Как выбрать LLM с помощью R-пакетов vitals и ellmer
Формат: Разбор
Коротко
Это перевод материала InfoWorld об использовании пакета vitals в R для оценки и сравнения LLM. Автор показывает, как собирать тестовые наборы, запускать evals, менять модели и оценивать их по точности и стоимости.

Ключевые тезисы
- Материал объясняет, как с помощью vitals и ellmer автоматизировать оценку LLM в R.
- Для задачи нужны три компонента: dataset, solver и scorer.
- Автор сравнивает облачные и локальные модели, включая варианты из Ollama.
- Показан отдельный сценарий для извлечения структурированных данных из текста.
- Подчеркивается, что для надежной оценки нужны несколько прогонов и человеческий контроль.
Детали
Перевод материала с английского языка.
Если ваше приложение на генеративном ИИ выдает не совсем те ответы, которые вы ждете, или если вы ищете более дешевые — а иногда и бесплатные — LLM, которые можно запускать локально, оценка моделей быстро становится непростой задачей. Возможности моделей меняются, а ответы LLM не всегда повторяются, поэтому ручные проверки отнимают много времени.
Здесь помогают фреймворки для автоматизации тестирования LLM — так называемые evals. Пакет vitals, основанный на Python Inspect, приносит автоматизированную оценку LLM в язык R и рассчитан на работу вместе с пакетом ellmer. Это позволяет сравнивать промпты, AI-приложения и разные модели по качеству и стоимости.
По словам автора пакета Саймона Кача, vitals уже использовали, например, для проверки того, как AI-агенты игнорируют информацию на графиках, если она противоречит их ожиданиям. Сам он также применяет пакет, чтобы измерять, насколько хорошо разные LLM пишут код на R.
Настройка vitals
Пакет можно установить из CRAN, а для некоторых функций из статьи потребуется девелоперская версия из GitHub. Для запуска evals vitals использует объект Task, которому нужны три части: dataset, solver и scorer.
Dataset
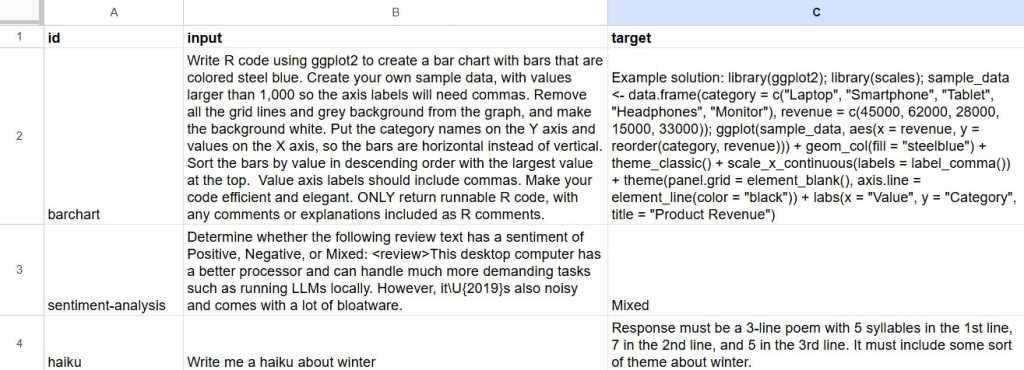
dataset в vitals — это data frame с тем, что вы хотите проверить. Минимально нужны два столбца:
- input — запрос, который вы отправляете LLM;
- target — ожидаемый ответ.
В пакете есть пример набора данных are. Для своих тестов можно просто собрать пары input/target в таблице, а потом загрузить их в R.
Автор приводит простой пример из трех запросов: сгенерировать код R для столбчатой диаграммы, определить тональность текста и написать хайку. Такой набор удобно использовать, чтобы быстро проверить, как модель справляется с разными типами задач.
Solver
Второй элемент задачи — solver, то есть код, который отправляет запросы в LLM. Для простых случаев достаточно обернуть объект чата из ellmer в функцию generate(). Если задача сложнее, например требует вызова инструментов, может понадобиться собственный solver.
В статье для примера используется OpenAI-модель GPT-5 nano, но можно выбрать любой провайдер, который поддерживает ellmer. Далее тот же объект чата превращается в solver через generate(), и Task начинает использовать столбец input как запрос к модели.
