Amazon Quick представила Dataset Q&A для естественно-языковых запросов к структурированным наборам данных
Каждая BI-команда знает этот узкий участок: у бизнес-пользователя возникает вопрос, который не укладывается в существующие дашборды, и он создает тикет. Аналитик пишет запрос, проверяет результат и передает его — через часы или дни. Если таких ad hoc-запросов сотни в месяц, очередь становится главным ограничением продуктивности команды данных.
Amazon Quick теперь добавляет новую мощную возможность естественно-языкового запроса, Dataset Q&A, чтобы снять это ограничение. Ваш вопрос переводится в SQL, выполняется по полному набору данных, а результат возвращается за секунды — без выборки строк, тематической курирования или заранее настроенных вычисляемых полей.
В Quick уже есть два режима естественно-языковых запросов. Dashboard Q&A предназначен для вопросов о данных, визуализированных в опубликованных дашбордах, и опирается на бизнес-контекст, который авторы встроили в каждый виджет. Topic Q&A идет дальше. Авторы обогащают модель данных понятными бизнесу названиями полей и синонимами, чтобы пользователи могли задавать вопросы к отобранному набору полей на обычном языке. Теперь Dataset Q&A завершает картину. Пользователи могут исследовать любой набор данных напрямую, выходя за пределы предварительной настройки автора, при этом все механизмы безопасности, прав доступа и governance, ожидаемые предприятиями от Quick, остаются полностью в силе.
Этот запуск также представляет Dataset Enrichment — упрощенный способ, с помощью которого авторы могут заземлить систему в бизнес-контексте для одного набора данных без необходимости настраивать topic. Если бизнес-контекст уже существует вне Quick — в data catalog, инструменте моделирования или командной wiki, — авторы могут загрузить его напрямую в виде файла, привязанного к набору данных. Описания полей, предполагаемые связи между полями, пользовательские инструкции по отдельным столбцам или по набору данных в целом — все это можно передать в стандартных форматах отрасли (YAML, JSON) или в виде обычного текстового файла с инструкциями. Система автоматически применяет этот контекст к каждому запросу, так что автор настраивает его один раз, а выигрывают все пользователи в масштабе.
Доверие требует прозрачности. С этим запуском мы также представляем Chat Explainability. Для любого промежуточного шага, задействованного в ответе на естественно-языковой запрос, система теперь дает пользователям механизмы, позволяющие посмотреть, что произошло внутри. Когда используются возможности для структурированных данных, пользователи видят пошаговое объяснение каждого ответа — сгенерированный SQL, предположения агента, примененные фильтры и понятное объяснение для нетехнических стейкхолдеров. Здесь нет черного ящика.
В этом посте вы узнаете, как начать работу с Dataset Q&A, разберете реальные сценарии на практических примерах и познакомитесь с продвинутыми возможностями вроде автообнаружения по всем вашим объектам данных и запроса к нескольким наборам данных в одном разговоре.
Обзор решения
Dataset Q&A позволяет любому пользователю задать вопрос на обычном естественном языке, после чего система генерирует SQL, выполняет его по полному набору данных и возвращает ответ за секунды. Результаты по умолчанию агрегируются, а каждый запрос автоматически учитывает настроенные вами row-level security (RLS) и column-level security (CLS) — без дополнительной настройки.
Ключевые преимущества:
- Анализ миллионов строк — запрос к полному набору данных без выборки строк и лимитов по объему.
- Запросы за пределами дашборда — вопросы о полях и измерениях, которых нет ни в одном существующем дашборде.
- Сложные многочастные вопросы — объединение фильтров, вычислений и агрегирований в одном естественно-языковом запросе.
- Проверка сгенерированного SQL — валидация логики запроса, точности и того, как система интерпретировала ваш вопрос.
- Понимание интерпретации вопросов — пошаговое объяснение каждого ответа, включая предположения и примененные фильтры, прежде чем делиться результатами со стейкхолдерами.
Практическое руководство
В этом пошаговом примере мы демонстрируем Dataset Q&A на реальном наборе данных о поездках на велосипедах из городской системы велошеринга. Чтобы повторить шаги в своей среде, убедитесь, что у вас есть следующее:
- Аккаунт AWS. Инструкции по настройке см. в разделе Getting Started с AWS.
- В аккаунте включена Amazon Quick Enterprise Edition, а также есть как минимум один Enterprise user и один Professional user. Подробности см. в разделе Amazon Quick Sight editions and pricing.
- Знакомство с концепциями Amazon Quick Sight, такими как datasets и чат-интерфейс. Чтобы начать, обратитесь к документации Amazon Quick Sight.
