Обучение с верifiable rewards и GRPO на SageMaker AI: как повысить точность математических рассуждений Qwen2.5-0.5B

Обучение больших языковых моделей требует точной обратной связи, но традиционное обучение с подкреплением (RL) часто сталкивается с ненадежностью reward-сигналов. Качество этих сигналов напрямую влияет на то, как модели учатся и принимают решения. Однако создание надежных механизмов обратной связи может быть сложным и подверженным ошибкам. В реальных сценариях обучения часто возникают скрытые смещения, непреднамеренные стимулы и расплывчатые критерии успеха, которые способны сорвать процесс обучения, приводя к непредсказуемому поведению модели или к результатам, не соответствующим целям.
В этом материале вы узнаете, как реализовать reinforcement learning with verifiable rewards (RLVR), чтобы добавить в reward-сигналы проверяемость и прозрачность и тем самым улучшить качество обучения. Подход особенно хорошо работает там, где ответы можно объективно проверить на корректность — например, в задачах математического рассуждения, генерации кода или символических преобразований. Также вы увидите, как сочетать Group Relative Policy Optimization (GRPO) и few-shot примеры, чтобы дополнительно повысить качество. В качестве примера используется набор данных GSM8K (Grade School Math 8K: набор школьных математических задач), чтобы повысить точность решения задач по математике, но описанные техники можно адаптировать и для множества других сценариев.
Технический обзор
Перед тем как переходить к реализации, полезно понять базовые концепции RL, на которых строится этот подход. RL решает задачи обучения моделей, создавая структурированную систему обратной связи через reward-сигналы. Эта парадигма позволяет моделям учиться через взаимодействие, получая обратную связь, которая направляет их к оптимальному поведению. RL дает моделям возможность итеративно улучшать ответы на основе четко определенных сигналов о качестве выходных данных, что делает его особенно эффективным для обучения моделей, взаимодействующих с пользователями и адаптирующихся по результатам своих действий. Традиционный RL подчеркнул важный момент: качество reward-сигнала имеет решающее значение. Если reward-функции неточны или неполны, модели могут заниматься reward hacking — находить не предусмотренные способы максимизировать оценку, не достигая нужного поведения. Осознание этого ограничения привело к более строгим подходам, ориентированным на создание надежных и четко определенных reward-функций.
RLVR решает проблему reward hacking через rule-based feedback, заданную разработчиком модели. Он использует программные reward-функции, которые автоматически оценивают ответы по заданным критериям, позволяя быстро итеративно улучшать модель без узкого места в виде сбора человеческих оценок. Такие «проверяемые» rewards строятся на объективных и воспроизводимых правилах, поэтому RLVR особенно полезен при меняющихся требованиях: он учится общим стратегиям оптимизации и быстро адаптируется к новым сценариям. GRPO — это алгоритм обучения с подкреплением, который улучшает обучение AI-моделей, сравнивая результаты внутри групп, а не по всему набору данных сразу. Он организует обучающие данные в осмысленные группы и оптимизирует качество относительно базовой линии каждой группы, уделяя каждому классу задач соответствующее внимание. Такая групповая оптимизация снижает дисперсию обучения, ускоряет сходимость и может давать модели, стабильно работающие по разным категориям. Сочетание RLVR и GRPO создает схему, в которой автоматизированные rewards направляют обучение, а group-relative optimization помогает добиваться сбалансированной производительности.
Вы задаете reward-функции для разных аспектов задачи, а GRPO рассматривает их как отдельные группы в процессе обучения, что позволяет одновременно улучшать несколько измерений качества. Такое сочетание обеспечивает быструю адаптацию и устойчивую производительность, что особенно полезно в динамических средах, где требуется обобщение за пределы обучающего распределения. Добавление few-shot learning усиливает эту схему тремя способами. Во-первых, few-shot примеры дают шаблоны, показывающие модели, как выглядят хорошие ответы, сужая пространство поиска при исследовании вариантов. Во-вторых, GRPO использует эти примеры, генерируя несколько кандидатов ответа на каждый запрос и обучаясь на их относительной эффективности внутри каждой группы. В-третьих, проверяемые rewards сразу подтверждают, какие подходы работают. В результате обучение ускоряется: модель начинает с конкретных примеров нужного формата, эффективно исследует варианты через групповое сравнение и получает однозначную обратную связь о корректности.
