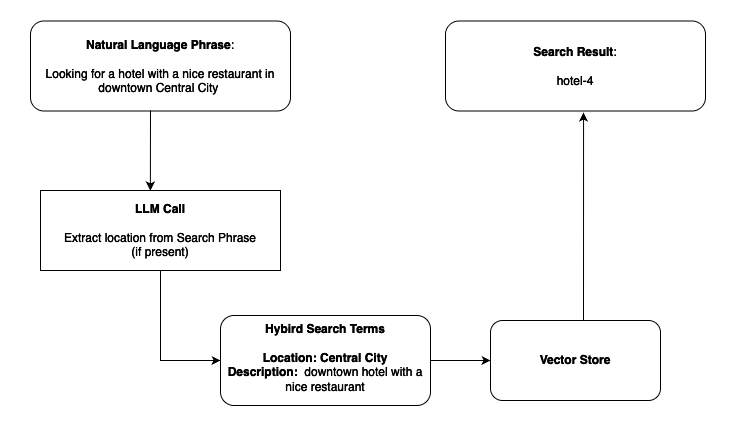
- Поисковая фраза: «Ищу отель с хорошим рестораном в центре Central City»
- Результат гибридного поиска: hotel-4 (лучшее соответствие с учетом и семантической релевантности, и точного местоположения)
Подробнее о реализациях гибридного поиска см. в публикации в блоге Amazon Bedrock Knowledge Bases о гибридном поиске.
Предлагаем агентное решение
Рассмотрим сценарий поиска отелей, где у пользователей могут быть разные потребности. Один пользователь может спросить: «найди мне уютный отель», и здесь требуется семантическое понимание слова «уютный». Другой может попросить: «найди отели в Майами», и тогда нужно точное фильтрование по местоположению. Третий может захотеть «роскошный отель на берегу в Майами», что требует одновременного применения обоих подходов. Традиционные RAG-реализации с фиксированными рабочими процессами не могут динамически адаптироваться к таким разным требованиям. В нашем сценарии нужна собственная логика поиска, которая может объединять несколько источников данных и динамически адаптировать стратегии извлечения информации в зависимости от характеристик запроса. Агентный подход обеспечивает такую гибкость. Сам LLM определяет оптимальную стратегию поиска, анализируя каждый запрос и выбирая подходящие инструменты.
Зачем нужны агенты?
Агентные системы обладают более высокой адаптивностью, поскольку LLM определяет последовательность действий, необходимых для решения задачи, обеспечивая динамическую маршрутизацию решений, интеллектуальный выбор инструментов и контроль качества через самооценку. В следующих разделах показано, как реализовать генеративного AI-ассистента с агентной логикой, который использует и семантический, и текстовый поиск с Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents и Amazon OpenSearch.
Обзор архитектуры
На рисунке 1 показана современная бессерверная архитектура, которую можно использовать для интеллектуального поискового ассистента. Она объединяет foundation models в Amazon Bedrock, Amazon Bedrock AgentCore (для оркестрации агента) и Amazon OpenSearch Serverless (для возможностей гибридного поиска).
Слой взаимодействия с клиентом
Клиентские приложения взаимодействуют с системой через Amazon API Gateway, который обеспечивает безопасную и масштабируемую точку входа для запросов пользователей. Когда пользователь задает вопрос вроде «Найди мне отель у пляжа в Northern Michigan», запрос проходит через API Gateway в Amazon Bedrock AgentCore.
Оркестрация агента с Amazon Bedrock AgentCore
Amazon Bedrock AgentCore служит движком оркестрации, управляющим полным жизненным циклом агента и координирующим взаимодействие между пользователем, LLM и доступными инструментами. AgentCore реализует agentic loop — непрерывный цикл рассуждения, действия и наблюдения, в котором агент:
- Анализирует запрос пользователя с помощью foundation models в Bedrock
- Решает, какие инструменты вызывать в зависимости от требований запроса
- Выполняет соответствующий инструмент гибридного поиска с извлеченными параметрами
- Оценивает результаты и определяет, нужны ли дополнительные действия
- Отвечает пользователю на основе синтезированной информации
На протяжении всего процесса Amazon Bedrock Guardrails обеспечивают безопасность контента и соблюдение политик, поддерживая корректные ответы.
