AWS представила AWS Generative AI Model Agility Solution для миграции LLM в production генеративного ИИ
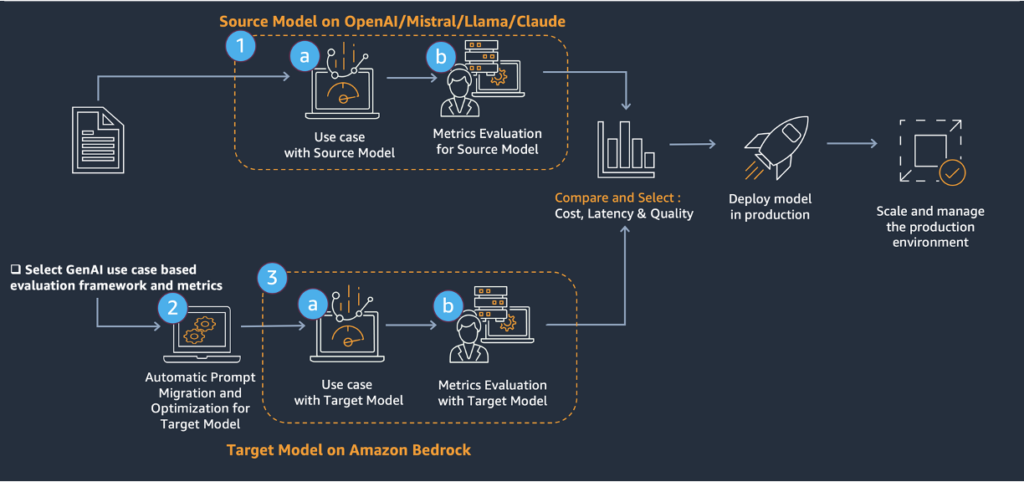
Поддержание гибкости моделей критически важно для организаций, которые хотят адаптироваться к технологическим изменениям и оптимизировать свои решения на основе искусственного интеллекта (AI). При переходе между разными семействами больших языковых моделей (LLM) или при обновлении до новых версий внутри одного семейства необходимы структурированный подход к миграции и стандартизованный процесс, чтобы обеспечивать непрерывное улучшение качества при минимальных перебоях в работе. Однако создание такого решения сложно как с технической, так и с нетехнической стороны, потому что оно должно:
- быть универсальным и покрывать широкий спектр сценариев использования
- быть достаточно конкретным, чтобы новый пользователь мог применить его к своему сценарию
- обеспечивать всестороннее и справедливое сравнение LLM
- быть автоматизированным и масштабируемым
- включать доменные и прикладные знания и входные данные
- иметь четкий сквозной процесс — от подготовки данных до финальных критериев успешности
В этом посте мы представляем системный фреймворк для миграции или обновления LLM в production генеративного ИИ, включающий необходимые инструменты, методологии и best practices. Фреймворк упрощает переходы между разными LLM за счет надежных протоколов для преобразования и оптимизации prompt. Он также включает механизмы оценки нескольких измерений качества, позволяя принимать решения на основе данных через детальный сравнительный анализ исходной и целевой моделей. Предлагаемый подход — это комплексное решение, которое охватывает технические аспекты миграции модели и предоставляет количественные метрики для подтверждения успешного перехода и выявления зон дальнейшей оптимизации, обеспечивая бесшовную миграцию и непрерывное улучшение. Вот несколько ключевых возможностей решения:
- Предоставляет различные варианты отчетности с использованием разных фреймворков оценки LLM и подробные рекомендации по выбору метрик для целевых сценариев.
- Предоставляет автоматизированную оптимизацию и миграцию prompt с помощью Amazon Bedrock Prompt Optimization и Anthropic Metaprompt tool, а также best practices для дальнейшей оптимизации prompt.
- Предоставляет подробные рекомендации по выбору модели и сквозное решение для сравнения моделей по стоимости, задержке, точности и качеству.
- Предоставляет примеры функций и сценариев использования, чтобы пользователи могли быстро адаптировать решение под свой кейс.
- Общее время, необходимое для миграции или обновления LLM по этому фреймворку, составляет от двух дней до двух недель в зависимости от сложности сценария.
Обзор решения
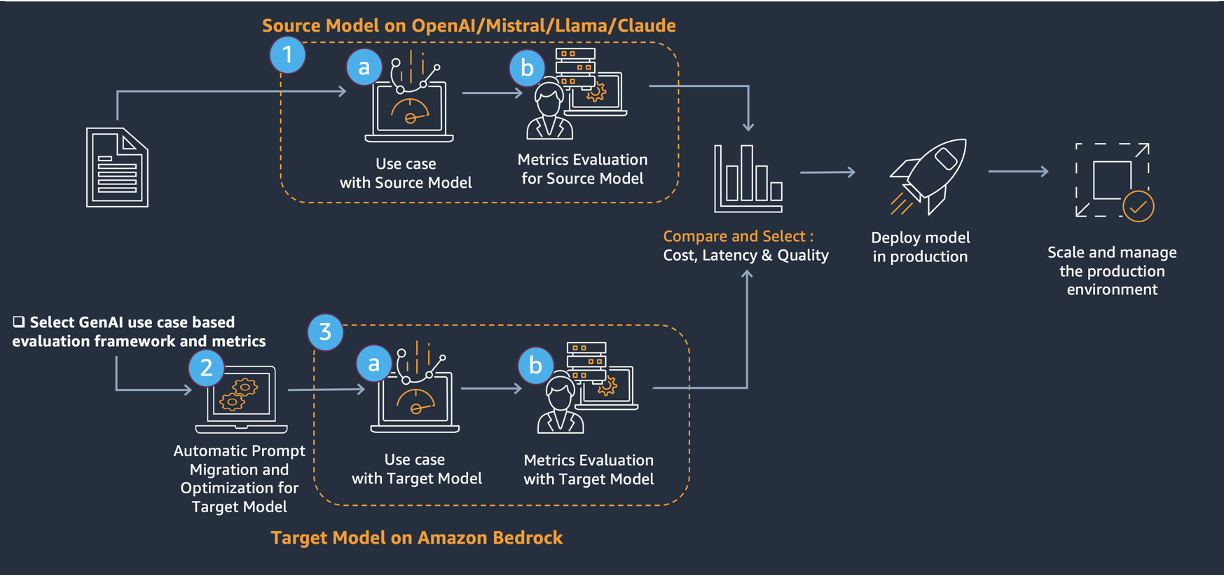
В основе миграции лежит трехэтапный подход, показанный на предыдущей диаграмме.