Обзор решения
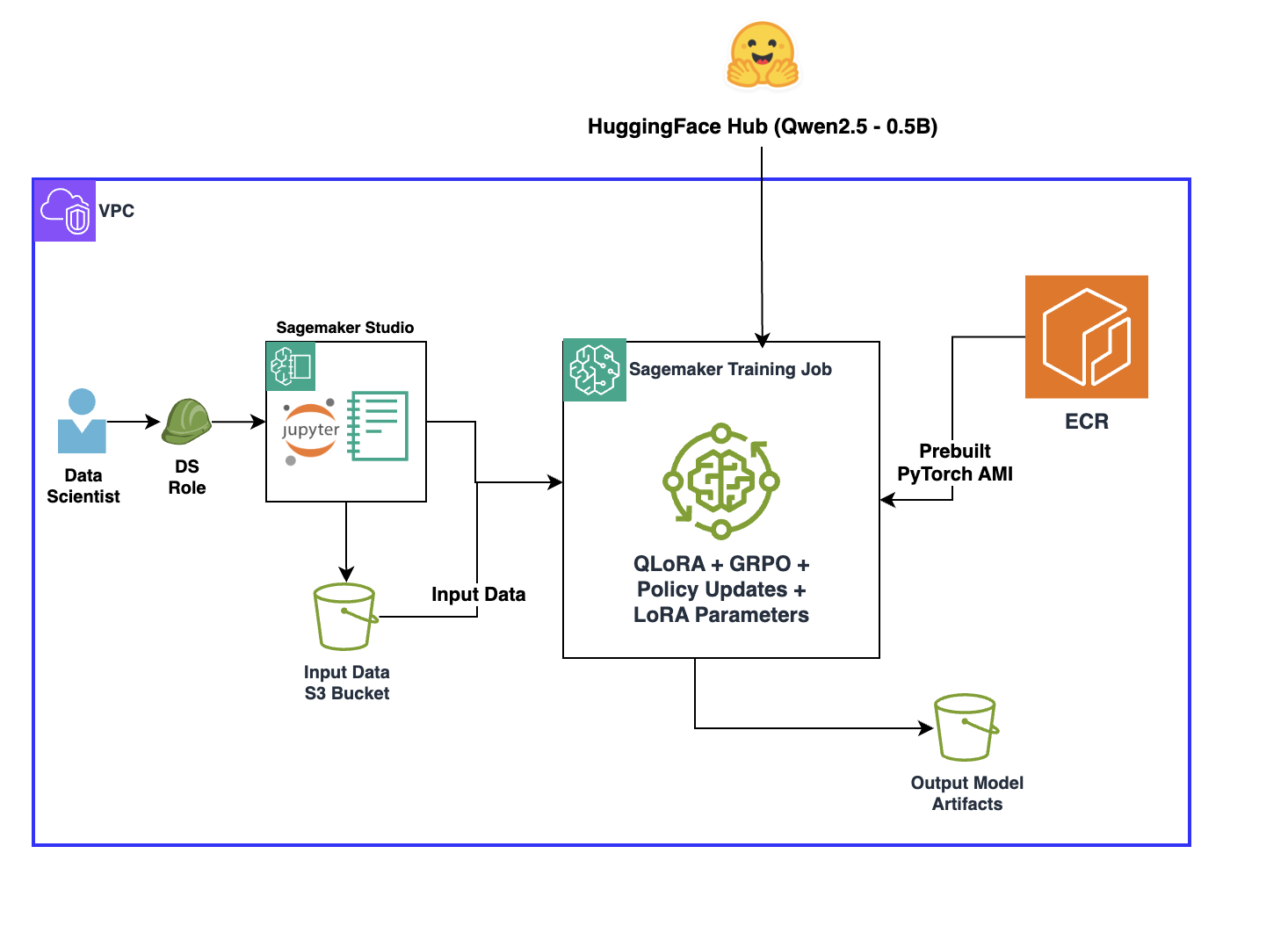
В этом разделе вы пройдете через процесс дообучения модели Qwen2.5-0.5B в SageMaker AI с использованием Amazon Amazon SageMaker Training Jobs. SageMaker Training jobs поддерживают распределенные конфигурации с несколькими GPU и несколькими узлами, поэтому вы можете по требованию поднимать высокопроизводительные кластеры, быстрее обучать модели с миллиардами параметров и автоматически завершать ресурсы после окончания задания.