Гибридный поиск с OpenSearch Serverless
Архитектура использует Amazon OpenSearch Serverless как векторное хранилище и поисковый движок. OpenSearch хранит как векторизованные эмбеддинги (для семантического понимания), так и структурированные текстовые поля (для точной фильтрации). Этот подход поддерживает нашу стратегию гибридного поиска. Когда агент вызывает инструмент гибридного поиска, OpenSearch выполняет запросы, которые объединяют:
- Семантическое сопоставление с использованием векторного сходства для концептуального понимания
- Текстовую фильтрацию для точных ограничений, таких как местоположение или удобства
Мониторинг и безопасность
Архитектура включает Amazon CloudWatch для мониторинга производительности системы и паттернов использования. AWS IAM управляет контролем доступа и политиками безопасности во всех компонентах.
Почему именно такая архитектура?
Эта бессерверная схема дает несколько ключевых преимуществ:
- Низкая задержка ответов для интерактивных разговоров в реальном времени
- Автомасштабирование для обработки переменных нагрузок без ручного вмешательства
- Экономичность благодаря оплате по мере использования без простаивающей инфраструктуры
- Готовность к production благодаря встроенным возможностям мониторинга, логирования и безопасности
Сочетание возможностей оркестрации AgentCore с гибридным поиском OpenSearch позволяет нашему ассистенту динамически адаптировать стратегию поиска в зависимости от намерения пользователя — то, чего не могут добиться жестко заданные RAG-пайплайны.
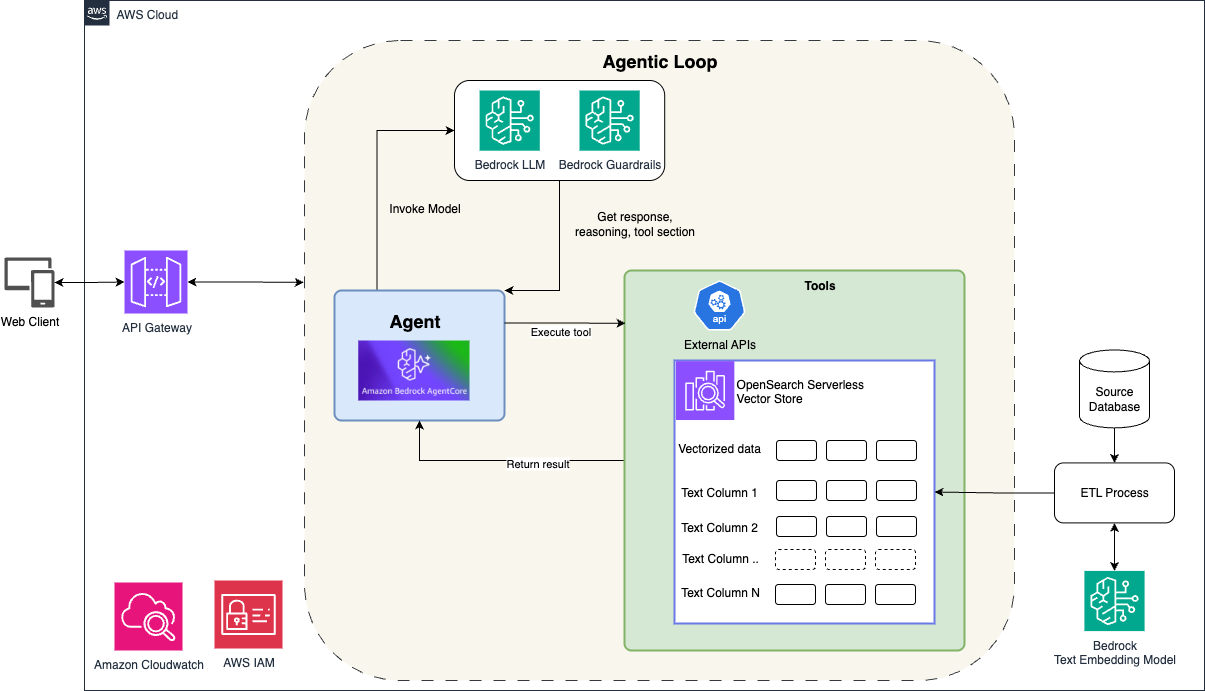
Рисунок 1
Примечание к рисунку: кодовые примеры и архитектурные артефакты, приведенные в этом документе, предназначены только для демонстрации и справки и не готовы к использованию в production.