- Оценка исходной модели.
- Миграция prompt и оптимизация целевой модели с помощью Amazon Bedrock prompt optimization и Anthropic Metaprompt tool.
- Оценка целевой модели.
Это решение предлагает комплексный подход к обновлению существующих generative AI решений (source model) до LLM в Amazon Bedrock (target model). Технические задачи здесь решаются за счет:
- выбора метрик оценки с использованием фреймворка, работающего с разными LLM
- улучшения и миграции prompt с помощью Amazon Bedrock Prompt Optimization и Anthropic Metaprompt tool
- сравнения моделей по стоимости, задержке и производительности
Такой структурированный подход создает надежную основу для оценки, миграции и оптимизации LLM. Следуя этим шагам, можно переходить между моделями, потенциально повышая производительность, экономичность и функциональные возможности AI-приложений. Процесс делает акцент на тщательной подготовке, системной оценке и непрерывном улучшении, закладывая основу для долгосрочного успеха при работе с продвинутыми языковыми моделями.
Реализация решения
Подготовка набора данных
Набор данных для оценки с качественными примерами критически важен для процесса миграции. Для большинства сценариев требуются примеры с эталонными ответами; для других сценариев можно использовать метрики, не требующие ground truth, — такие как answer relevancy, faithfulness, toxicity и bias (см. раздел Оценка фреймворков и выбор метрик) — в качестве метрик определения. Используйте следующие рекомендации и формат данных для подготовки примеров под целевые сценарии.
Рекомендуемые поля для sample data включают:
- Prompt, использованный для исходной модели
- Вход prompt (если есть), например вопросы и контекст для генерации ответа на основе Retrieval-Augmented Generation (RAG)
- Конфигурации, использованные при вызове исходной модели, например temperature, top_p, top_k и так далее
- Ground truths
- Выход исходной модели
- Задержка исходной модели
- Входные и выходные tokens исходной модели, которые можно использовать для расчета стоимости
Важно помнить, что качественные ground truths необходимы для успешной миграции в большинстве случаев. Ground truths должны проверяться не только на корректность, но и на соответствие рекомендациям subject matter expert (SME) и критериям оценки. См. раздел Анализ ошибок как пример рекомендаций и критериев оценки SME.
Кроме того, если доступны существующие метрики оценки, такие как человеческая оценка или thumbs up/thumbs down от SME, включайте эти метрики и соответствующие обоснования или комментарии для каждого примера данных. Если выполнялись автоматические оценки, включайте оценки, методы и конфигурации. Следующий раздел содержит более подробные рекомендации по выбору фреймворков оценки и определению метрик. Однако по-прежнему полезно собрать существующие или предпочтительные метрики оценки у заинтересованных сторон для справки.
При необходимости включите следующие поля:
- Существующие человеческие метрики оценки для исходной модели, например SME score для исходной модели.
- Существующие автоматические метрики оценки для исходной модели, например LLM-as-a-judge score для исходной модели.