В качестве примера в этом материале используется общедоступный набор данных Divvy bike trip dataset за последние четыре месяца 2025 года, содержащий записи поездок велошеринга в Чикаго. Скачайте файлы и создайте dataset в Quick Sight. Для объединения нескольких файлов можно использовать опцию append. Подробнее о новом процессе подготовки данных см. в документации Quick Sight documentation или в этом видео YouTube.
Примечание: поскольку базовая модель может формулировать или форматировать ответы по-разному в разных сеансах, точная формулировка и визуальное оформление ответов могут отличаться от показанного здесь. Однако значения данных и результаты запросов должны совпадать при использовании одного и того же вопроса и набора данных.
Шаг 1: Подключитесь к данным
Чтобы использовать Dataset Q&A в чат-интерфейсе, выполните следующие действия:
- В Amazon Quick выберите значок Open chat в правом верхнем углу навигации.
- My Assistant отображается как чат-агент системы по умолчанию.
- Откройте picker знаний в нижней части чата и выберите Add в разделе Specific data and apps.
- В разделе Add Quick assets выберите Datasets и укажите набор данных Divvy_Bike_Trips.
- Нажмите Save.
- После выбора набора данных Divvy_Bike_Trips вводите вопросы в чат-интерфейсе.
- Для начала попробуйте вопрос на обнаружение структуры набора данных: Can you describe the structure of this dataset?
Чат Quick отвечает подробным разбором структуры набора данных, объясняя, какая информация хранится в каждом столбце, а также описывает доступные поля и их назначение.
Возможности Dataset Q&A можно использовать как для наборов данных SPICE, так и для direct query, включая Amazon Redshift, Amazon Athena, Amazon Aurora PostgreSQL и Amazon Simple Storage Service (S3) Tables.
Шаг 2: Исследуйте набор данных
После подключения к набору данных Divvy_Bike_Trips можно исследовать данные через серию естественно-языковых вопросов. Следующие примеры показывают, как Dataset Q&A справляется с возрастающей сложностью, сохраняя контекст разговора.
Пример 1: Анализ паттернов поездок
Начните с общего исследования паттернов поездок по месяцам:
How many rides do we have for every month in 2025 from September until December?
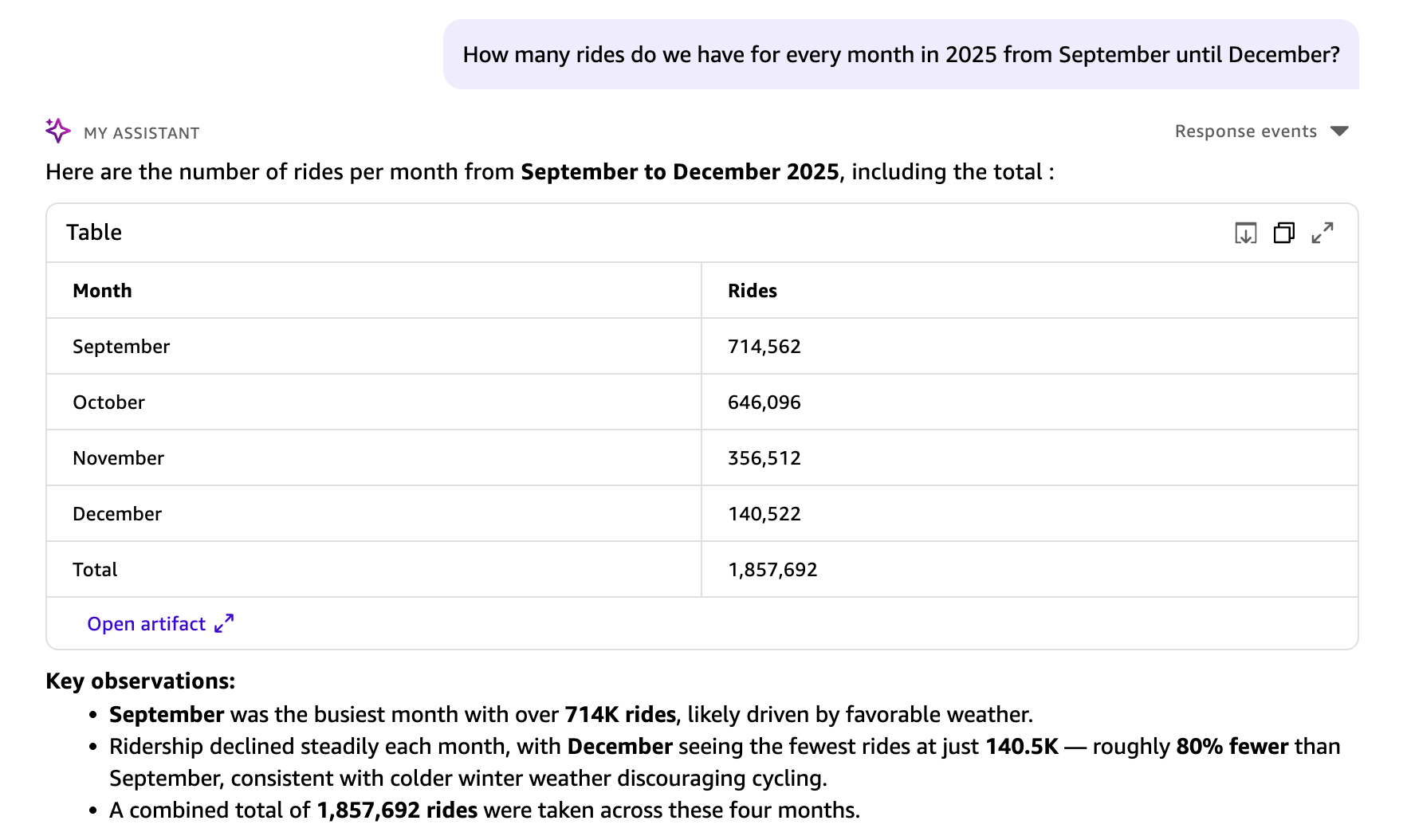
