Как зарезервировать GPU-квоту для ML-загрузок с помощью EC2 Capacity Blocks for ML и SageMaker training plans

По мере того как компании разных размеров внедряют обучение, дообучение и инференс на базе графических процессоров (GPU) для машинного обучения (ML), спрос на GPU-квоты опережает отраслевое предложение. Этот дисбаланс сделал GPU дефицитным ресурсом, что создает проблему для клиентов, которым нужен надежный доступ к GPU-вычислениям для своих ML-нагрузок.
Когда вы сталкиваетесь с ограничениями по GPU-квоте, можно рассмотреть on-demand capacity reservations (ODCRs). ODCR подходят для запланированных, стабильных нагрузок с хорошо понятным профилем использования. Доступность ODCR на короткий срок для GPU-инстансов, особенно инстансов семейства P, часто ограничена. Кроме того, без долгосрочного контракта ODCR тарифицируются по ставкам on-demand, не давая ценового преимущества. Это делает ODCR неподходящими для коротких или исследовательских задач, таких как тестирование, оценки или мероприятия. Нужен более управляемый подход к резервированию краткосрочной GPU-квоты.
В этом материале показано, как зарезервировать GPU-квоту для краткосрочных нагрузок с помощью Amazon Elastic Compute Cloud (Amazon EC2) Capacity Blocks for ML и Amazon SageMaker training plans. Эти решения помогают справляться с дефицитом GPU, когда нужна краткосрочная мощность для нагрузочного тестирования, валидации модели, воркшопов с ограничением по времени или подготовки инференс-мощностей перед релизом.
Обзор решения и варианты краткосрочного доступа к GPU
Для краткосрочных задач в AWS есть несколько способов получить доступ к GPU-квоте:
On-demand GPU-инстансы
On-demand-инстансы обычно становятся первым вариантом для краткосрочного использования GPU. Если квота доступна в момент запуска, можно сразу начать работу без предварительных обязательств. Это хорошо подходит для разовых экспериментов, коротких тестов и задач разработки.
Доступность on-demand GPU-квоты зависит от регионального предложения и текущего спроса, а ситуация может быстро меняться. Если вы остановите или уменьшите инстанс, позже может не получиться снова получить ту же квоту. Из-за этой неопределенности GPU-инстансы нередко держат включенными дольше, чем нужно, что увеличивает затраты. Используйте on-demand-инстансы, когда нагрузка допускает возможную задержку запуска или когда сроки гибкие.
Spot GPU-инстансы
Spot-инстансы могут снизить стоимость GPU-вычислений до 90%, но в обмен на экономию вы жертвуете предсказуемостью доступности. Spot-квота зависит от неиспользуемой емкости в AWS Region. Инстансы могут быть прерваны, когда Amazon EC2 потребуется вернуть эту емкость, поэтому spot-инстансы подходят только для нагрузок, которые умеют переживать прерывания.
Для ML-нагрузок spot-инстансы особенно хорошо работают, если вы можете сохранять контрольные точки и возобновлять выполнение. Рекомендуемые сценарии включают распределенные задачи обучения с периодическими checkpoint, пакетный инференс, который можно повторить, и среды для воркшопов, рассчитанные на частичную доступность ресурсов.
Amazon EC2 Capacity Blocks for ML
Amazon EC2 Capacity Blocks for ML резервируют GPU-квоту на определенное временное окно, чтобы нужные инстансы были доступны в течение зарезервированного периода. В отличие от ODCR, Capacity Blocks полностью управляются через self-service и обеспечивают лучшую краткосрочную доступность GPU-инстансов со скидкой 40–50%. Каждый Capacity Block — это резервирование определенного числа выбранного типа инстансов на заданный срок. Можно:
- Забронировать время начала за восемь недель вперед.
- Выбрать длительность от 1 до 14 дней с шагом в 1 день или от 15 до 182 дней с шагом в 7 дней.
- Настроить до 64 инстансов в одном Capacity Block.
- Настроить до 256 инстансов через несколько Capacity Blocks в разных аккаунтах в составе AWS Organizations на конкретную дату (для достижения этого лимита нужно минимум четыре блока; блоки могут работать одновременно).
- Организации могут покупать Capacity Blocks и распределять их между несколькими аккаунтами, позволяя разным нагрузкам использовать общий пул зарезервированной емкости без дополнительной платы.