Ниже приведен пример формата sample data:
| sample_id | … |
| question | |
| content | |
| prompt_source_llm | |
| answer_ground_truth | |
| answer_ source_llm | |
| latency_ source_llm | |
| input_token_source_llm | |
| output_token_source_llm | |
| llm_judge_score_source_llm | |
| human_score_source_llm | |
| human_score_reasoning_source_llm |
Оценка фреймворков и выбор метрик
После сбора информации и примеров данных следующим шагом является выбор подходящих метрик оценки для сценария генеративного ИИ. Помимо человеческой оценки со стороны SME, рекомендуются автоматические метрики, потому что они более масштабируемы, объективны и поддерживают долгосрочное здоровье и устойчивость продукта. Следующая таблица показывает автоматические метрики, доступные для каждого сценария использования.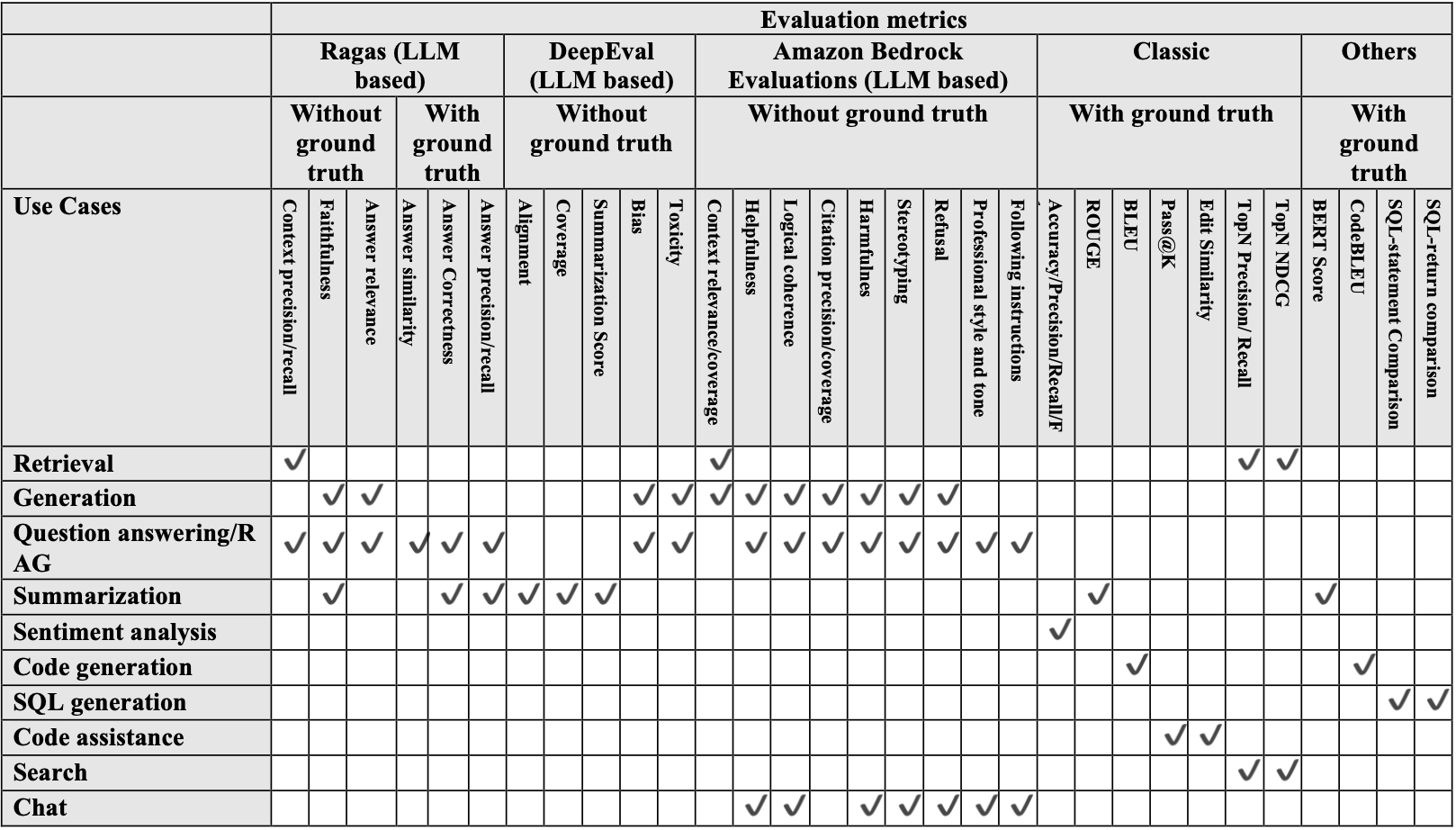
Выбор модели
Выбор подходящей LLM требует внимательного учета нескольких факторов. Независимо от того, идет ли миграция на LLM в пределах того же семейства или на модель из другого семейства, понимание ключевых характеристик каждой модели и критериев оценки критически важно для успеха. При планировании миграции между LLM тщательно сравнивайте и оценивайте доступные варианты и изучайте model card и соответствующие prompting guides, опубликованные каждым поставщиком модели. При оценке вариантов LLM учитывайте несколько ключевых критериев:
- Модальности входа и выхода: текст, код и multimodal-возможности
- Размер context window: максимальное число input tokens, которое модель может обработать
- Стоимость одного inference или token
- Метрики производительности: latency и throughput
- Качество и точность выхода
- Доменная специализация и соответствие конкретному сценарию использования
- Варианты размещения: cloud, on-premises и hybrid
- Требования к конфиденциальности и безопасности данных
После первичной фильтрации по этим характеристикам следует провести benchmarking-тесты, оценивая производительность на конкретных задачах, чтобы сравнить отобранные модели. Amazon Bedrock предлагает комплексное решение с доступом к различным LLM через единый API. Это позволяет экспериментировать с разными моделями, сравнивать их производительность и даже использовать несколько моделей параллельно, сохраняя при этом единую точку интеграции. Такой подход не только упрощает техническую реализацию, но и помогает избежать vendor lock-in, позволяя строить диверсифицированную стратегию AI-моделей.
Миграция prompt
Здесь представлены два автоматизированных инструмента миграции и оптимизации prompt: Amazon Bedrock Prompt Optimization и Anthropic Metaprompt tool.
Amazon Bedrock Prompt Optimization
Вариант A) Оптимизация prompt из Amazon Bedrock Console
- В Amazon Bedrock console перейдите в Prompt management.
- Выберите Create prompt, задайте имя для шаблона prompt и нажмите Create.
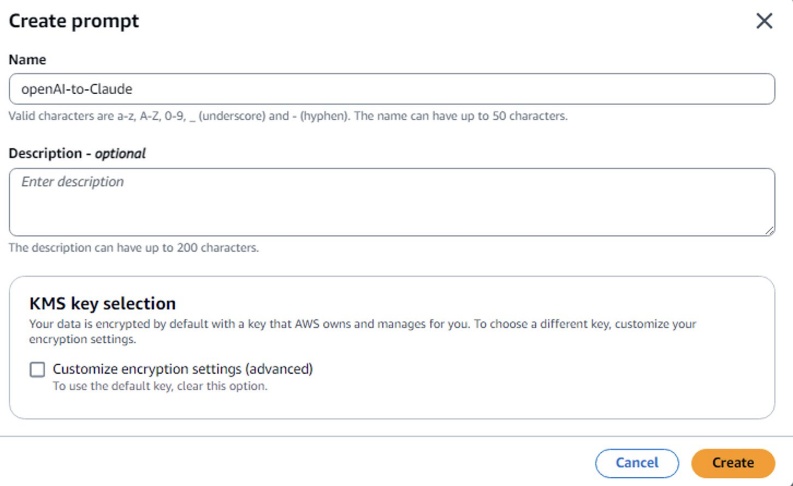
- Введите prompt исходной модели. Создайте переменные, заключая имя в двойные фигурные скобки:
{{variable}}. В разделе Test variables укажите значения, которые будут подставляться при тестировании. - Выберите Target Model for your optimized prompt. Например, Anthropic Claude Sonnet 4.