Ваш вопрос переводится в структурированный SQL-запрос. Результаты появляются в виде таблицы, включая блок ключевых наблюдений и предлагаемые следующие шаги. Этот запрос проанализировал все 1,857,960 поездок в наборе данных. Dataset Q&A не имеет ограничений по числу строк для direct query datasets, поэтому агрегаты отражают полный набор данных. Для наборов данных SPICE агрегаты зависят от SPICE capacity.
Пример 2: Передайте контекст, чтобы направить модель
Набор данных содержит два временных поля: started_at — когда поездка началась, и ended_at — когда поездка завершилась. Если контекст не задан, Quick Chat использует started_at как логическое значение по умолчанию для группировки поездок по месяцам. Чтобы анализировать по времени завершения, добавьте контекст в вопрос:
How many rides do we have for every month in 2025 from September until December? Use the ended_at timestamp to determine the month.
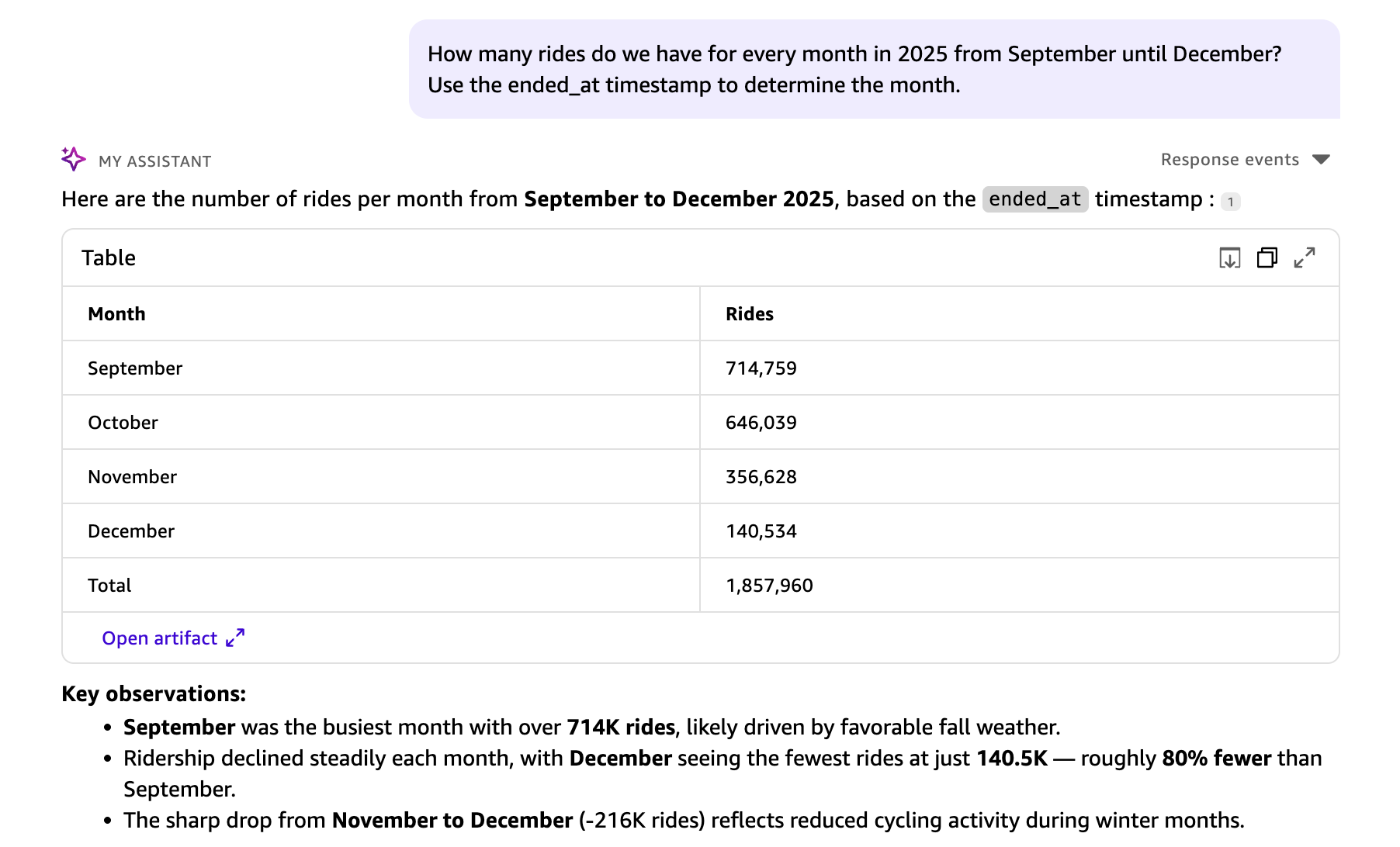
Quick Chat понимает контекст, и для группировки по месяцам в ответе используется ended_at.
Пример 3: Проверьте сгенерированный SQL
