Формат: Новость
Коротко
В материале AWS рассказывается, как с помощью Serverless model customization в Amazon SageMaker AI дообучить модель Qwen 2.5 7B Instruct для вызова инструментов. Это перевод и адаптация англоязычного материала: авторы показывают, как RLVR помогает снизить галлюцинации инструментов, ошибки в параметрах и лишние действия агента.

Ключевые тезисы
- AWS использовала Reinforcement Learning with Verifiable Rewards (RLVR) для дообучения Qwen 2.5 7B Instruct под вызов инструментов.
- Подготовили 1 500 синтетических JSONL-примеров под три поведения агента: выполнение, уточнение и отказ.
- Reward function строили с многоуровневой оценкой, а обучение велось через GRPO.
- Финальная модель дала на 57% более высокий reward по tool calling, чем базовая модель, на сценариях вне обучающей выборки.
- SageMaker AI берёт на себя инфраструктуру, а также поддерживает разные семейства моделей и техники дообучения.
Детали
Это перевод и адаптация англоязычного материала AWS.
В статье AWS объясняет, почему агентный tool calling критически важен для production-систем: агенты запрашивают базы данных, запускают рабочие процессы, получают данные в реальном времени и действуют от имени пользователя. При этом базовые модели нередко «галлюцинируют» инструменты, передают неверные параметры или пытаются выполнить действие там, где нужно сначала уточнение.
AWS предлагает решать эту задачу через Serverless model customization в Amazon SageMaker AI. Такой подход позволяет дообучать модель без управления инфраструктурой, а для задач с проверяемым результатом особенно хорошо подходит RLVR — Reinforcement Learning with Verifiable Rewards.
Почему RLVR подходит для вызова инструментов
Для tool calling есть понятная проверяемая цель: модель либо вызвала правильную функцию с правильными параметрами, либо нет. Поэтому задача хорошо ложится на RLVR.
В отличие от классического самообслуживаемого reinforcement learning, где приходится отдельно решать вопросы с GPU, памятью, инфраструктурой reward-сигналов и checkpointing, в SageMaker AI эта операционная сложность скрыта за сервисом. Пользователь выбирает модель, технику, данные и функцию вознаграждения, а остальное делает платформа.
Также SageMaker AI поддерживает семейства моделей Amazon Nova, GPT-OSS, Llama, Qwen и DeepSeek, а среди техник доступны SFT, DPO, RLVR и RLAIF. Метрики обучения и валидации отслеживаются через интегрированный MLflow.
Как обучали Qwen 2.5 7B Instruct
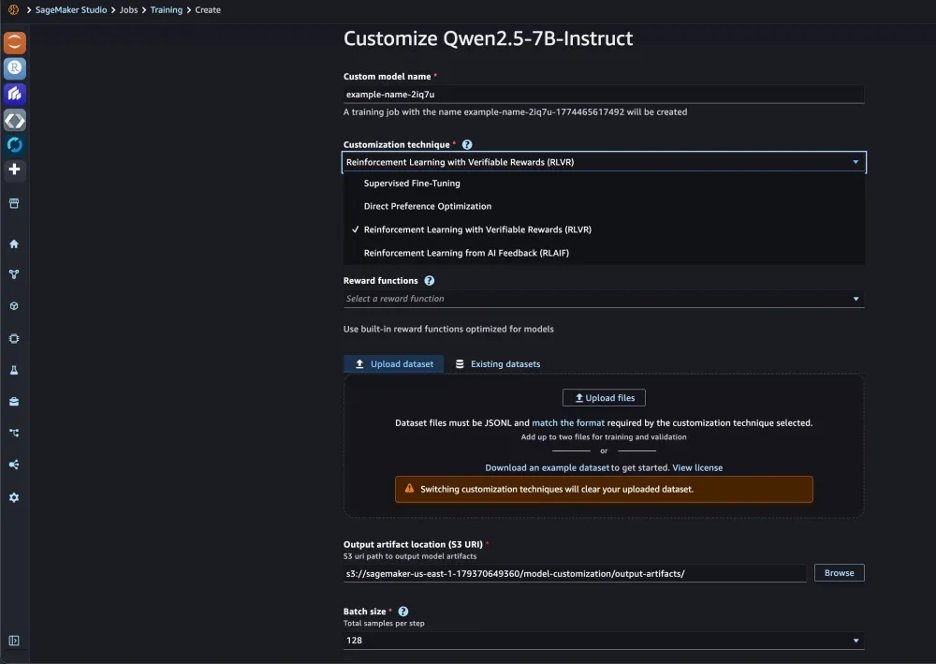
В материале авторы показывают пример дообучения Qwen 2.5 7B Instruct для tool calling. Для запуска в SageMaker AI Studio нужно выбрать нужную foundation model, открыть интерфейс Customize with UI и указать технику, данные для обучения и reward function.
Для такой задачи недостаточно просто показать модели правильные вызовы API. В production-агентах есть три разных сценария поведения: execute — когда у пользователя есть все нужные параметры; clarify — когда нужно уточнение; refuse — когда запрос вредоносный или выходит за рамки области применения.
Чтобы покрыть эти случаи, AWS сгенерировала 1 500 синтетических тренировочных примеров на основе схем инструментов: weather, flights, translation, currency conversion и statistics. Для генерации использовали Kiro, IDE от Amazon с ИИ-функциями.
Пример структуры данных
Каждая строка должна быть валидной JSONL-записью в формате: prompt с ролями system и user, а также reward_model с ground_truth.
В выборке распределение было таким: 60% примеров на выполнение действия, 25% — на уточнение, 15% — на вежливый отказ. Формулировки варьировались от формальных до кратких и разговорных.
Как работает обучение
RLVR работает иначе, чем SFT. Для каждого промпта модель генерирует несколько кандидатных ответов — в статье используется восемь. Затем reward function проверяет, какие ответы корректны.
Дальше модель обновляет политику так, чтобы чаще выбирать удачные варианты. В этом процессе используется Group Relative Policy Optimization (GRPO): он сравнивает оценку каждого ответа со средним значением в группе и усиливает ответы, которые набрали выше среднего.
По мере обучения модель лучше усваивает не только формат tool call, но и момент, когда нужно вызывать инструмент, а когда — задавать уточняющий вопрос.
Результаты и выводы
AWS оценила модель на отложенных данных, включая сценарии с незнакомыми инструментами. По итогам fine-tuning модель показала улучшение reward по tool calling на 57% по сравнению с базовой моделью на сценариях, которых не было в обучении.
Авторы подчёркивают, что такой путь особенно полезен командам, у которых пока нет достаточного объёма production-логов для обучения. Если реальные пользовательские запросы и tool calls уже есть, они могут дать ещё более качественные данные для дообучения.
Материал в целом показывает практический сценарий: SageMaker AI берёт на себя инфраструктурную часть, а команде остаётся сосредоточиться на модели, данных и reward function.
Оригинал на английском: Accelerate agentic tool calling with serverless model customization in Amazon SageMaker AI
Telegram-канал: https://t.me/no_glam_AI