Capacity Blocks подходят для нагрузок, которые выполняются напрямую на Amazon EC2, где вы сами управляете операционной системой, сетью и слоями оркестрации.
Соглашение об уровне сервиса (SLA) и аппаратные сбои: если в период резервации происходит аппаратный сбой, можно завершить затронутый инстанс и вручную запустить замену в том же резервировании Capacity Blocks. Система возвращает зарезервированный слот емкости в ваш резерв примерно через 10 минут после очистки. Amazon EC2 поддерживает буфер внутри каждого Capacity Block, чтобы при деградации оборудования можно было перезапустить инстансы без дополнительной платы.
Примечание: у Capacity Blocks есть следующие ограничения:
- Поддерживаются только отдельные семейства инстансов Amazon EC2, например P5, Trn1 и Trn2; они не покрывают все типы GPU-инстансов.
- Нельзя резервировать емкость для управляемых Amazon SageMaker типов инстансов, таких как ml.p4dn или ml.p5.
- Их нельзя использовать совместно с Amazon SageMaker.
- Их нельзя перемещать или делить.
- UltraServer Capacity Blocks привязаны к аккаунту AWS, в котором они были куплены, и не могут быть общими между аккаунтами или внутри AWS Organization.
Amazon SageMaker training plans
Amazon SageMaker training plans дают возможность резервировать GPU-квоту для ML-нагрузок в управляемой среде Amazon SageMaker AI, например для training jobs, кластеров Amazon SageMaker HyperPod и инференса. SageMaker training plans не взаимозаменяемы с EC2 Capacity Blocks. С помощью SageMaker training plans можно:
- Планировать резервирования для конкретных GPU-инстансов и сроков.
- Получать доступ к квоте без управления базовой инфраструктурой.
- Использовать широкий набор ускоренных вычислительных вариантов, включая новейшие NVIDIA GPU и ускорители AWS Trainium.
Обратите внимание, что инстансы семейства G (кроме G6) сейчас не поддерживаются SageMaker training plans. Если вам нужны инстансы G6, обратитесь в свою команду по работе с аккаунтом AWS. Подробности о поддерживаемых типах инстансов в конкретном AWS Region, вариантах длительности и количества см. в разделе Поддерживаемые типы инстансов, AWS Regions и цены.
Amazon SageMaker training plans применимы к:
- SageMaker training jobs
- Кластерам SageMaker HyperPod
- нагрузкам SageMaker Inference
Выбирайте этот вариант, если хотите, чтобы Amazon SageMaker AI управлял выделением инстансов, масштабированием и жизненным циклом, при этом сохраняя зарезервированную емкость на определенное окно времени.
Фреймворк принятия решения: как выбрать подходящий вариант
Планируя краткосрочную стратегию по GPU, следует оценивать варианты по трем ключевым факторам:
- Доступность: от on-demand до зарезервированной емкости.
- Модель затрат: оплата по мере использования или предварительное обязательство с ценой ниже on-demand.
- Среда выполнения нагрузки: прямой доступ к Amazon EC2 или управляемые нагрузки Amazon SageMaker.
- От краткосрочного к долгосрочному планированию емкости: хотя этот материал посвящен краткосрочному резервированию GPU, вам может потребоваться планирование для более длительных или повторяющихся нагрузок. Можно проводить оценку на основе исторических данных или использовать краткосрочные GPU-ресурсы для нагрузочного тестирования и лучшего понимания того, сколько инстансов и какого типа потребуется в production. Для production-развертываний или крупных мероприятий, требующих значительных GPU-ресурсов, начинайте планирование как минимум за три недели. Работайте со своей командой AWS account team, чтобы оценить требования и выстроить стратегию емкости под ваши сроки.
Соображения по стоимости
- Capacity Blocks for ML требуют предоплаты и предлагают почасовые ставки на 40–50% ниже, чем on-demand. Например, в US East (N. Virginia) p5.48xlarge стоит $34.608 в час с Capacity Blocks против $55.04 в час по on-demand.
- SageMaker training plans стоят на 70–75% ниже on-demand. Вы оплачиваете резервирование заранее в момент его планирования. AWS регулярно обновляет цены в зависимости от изменений спроса и предложения. Вы платите ставку, актуальную на момент оформления резерва, даже если training plan начнет действовать позже, после изменения цены.
- Если инстансы не работают непрерывно в течение всего периода резервирования, общая стоимость резервов может оказаться выше, чем on-demand. Оценивайте вариант с учетом фактического времени работы вашей нагрузки.
