Reinforcement Fine-Tuning с LLM-as-a-judge для Amazon Nova: как построить reward-функции и обучающий workflow

Большие языковые модели (LLM) сегодня лежат в основе самых продвинутых разговорных агентов, креативных инструментов и систем поддержки принятия решений. Однако их «сырые» ответы нередко содержат неточности, несоответствия политикам или неудачные формулировки — проблемы, которые подрывают доверие и ограничивают практическую ценность. Reinforcement Fine-Tuning (RFT) стал предпочтительным методом эффективного выравнивания таких моделей, используя автоматизированные reward-сигналы вместо дорогостоящей ручной разметки.
В основе современного RFT лежат reward-функции. Их строят под каждую предметную область либо через проверяемые reward-функции, которые оценивают генерации LLM с помощью кода (Reinforcement Learning with Verifiable Rewards, RLVR), либо через LLM-as-a-judge, когда отдельная языковая модель оценивает кандидатные ответы и направляет выравнивание (Reinforcement Learning with AI Feedback, RLAIF). Оба подхода передают оценки в RL-алгоритм, чтобы подтолкнуть модель к решению поставленной задачи. В этой статье подробно рассматривается, как RLAIF, или RL с LLM-as-a-judge, эффективно работает с моделями Amazon Nova.
Почему RFT с LLM-as-a-judge лучше, чем обычный RFT?
Reinforcement Fine-Tuning может использовать любой reward-сигнал: простые ручные правила (RLVR) или LLM, который оценивает выход модели (LLM-as-a-judge, или RLAIF). RLAIF делает выравнивание гораздо более гибким и мощным, особенно когда reward-сигналы расплывчаты и их трудно вручную сформулировать. В отличие от типичных reward-оценок в RFT, которые опираются на грубый числовой скоринг вроде совпадения подстрок, LLM-judge рассуждает сразу по нескольким измерениям — корректность, тон, безопасность, релевантность — и дает контекстно-зависимую обратную связь, улавливающую тонкости и особенности предметной области без отдельного дообучения под задачу. Кроме того, LLM-judge предоставляет встроенную объяснимость через рационализации (например, «Ответ A ссылается на рецензируемые исследования»), что дает диагностику, ускоряет итерации, помогает точнее находить ошибки и уменьшает скрытые несоответствия — того, чего статические reward-функции сделать не могут.
Внедрение LLM-as-a-judge: шесть критически важных шагов
В этом разделе рассматриваются ключевые шаги, необходимые для проектирования и внедрения reward-функций на базе LLM-as-a-judge.
Выберите архитектуру судьи
Первое критически важное решение — выбор архитектуры судьи. LLM-as-a-judge предлагает два основных режима оценки: Rubric-based (point-based) judging и Preference-based judging; каждый подходит для разных сценариев выравнивания.
| Критерий | Rubric-based judging | Preference-based judging |
| Метод оценки | Присваивает числовую оценку одному ответу по заранее заданным критериям | Сравнивает два кандидатных ответа бок о бок и выбирает лучший |
| Измерение качества | Абсолютные измерения качества | Относительное качество через прямое сравнение |
| Когда предпочтительно использовать | Когда существуют четкие, измеримые измерения качества (точность, полнота, соблюдение требований безопасности) | Когда policy-модель должна свободно исследовать пространство ответов без ограничений со стороны эталонных данных |
| Требования к данным | Требуется только аккуратный prompt engineering, чтобы согласовать модель со спецификацией reward | Требуется как минимум один образец ответа для сравнения по предпочтениям |
| Обобщаемость | Лучше работает на данных вне распределения, снижает риск смещения данных | Зависит от качества эталонных ответов |
| Стиль оценки | Моделирует системы абсолютного скоринга | Моделирует естественную человеческую оценку через сравнение |
| Рекомендуемая стартовая точка | Начните отсюда, если данные предпочтений недоступны и RLVR не подходит | Используйте, когда доступны сравнительные данные |
Определите критерии оценки
После выбора типа судьи нужно четко сформулировать конкретные измерения, которые вы хотите улучшить. Ясные критерии оценки — основа эффективного обучения RLAIF.
Для судей Preference-based:
Пишите понятные prompts, объясняющие, что делает один ответ лучше другого. Четко задавайте предпочтения по качеству с конкретными примерами. Пример: «Предпочитайте ответы, которые ссылаются на авторитетные источники, используют доступный язык и прямо отвечают на вопрос пользователя.»