- Нажмите кнопку Optimize, чтобы сгенерировать оптимизированный prompt для целевой модели.

6. После генерации prompt отображается окно сравнения оптимизированного prompt для целевой модели с исходным prompt source model.
7. Сохраните новый оптимизированный prompt перед выходом из режима сравнения.
Вариант B) Оптимизация prompt через Amazon Bedrock API
Можно также использовать Bedrock API для генерации мигрированного prompt, отправив OptimizePrompt request к Agents for Amazon Bedrock runtime endpoint. Передайте prompt, который нужно оптимизировать, в объекте input и укажите модель, для которой выполняется оптимизация, в поле targetModelId.
Поток ответа возвращает следующие события:
- analyzePromptEvent — появляется, когда анализ prompt завершен. Содержит сообщение с описанием анализа prompt.
- optimizedPromptEvent — появляется, когда переписывание prompt завершено. Содержит оптимизированный prompt.
Запустите следующий пример кода, чтобы оптимизировать prompt:
import boto3
# Set values here
TARGET_MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0" # Model to optimize for. For model IDs, see https://docs.aws.amazon.com/bedrock/latest/userguide/model-ids.html
PROMPT = "Please summarize this text: " # Prompt to optimize
def get_input(prompt):
return {
"textPrompt": {
"text": prompt
}
}
def handle_response_stream(response):
try:
event_stream = response['optimizedPrompt']
for event in event_stream:
if 'optimizedPromptEvent' in event:
print("========================== OPTIMIZED PROMPT ======================\n")
optimized_prompt = event['optimizedPromptEvent']
print(optimized_prompt)
else:
print("========================= ANALYZE PROMPT =======================\n")
analyze_prompt = event['analyzePromptEvent']
print(analyze_prompt)
except Exception as e:
raise e
if __name__ == '__main__':
client = boto3.client('bedrock-agent-runtime')
try:
response = client.optimize_prompt(
input=get_input(PROMPT),
targetModelId=TARGET_MODEL_ID
)
print("Request ID:", response.get("ResponseMetadata").get("RequestId"))
print("========================== INPUT PROMPT ======================\n")
print(PROMPT)
handle_response_stream(response)
except Exception as e:
raise e
Anthropic Metaprompt tool
Metaprompt — это инструмент оптимизации prompt от Anthropic, где Claude получает задачу написать шаблоны prompt от имени пользователя на основе темы или задачи. Его можно использовать, чтобы попросить Claude наиболее эффективно сформировать prompt для последовательного и точного достижения заданной цели.
Ключевые шаги:
- Укажите исходный шаблон prompt, опишите задачу и перечислите входные переменные и ожидаемый выход.
- Запустите Metaprompt с Claude LLM, например Claude-3-Sonnet, передав raw prompt из source model.
- Новый шаблон prompt будет сгенерирован с оптимизированным набором инструкций и форматом, соответствующим best practices Claude LLM.
Преимущества использования metaprompts:
- Prompt становятся значительно более подробными и полными по сравнению с созданными человеком
- Это повышает вероятность соблюдения best practices при работе с моделями Anthropic
- Позволяет указывать важные детали, например предпочитаемый тон
- Улучшает качество и согласованность ответов модели
Metaprompt tool особенно полезен для изучения предпочтительного стиля prompt у Claude или как способ сгенерировать несколько версий prompt для одной задачи, упрощая тестирование различных начальных вариантов prompt для целевого сценария.
Чтобы реализовать этот процесс, следуйте шагам в Prompt Migration Jupyter Notebook, чтобы перенести prompts source model в prompts target model. В этом notebook должен быть включен Claude-3-Sonnet как LLM в Amazon Bedrock через Model Access для генерации конвертированных prompt.
Ниже приведен один пример prompt source model для сценария финансовых Q&A:
To answer the financial question, think step-by-step:
1. Carefully read the question and any provided context paragraphs related to yearly and quarterly document reports to find all relevant paragraphs. Prioritize context paragraphs with CSV tables.
2. If needed, analyze financial trends and quarter-over-quarter (Q/Q) performance over the detected time spans mentioned in the related time keywords. Calculate rates of change between quarters to identify growth or decline.
3. Perform any required calculations to get the final answer, such as sums or divisions. Show the math steps.
4. Provide a complete, correct answer based on the given information. If information is missing, state what is needed to answer the question fully.
5. Present numerical values in rounded format using easy-to-read units.
6. Do not preface the answer with "Based on the provided context" or anything similar. Just provide the answer directly.
7. Include the answer with relevant and exhaustive information across all contexts. Substantiate your answer with explanations grounded in the provided context. Conclude with a precise, concise, honest, and to-the-point answer.
8. Add the page source and number.
9. Add all source files from where the contexts were used to generate the answers.
context = {CONTEXT}
query = {QUERY}
rephrased_query = {REPHARSED_QUERY}
time_kwds = {TIME_KWDS}
После выполнения шагов в notebook мы можем автоматически получить оптимизированный prompt для целевой модели. Следующий пример генерирует prompt, оптимизированный для Claude LLM от Anthropic.
Here are the steps to answer the financial question:
1. Read the provided <context>{$CONTEXT}</context> carefully, paying close attention to any paragraphs and CSV tables related to yearly and quarterly financial reports. Prioritize context paragraphs containing CSV tables.