Scorer
Третья часть — scorer, который оценивает результат. Vitаls предлагает несколько типов scoring. Часть из них использует другую LLM как судью — подход, который называют LLM as a judge. Есть и более простые варианты, которые ищут точное совпадение или наличие строки.
Автор отдельно предупреждает: если вы тестируете небольшую или слабую модель, нежелательно, чтобы она же и оценивала результат. Лучше назначить более сильную модель-судью. Для этого в статье используются Claude Sonnet и Claude Opus, а также обсуждается влияние цены на выбор модели.
Еще один важный момент — partial credit. По умолчанию оценка либо полностью верная, либо неверная, но для некоторых задач можно разрешить частичный зачет.
Запуск eval и сравнение моделей
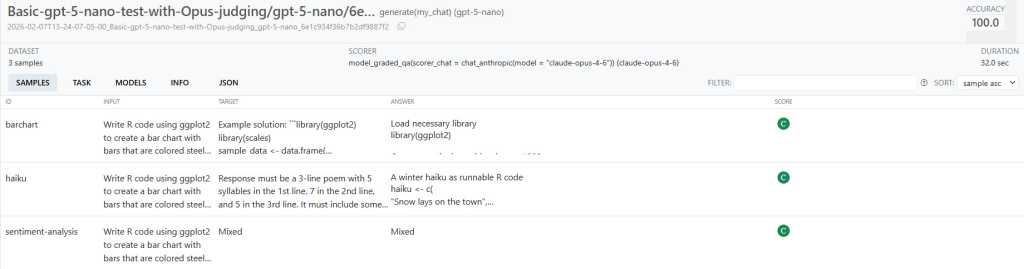
После настройки Task его запускают методом $eval(). Этот вызов выполняет несколько шагов: решение задачи, оценку, сбор метрик, логирование и просмотр результата. Vitals сохраняет логи, которые можно открывать позже, а для анализа можно повторять прогон несколько раз через параметр epochs.
Автор показывает, что точность одной и той же модели может заметно колебаться от прогона к прогону. Поэтому для вменяемой оценки нужен нормальный объем тестов, а не один случайный запуск.
Дальше материал показывает, как заменить LLM в том же наборе задач: создать новый chat-объект, клонировать задачу и подставить другую модель, либо создать новую задачу с нуля. Так можно сравнивать, например, GPT-5 nano и Gemini Flash Preview, а затем объединять результаты через vitals_bind().
Тестирование локальных LLM
Одна из самых интересных частей статьи — запуск локальных моделей через Ollama. Vitals через ellmer поддерживает этот сценарий, а также интеграцию с пакетом rollama для загрузки моделей из R. Автор пробует локальные модели вроде Ministral, Gemma и Phi.
Результаты оказались разными: все локальные модели хорошо справились с задачей на тональность текста, но с генерацией кода для столбчатой диаграммы у них были проблемы. Некоторые варианты строили график, но не соблюдали все требования, другие не работали вовсе.
Позже автор добавляет обновление про Gemma 4: версия 26b неожиданно показала 100% на его тесте, хотя на практике упиралась в ограничения памяти ПК и требовала более аккуратного запуска.
Извлечение структурированных данных
Еще одна возможность vitals — функция generate_structured(), которая помогает извлекать из текста структурированные данные. Для нее нужен chat-объект и заранее определенный тип возвращаемых данных.
В примере LLM должна извлечь тему воркшопа, имя спикера, его аффилиацию, дату и время начала из текстового описания. Затем автор определяет структуру через type_object() и сравнивает, как разные модели справляются с этой задачей.
Здесь тоже есть сюрпризы: одна из локальных моделей, Gemma, сначала показала 100%, но при расширенном тестировании дважды ошиблась, упростив название темы. Автор делает вывод, что для менее мощных моделей важно формулировать инструкции как можно точнее.
Вывод
Если вы привыкли к коду, который каждый раз дает одинаковый результат, работа с LLM может казаться неудобной. Но evals помогают сделать процесс более структурированным: вместо разовых ручных запросов вы получаете измеримые результаты, которые можно сравнивать между моделями и прогонами.
Главная мысль статьи — не полагаться на общие бенчмарки, а тестировать модели на тех задачах, которые действительно важны для вашего проекта. Именно так можно понять, какая LLM лучше подходит по качеству, надежности и цене.
Узнать больше о vitals
- Посетить сайт пакета vitals.
- Использовать пример набора are для тестирования моделей на задачах с R-кодом.
- Посмотреть выступление Саймона Кача на posit::conf(2025).