Реализация с помощью Strands и Amazon Bedrock AgentCore
Чтобы построить нашего агентного помощника для гибридного поиска, мы используем Strands — open-source фреймворк для AI-агентов, который упрощает разработку приложений на базе LLM с возможностями вызова инструментов. Strands позволяет определить нашу функцию гибридного поиска как «инструмент», который агент может интеллектуально вызывать на основе пользовательских запросов. Подробности об архитектуре и паттернах Strands см. в документации Strands.
Вот как мы определяем инструмент гибридного поиска:
from strands import tool
@tool
def hybrid_search(query_text: str, country: str = None, city: str = None):
"""
Выполняет гибридный поиск, сочетающий семантическое понимание с фильтрацией по местоположению.
Агент вызывает это, когда пользователи указывают и описательные предпочтения, и местоположение.
Args:
query_text: Естественно-языковое описание того, что нужно искать
country: Необязательный фильтр по стране
city: Необязательный фильтр по городу
"""
# Генерация эмбеддингов для семантического поиска
vector = generate_embeddings(query_text)
# Построение гибридного запроса, объединяющего векторное сходство и текстовые фильтры
query = {
"bool": {
"must": [
{"knn": {"embedding_field": {"vector": vector, "k": 10}}}
],
"filter": []
}
}
# Добавление фильтров по местоположению, если они указаны
if country:
query["bool"]["filter"].append({"term": {"country": country}})
if city:
query["bool"]["filter"].append({"term": {"city": city}})
# Выполнение поиска в OpenSearch
response = opensearch_client.search(index="hotels", body=query)
return format_results(response)
После определения инструментов мы интегрируем их с Amazon Bedrock AgentCore для развертывания и оркестрации во время выполнения. Amazon Bedrock AgentCore позволяет безопасно развертывать и эксплуатировать высокоэффективных агентов в масштабе с использованием любого фреймворка и любой модели. Он предоставляет специально созданную инфраструктуру для безопасного масштабирования агентов и средства управления для работы с заслуживающими доверия агентами.
Для подробной информации об интеграции Strands с Amazon Bedrock AgentCore см. руководство по интеграции AgentCore и Strands.
Подробный разбор реализации гибридного поиска
Ключевое отличие нашего AI-ассистента — это его продвинутая возможность гибридного поиска. В то время как многие реализации RAG опираются только на семантический поиск, наша архитектура идет дальше. Мы использовали весь потенциал OpenSearch, обеспечив семантический, текстовый и гибридный поиск в рамках одного эффективного запроса. В следующих разделах рассматриваются технические детали этой реализации.
Реализация в два направления
Наша реализация гибридного поиска строится на двух фундаментальных компонентах: оптимизированном хранении данных и универсальной обработке запросов.
1. Оптимизированное хранение данных
Подход к хранению данных важен для эффективного гибридного поиска.
- Классификация данных: Мы систематически делим данные на два основных типа:
- кандидаты для семантического поиска: сюда входят подробные описания, контексты и пояснения — контент, для которого важно понимание смысла за пределами ключевых слов;
- кандидаты для текстового поиска: это метаданные, идентификаторы товаров, даты и другие структурированные поля.
- Векторное представление: Для семантических данных мы используем embedding-модели AWS Bedrock. Они преобразуют текст в высокоразмерные векторы, эффективно передающие семантический смысл.
- Оптимизация текстовых данных: Текстовые данные хранятся в исходном формате и оптимизированы для быстрых традиционных запросов.
- Единая структура индекса: Наш индекс OpenSearch спроектирован так, чтобы одновременно поддерживать и векторные эмбеддинги, и текстовые поля, обеспечивая гибкие возможности запросов.
2. Универсальная поисковая функциональность
На основе оптимизированного хранения данных мы разработали полноценную поисковую функцию, которую AI-агент может эффективно использовать:
- Адаптивные типы поиска: Наша поисковая функция умеет выполнять семантический, текстовый или гибридный поиск в зависимости от потребностей агента.
- Реализация семантического поиска: Для запросов, ориентированных на смысл, мы генерируем эмбеддинги запроса с помощью Amazon Bedrock и выполняем k-NN (k-Nearest Neighbors) поиск в векторном пространстве.
- Возможности текстового поиска: Когда требуется точное совпадение, мы используем мощные текстовые функции запросов OpenSearch, включая точное и нечеткое сопоставление.
- Выполнение гибридного поиска: Здесь мы объединяем векторное сходство с текстовым сопоставлением в единый запрос. Используя bool-запрос OpenSearch, мы можем при необходимости настраивать баланс между семантической и текстовой релевантностью.