2. Identify the relevant time periods mentioned in the <time_kwds>{$TIME_KWDS}</time_kwds>. Analyze the financial trends and quarter-over-quarter (Q/Q) performance during those time spans. Calculate rates of change between quarters to determine growth or decline.
3. <scratchpad>
In this space, you can perform any necessary calculations to arrive at the final answer to the <query>{$QUERY}</query> or <rephrasedquery>{$REPHARSED_QUERY}</rephrasedquery>. Show your step-by-step work, including formulas used and intermediate values.
</scratchpad>
4. <answer>
Provide a complete and correct answer based on the information given in the context. If any crucial information is missing to fully answer the question, state what additional details are needed.
Present numerical values in an easy-to-understand format using appropriate units. Round numbers as necessary.
Do not include any preamble like "Based on the provided context..." Just provide the direct answer.
Include all relevant and exhaustive information from the contexts to substantiate your answer. Explain your reasoning grounded in the provided evidence. Conclude with a precise, concise, honest, and to-the-point final answer.
Finally, cite the page source and number, as well as list all files that contained context used to generate this answer.
</answer>
Как показано в предыдущем примере, стиль и формат prompt автоматически преобразуются в соответствии с best practices целевой модели, например с использованием XML-тегов и перегруппировкой инструкций, чтобы они были более понятными и прямыми.
Генерация результатов
Генерация ответа во время миграции — это итеративный процесс. Общий поток включает передачу migrated prompt и контекста в LLM и генерацию ответа. Нужны несколько итераций, чтобы сравнить разные версии prompt, несколько LLM и разные конфигурации каждой LLM, помогая выбрать лучшую комбинацию. В большинстве случаев не мигрируется весь pipeline generative AI-системы, например RAG-based chatbot. Вместо этого мигрируется только часть pipeline. Поэтому крайне важно, чтобы оставалась доступной фиксированная версия остальных компонентов pipeline. Например, в RAG-based question and answer (Q&A) системе можно мигрировать только компонент генерации ответа в pipeline. В результате можно продолжать использовать уже сгенерированный контекст существующей production-модели.
В качестве best practice используйте стандартный метод вызова Amazon Bedrock models (в Migration code repository) для генерации метаданных, таких как latency, time to first token, input token и output token, в дополнение к финальному ответу. Эти поля метаданных добавляются как новый столбец в конце таблицы результатов и используются для оценки. Формат вывода и имя столбца должны соответствовать требованиям к метрикам оценки. Следующая таблица показывает пример sample data перед передачей в evaluation pipeline для RAG-сценария.
Пример sample data до оценки:
| financebench_id | financebench_id_03029 |
| doc_name | 3M_2018_10K |
| doc_link | https://investors.3m.com/financials/sec-filings/content/0001558370-19-000470/0001558370-19-000470.pdf |
| doc_period | 2018 |
| question_type | metrics-generated |
| question | What is the FY2018 capital expenditure amount (in USD millions) for 3M? Give a response to the question by relying on the details shown in the cash flow statement. |
| ground_truths | [‘$1577.00’] |
| evidence_text | … |
| page_number | 60 |
| llm_answer | According to the cash flow statement in the 3M 2018 10-K report, the capital expenditure (purchases of property, plant and equipment) for fiscal year |
| llm_contexts | … |
| latency_meta_time | 0.92706 |
| latency_meta_kwd | 0.60666 |
| latency_meta_comb | 1.44876 |
| latency_meta_ans_gen | 2.48371 |
| input_tokens | 21147 |
| output_tokens | 401 |
Оценка
Оценка — одна из важнейших частей процесса миграции, потому что она напрямую связана с критериями sign-off и определяет успех миграции. Для большинства случаев оценка сосредоточена на метриках в трех основных категориях: точность и качество, задержка и стоимость. Для оценки точности и качества ответа модели можно использовать либо автоматическую, либо человеческую оценку.
Автоматическая оценка
Интеграция LLM в процесс оценки качества представляет собой значительный шаг вперед в методологии измерения. Эти модели хорошо подходят для комплексной оценки по нескольким измерениям, включая релевантность контекста, связность и фактическую точность, сохраняя при этом согласованность и масштабируемость. Здесь представлены две основные категории автоматических метрик оценки:
- Предопределенные метрики: метрики, заранее определенные в LLM-based evaluation frameworks, таких как Ragas, DeepEval и Amazon Bedrock Evaluations, или напрямую основанные на non-LLM algorithms, как описано в Оценка фреймворков.
- Пользовательские метрики: настраиваемые метрики с определениями, критериями оценки или prompt, предоставленными пользователем, для использования LLM как impartial judge.
Предопределенные метрики
Эти метрики используют либо LLM-based evaluation frameworks, такие как Ragas и DeepEval, либо напрямую основаны на non-LLM algorithms. Они широко применяются, заранее определены и имеют ограниченные возможности настройки. Ragas и DeepEval — это два LLM-based evaluation frameworks и набора метрик, которые мы использовали в качестве примеров в Migration code repository.
- Ragas: Ragas — это open source framework, который помогает оценивать RAG pipeline. RAG обозначает класс LLM-приложений, использующих внешние данные для расширения контекста LLM. Он предоставляет набор автоматических метрик оценки на основе LLM. Следующие метрики представлены в Ragas evaluation notebook в Migration code repository.
- Answer precision: измеряет, насколько точно сгенерированный ответ модели содержит релевантные и корректные утверждения по сравнению с ground truth answer.
- Answer recall: оценивает полноту ответа; то есть способность модели извлекать корректные утверждения и сравнивать их с ground truth answer. Высокий recall означает, что ответ подробно покрывает необходимые детали в соответствии с ground truth.