Примечание: хотя для этого сценария выбрана Qwen2.5-0.5B, для таких задач, как генерация кода, потребуется более крупная модель, например Qwen2.5-Coder-7B, а следовательно, и более мощные экземпляры для обучения.
Необходимые условия
Чтобы запустить пример из этого материала в Amazon SageMaker AI, необходимо выполнить следующие условия:
- Учетная запись AWS, в которой будут размещаться ваши ресурсы AWS.
- Роль AWS Identity and Access Management (IAM) для доступа к SageMaker AI. Подробнее о том, как IAM работает с SageMaker AI, см. в статье AWS Identity and Access Management for Amazon SageMaker AI.
- Вы можете запускать ноутбук из этого материала из предпочитаемой среды разработки, включая IDE, такие как PyCharm или Visual Studio Code, если ваши учетные данные AWS корректно настроены и дают доступ к вашей учетной записи AWS. Чтобы настроить локальную среду, см. Configuring settings for the AWS CLI. При желании можно использовать Amazon SageMaker Studio для более простого процесса разработки в SageMaker AI.
- Если вы повторяете шаги из материала, вам понадобится тренировочный экземпляр ml.p4d.24xlarge. Для запуска кода обучения примера нужен доступ к этим экземплярам SageMaker training. Если вы не уверены, откройте квоты сервиса AWS в AWS Management Console: выберите Amazon SageMaker в качестве сервиса AWS в разделе Manage Quotas. Выберите ml.p4d.24xlarge для training job usage и запросите увеличение квоты на уровне аккаунта.
- Доступ к репозиторию GitHub: https://github.com/aws-samples/amazon-sagemaker-generativeai
Настройка среды
Вы можете использовать любую IDE, например VS Code или PyCharm, но убедитесь, что ваша локальная среда настроена для работы с AWS, как указано в prerequisites.
Чтобы использовать SageMaker Studio JupyterLab spaces, выполните следующие шаги:
- В консоли Amazon SageMaker AI выберите Domains в панели навигации, а затем откройте свой domain.
- В панели навигации в разделе Applications and IDEs выберите Studio.
- На вкладке User profiles найдите свой профиль пользователя, затем выберите Launch и Studio.
- В Amazon SageMaker Studio запустите экземпляр ноутбука JupyterLab
ml.t3.mediumс объемом хранилища не менее 50 GB.
Большой экземпляр ноутбука не нужен, потому что задача дообучения будет выполняться на отдельном временном training instance с GPU-ускорением.
- Чтобы начать дообучение, сначала клонируйте GitHub repo и перейдите в каталог
3_distributed_training/reinforcement-learning/grpo-with-verifiable-reward, затем откройте model-finetuning-grpo-rlvr.ipynb - Ноутбук с ядром Python 3.12 или более поздней версии
Подготовка набора данных для дообучения
Запуск GRPO с RLVR требует наличия финального ответа на каждый вопрос, чтобы вычислять reward. Сначала подготовьте данные, извлекая конечный ответ для каждого вопроса.
dataset = GSM8K(split='train', include_answer=False, include_reasoning=True, few_shot=True, num_shots=8, seed=None, cot=True).dataset.shuffle(seed=42)
Dataset({
features: ['question', 'answer', 'prompt', 'final_answer'],
num_rows: 7473
})
Кроме того, в этом примере используются few-shot примеры (8 shots), чтобы повысить эффективность обучения модели. Подробнее о few-shot примерах в reinforcement learning см. в статье “Reinforcement Learning for Reasoning in Large Language Models with One Training Example”. Хотя исследование фокусируется на single-shot примерах, в этом материале показаны результаты как с одним, так и с несколькими shots.