- Оговорка: все ценовые данные в этом разделе основаны на общедоступных ценах AWS на дату публикации и могут измениться. За актуальными ценами обращайтесь к Amazon EC2 pricing и SageMaker AI pricing.
Процесс принятия решения
Начинайте с наименее ограничивающего варианта и переходите к зарезервированной емкости, когда доступность или сроки становятся критичными.
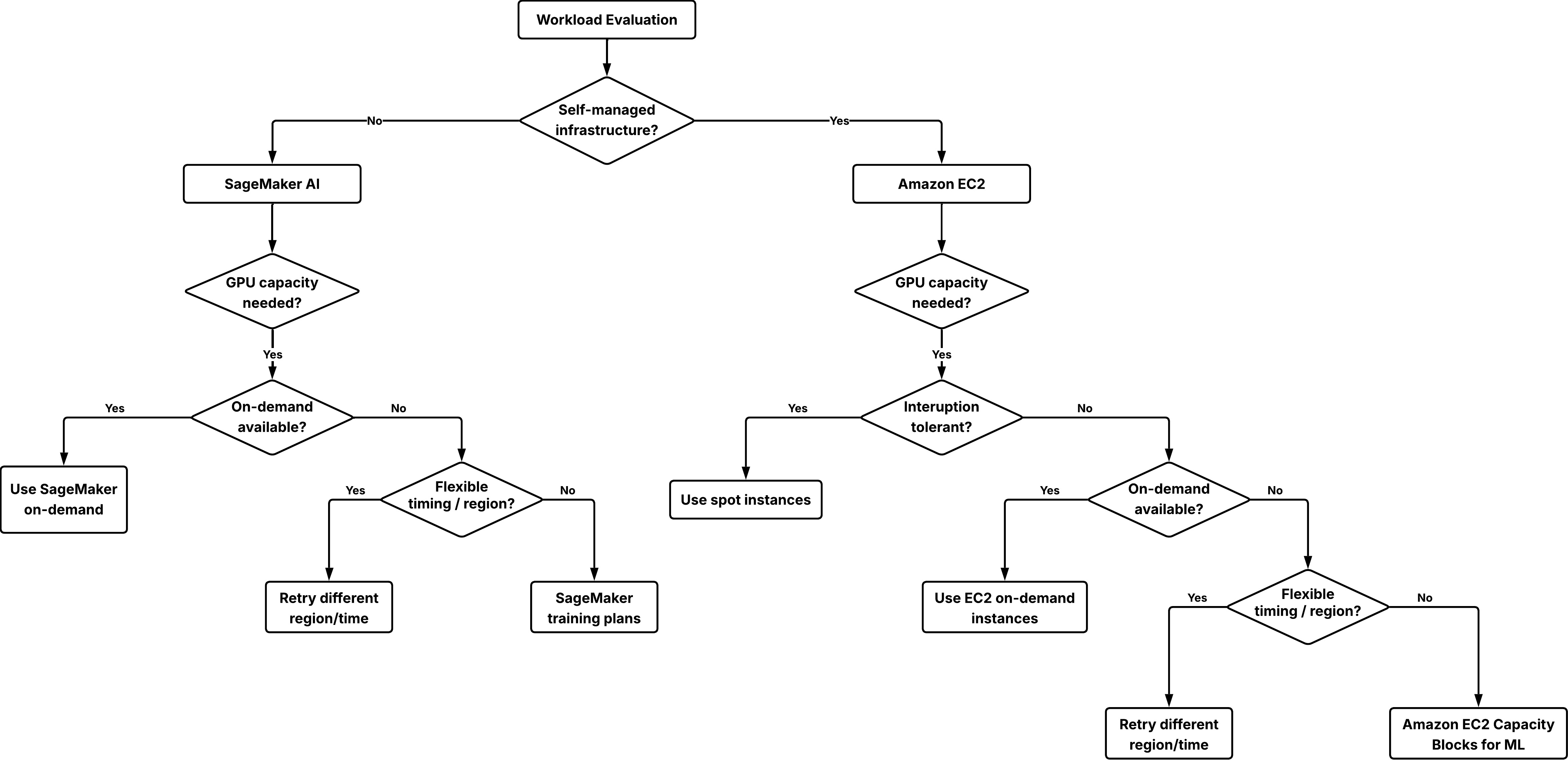
Шаг 1: Определите модель управления инфраструктурой
- Если вам нужен полный контроль над операционной системой, сетью и оркестрацией, используйте Amazon EC2 и применяйте on-demand-инстансы, spot-инстансы или Capacity Blocks.
