Гибридный RAG-поиск на Amazon Bedrock и Amazon OpenSearch для агентных ИИ-ассистентов
Формат: Разбор
Коротко
Это перевод материала с английского языка от AWS о том, как строить интеллектуальный поиск для агентных ИИ-ассистентов. Авторы объясняют, почему одной семантической выдачи недостаточно, и показывают, как сочетать семантический и текстовый поиск в hybrid RAG-сценариях.

Ключевые тезисы
- Материал посвящён архитектуре агентного ИИ-ассистента, который получает данные из backend-систем в реальном времени.
- Семантический поиск помогает находить результаты по смыслу, но может проигрывать в точном атрибутном фильтре, например по локации.
- Гибридный поиск объединяет смысловой и лексический подходы, чтобы повысить релевантность выдачи.
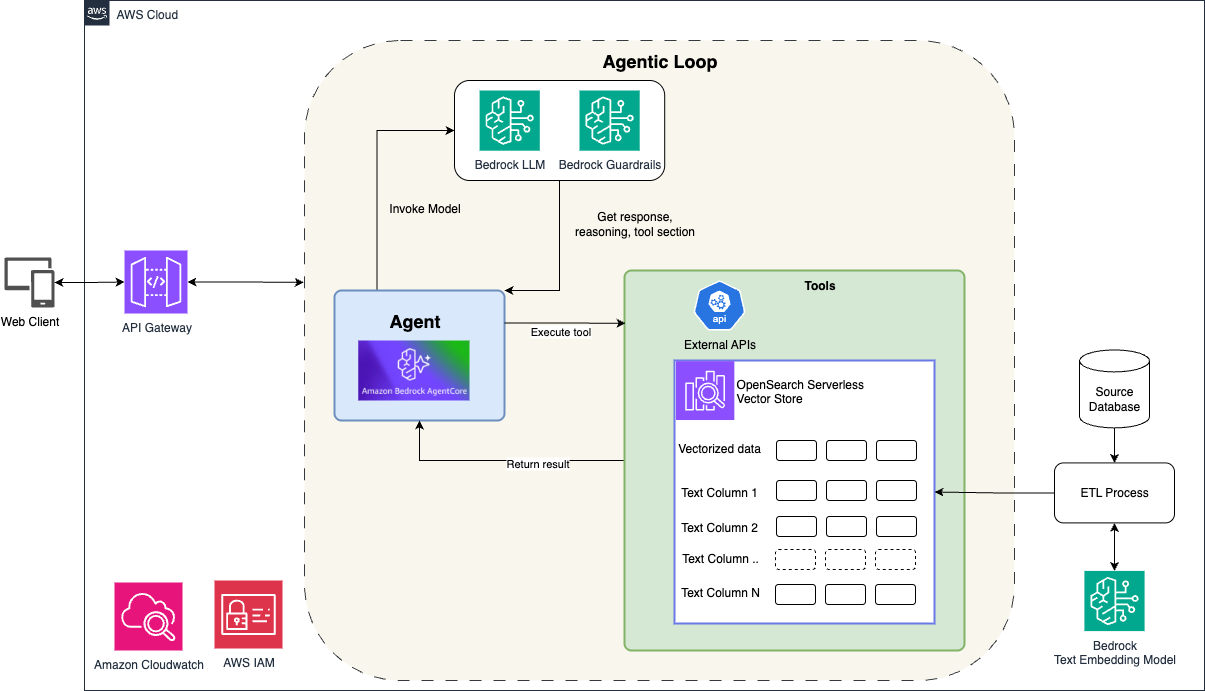
- В примере AWS рассматривает использование Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents и Amazon OpenSearch.
- Публикация носит технический характер и объясняет принципы построения RAG-решений, а не сообщает о запуске продукта.
Детали
Это перевод материала с английского языка от AWS. В статье рассматривается, как строить агентного генеративного ИИ-ассистента, который использует и семантический, и текстовый поиск на базе Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents и Amazon OpenSearch.
Авторы начинают с общего объяснения RAG-подхода: ассистент в реальном времени обращается к API и базам данных, чтобы подмешивать актуальные бизнес-данные в ответ модели. Такой подход особенно полезен там, где пользователю нужна не только генерация текста, но и точная, свежая информация из backend-систем.
Зачем нужен семантический поиск
Семантический поиск ищет не по точному совпадению ключевых слов, а по смыслу запроса. Для этого документы и запросы заранее преобразуются в векторы, а затем система находит наиболее близкие по метрике расстояния совпадения.
Такой метод хорошо работает, когда пользователь формулирует запрос естественным языком и точные ключевые слова могут отсутствовать. Например, если в наборе данных есть записи вроде «building materials», «plumbing supplies» и «2×2 multiplication result», запрос «2×4 lumber board» с высокой вероятностью вернёт «building materials».
Авторы подчёркивают, что семантический поиск особенно удобен в связке с LLM-ассистентами: модель формулирует запрос на естественном языке, а поисковый слой находит данные по смыслу этого запроса.
Почему одного семантического поиска недостаточно
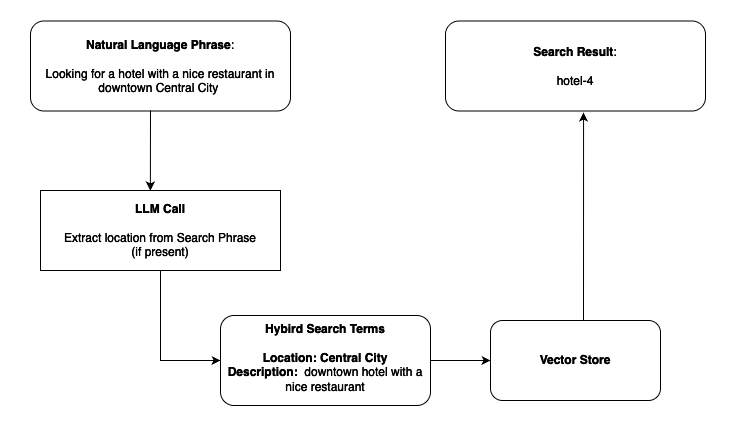
Проблема в том, что семантическая релевантность не всегда совпадает с точными бизнес-ограничениями. В примерe с поиском отеля запрос «роскошный отель с видом на океан в Майами, Флорида» может вернуть очень подходящие по смыслу варианты, но не обязательно именно в Майами.
Семантический поиск лучше улавливает понятия вроде «роскошный» и «вид на океан», но хуже справляется с жёсткой фильтрацией по конкретному месту. Если пользователю важны и смысл, и точные атрибуты, одного семантического подхода недостаточно.
Что даёт hybrid search
Именно для таких случаев нужен гибридный поиск. Он объединяет семантическое понимание запроса с лексическим или текстовым поиском, чтобы одновременно учитывать смысл и точные совпадения по ключевым словам и атрибутам.
В результате система лучше подходит для агентных сценариев, где ассистенту нужно и понимать намерение пользователя, и находить данные по строгим бизнес-ограничениям. В статье AWS этот подход рассматривается как основа для более точных hybrid RAG-решений.
Контекст статьи
Материал сфокусирован на архитектурном подходе и объяснении принципов, а не на новостном анонсе. AWS показывает, как совмещать возможности LLM, real-time retrieval и гибридного поиска в одном агентном решении.
Гибридный поиск сочетает семантическое понимание и точную текстовую выдачу, чтобы агентный ассистент мог отвечать и естественно, и корректно с точки зрения бизнес-данных.
Оригинал: Building Intelligent Search with Amazon Bedrock and Amazon OpenSearch for hybrid RAG solutions