- Интеграция результатов: Независимо от типа поиска, система объединяет и ранжирует результаты на основе общей релевантности, сочетая семантическое понимание с точным текстовым сопоставлением.
Справочный псевдокод реализации гибридного поиска:
def hybrid_search(query_text, country, city, search_type="hybrid"):
"""
Гибридный поиск, сочетающий семантический и текстовый поиск с фильтрацией по местоположению
"""
# 1. Генерация эмбеддингов для семантического поиска
if search_type in ["semantic", "hybrid"]:
vector = generate_embeddings(query_text)
# 2. Построение поискового запроса в зависимости от типа
if search_type == "semantic":
query = build_semantic_query(vector)
elif search_type == "text":
query = build_text_query(country, city)
else: # hybrid search
query = build_hybrid_query(vector, country, city)
# 3. Выполнение поиска
response = search_opensearch(query)
# 4. Обработка и возврат результатов
return format_results(response)
# Пример использования:
results = hybrid_search(
query_text="luxury hotel",
country="USA",
city="Miami"
)
OpenSearch поддерживает несколько типов запросов, включая текстовый поиск, векторный поиск (knn) и гибридные подходы, объединяющие оба метода. За подробностями о доступных типах запросов и их реализации обратитесь к документации по запросам OpenSearch.
Значимость гибридного подхода
Гибридный подход значительно расширяет возможности нашего AI-ассистента:
- Он поддерживает высокоточное извлечение информации, учитывая и контекст, и содержание.
- Он адаптируется к различным типам запросов, сохраняя стабильную производительность.
- Он дает более релевантные и полные ответы на запросы пользователей.
В области поиска на базе ИИ наш гибридный подход представляет собой значительный шаг вперед. Он обеспечивает уровень гибкости и точности, который заметно улучшает способность ассистента эффективно извлекать и обрабатывать информацию.
Реальные сценарии применения
К числу сценариев, где гибридный поиск может быть полезен, относятся, например:
- Недвижимость: поиск объектов, сочетающий понимание предпочтений образа жизни («подходит для семьи») с точной фильтрацией по локации и удобствам.
- Юридические и профессиональные услуги: исследование судебной практики, объединяющее концептуальное сходство правовых вопросов с точной фильтрацией по юрисдикции и дате для всестороннего юридического исследования.
- Здравоохранение и медицина: команды ухода спрашивают о «пациентах с хроническими состояниями, требующих схожих протоколов лечения, как у John Doe» — здесь сочетаются семантическое понимание сложности лечения и точное сопоставление медицинских записей.
- Медиа и развлечения: система поиска контента, объединяющая точную фильтрацию по жанру с семантическим пониманием сюжета.
- Электронная коммерция и розница: поиск товаров на естественном языке с точностью фильтров — запрос «удобная зимняя обувь» находит семантически близкие совпадения с применением точных фильтров по размеру, цене или бренду.
Эти сценарии показывают, как гибридный поиск сокращает разрыв между пониманием естественного языка и точной фильтрацией данных, делая поиск более интуитивным и точным.
Заключение
Интеграция Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents и Amazon OpenSearch Serverless представляет собой значительный шаг вперед в создании интеллектуальных поисковых приложений, которые сочетают мощь LLM с продвинутыми техниками извлечения информации. Эта архитектура объединяет семантический, текстовый и гибридный поиск, чтобы выдавать более точные и контекстно релевантные результаты, чем традиционные подходы. Используя агентную систему на базе Amazon Bedrock AgentCore, управление состоянием и абстракции инструментов Strands, разработчики могут создавать динамичных разговорных AI-ассистентов, которые интеллектуально определяют наиболее подходящие стратегии поиска на основе запросов пользователей. Подход гибридного поиска, сочетающий векторное сходство с точным текстовым сопоставлением, обеспечивает гибкость и точность извлечения информации, позволяя AI-системам лучше понимать намерение пользователя и давать более полные ответы. По мере того как организации продолжают создавать AI-решения, эта архитектура предоставляет масштабируемую и безопасную основу, использующую весь потенциал сервисов AWS и при этом сохраняющую необходимую адаптивность для сложных реальных задач.
Материал — перевод статьи с английского.
Оригинал: Building Intelligent Search with Amazon Bedrock and Amazon OpenSearch for hybrid RAG solutions