- Answer correctness: оценка правильности ответа заключается в измерении точности сгенерированного ответа по сравнению с ground truth. Эта оценка опирается на
ground truthиanswer, а оценки находятся в диапазоне от 0 до 1. Более высокий балл означает более близкое соответствие сгенерированного ответа ground truth, то есть лучшую правильность. - Answer similarity: оценка семантического сходства между сгенерированным ответом и ground truth. Эта оценка основана на
ground truthиanswer, а значения лежат в диапазоне от 0 до 1. Более высокий балл означает лучшее соответствие сгенерированного ответа ground truth.
Ниже приведена таблица с sample data output после оценки Ragas.
| financebench_id | financebench_id_03029 |
| doc_name | 3M_2018_10K |
| doc_link | https://investors.3m.com/financials/sec-filings/content/0001558370-19-000470/0001558370-19-000470.pdf |
| doc_period | 2018 |
| question_type | metrics-generated |
| question | What is the FY2018 capital expenditure amount (in USD millions) for 3M?. |
| ground_truths | [‘$1577.00’] |
| evidence_text | … |
| page_number | 60 |
| llm_answer | According to the cash flow statement in the 3M 2018 10-K report, the capital expenditure (purchases of property, plant and equipment) for fiscal year 2018 was $1,577 million. … |
| llm_contexts | … |
| latency_meta_time | 0.92706 |
| latency_meta_kwd | 0.60666 |
| latency_meta_comb | 1.44876 |
| latency_meta_ans_gen | 2.48371 |
| input_tokens | 21147 |
| output_tokens | 401 |
| answer_precision | 0 |
| answer_recall | 1 |
| answer_correctness | 0.16818 |
| answer_similarity | 0.33635 |
- DeepEval: DeepEval — это open source LLM evaluation framework. Он похож на Pytest, но специализирован на unit testing LLM outputs. DeepEval использует последние исследования для оценки LLM outputs на основе таких метрик, как G-Eval, hallucination, answer relevancy, Ragas и так далее. Он использует LLM и различные другие NLP models, которые запускаются локально на вашей машине для оценки. В DeepEval метрика служит стандартом измерения для оценки производительности LLM output по заданным критериям. DeepEval предлагает набор стандартных метрик, чтобы быстро начать работу. Следующие метрики представлены в DeepEval evaluation notebook в Migration code repository.|
- Answer relevancy: эта метрика измеряет качество generator в вашем RAG pipeline, оценивая, насколько релевантен
actual_outputвашего LLM-приложения по сравнению с предоставленным input. - Faithfulness: эта метрика измеряет качество generator в вашем RAG pipeline, оценивая, фактически ли
actual_outputсоответствует содержимому вашегоretrieval_context. - Toxicity: еще одна referenceless-метрика, оценивающая токсичность в LLM outputs.
- Bias: метрика, определяющая, содержит ли output гендерную, расовую или политическую предвзятость.
- Answer relevancy: эта метрика измеряет качество generator в вашем RAG pipeline, оценивая, насколько релевантен
- Amazon Bedrock Evaluations: Amazon Bedrock Evaluations — это набор инструментов для оценки, сравнения и выбора foundation models, включая собственные или сторонние модели, под ваши сценарии использования. Он поддерживает оценку как model-only, так и RAG pipelines. Bedrock Evaluations можно использовать через AWS console или API. Amazon Bedrock Evaluations предлагает обширный список встроенных метрик как для отдельных LLM, так и для полных RAG pipelines, включая, но не ограничиваясь:
- Accuracy: измеряет корректность выходов модели.
- Faithfulness: проверяет фактическую точность и предотвращает галлюцинации.
- Helpfulness: оценивает, насколько ответы полезны при ответе на вопросы.
- Logical coherence: оценивает, свободны ли ответы от логических пробелов, несоответствий или противоречий.
- Harmfulness: измеряет вредоносный контент в ответах, включая ненависть, оскорбления, насилие или сексуальный контент.
- Stereotyping: измеряет обобщающие высказывания о людях или группах людей в ответах.
- Refusal: измеряет, насколько уклончиво модель отвечает на вопросы.
- Following instructions: измеряет, насколько ответ модели соответствует точным инструкциям из prompt.
- Professional style and tone: измеряет, насколько стиль, форматирование и тон ответа подходят для профессиональной среды.
Пользовательские метрики
Эти метрики задаются пользователем и обычно настраиваются под конкретные задачи или домены. Один из популярных методов — использовать custom LLM as a judge, чтобы получить оценку ответа по пользовательскому prompt. В отличие от предопределенных метрик, этот метод очень гибкий, потому что можно задавать prompt с требованиями к оценке, специфичными для задачи. Например, можно попросить LLM создать 10-балльную шкалу и всесторонне оценить ответ по ground truth по разным измерениям, таким как корректность информации, релевантность контексту, глубина и полнота деталей, а также общая полезность.
Ниже приведен пример пользовательского prompt для LLM as a judge:
#Prompt:
System: "You are an AI evaluator that helps in evaluating output from LLM",
resp_fmt = """{
"score":float,
"reasoning": str
}
"""
User = f"""[Instruction]\nPlease act as an impartial judge and evaluate the quality of the response
provided by an AI assistant to the user question displayed below. Your evaluation should consider correctness,
relevance, level of detail and helpfulness. You will be given a reference answer and the assistant's answer.
Begin your evaluation by comparing the assistant's answer with the reference answer. Identify any mistakes. Be as
objective as possible. After providing your explanation in the "reasoning" tab , you must score the response on a
scale of 1 to 10 in the "score" tab. Strictly follow the below json format:{resp_fmt}.
