Развертывание vision-language моделей для обнаружения поведения питомцев на AWS Inferentia2: как Tomofun снизила затраты на 83%

Tomofun, тайваньский pet-tech стартап, стоящий за Furbo Pet Camera, меняет то, как владельцы взаимодействуют со своими питомцами на расстоянии. Furbo сочетает умные камеры с AI, чтобы выявлять такое поведение, как лай, бег или необычная активность, и отправлять владельцам уведомления в реальном времени. В основе этой возможности лежат компьютерное зрение и vision-language models, которые интерпретируют действия питомцев по видеопотокам.
Изначально инференс-нагрузки Furbo размещались на GPU-инстансах Amazon Elastic Compute Cloud (Amazon EC2). Хотя GPU обеспечивали высокую пропускную способность, они были дорогими, поскольку постоянный инференс нужен для поддержки оповещений о поведении питомцев в реальном времени на масштабе. Чтобы снизить затраты и сохранить точность, Tomofun перешла на EC2 Inf2-инстансы на базе AWS Inferentia2, специализированных AI-чипов Amazon. В этом материале мы подробно разбираем следующие разделы.
Проблема: снижение стоимости GPU-инференса для vision-language моделей в реальном времени на масштабе
Запуск продвинутых vision-language моделей, таких как Bootstrapping Language-image Pre-Training (BLIP), подробно описанных в оригинальной статье, выполнялся на GPU-инстансах и оказался менее экономичным для круглосуточных нагрузок реального времени на масштабе. Задача была двойной: Tomofun нужно было сохранить эффективность затрат при почти непрерывном мониторинге поведения питомцев на сотнях тысяч устройств и одновременно удержать качество модели и пропускную способность. При этом требовалось обойтись без переписывания больших частей кода BLIP, уже оптимизированного под PyTorch.
Обзор решения
Перед тем как перейти к архитектуре, приведенная ниже схема дает общее представление о том, как система обрабатывает обнаружение поведения питомцев на масштабе с использованием сервисов AWS.
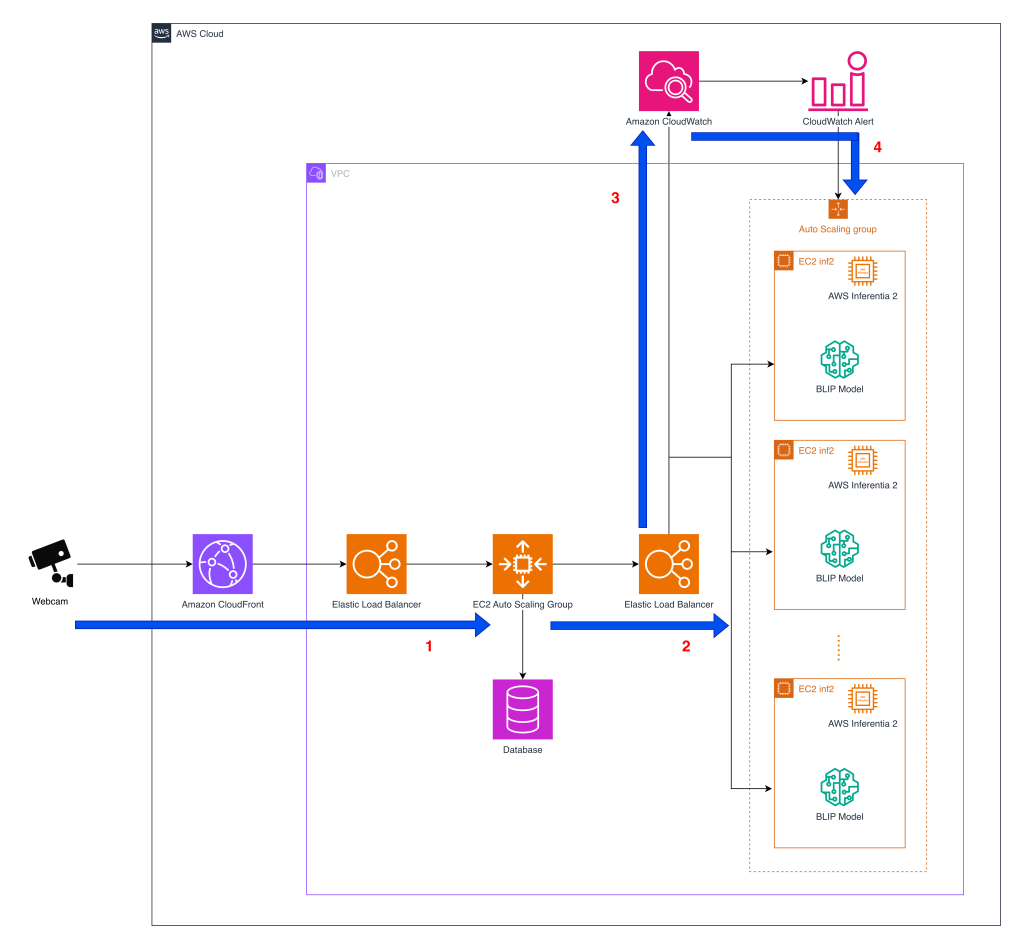
- Взаимодействие с веб-камерой – API Furbo находится в центре сервиса Tomofun для обнаружения поведения питомцев и координирует потоки изображений с камер клиентов к inference endpoints в AWS. Схема показывает архитектуру Elastic Load Balancing (ELB) и группы Amazon EC2 Auto Scaling, реализованных на EC2 Inf2-инстансах, которые обеспечивают масштабирование