Чтобы посмотреть SQL, который генерирует Quick Sight, используйте функцию Explainability, доступную в ответе чата. Она показывает пошаговое объяснение каждого ответа, включая сгенерированный SQL, чтобы вы могли проверить, как система интерпретировала ваш вопрос.
How many rides do we have for every month in 2025 from September until December?
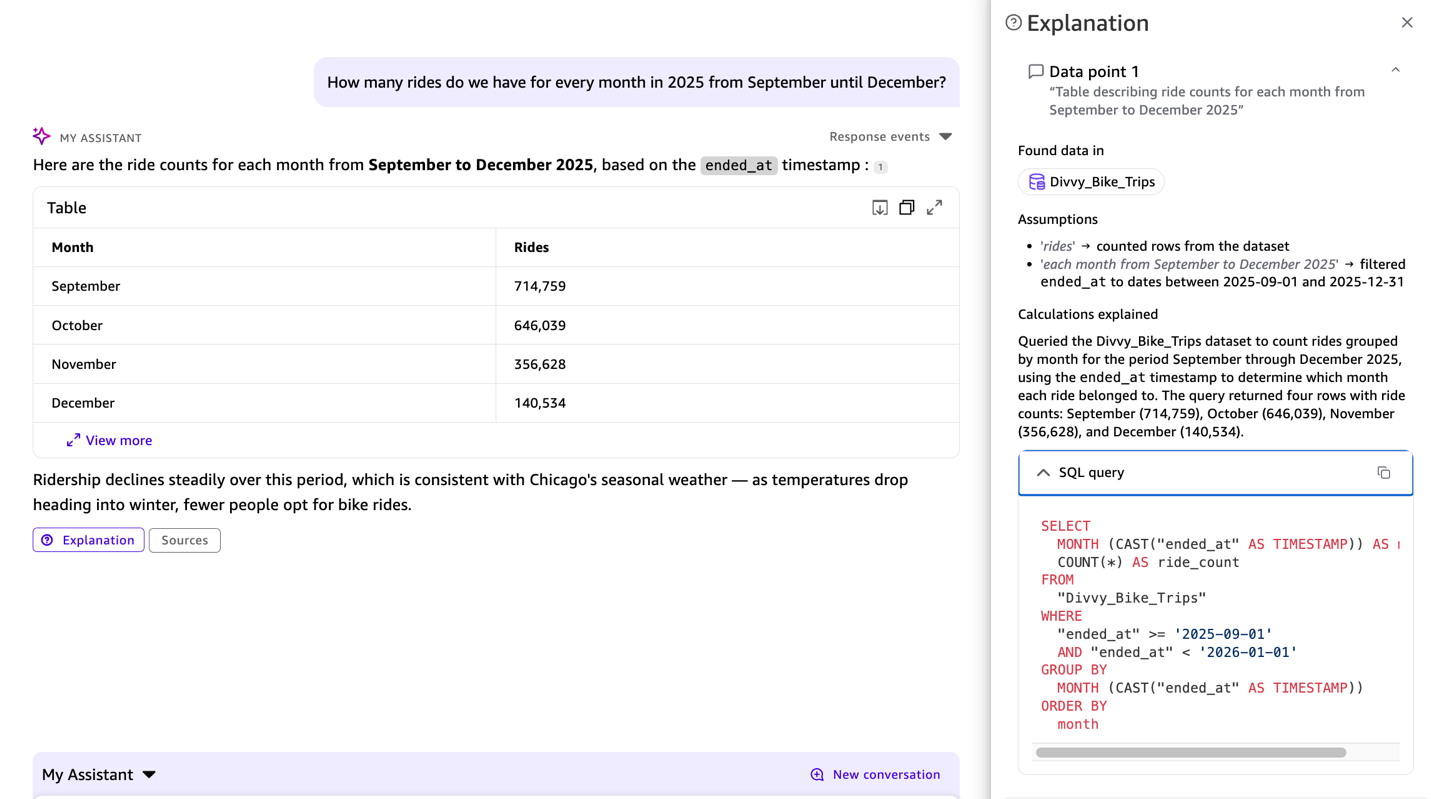
SQL-запрос появляется в ответе, и вы видите, что ended_at используется из предыдущего контекста, так что можно убедиться в корректности интерпретации.
Пример 4: Задайте несколько вопросов сразу
Можно исследовать данные с помощью нескольких вопросов в одном запросе:
How many bike rides are there?
How many trips by bike type?
How many trips by members?
Для каждого вопроса выполняется отдельный SQL-запрос, а затем возвращается объединенная сводка.

Пример 5: Объедините продвинутые вычисления
Следующий запрос задает два вопроса сразу, и оба требуют метрик, вычисляемых во время выполнения, а не хранящихся в наборе данных.
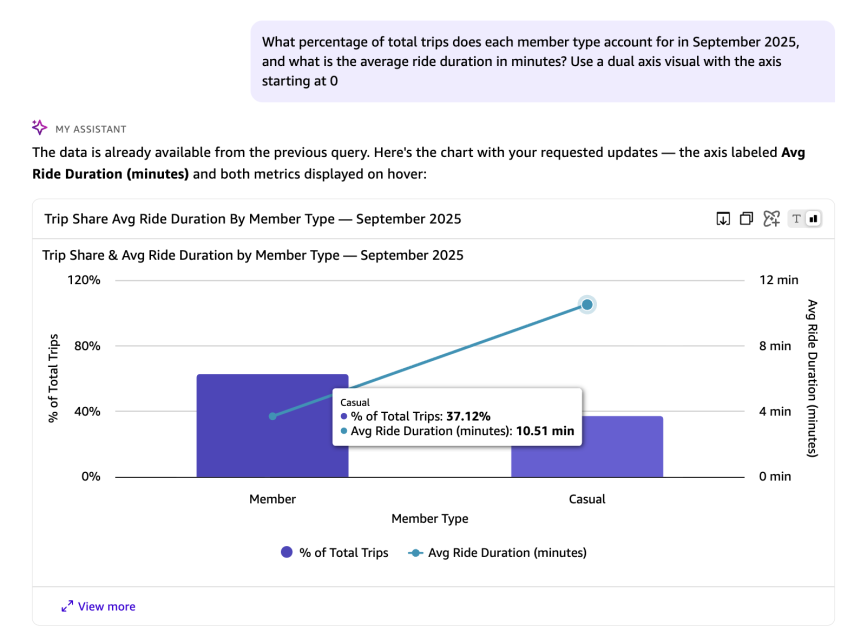
What percentage of total trips does each member type account for in September 2025, and what is the average ride duration in minutes? Use a dual axis visual with the axis starting at 0.