Для судей Rubric-based:
Для rubric-based судей мы рекомендуем использовать Boolean (pass/fail) скоринг. Boolean-оценка надежнее и снижает вариативность судьи по сравнению с тонкими шкалами 1–10. Для каждого измерения оценки определяйте четкие pass/fail-критерии с конкретными, наблюдаемыми признаками.
Выберите и настройте модель судьи
Выберите LLM с достаточной способностью к рассуждению, чтобы оценивать целевую предметную область, настройте ее через Amazon Bedrock и вызывайте с помощью reward AWS Lambda function. Для распространенных областей, таких как математика, кодинг и разговорные способности, более компактные модели могут работать хорошо при аккуратном prompt engineering.
| Класс модели | Предпочтительно для | Стоимость | Надежность | Модель Amazon Bedrock |
| Большая/тяжелая | Сложное рассуждение, нюансированная оценка, многомерный скоринг | Высокая | Очень высокая | Amazon Nova Pro, Claude Opus, Claude Sonnet |
| Средняя/легкая | Общие области вроде математики или кодинга, баланс стоимости и производительности | Низкая–средняя | Умеренно высокая | Amazon Nova 2 Lite, Claude Haiku |
Уточните prompt для модели судьи
Prompt судьи — основа качества выравнивания. Проектируйте его так, чтобы он выдавал структурированный, парсируемый вывод с понятными измерениями оценки:
- Структурированный формат вывода — укажите JSON или другой парсируемый формат для удобного извлечения
- Четкие правила оценки — определите, как именно рассчитывается каждый критерий
- Обработка крайних случаев — предусмотрите неоднозначные сценарии (например, «Если ответ пустой, присвойте 0»)
- Желаемое поведение — явно опишите действия, которые нужно поощрять или, наоборот, не поощрять
Согласуйте критерии судьи с продакшен-метриками
Reward-функция должна отражать метрики, по которым финальная модель будет оцениваться в production. Согласуйте reward-функцию с критериями успеха в production, чтобы модели оптимизировались под правильные цели.
Рабочий процесс согласования:
- Определите критерии успеха в production (например, точность, безопасность) с допустимыми порогами
- Сопоставьте каждый критерий с конкретными измерениями скоринга судьи
- Проверьте, что оценки судьи коррелируют с вашими метриками оценки
- Протестируйте судью на репрезентативных выборках и крайних случаях
Постройте надежную reward Lambda function
Production-RFT системы обрабатывают тысячи reward-оценок на каждый training step. Постройте устойчивую reward Lambda function, чтобы обеспечить стабильность обучения, эффективное использование вычислений и надежное поведение модели. В этом разделе описывается, как сделать reward Lambda function устойчивой, эффективной и готовой к production.
Структурирование составного reward-скора
Не полагайтесь только на LLM-judge. Комбинируйте его с быстрыми детерминированными reward-компонентами, которые отсекают очевидные ошибки до дорогой оценки судьей:
Основные компоненты