- Если вам нужен управляемый сервис, который берет на себя выделение инфраструктуры и операции, используйте Amazon SageMaker AI и применяйте SageMaker on-demand или SageMaker training plans для типов инстансов ml.*.
Шаг 2: Сначала попробуйте on-demand-квоту
Для нагрузок как в Amazon EC2, так и в Amazon SageMaker AI сначала пробуйте on-demand-квоту. Такой подход:
- не требует предварительных обязательств;
- позволяет немедленно начать работу, если квота доступна.
Если первый запуск не удался, попробуйте следующие варианты повышения гибкости:
- выберите другой AWS Region, где квота может быть доступна;
- сдвиньте старт на часы с меньшей нагрузкой, когда спрос обычно ниже;
- используйте spot-инстансы как дополнение для нагрузок, которые могут пережить прерывания.
Шаг 3: Используйте зарезервированную квоту, когда нужна предсказуемость
Если нагрузка должна стартовать в конкретное время или если выполнение зависит от гарантированного доступа к GPU, резервирование становится правильным выбором:
- для нагрузок Amazon EC2 используйте Capacity Blocks for ML;
- для нагрузок Amazon SageMaker AI используйте Amazon SageMaker training plans для training jobs, кластеров HyperPod или инференса.
Техническая реализация: резервирование GPU-квоты для инференса с помощью SageMaker training plans
Этот раздел показывает, как резервировать и использовать GPU-квоту для инференса, управляемого Amazon SageMaker training plans. Обратите внимание: резервирования SageMaker training plans привязаны к выбранному целевому ресурсу. План, купленный для инференса, нельзя использовать для Training Jobs или кластеров HyperPod, и наоборот.
Для других сценариев:
- Если вы резервируете квоту для SageMaker training jobs или кластеров SageMaker HyperPod, см. раздел создание training plans для training jobs или HyperPod clusters.
- Если нагрузка работает напрямую на Amazon EC2 и требует зарезервированной емкости на фиксированное окно, см. Capacity Blocks for ML.
Предварительные требования
Перед началом убедитесь, что у вас есть:
- аккаунт AWS с нужными правами AWS Identity and Access Management (IAM);
- для создания training plans используйте управляемую политику AmazonSageMakerTrainingPlanCreateAccess;
- для создания, описания и удаления inference endpoints используйте следующую политику:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sagemaker:CreateEndpointConfig",
"sagemaker:CreateEndpoint",
"sagemaker:DescribeEndpoint",
"sagemaker:DeleteEndpoint",
"sagemaker:DeleteEndpointConfig"
],
"Resource": [
"arn:aws:sagemaker:*:*:endpoint/*",
"arn:aws:sagemaker:*:*:endpoint-config/*"
]
}
]
}
- созданный и готовый к развертыванию ресурс модели SageMaker AI. Инструкции см. в разделе создание модели;
- AWS Command Line Interface (AWS CLI) версии 2.0 или выше.
Создание training plan
Чтобы начать, откройте консоль Amazon SageMaker AI, выберите Training plans в левом меню и нажмите Create training plan.