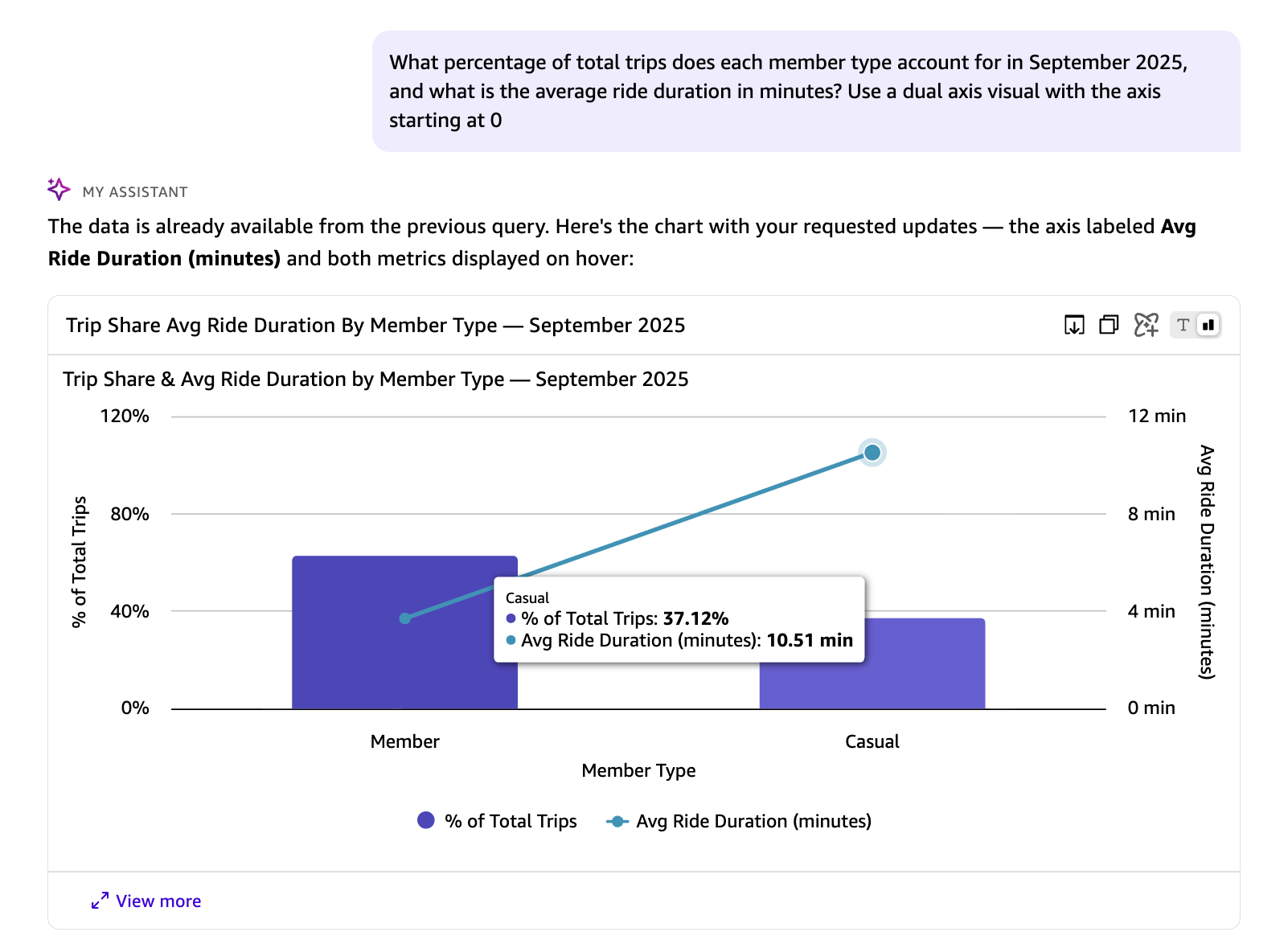
В предыдущем ответе avg_duration_minutes и percentage_of_total_trips — это вычисления во время выполнения, которых нет в исходном наборе данных. Вы также можете указать Quick тип визуализации и конфигурацию осей для отображения результатов. Следующий SQL-запрос автоматически генерируется Quick в ответ на приведенный выше естественно-языковой вопрос. Он рассчитывает долю от общего числа поездок и среднюю длительность поездки для каждого типа райдера в сентябре 2025 года с использованием оконных функций и арифметики дат:
SELECT
"member_casual",
COUNT(*) AS trip_count,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER (), 2) AS percentage_of_total_trips,
ROUND(AVG(date_diff('second', "started_at", "ended_at")) / 60.0, 2) AS avg_duration_minutes
FROM "Divvy_Bike_Trips"
WHERE "ended_at" >= '2025-09-01 00:00:00'
AND "ended_at" < '2025-10-01 00:00:00'
GROUP BY "member_casual"
ORDER BY trip_count DESC
Ключевые компоненты этого запроса:
- Оконная функция: SUM(COUNT(*)) OVER () вычисляет общее число поездок по всем типам райдеров для расчета процентов.
- Расчет процента: COUNT(*) * 100.0 / SUM(COUNT(*)) OVER () вычисляет долю каждой группы от общего числа поездок.