по мере роста объема инференса в реальном времени. Когда камера захватывает кадр, данные проходят через Amazon CloudFront и ELB к первому уровню группы EC2 Auto Scaling, где размещены API-серверы для обнаружения поведения питомцев. После обработки каждого запроса API-слой пересылает изображение во второй уровень Auto Scaling group, предназначенный для запуска инференса модели.
- Инференс модели – После обработки изображения направляются во второй уровень EC2 Auto Scaling group, содержащий inference-инстансы. Внутри этой группы контейнеры хостят модель BLIP, которая может работать на EC2 Inf2-инстансах на базе Inferentia2. Компоненты модели BLIP, скомпилированные с помощью Neuron SDK, загружаются в контейнеры на Inf2-инстансах. В ранней реализации API Furbo направлял запросы только в GPU-контейнеры, но теперь может отправлять запросы и в контейнеры на базе Inf2 без изменения ни upstream API, ни логики downstream-оповещений. Эта архитектура позволяет Tomofun в реальном времени направлять запросы инференса и переключаться между GPU и Inferentia2 backend-ами. Это обеспечивает высокую доступность и дает гибкость масштабировать более дешевый инференс, сохраняя тот же API surface для пользователей Furbo.
- Сбор метрик – Amazon CloudWatch отслеживает ключевые операционные метрики по всему инференс-флоту, включая latency, throughput и error rates. Эти сигналы дают observability, необходимую для раннего выявления деградации производительности и гарантии выполнения service-level objectives по мере изменения трафика в течение дня.
- Масштабирование по спросу – ELB распределяет запросы между доступными инстансами внутри Auto Scaling group, а размер пула инстансов управляется на основе числа входящих запросов как метрики CloudWatch. Такой подход, основанный на метриках, используется потому, что throughput-бенчмарки для каждого типа инстансов уже определены в ходе stress testing, поэтому решения о масштабировании можно напрямую привязывать к объему запросов на изображения. В результате получается архитектура, которая в реальном времени масштабирует более дешевую вычислительную мощность для инференса, сохраняя высокую доступность по мере роста спроса.
Улучшение BLIP на Inferentia2
Перед тем как перейти к деталям модели, приведенная ниже схема показывает общий вид архитектуры BLIP и то, как взаимодействуют ее основные компоненты.