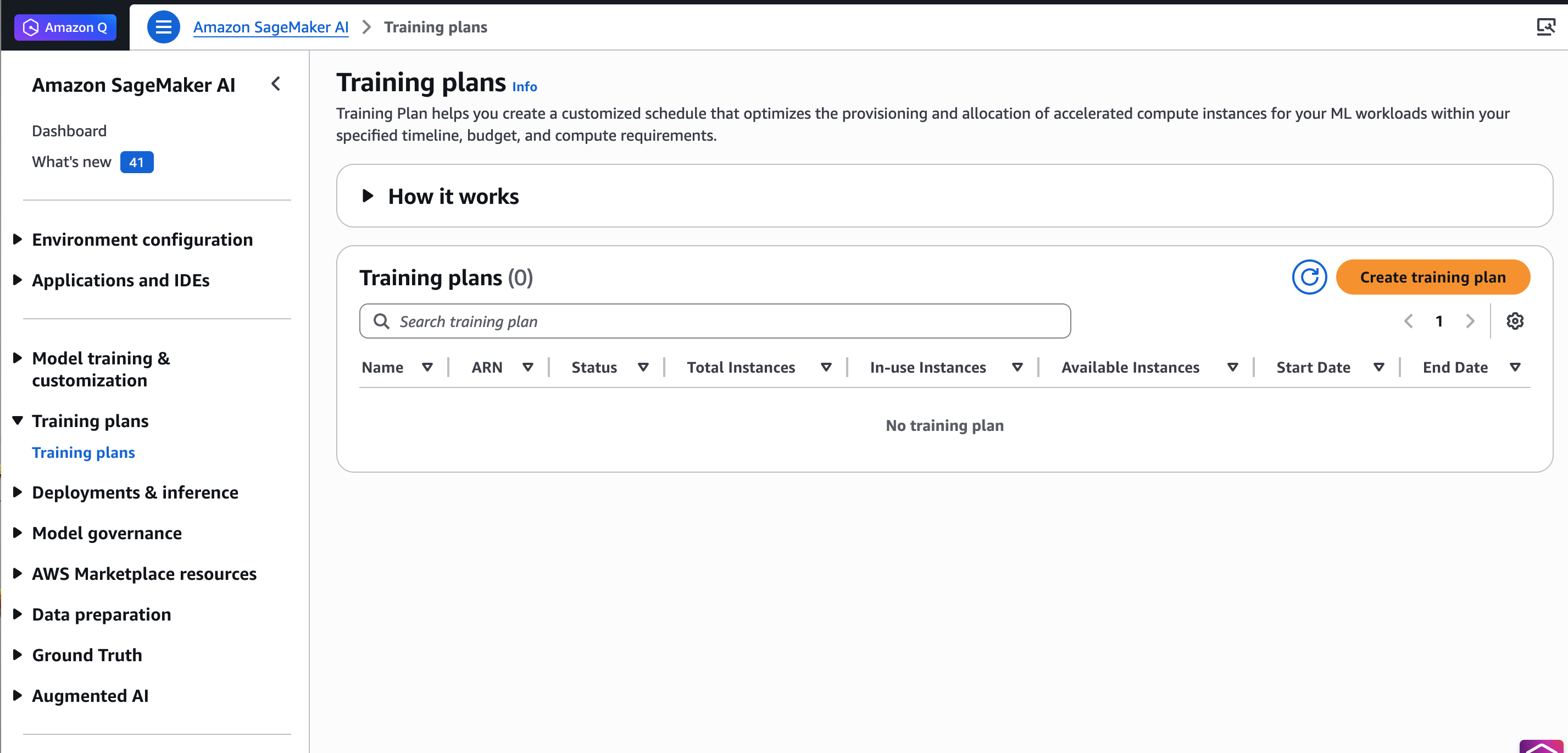
Например, выберите предпочтительную дату обучения и длительность (1 день), тип и количество инстансов (1 ml.trn1.32xlarge) для Inference Endpoint и нажмите Find training plan.
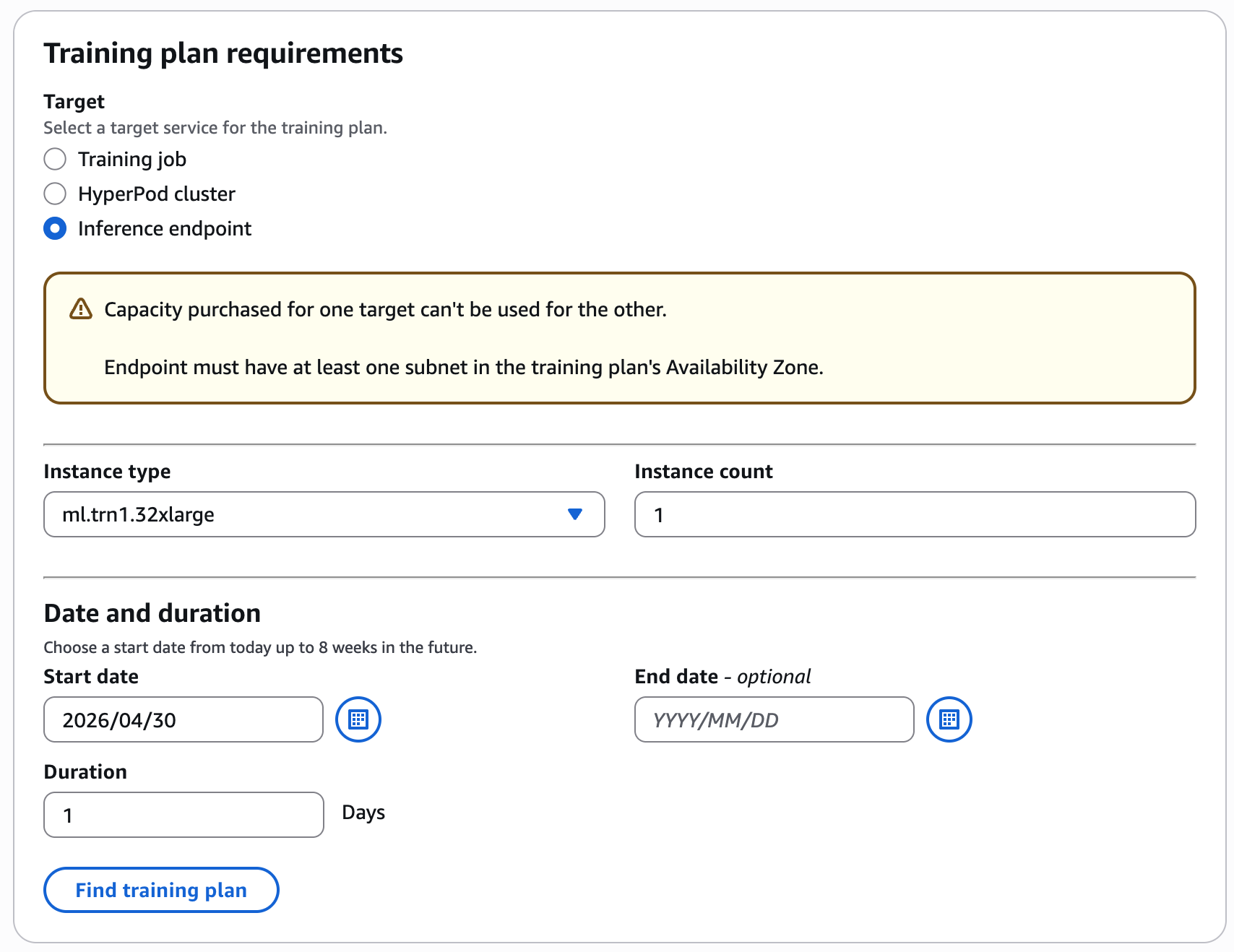
Консоль покажет доступные планы с общей стоимостью.
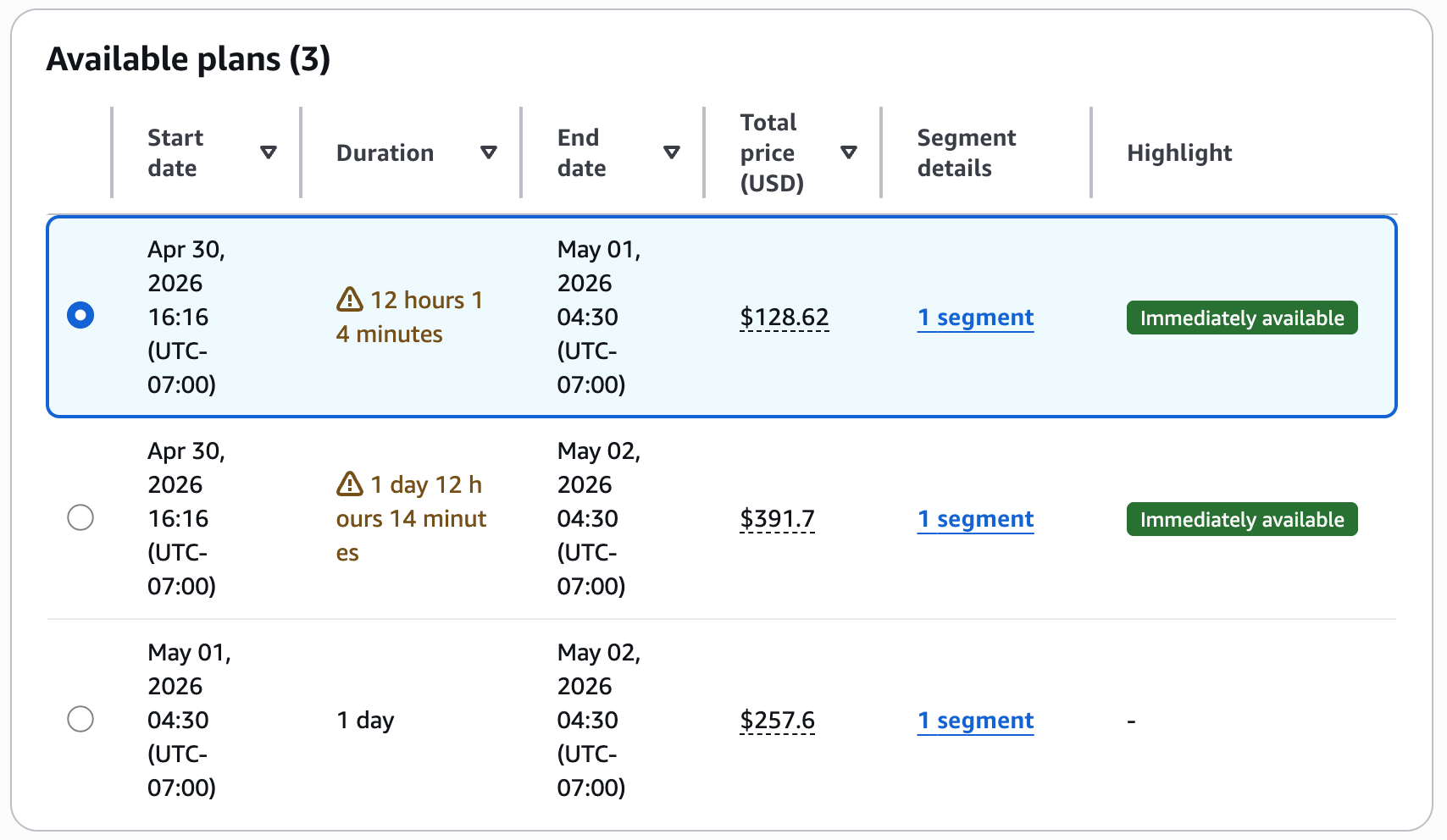
Если вы принимаете этот training plan, на следующем шаге добавьте сведения о training details и нажмите Create your plan.
Примечание: SageMaker training plans нельзя отменить после покупки. Резервирование автоматически истечет в конце зарезервированного периода.
Мониторинг статуса training plan
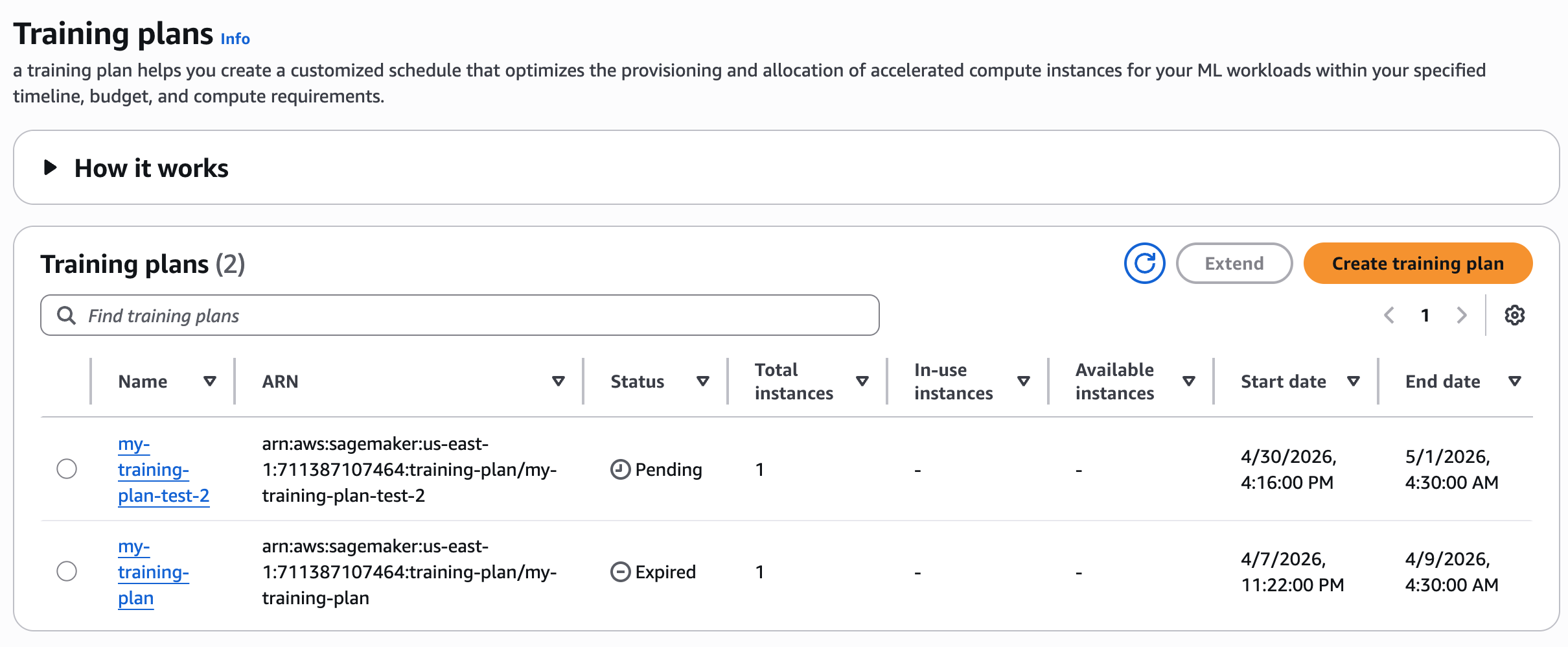
После создания training plan вы увидите список планов. Сначала план переходит в состояние Pending, ожидая оплаты. Вы оплачиваете полную стоимость training plan заранее. После завершения обработки платежа AWS план переходит в состояние Scheduled. В день начала план становится Active, и система выделяет ресурсы для вашего использования.