- Расчет длительности: AVG(DATEDIFF(‘minute’, started_at, ended_at)) вычисляет среднюю длительность поездки в минутах.
- Фильтрация: ограничивает данные сентябрем 2025 года — с 1 сентября до момента до 1 октября.
- Группировка: группирует по member_casual, чтобы разделить member и casual riders.
- Сортировка: сортирует по общему числу поездок по убыванию.
Работа с несколькими наборами данных и spaces
Dataset Q&A не ограничивается одним набором данных. Если вы вручную выбираете dataset, добавляете несколько datasets или собираете Space с разными типами объектов, встроенный enterprise knowledge graph определяет нужный источник данных на основе интерпретации вашего вопроса.
Добавление одного набора данных
Предыдущее руководство показало, как подключить один dataset через knowledge picker и исследовать его с помощью естественно-языковых вопросов. Это самый простой способ начать работу с Dataset Q&A.
Добавление нескольких наборов данных
Вы можете добавить несколько datasets в knowledge picker и задавать вопросы, охватывающие весь ваш data landscape. Когда выбрано несколько наборов данных, Quick Chat автоматически направляет каждый вопрос к наиболее подходящему dataset на основе контекста вопроса и доступной схемы.
Сценарий примера: транспортный аналитик имеет доступ и к набору данных о поездках Divvy, и к набору данных о погоде в Чикаго. Выбрав оба набора данных в knowledge picker, он может спросить:
“What was the total number of bike trips in September 2025?” (routes to Divvy dataset)
“What were the average temperatures in September 2025?” (routes to weather dataset)
“Show me bike trip volumes and weather patterns for each month” (analyzes both datasets separately and presents combined insights)
Автообнаружение с All data and apps
Вам даже не нужно знать, какие datasets доступны. В Quick Chat knowledge picker предлагает вариант All data and apps. Если выбрать его, вы можете задать вопрос, и система автоматически обнаружит нужные datasets, выполнит по ним запросы и сформирует единый ответ.
Формирование Space для анализа между объектами
Для самого полного сценария организуйте связанные объекты вместе с помощью Amazon Quick Spaces. Space — это коллекция файлов, datasets, dashboards и knowledge bases.Сценарий примера: пространство “Transportation Analytics” может содержать dataset Divvy bike trips в Quick Sight, dataset по погоде в Чикаго, отчеты по городской инфраструктуре в PDF и календарь событий в форматах Word, а также существующие дашборды Quick Sight по транспорту.
После выбора этого Space в knowledge picker вы можете задавать вопросы, которые используют все объекты внутри него:
“How did weather patterns affect bike ridership in September?” (combines Divvy bike trip dataset with the Chicago weather dataset)
“What major events occurred during peak ridership weeks?” (references event calendar documents)
“Compare bike-sharing usage with public transit ridership trends” (analyzes multiple datasets)
Quick Chat автоматически определяет, какие объекты содержат нужную информацию, и синтезирует выводы как по структурированным данным (datasets), так и по неструктурированному контенту (documents).
Сценарии использования
Следующие примеры представляют четыре типовых паттерна, где Dataset Q&A приносит наибольшую пользу.
Паттерн 1: Постепенное усложнение без перенастройки
Что мы показали: начиная с помесячных агрегатов, в walkthrough были продемонстрированы все более сложные вопросы — от определения пользовательских метрик (средняя длительность поездки) до выполнения вложенных агрегирований (процент по типу member) — и все это без каких-либо изменений в настройках или конфигурации.
Реальный сценарий: бизнес-аналитик, изучающий данные о продажах, может начать с вопроса “What were total sales last quarter?” и естественно перейти к “What percentage of revenue came from repeat customers in each region, and how did their average order value compare to new customers?” не ожидая обновления дашборда.
Почему это важно: Dataset Q&A поддерживает итеративное исследование, в котором каждый вопрос опирается на предыдущий, а контекст сохраняется на протяжении всего разговора.
Польза: естественный аналитический процесс, который соответствует тому, как аналитики мыслят при решении задач.
Паттерн 2: Прозрачность SQL и explainability для технической проверки
Что мы показали: для каждого запроса в walkthrough SQL был доступен по требованию — от простых агрегатов до вложенных агрегатов с оконными функциями. Благодаря такой прозрачности можно проверить, правильно ли интерпретирован естественный язык, прежде чем делиться результатами.
Реальный сценарий: data engineer должен убедиться, что вопрос “What is the average order value for repeat customers who made purchases in both Q3 and Q4 2025?” корректно определяет repeat customers (тех, у кого есть заказы и в обоих кварталах, а не просто в одном из них), прежде чем отправлять результат руководству.