| Компонент | Назначение | Когда использовать |
| Корректность формата | Проверять JSON-структуру, обязательные поля, соответствие схеме | Всегда — мгновенно отсекает некорректные выходы. Дешевый и мгновенный фидбек. |
| Штрафы за длину | Сдерживать чрезмерно длинные или слишком краткие ответы | Когда длина ответа важна, например для summary |
| Согласованность языка | Проверять, что ответы совпадают с языком входа | Критично для многоязычных приложений |
| Фильтры безопасности | Правиловые проверки на запрещенный контент | Всегда — не допускают unsafe-контент в production |
Готовность инфраструктуры
- Реализуйте exponential backoff: он корректно обрабатывает rate limits Amazon Bedrock API и временные сбои
- Стратегия параллелизации: используйте ThreadPoolExecutor или async-подходы, чтобы параллелить вызовы судьи по rollout-ам и снижать задержку
- Избегайте задержек cold start в Lambda: задайте подходящий timeout Lambda (рекомендуется 15 минут) и provisioned concurrency (около 100 для типичной конфигурации)
- Обработка ошибок: добавьте полноценную обработку ошибок, которая возвращает нейтральные/шумные rewards (0.5) вместо падения всего training step
Проверьте устойчивость reward Lambda function
Проверьте согласованность и калибровку судьи:
- Согласованность: несколько раз прогоняйте одни и те же образцы через судью, чтобы измерить дисперсию оценок (для детерминированной оценки она должна быть низкой)
- Сравнение между судьями: сравнивайте оценки разных моделей-судей, чтобы выявить слепые зоны в оценке
- Человеческая калибровка: периодически отправляйте rollout-ы на ручную проверку, чтобы поймать drift судьи или систематические ошибки
- Регрессионное тестирование: создайте «набор тестов для судьи» с известными хорошими и плохими примерами, чтобы регрессионно проверять его поведение
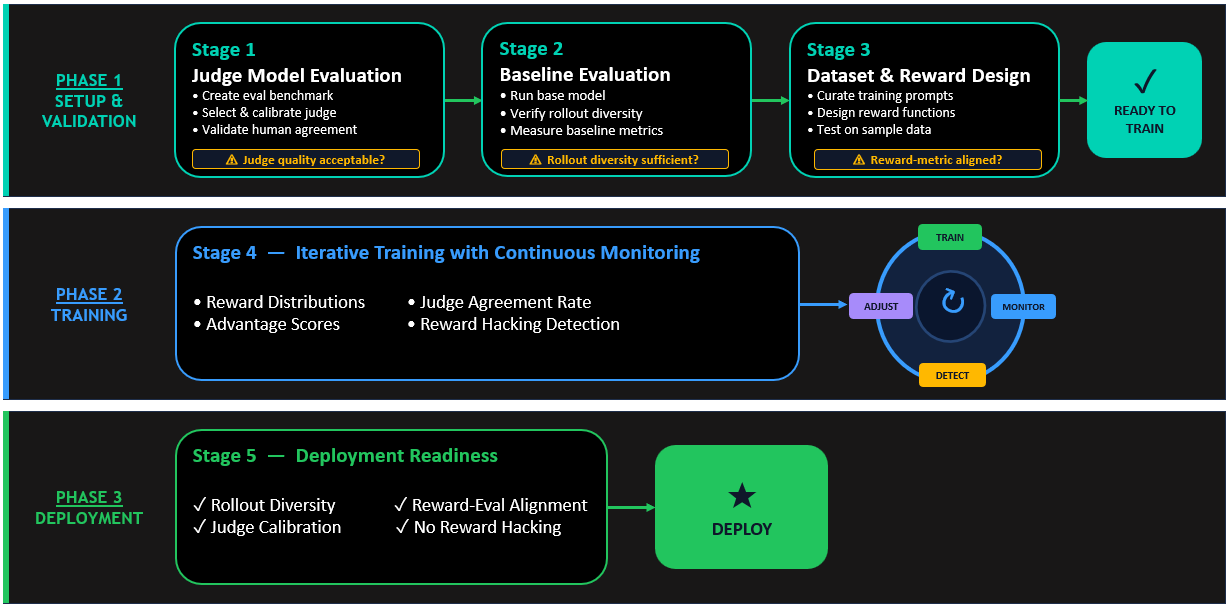
RFT с LLM-as-a-judge — рабочий процесс обучения
Следующая схема показывает полный end-to-end процесс обучения — от базовой оценки до валидации судьи и продакшен-развертывания. Каждый шаг опирается на предыдущий, формируя устойчивый pipeline, который балансирует качество выравнивания и вычислительную эффективность, при этом активно предотвращает reward hacking и поддерживает поведение модели, готовое к production.
Практический кейс: автоматизация проверки юридических контрактов
В этом разделе рассматривается реальный кейс с одним из ведущих партнеров в юридической отрасли. Задача — генерировать комментарии о рисках, оценках и действиях по юридической документации с опорой на политики и предыдущие контракты как на reference-документы.
Проблема
Партнер хотел автоматизировать процесс просмотра, оценки и выявления рисков в юридических контрактах. В частности, нужно было оценивать потенциальные новые контракты на соответствие внутренним правилам и регламентам, прошлым контрактам и законам страны, к которой относится договор.