Проверка статуса training plan через AWS CLI
Используйте следующую команду, чтобы проверить статус training plan:
aws sagemaker describe-training-plan \
--training-plan-name your-training-plan-name \
--region your-region
Когда ответ покажет "Status": "Active", можно начинать выполнение задач инференса. Убедитесь, что поле TargetResources содержит endpoint, чтобы подтвердить, что план настроен для инференс-нагрузок.
Создание конфигурации endpoint
Используйте следующую команду, чтобы создать конфигурацию endpoint с ресурсами training plan:
aws sagemaker create-endpoint-config \
--endpoint-config-name your-endpoint-config-name \
--production-variants '[
{
"VariantName": "your-variant-name",
"ModelName": "your-model-name",
"InitialInstanceCount": 1,
"InstanceType": "ml.trn1.32xlarge",
"CapacityReservationConfig": {
"MlReservationArn": "your-training-plan-arn",
"CapacityReservationPreference": "capacity-reservations-only"
}
}
]'
Развертывание endpoint
Создайте ресурс endpoint, указав конфигурацию endpoint из предыдущего шага:
aws sagemaker create-endpoint \
--endpoint-name your-endpoint-name \
--endpoint-config-name your-endpoint-config-name
Проверка статуса endpoint
Проверьте статус endpoint и статус резервации емкости training plan:
aws sagemaker describe-endpoint \
--endpoint-name your-endpoint-name \
--region your-region
Очистка ресурсов
Чтобы избежать дальнейших затрат, удалите созданные ресурсы:
Удалите endpoint:
aws sagemaker delete-endpoint --endpoint-name your-endpoint-name
Удалите конфигурацию endpoint:
aws sagemaker delete-endpoint-config --endpoint-config-name your-endpoint-config-name
Вывод
Резервирование GPU-квоты для временных нагрузок требует иного подхода, чем планирование долгосрочного стабильного использования. В этом материале вы узнали, как подходить к краткосрочному планированию GPU-квоты, если:
- начинать с on-demand-квоты и по возможности повышать гибкость;
- разделять нагрузки на базе Amazon EC2 и управляемые нагрузки Amazon SageMaker AI;
- резервировать емкость с помощью Capacity Blocks или SageMaker training plans, когда нужны доступность и предсказуемость.
Также вы узнали, как использовать SageMaker training plans, чтобы заранее зарезервировать GPU-квоту. Это помогает снизить операционные сложности при подготовке инференс-мощностей для запланированных оценок, релизов или ожидаемого роста трафика.
Чтобы узнать больше, см. следующие ресурсы:
- Capacity Blocks for ML
- Резервирование training plans для training jobs или HyperPod clusters
- Amazon SageMaker AI теперь поддерживает Flexible Training Plans capacity для инференса
- Amazon SageMaker AI Pricing
- Резервирование вычислительной мощности с помощью EC2 On-Demand Capacity Reservations
Материал — перевод статьи с английского.