Каждый вход будет содержать 8 примеров, а затем задачу, которую нужно решить:
"Question: Mark has $50 and buys a toy that costs $35. How much money does he have left?
Solution: Let's think step by step. To find out how much money Mark has left, subtract the cost of the toy from the total amount of money Mark has. So, $50 - $35 = $15.
#### The final answer is 15
Question: Emily has 3 times as many pencils as Alice. If Alice has 15 pencils, how many pencils does Emily have?
Solution: Let's think step by step. To find out how many pencils Emily has, we multiply the number of pencils Alice has by 3. Alice has 15 pencils, so Emily has 15 * 3 = 45 pencils.
#### The final answer is 45
Question: Jack has collected 12 more marbles than Kevin. If Kevin has 27 marbles, how many marbles does Jack have?
Solution: Let's think step by step. To find how many marbles Jack has, we add 12 to the number of marbles Kevin has. So, Jack has 27 + 12 = 39 marbles.
#### The final answer is 39
Question: There are 24 students in a classroom. If each group must have 4 students, how many groups can be formed?
Solution: Let's think step by step. To find how many groups can be formed, we divide the number of students by the number of students per group. So, 24 / 4 = 6 groups can be formed.
#### The final answer is 6
Question: Samantha baked 40 cookies and wants to divide them equally into bags, with each bag containing 5 cookies. How many bags will Samantha need?
Solution: Let's think step by step. To find the number of bags needed, divide the total number of cookies by the number of cookies per bag. Thus, 40 divided by 5 equals 8.
#### The final answer is 8
Question: A pack of pencils costs $4. If you buy 7 packs, how much will you spend in total?
Solution: Let's think step by step. The total cost is found by multiplying the cost per pack by the number of packs. Hence, you spend 7 * $4 = $28.
#### The final answer is 28
Question: A book has 240 pages, and Sarah reads 20 pages each day. How many days will it take her to finish the book?
Solution: Let's think step by step. Sarah reads 20 pages per day, so we divide the total pages by the number of pages she reads per day. Therefore, it takes her 240 / 20 = 12 days to finish the book.
#### The final answer is 12
Question: A farmer has a total of 80 apples and oranges. If he has 30 apples, how many oranges does he have?
Solution: Let's think step by step. To determine the number of oranges, we subtract the number of apples from the total number of fruits. So, the number of oranges is 80 - 30 = 50.\n
#### The final answer is 50
Question: Mimi picked up 2 dozen seashells on the beach. Kyle found twice as many shells as Mimi and put them in his pocket. Leigh grabbed one-third of the shells that Kyle found. How many seashells did Leigh have?
Solution: Let's think step by step.
После подготовки данных сохраните 10 процентов данных как validation set и загрузите и training, и validation set в S3.