Решение
Мы сформулировали задачу так: на вход подается целевой документ — «контракт», который нужно оценить, — и reference-документ, который служит grounding-источником и контекстом; на выходе LLM должна сгенерировать JSON с несколькими комментариями, типами комментариев и рекомендованными действиями на основе оценки. Исходный датасет для этого кейса был относительно небольшим и содержал полные контракты вместе с аннотациями и комментариями от юридических экспертов. Мы использовали LLM-as-a-judge с моделью GPT OSS 120b в роли судьи и кастомным system prompt во время RFT.
Рабочий процесс RFT
В следующем разделе описаны ключевые аспекты RFT workflow для этого кейса.
Reward Lambda function для LLM-as-a-judge
Ниже приведены основные компоненты reward Lambda function.
Примечание: имя Lambda function должно содержать «SageMaker», например "arn:aws:lambda:us-east-1:123456789012:function:MyRewardFunctionSageMaker"
a) Начните с определения верхнеуровневой цели
# Contract Review Evaluation - Unweighted Scoring
Вы — эксперт по проверке контрактов, оценивающий комментарии, сгенерированные ИИ. Ваша ОСНОВНАЯ цель — определить, насколько хорошо каждый предсказанный комментарий выявляет проблемы в пунктах TargetDocument-контракта и насколько эти проблемы обоснованы Reference-руководством.
b) Определите подход к оценке
## Подход к оценке
Для каждого примера вы получаете:
- **TargetDocument**: текст контракта, который проходит проверку (документ под оценкой)
- **Reference**: reference-руководство/стандарты, используемые для проверки (критерии оценки)
- **Prediction**: один или несколько комментариев от модели ИИ
**Важно**: SystemPrompt показывает, какие инструкции получила модель. Оценивая качество prediction, учитывайте, следовала ли модель этим инструкциям.
**КРИТИЧЕСКИ ВАЖНО**: каждый комментарий должен указывать на конкретную проблему, пробел или риск В САМОМ ТЕКСТЕ КОНТРАКТА TargetDocument. Поле text_excerpt в комментарии должно цитировать проблемный фрагмент языка контракта из TargetDocument, а НЕ цитировать текст из Reference-руководства. Reference обосновывает, ПОЧЕМУ пункт контракта проблематичен, но сама проблема должна существовать ИМЕННО в контракте.
Оценивайте КАЖДЫЙ предсказанный комментарий независимо. Комментарии должны отмечать проблемы в пунктах контракта, а не просто цитировать требования Reference.
c) Опишите измерения оценки с четкими спецификациями того, как должен рассчитываться конкретный score
## Измерения оценки (на каждый комментарий)
**ПОРЯДОК ОЦЕНКИ**: оценивайте в следующей последовательности: (1) TargetDocument_Grounding, (2) Reference_Consistency, (3) Actionability
### 1. TargetDocument_Grounding
**Оценивает**: (a) цитирует ли text_excerpt текст контракта из TargetDocument, и (b) насколько комментарий релевантен процитированному text_excerpt
**ОБЯЗАТЕЛЬНО**: text_excerpt должен цитировать текст контракта из TargetDocument. Если text_excerpt цитирует Reference, score ДОЛЖЕН быть равен 1.
- **5**: text_excerpt корректно цитирует текст контракта из TargetDocument И комментарий указывает на очень релевантную, валидную и заметную проблему в процитированном тексте
- **4**: text_excerpt корректно цитирует текст контракта из TargetDocument И комментарий указывает на валидную и релевантную проблему в процитированном тексте
- **3**: text_excerpt корректно цитирует текст контракта из TargetDocument И комментарий в некоторой степени релевантен процитированному тексту, но обоснованность проблемы средняя
- **2**: text_excerpt корректно цитирует текст контракта из TargetDocument, НО комментарий слабо релевантен процитированному тексту или проблема сомнительна
- **1**: text_excerpt НЕ цитирует текст контракта из TargetDocument (цитирует Reference или отсутствует реальная цитата), ИЛИ комментарий нерелевантен процитированному тексту
### 2. Reference_Consistency
...