\n\n[Question]\n{question}\n\n[The Start of Reference Answer]\n{reference}\n[The End of Reference Answer]\n\n[The
Start of Assistant's Answer]\n{response}\n[The End of Assistant's Answer]"""
Человеческая оценка
Хотя количественные метрики дают ценные данные, также необходима комплексная качественная оценка на основе профессиональных guideline и feedback от SME для подтверждения производительности модели. Эффективная качественная оценка обычно охватывает несколько ключевых областей, включая согласованность темы и тона ответа, выявление неподобающего или нежелательного контента, точность в предметной области, вопросы дат и времени и так далее. Используя экспертизу SME, можно выявить тонкие нюансы и потенциальные проблемы, которые могут ускользнуть от количественного анализа. Анализ ошибок предлагает некоторые потенциальные аспекты, которые SME может использовать как критерии оценки, а также как guidance для проверки и подготовки ground truths. Для человеческой оценки можно использовать такие инструменты, как Amazon Bedrock Evaluations.
Хотя человеческая оценка или пользовательский feedback, собранный через UI, может напрямую отражать критерии оценки SME, это менее эффективно, масштабируемо и объективно, чем автоматические методы оценки. Поэтому жизненный цикл разработки generative AI-системы может начинаться с человеческой оценки, но в итоге переходить к автоматической. Человеческая оценка может использоваться, если автоматическая оценка не достигает базовых целевых значений или заранее определенных критериев.
Метрики задержки
При миграции языковых моделей runtime performance metrics являются важными индикаторами операционного успеха. Общая задержка и Time to first token (TTFT) — наиболее распространенные метрики для измерения latency.
- Total latency — это end-to-end метрика, которая измеряет общую длительность полного формирования ответа: от начального prompt до финального вывода. Она включает обработку входа, генерацию ответа и доставку пользователю. Total latency влияет на удовлетворенность пользователей, throughput системы и использование ресурсов.
- Time to first token (TTFT) измеряет скорость первоначального отклика — а именно время до генерации моделью первого выходного token. Эта метрика существенно влияет на воспринимаемую отзывчивость и пользовательский опыт, особенно в интерактивных приложениях. TTFT особенно важен в conversational AI и real-time системах (например, чат-ботах, виртуальных ассистентах и интерактивных поисковых системах), где пользователи ожидают немедленной реакции. Низкий TTFT создает впечатление отзывчивости системы и может значительно повысить вовлеченность пользователей.
Если шаг генерации результата требует нескольких вызовов LLM, необходимо указывать разбиение latency по этапам, потому что на следующем шаге сравнения моделей следует сопоставлять только latency подмодуля, связанного с миграцией LLM.
Расчет стоимости
Для вызова LLM стоимость можно рассчитать на основе количества входных и выходных tokens и соответствующей цены за token:
LLM_invocation_cost = number_of_input_tokens * price_per_input_token + number_of_output_tokens * price_per_output_token
Таблицу расчетов стоимости по цене за input и output token можно найти в Amazon Bedrock Pricing.
Отчет о сравнении моделей: производительность, задержка и стоимость
Мы можем использовать Generate Comparison Report notebook в code repository, чтобы автоматически создать финальный отчет сравнения source и target model в целостном виде.
Также можно использовать evaluation reports, созданные в Ragas и DeepEval с соответствующими метриками, чтобы сравнивать модели по двум фреймворкам оценки. Можно получить сравнение side-by-side по средним input и output tokens, а также по средней стоимости и задержке для выбранных моделей. Как показано на следующем рисунке, после запуска этого notebook появляются две сравнительные таблицы для source и target models из двух выбранных фреймворков оценки.
Ragas
DeepEval
Дальнейшая оптимизация
При улучшении и оптимизации production pipeline генеративного ИИ во время миграции или обновления LLM пользователи обычно сосредотачиваются на двух ключевых областях:
- Качество сгенерированных ответов
- Задержка генерации ответа
Оптимизация prompt
Чтобы оптимизировать качество сгенерированных ответов, нужно хорошо понимать ошибки, проводя анализ ошибок и определяя элементы для prompt optimization.
Анализ ошибок
Получить наилучший возможный ответ от candidate LLM без какой-либо оптимизации маловероятно. Поэтому проведение анализа ошибок и фокус на возможных паттернах ошибок помогает оценить качество сгенерированных ответов и выявить возможности для улучшения. Анализ ошибок также дает путь к ручному prompt engineering для улучшения качества. После сбора инсайтов анализа ошибок и feedback от SME можно проводить итеративный процесс оптимизации prompt. Для начала сформулируйте инсайты анализа ошибок и feedback от SME в виде четких рекомендаций или критериев. В идеале эти критерии должны быть определены до начала миграции prompt. Эти критерии служат основными ориентирами для дальнейшей оптимизации prompt, помогая обеспечивать стабильные, качественные ответы, соответствующие планке SME. Ниже приведен пример возможных рекомендаций и критериев, которые мы можем получить от SME.
Пример руководства по стилю форматирования ответа от SME в сценарии финансовых Q&A:
- Корректность
- Убедитесь, что извлеченные числа верны. Все числа должны совпадать с ground truth.
- Убедитесь, что все утверждения из ground truth присутствуют в ответе LLM.
- Сгенерированные ответы не должны добавлять нерелевантные предложения.
- Время
- Сгенерированные ответы должны корректно распознавать fiscal year и все необходимые quarters из вопроса.
- В ответе предпочтителен порядок quarters от самого позднего к самому раннему.
- Когда вопрос спрашивает о year-over-year, ответ должен указывать общий год или последний квартал, а не quarter-by-quarter.
- Когда ответ получен из одного новостного документа, включайте дату публикации в ответ.