С Dataset Q&A технические пользователи могут:
- понимать, как естественно-языковые вопросы интерпретируются и выполняются через функцию Explainability;
- просматривать логику сгенерированного запроса;
- проверять сложные условия, такие как логика AND против OR, диапазоны дат и уровни агрегации;
- запрашивать корректировки, если интерпретация не совпадает с намерением;
- проверять подход перед передачей результатов стейкхолдерам.
Польза: уверенность в результатах, возможность объяснить методологию и техническая достоверность.
Паттерн 3: Полный анализ набора данных
Что мы показали: каждый запрос обращался к полному исходному набору данных. Помесячный анализ обработал все 1,857,960 поездок. Расчеты процентов за сентябрь были выполнены по 714,562 поездкам. Выборки или усечения не было.
Реальный сценарий: менеджеру операций, анализирующему обращения в поддержку, нужны паттерны обработки всех тикетов за последний год. Такой вопрос, как “What percentage of tickets were resolved within SLA by priority level and support tier?”, требует полных данных для точных выводов.
Dataset Q&A выполняет запрос к полному исходному набору данных с помощью SQL, обеспечивая точные агрегаты по миллионам записей без выборки или усечения.
Польза: полные и точные результаты для принятия решений на основе данных.
Паттерн 4: Анализ нескольких объектов
Что это демонстрирует: Dataset Q&A работает, когда в области видимости находятся несколько наборов данных или Space с разными объектами (datasets + documents), позволяя проводить целостный анализ данных организации.
Реальный сценарий: транспортный планировщик должен понять, как использование велошеринга соотносится с пассажиропотоком общественного транспорта и городскими событиями. Он создал Space “Transportation Analytics”, который содержит:
- Divvy bike trip dataset (structured data)
- CTA transit ridership dataset (structured data)
- City events calendar (PDF document)
- Weather data (CSV file)
Выбрав этот Space, он может задать вопрос: “What was the impact of major events on bike and transit usage in October 2025?”
Разговорный ассистент:
- определяет релевантные структурированные данные из наборов поездок на велосипедах и пассажиропотока;
- извлекает информацию о событиях из PDF-календаря;
- сопоставляет погодные паттерны из CSV-файла;
- синтезирует выводы по всем источникам.
Почему это важно: организации редко принимают решения, опираясь на один-единственный dataset. Dataset Q&A с Spaces позволяет анализировать данные из разных silos без ручной интеграции данных или сложных ETL-процессов.
Польза: целостные, контекстные инсайты, отражающие всю сложность бизнес-операций.
Ключевые различия
- Dataset Q&A открывает разовые исследования за пределами заранее настроенных границ. Он дает доступ к любому полю с пользовательскими runtime-вычислениями на естественном языке, а также обеспечивает полную прозрачность SQL для технической проверки.
- Dashboard Q&A хорошо подходит для поиска инсайтов в рамках того, что настроили авторы дашбордов, включая конкретные визуализации, поля, фильтры и курированную бизнес-логику с вычислениями.
- Topic Q&A особенно полезен, когда авторы создали и поддерживают topic-конфигурации с отобранными определениями полей, синонимами и пользовательскими инструкциями.
Поддерживаемые источники данных
На данный момент для Dataset Q&A в режиме direct query поддерживаются Amazon Athena, Amazon Redshift, Amazon Aurora PostgreSQL и Amazon S3 Tables.
Текущие ограничения
- Composite datasets не поддерживаются, если родительские datasets используют SPICE, а дочерний dataset работает в direct query mode.
- Пользовательские SQL datasets с параметрами сейчас не поддерживаются.
Очистка
Чтобы избежать дальнейших расходов, удалите созданный в рамках этого walkthrough набор данных Divvy_Bike_Trips. Инструкции см. в разделе Deleting a dataset в документации Amazon Quick.
Заключение
Dataset Q&A для наборов данных в Quick Sight внутри Amazon Quick убирает барьер между бизнес-вопросами и аналитическими инсайтами. Он дает аналитикам гибкость, позволяя выходить за рамки заранее настроенных дашбордов, дает техническим пользователям прозрачность SQL для проверки сложной логики и дает всем доступ к полным наборам данных без ограничений по строкам.
Эта возможность дополняет существующие функции Dashboard Q&A и Topic Q&A, предлагая правильный инструмент для каждого аналитического сценария: курированные инсайты, когда нужны guardrails, и гибкое исследование, когда вопросы выходят за рамки заранее настроенных визуализаций.
Материал — перевод статьи с английского.
Оригинал: Introducing Dataset Q&A: Expanding natural language querying for structured datasets in Amazon Quick