d) Четко определите итоговый формат вывода для парсинга
## Расчет оценки
**Comment_Score** = простое среднее трех измерений:
- Comment_Score = (TargetDocument_Grounding + Reference_Consistency + Actionability) / 3
**Aggregate_Score** = среднее всех значений Comment_Score для sample
## Формат вывода
Для каждого sample оцените ВСЕ предсказанные комментарии и предоставьте:
```json
{ "comments": [
{ "comment_id": "...",
"TargetDocument_Grounding": {"score": X, "justification": "...", "supporting_evidence": "Проверьте, что text_excerpt цитирует реальный текст контракта из TargetDocument и что комментарий релевантен ему"},
"Reference_Consistency": {"score": X, "justification": "...", "supporting_reference": "Цитата из Reference, которая обосновывает проблему, ИЛИ объяснение на основе осмысленного reasoning"},
"Actionability": {"score": X, "justification": "Оцените, насколько действие ясно, grounded в TargetDocument и Reference и релевантно комментарию"},
"Comment_Score": X.XX
} ],
"Aggregate_Score": {
"score": X.XX,
"total_comments": N,
"rationale": "..."
}
}
```
e) Создайте высокоуровневый Lambda handler, обеспечив достаточную многопоточность для более быстрого inference
def lambda_handler(event, context):
scores: List[RewardOutput] = []
samples = event
max_workers = len(samples)
print(f"Evaluating {len(samples)} items with {max_workers} threads...")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [executor.submit(judge_answer, sample) for sample in samples]
scores = [future.result() for future in futures]
print(f"Completed {len(scores)} evaluations")
return [asdict(score) for score in scores]
Развертывание Lambda function
Мы использовали следующие разрешения AWS Identity and Access Management (IAM) и настройки в Lambda function. Следующие конфигурации обязательны для reward Lambda functions. Обучение RFT может завершиться ошибкой, если хотя бы одна из них отсутствует.
a) Разрешения для execution role Amazon SageMaker AI
Execution role Amazon SageMaker AI должен иметь разрешение вызывать вашу Lambda function. Добавьте эту политику в execution role Amazon SageMaker AI:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": "arn:aws:lambda:region:account-id:function:function-name"
}
]
}
b) Разрешения для execution role Lambda function
Execution role вашей Lambda function нужны базовые разрешения на выполнение Lambda и разрешения на вызов judge-модели Amazon Bedrock.
Примечание: это решение следует модели shared responsibility AWS. AWS отвечает за безопасность инфраструктуры, на которой работают сервисы AWS в облаке. Вы отвечаете за безопасность кода вашей Lambda function, настройку IAM-разрешений, внедрение шифрования и механизмов контроля доступа, управление безопасностью и конфиденциальностью данных, настройку мониторинга и логирования, а также проверку соответствия применимым регламентам. Следуйте принципу least privilege, ограничивая разрешения конкретными ARN ресурсов. Подробнее см. Безопасность в AWS Lambda и Amazon SageMaker AI Безопасность в документации AWS.
c) Добавьте provisioned concurrency
Мы опубликовали версию Lambda и, чтобы функция масштабировалась без колебаний задержки, добавили provisioned concurrency. В этом случае было достаточно значения 100, хотя здесь еще есть пространство для улучшения затрат.

d) Установите timeout Lambda на 15 минут

Настройка training configuration
Мы запустили Nova Forge SDK, который можно использовать для всего жизненного цикла настройки модели — от подготовки данных до развертывания и мониторинга. Nova Forge SDK избавляет от необходимости искать подходящие recipes или URI контейнера для конкретных техник.
С помощью Nova Forge SDK можно настраивать параметры обучения двумя способами: передать полный recipe YAML через recipe_path или указать отдельные поля через overrides для выборочных изменений. В этом кейсе мы используем overrides, чтобы настроить rollout-ы и trainer-параметры, как показано в следующем разделе.
# Запуск обучения с overrides для recipe
result = customizer.train(
job_name="my-rft-run",
rft_lambda_arn="<your-lambda-arn>",
overrides={
# Training config
"max_length": 64000,
"global_batch_size": 64,
"reasoning_effort": None,
# Data
"shuffle": False,
# Rollout
"type": "off_policy_async",
"age_tolerance": 2,
"proc_num": 6,
"number_generation": 8,
"max_new_tokens": 16000,
"set_random_seed": True,
"temperature": 1,
"top_k": 0,
"lambda_concurrency_limit": 100,
# Trainer
"max_steps": 516,
"save_steps": 32,
"save_top_k": 17,
"refit_freq": 4,
"clip_ratio_high": 0.28,
"ent_coeff": 0.0,
"loss_scale": 1,
},
)
Результаты
RFT с Amazon Nova 2 Lite достигла итоговой оценки 4.33 — лучшего результата среди всех оцененных моделей — при этом сохранив идеальную валидацию JSON schema. Это представляет собой значимое улучшение и показывает, что RFT может создавать готовые к production специализированные модели, превосходящие более крупные универсальные альтернативы.