- Тема и тон
- Используйте профессиональный язык, отражающий стиль газеты.
- Длина
- Большинство ответов должны быть в пределах 30–150 слов. Более длинные ответы допустимы, когда вопрос касается нескольких сущностей или требует подкатегорий в ответе.
Техники оптимизации
После получения четких критериев можно использовать несколько техник оптимизации, таких как:
- Prompt engineering для задания определенных критериев в инструкции prompt
- Few-shot learning для задания формата ответа и примеров сгенерированных ответов
- Включение метаинформации, которая помогает LLM понять контекст задачи и вопроса
- Пред- или постобработка для обеспечения формата вывода или устранения частых паттернов ошибок
Оптимизация задержки
Существует несколько возможных решений для оптимизации latency:
Оптимизация prompt для более коротких ответов
Latency модели LLM напрямую зависит от числа output tokens, поскольку каждый дополнительный token требует отдельного forward pass через модель, увеличивая время обработки. По мере генерации большего числа tokens latency растет, особенно в более крупных моделях, таких как Opus 4. Чтобы снизить latency, можно добавить в prompt инструкции избегать длинных ответов, нерелевантных объяснений или слов-паразитов.
Использование provisioned throughput
Throughput — это число и скорость входов и выходов, которые модель обрабатывает и возвращает. Покупка provisioned throughput для обеспечения более высокого throughput выделенной hosted model может потенциально снизить latency по сравнению с on-demand моделями. Хотя это не гарантирует улучшение latency, такой подход стабильно помогает предотвращать throttled requests.
Цикл улучшения
Маловероятно, что candidate LLM сможет достичь наилучшей возможной производительности без какой-либо оптимизации. Также обычно preceding optimization processes выполняются итеративно. Поэтому цикл улучшения (optimization) критически важен для повышения производительности и выявления пробелов или дефектов в pipeline или данных. Обычно цикл улучшения включает:
- Оптимизацию prompt
- Генерацию ответа
- Генерацию метрик оценки
- Анализ ошибок
- Проверку разметки примеров
- Обновление набора данных в части дефектов примеров и неверных labels
Определение знаний предметной области или задачи Процесс миграции, описанный в этом посте, можно использовать в двух фазах жизненного цикла production generative AI-решения.
Сквозная миграция LLM и гибкость моделей
Новые LLM выпускаются часто. Ни одна LLM не может стабильно сохранять пик производительности для конкретного сценария. Для production generative AI-решения обычно нормально перейти на другое семейство LLM или обновить версию модели. Поэтому наличие стандартного и повторно используемого сквозного процесса миграции или обновления LLM критически важно для долгосрочного успеха любого generative AI-решения.
Мониторинг и контроль качества
Когда миграция или обновления стабилизированы, должен быть стандартный процесс мониторинга и контроля качества с регулярно обновляемым golden evaluation dataset с ground truth и автоматическими или человеческими метриками оценки, а также с оценкой реальных пользовательских traces. В рамках этого решения установленные процессы оценки и сбора данных или ground truth можно повторно использовать для мониторинга и контроля качества.
Советы и рекомендации (выводы из практики)
Ниже приведены советы и рекомендации для успешной миграции или обновления LLM.
- Условие sign-off: данные, критерии оценки и критерии успешности, определенные в начале, должны быть достаточными для того, чтобы заинтересованные стороны могли уверенно утвердить процесс. В идеале в ходе процесса не должно быть изменений в данных, ground truths или критериях оценки и успешности SME.
- Sample data и качество: данные должны быть достаточно качественными и достаточными по объему для уверенной оценки. Ground truth ответы и labels должны полностью соответствовать критериям оценки и ожиданиям SME. В идеале в ходе процесса не должно быть изменений в данных, ground truths или критериях оценки SME.
- Цикл улучшения: обязательно спланируйте и внедрите цикл улучшения, чтобы извлечь максимум из выбранной LLM.
- Выбор модели: при выборе конкурирующих target models против source model используйте такие ресурсы, как сайт бенчмаркинга Artificial Analysis, чтобы получить целостное сравнение моделей. Такие сравнения обычно охватывают качество, производительность и цену, давая полезные ориентиры до начала эксперимента. Это предварительное исследование помогает сузить круг наиболее перспективных кандидатов и сформировать дизайн эксперимента.
- Баланс производительности и стоимости: при оценке разных моделей или решений важно учитывать баланс между производительностью и стоимостью. В некоторых случаях модель может показывать немного более низкую производительность, но при существенно меньшей стоимости оказаться в целом более выгодным вариантом. Это особенно актуально, когда разница в производительности минимальна, а экономия заметна.
- Техники оптимизации: изучение различных техник оптимизации, таких как prompt engineering или provisioned throughput, может существенно улучшить метрики производительности, например точность и latency. Эти оптимизации могут сократить разрыв между моделями и должны рассматриваться как часть процесса оценки.
Заключение
В этом посте мы представили AWS Generative AI Model Agility Solution — сквозное решение для миграции и обновления LLM в существующих generative AI-приложениях, которое поддерживает и улучшает гибкость моделей. Решение определяет стандартизованный процесс и предоставляет полноценный набор инструментов для миграции или обновления LLM с разнообразием готовых к использованию инструментов и продвинутых техник, которые можно применять для переноса generative AI-приложений на новые LLM. Его можно использовать как стандартный процесс в жизненном цикле ваших generative AI-приложений. После того как приложение стабилизировано на конкретной LLM и конфигурации, процессы оценки и сбора данных и ground truth, описанные в этом решении, можно повторно использовать для production monitoring и контроля качества.
Чтобы узнать больше об этом решении, ознакомьтесь с нашим AWS Generative AI Model Agility Code Repo.
Материал — перевод статьи с английского.