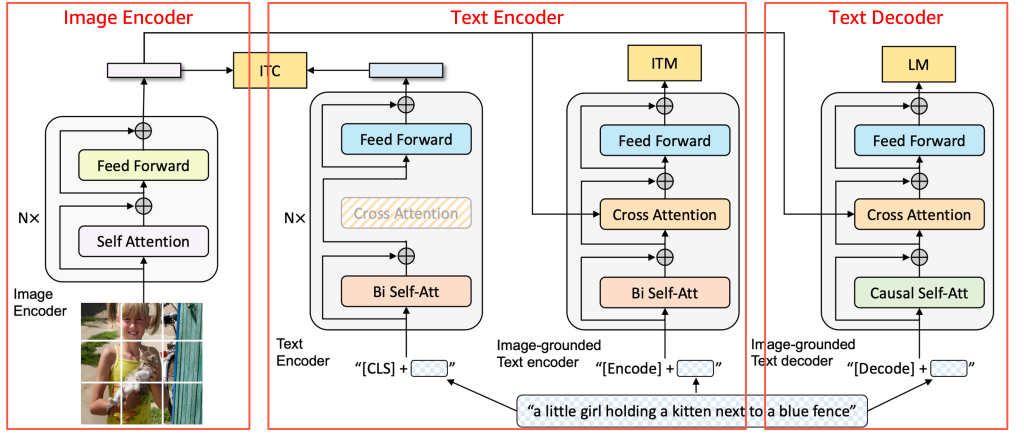
Источник: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, 2022 https://arxiv.org/pdf/2201.12086
BLIP состоит из трех компонентов — Image Encoder, Text Encoder и Text Decoder, как показано на изображении. Для поддержки Inferentia2 модели можно разбивать на компоненты и оборачивать так, чтобы они соответствовали входным и выходным формам. Tomofun применила этот подход к BLIP, создав легковесные wrapper-ы для каждого из трех компонентов модели BLIP, чтобы исходная архитектура осталась неизменной. Каждый компонент был скомпилирован независимо с помощью torch_neuronx, а затем объединен в inference pipeline, позволяя данным последовательно проходить через систему. Такой модульный подход обеспечил совместимость с Inferentia2 без изменения pretrained-логики BLIP.
Исходный код модели
Первый шаг — изолировать исходный BLIP Text Encoder, чтобы его можно было скомпилировать без изменения внутренней логики. Класс TextEncoder — это тонкий wrapper над исходным подмодулем (model.text_encoder.model), который стандартизирует выход функции forward, возвращая только основной тензор. Это делает компонент удобным для trace и компиляции с Neuron при сохранении исходной архитектуры.
class TextEncoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask):
output = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)
return output[0]
На этапе compilation phase исходная модель (model.text_encoder.model) передается напрямую в torch_neuronx.trace() и компилируется в Neuron-оптимизированный TorchScript artifact без изменения pretrained-логики BLIP.
Код wrapper-а
Wrapper необходим потому, что API torch_neuronx.trace() ожидает на входе и выходе tuple тензоров. Чтобы не переписывать модель, легковесные wrapper-ы выступают как adapter layer, который преобразует входы и выходы, сохраняя исходную архитектуру без изменений. Такой подход минимизирует изменения в коде и позволяет компилированным компонентам бесшовно встраиваться в существующий inference pipeline.
class TextEncoderWrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = TextEncoder(model)
@classmethod
def from_model(cls, model):
wrapper = cls(model)
wrapper.model = model
return wrapper
def forward(self, input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask, return_dict):
output = self.model(input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask)
return (output,)
Wrapper используется только при развертывании, чтобы загрузить компилированную модель и отформатировать I/O, поэтому он подходит для существующего BLIP pipeline.
- Компиляция: использовать исходную модель (
model.text_encoder.model) - Развертывание: использовать
TextEncoderWrapperдля запуска компилированной модели
Это сохраняет исходный код без изменений и одновременно делает компилированную модель удобной для подключения в production.
Компиляция модели для Inferentia2
В приведенном ниже фрагменте model.text_encoder.model обозначает неизмененный submodule Text Encoder, который компилируется в Neuron-оптимизированный формат TorchScript.