Мы оценивали модели в режиме «best of k» для одного комментария: каждая модель генерировала несколько комментариев на sample, а мы оценивали самый качественный вариант. Такой подход задает верхнюю границу качества и позволяет справедливо сравнивать модели, которые генерируют один или несколько выходов.
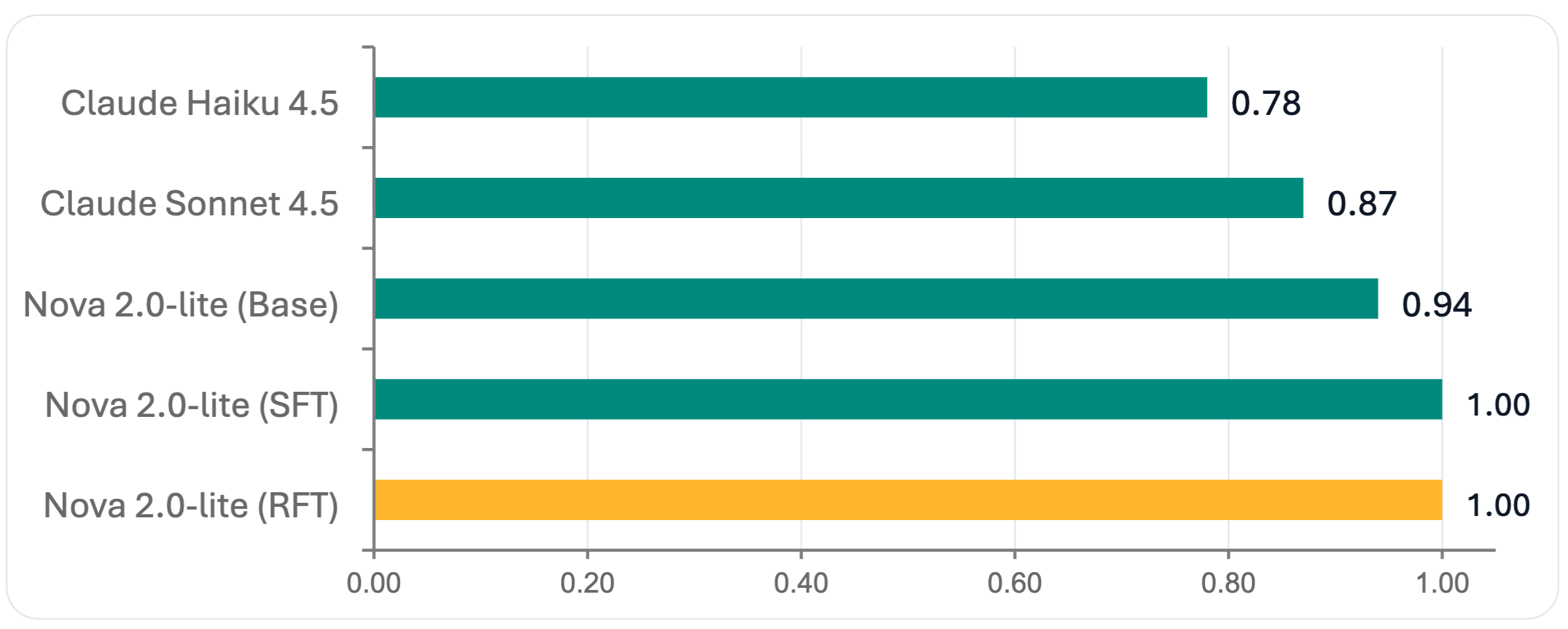
Рисунок 1 — Scores валидации JSON schema (шкала 0–1, выше — лучше)
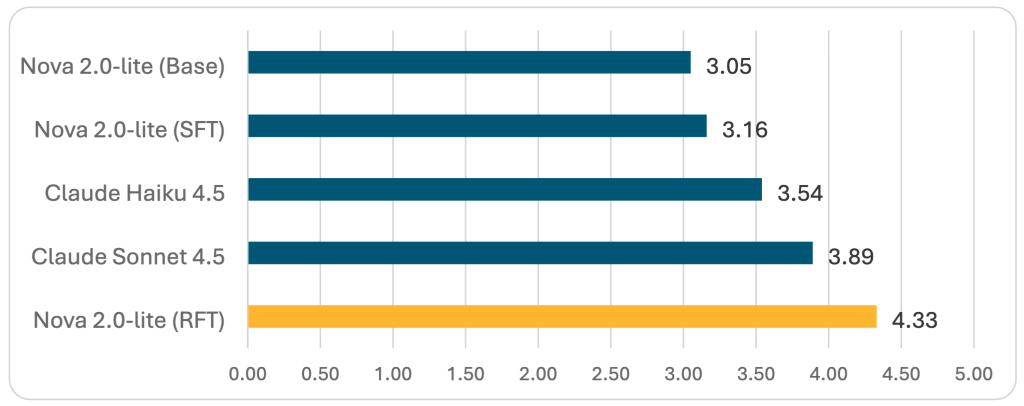
Рисунок 2 — Aggregate scores LLM-judge (шкала 1–5, выше — лучше)
Ключевые выводы:
- В этом исследовании RFT показал наивысшую производительность среди оцененных моделей.