def trace_model(model, directory, compiler_args=f"--auto-cast-type fp16 --logfile {LOG_DIR}/log-neuron-cc.txt"):
if os.path.isfile(directory):
print(f"Provided path ({directory}) should be a directory, not a file")
return
os.makedirs(directory, exist_ok=True)
os.makedirs(LOG_DIR, exist_ok=True)
# Skip trace if the model is already traced
if not os.path.isfile(os.path.join(directory, 'text_encoder.pt')):
print("Tracing text_encoder")
# Step 1: Provide pseudo input data with expected shapes and dtypes
inputs = (
torch.ones((1, 8), dtype=torch.int64),
torch.ones((1, 8), dtype=torch.int64),
torch.ones((1, 577, 768), dtype=torch.float32),
torch.ones((1, 577), dtype=torch.int64),
)
# Step 2: Use torch_neuronx.trace() to compile the model for Inferentia
encoder = torch_neuronx.trace(model.text_encoder.model,
inputs,
compiler_args=compiler_args)
# Step 3: Save the compiled model as TorchScript artifact
torch.jit.save(encoder, os.path.join(directory, 'text_encoder.pt'))
else:
print('Skipping text_encoder.pt')
Чтобы компилировать компоненты BLIP для Inferentia2, Tomofun определила функцию trace, автоматизирующую преобразование PyTorch-моделей, обученных на GPU, в Inferentia-оптимизированные артефакты. Процесс начинается с подготовки псевдовходных тензоров, которые отражают ожидаемые формы и типы данных входов модели и направляют процесс tracing. После задания входов функция вызывает torch_neuronx.trace(), чтобы скомпилировать sub-model BLIP для выполнения на Inferentia, создавая Neuron-оптимизированную версию исходного кода. Наконец, скомпилированный артефакт сохраняется с помощью torch.jit.save, после чего он готов к развертыванию на Inf2-инстансах. Этот трехшаговый поток — загрузка wrapper-а, предоставление псевдовходных данных и компиляция с Neuron — помогает Tomofun переносить TextDecoder BLIP и другие компоненты без изменения исходного кода модели.
Развертывание модели на Inferentia2
На этапе развертывания скомпилированные подмодули загружаются через wrapper-классы, чтобы собрать итоговый BLIP inference pipeline. Такое разделение создает понятный рабочий процесс: исходные компоненты модели используются напрямую для Neuron improvement на этапе компиляции, а wrapper-классы обрабатывают форматирование входов и выходов во время инференса, обеспечивая совместимость с Inferentia2. Код этапа развертывания выглядит следующим образом:
models.text_encoder = TextEncoderWrapper.from_model(
torch.jit.load(os.path.join(directory, 'text_encoder.pt')))
Такая конструкция сохранила исходную архитектуру BLIP без изменений и при этом удовлетворила требования Neuron SDK к I/O interface за счет легковесных wrapper-классов. Она также обеспечила модульный workflow на уровне компонентов как для компиляции, так и для развертывания, позволяя независимо компилировать и управлять каждым submodule BLIP. В результате использование model.text_encoder.model критично на этапе компиляции для прямой Neuron-оптимизации, тогда как wrapper-классы берут на себя форматирование входов и выходов во время инференса для стабильной работы на Inferentia2.
Стресс-тестирование
Чтобы проверить производительность на масштабе, Tomofun провела stress tests, имитирующие реальные нагрузки камер Furbo. Каждый видеопоток запускал запросы на определение действий, например: «Собака лает?», «Собака играет?» или «Собака грызет мебель?». Тесты подтвердили, что Inf2-инстансы (один чип Inferentia2, 32 ГБ памяти) способны обеспечивать необходимую пропускную способность при низкой latency. Помимо точности, тесты показали, что развертывание на Inf2 может обрабатывать одновременные запросы от сотен тысяч устройств, что делает его подходящим для глобальной круглосуточной базы клиентов Furbo. Важно, что базовой линией сравнения были GPU-инстансы с on-demand pricing model, которые отражали затраты Tomofun до миграции на Inf2. Переход с этих GPU on-demand deployments на Inf2.xlarge-инстансы с Inferentia2 позволил Tomofun добиться сокращения затрат на 83% без ухудшения производительности.
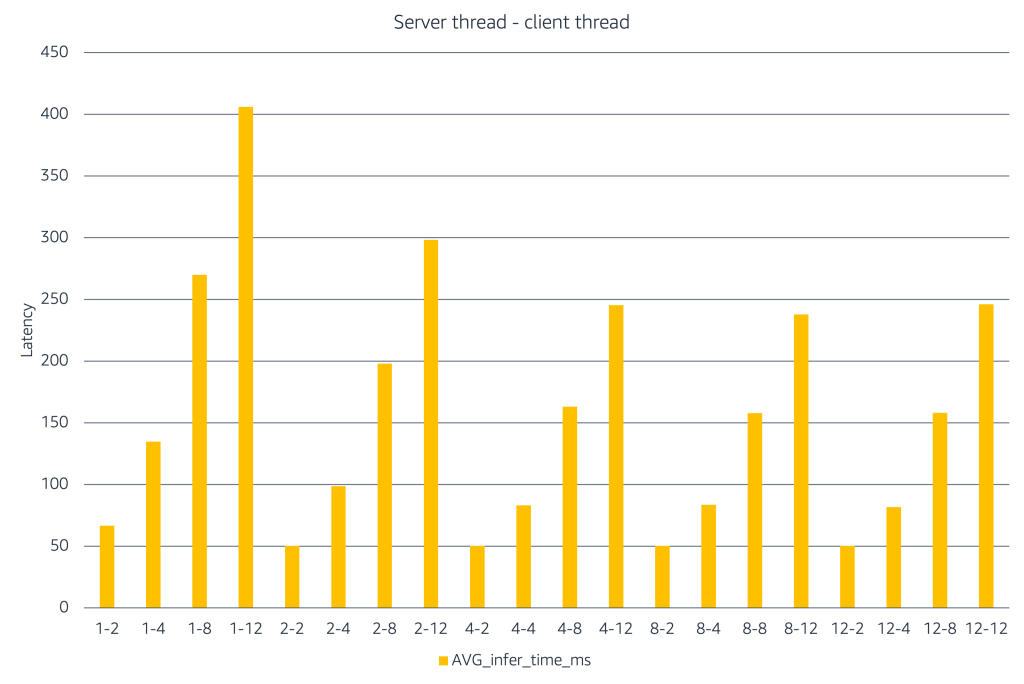
График показывает, как меняется задержка инференса по мере роста server- и client-concurrency. Ось X представляет комбинации меток, где указано число server threads — client threads, чтобы смоделировать производительность при разных сценариях нагрузки. Когда доступно мало server threads, увеличение числа client threads быстро повышает задержку. Увеличение количества server threads помогает поглощать эту нагрузку и удерживать задержку ниже. На более высоких уровнях concurrency задержка растет, а выигрыш от добавления ресурсов выравнивается, что указывает на saturation. Этот эксперимент показывает, что командам следует использовать load testing, чтобы найти правильный баланс между client concurrency и server capacity, а затем ограничивать concurrency этим диапазоном, чтобы добиться нужного компромисса между latency и стоимостью в production.
Заключение
Перенеся инференс BLIP на EC2 Inf2-инстансы на базе AWS Inferentia, Tomofun снизила затраты на развертывание приложения Furbo на 83%. Переход с GPU на Inferentia2 оказался бесшовным, поскольку миграция потребовала только легковесных wrapper-классов и не затронула core logic BLIP. Тестирование подтвердило, что использование Inferentia2 не только сокращает затраты на развертывание, но и сохраняет высокую пропускную способность для инференса в реальном времени на масштабе. Tomofun планирует переносить на Inferentia2 и другие нагрузки, поскольку платформа поддерживает задачи за пределами vision-language моделей, например обнаружение аудиособытий для распознавания лая и потенциальную будущую интеграцию с large language models для улучшения взаимодействия владельцев с питомцами. Кроме того, внедрение AWS Deep Learning Containers (DLCs) уже включено в roadmap как следующий шаг: использование готовых улучшенных контейнерных образов должно упростить управление зависимостями и ускорить inference workflows.
Чтобы узнать, как реализовать похожие улучшения, изучите документацию и примеры AWS Neuron, которые можно найти в документации AWS Neuron. Вы также можете посетить сайт Furbo, чтобы изучить AI-функции Furbo и увидеть, как экосистема Furbo помогает обеспечивать безопасность питомцев.
Материал — перевод статьи с английского.
Оригинал: Cost effective deployment of vision-language models for pet behavior detection on AWS Inferentia2