Amazon Nova 2 Lite с RFT достигла 4.33 aggregate, опередив как Claude Sonnet 4.5, так и Claude Haiku 4.5, а также обеспечив идеальную JSON schema validation.
- Убирает ненужные артефакты обучения
Во время итераций SFT мы наблюдали проблемное поведение, включая повторяющуюся генерацию комментариев и неестественные предсказания Unicode-символов. Эти проблемы, вероятно вызванные переобучением или дисбалансом датасета, не проявлялись в checkpoint-ах RFT. Улучшения на основе reward естественным образом подавляют такие артефакты, делая выводы более устойчивыми и надежными.
- Сильная генерализация на новые критерии судьи
Когда мы оценивали RFT-модели с измененным prompt судьи (согласованным, но не идентичным обучающей reward-функции), результаты оставались сильными. Это показывает, что RFT обучается обобщаемым паттернам качества, а не переобучается на конкретные критерии оценки. Это критически важно для реального внедрения, где требования со временем меняются.
- Вычислительные затраты
Для RFT требовалось 4–8 rollout-ов на каждый training sample, что повышало вычислительные затраты по сравнению с SFT. Этот overhead усиливается при ненулевых настройках reasoning effort. Однако для критически важных приложений, где качество выравнивания напрямую влияет на бизнес-результаты — например, проверка юридических контрактов, финансовый комплаенс или медицинская документация, — выигрыш в качестве оправдывает дополнительные затраты на вычисления.
Заключение
Reinforcement Fine-Tuning (RFT) с LLM-as-a-judge — мощный подход к выравниванию LLM под специфические доменные задачи. Как показано в кейсе с проверкой юридических контрактов, этот метод дает значительное улучшение по сравнению и с базовыми моделями, и с традиционным supervised fine-tuning (SFT), при этом RFT достигает лучших aggregate scores по всем измерениям оценки. Для команд, строящих mission-critical AI-системы, где качество выравнивания напрямую влияет на бизнес-результаты, RFT с LLM-as-a-judge предлагает убедительный путь вперед. Объяснимость, гибкость и более высокая производительность делают этот метод особенно ценным для сложных областей вроде юридической проверки, а также Financial Services и Healthcare, где важны тонкие нюансы.
Организациям, которые рассматривают этот подход, стоит начинать с малого — проверить дизайн судьи на отобранных benchmark-ах, убедиться в устойчивости инфраструктуры и постепенно масштабироваться, одновременно отслеживая reward hacking. При корректной реализации RFT может превратить способные базовые модели в высокоспециализированные, готовые к production системы, которые стабильно выдают выровненные и заслуживающие доверия ответы.
References:
- Amazon Nova Developer Guide for Amazon Nova 2
- Nova Forge SDK- GitHub
- Reinforcement Fine-Tuning (RFT) with Amazon Nova models
Disclaimer:
Сценарий проверки юридических контрактов, описанный в этой статье, приведен только в технических демонстрационных целях. Анализ контрактов, созданный ИИ, не заменяет профессиональную юридическую консультацию. По юридическим вопросам обращайтесь к квалифицированному юристу.
Материал — перевод статьи с английского.