Функция проверяемого rewards
Эта реализация GRPO для математического рассуждения использует двойную систему rewards, которая дает объективную, проверяемую обратную связь во время обучения. Подход опирается на внутреннюю проверяемость математических задач, чтобы создавать надежные обучающие сигналы без необходимости в человеческой разметке или субъективной оценке. Вы реализуете две взаимодополняющие reward-функции, которые вместе направляют модель как к правильному формату ответа, так и к математической корректности результата:
Функция reward за формат
Эта функция помогает убедиться, что модель учится правильно структурировать ответы, следующим образом:
- Поиск шаблона: ищет конкретный формат
#### The final answer is [number] - Последовательное оценивание: начисляет 0.5 балла за правильное форматирование и 0.0 за неверный формат
- Обучающий сигнал: поощряет модель следовать ожидаемой структуре ответа
#Format reward function
def format_reward_func_qa(completions, **kwargs):
pattern = r"\n#### The final answer is \d+"
completion_contents = [completion for completion in completions]
matches = [re.search(pattern, content) for content in completion_contents]
return [0.5 if match else 0.0 for match in matches]
Функция reward за корректность
Эта функция обеспечивает основную математическую проверку за счет следующих шагов:
- Извлечение ответа: использует regex для извлечения числовых ответов из отформатированных ответов
- Нормализация: удаляет распространенные символы форматирования — запятые, знаки валюты, единицы измерения
- Сравнение с точностью: использует допуск 1e-3 для учета особенностей floating-point precision
- Бинарное оценивание: начисляет 1.0 за правильный ответ и 0.0 за неправильный
#Correctness reward function
def correctness_reward_func_qa(completions, final_answer, **kwargs):
rewards = []
for completion, ground_truth in zip(completions, final_answer):
try:
match = re.search(r'####.*?([\d,]+(?:\.\d+)?)', completion)
if match:
answer = match.group(1)
for remove_char in [',', '$', '%', 'g']:
answer = answer.replace(remove_char, '')
if abs(float(answer)-float(ground_truth)) < 1e-3:
rewards.append(1.0)
else:
rewards.append(0.0)
else:
rewards.append(0.0)
except ValueError:
rewards.append(0.0)
return rewards
Интеграция RLVR с GRPO
Reward-функции интегрируются в обучающий конвейер GRPO через GRPOTrainer:
rewards_funcs = [format_reward_func_qa, correctness_reward_func_qa]
trainer = GRPOTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
processing_class=tokenizer,
peft_config=peft_config,
reward_funcs=rewards_funcs,
)
Во время обучения GRPO использует эти reward-функции для вычисления policy gradients. Сначала модель генерирует несколько completions для каждой математической задачи. Затем для каждого ответа вычисляется reward по обеим reward-функциям. Функция reward за формат дает до 0.5 за корректную структуру ответа, а функция reward за корректность дает до 1.0 за математическую точность ответа, то есть максимальный совокупный reward на один completion составляет 1.5. Затем GRPO сравнивает completions внутри групп, чтобы определить лучшие ответы. Наконец, на шаге обновления policy функция потерь использует различия в reward для обновления параметров модели. Более высоко оцененные completions повышают свою вероятность, а менее удачные — снижают. Именно это относительное ранжирование и движет процесс оптимизации. Следующий пример показывает, как дообучить Qwen2.5-0.5B. Рецепт приведен в папке scripts, поэтому вы можете настроить его под себя или заменить базовую модель. Здесь используется GRPO с verifiable rewards и Quantized Low-Rank Adaptation (QLoRA). QLoRA применяется как способ снизить требования к вычислительным ресурсам и ускорить обучение, ценой небольшого снижения точности.
# Model arguments
model_name_or_path: Qwen/Qwen2.5-0.5B
tokenizer_name_or_path: Qwen/Qwen2.5-0.5B
model_revision: main
torch_dtype: bfloat16
attn_implementation: flash_attention_2
bf16: true
tf32: true
output_dir: /opt/ml/model/Qwen2.5-0.5B-RL-VR-GRPO
# Dataset arguments
train_dataset_id_or_path: /opt/ml/input/data/train/dataset.json
test_dataset_id_or_path: /opt/ml/input/data/val/dataset.json
dataset_splits: 'train'
max_seq_length: 2048
packing: true
# LoRA arguments
use_peft: true
load_in_4bit: true
lora_target_modules: ["q_proj", "k_proj", "v_proj", "o_proj", "up_proj", "down_proj", "gate_proj"]
lora_modules_to_save: ["lm_head", "embed_tokens"]
lora_r: 16
lora_alpha: 16
# Training arguments
num_train_epochs: 2
per_device_train_batch_size: 16
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: True
learning_rate: 1.84e-4
lr_scheduler_type: cosine
warmup_ratio: 0.1
# Logging arguments
logging_strategy: steps
logging_steps: 5
report_to:
- mlflow
save_strategy: "no"
seed: 42
Обзор recipe
Этот recipe реализует Group Relative Policy Optimization (GRPO) с verifiable rewards для дообучения модели Qwen2.5-0.5B на задачах математического рассуждения. В нем используется двойная система rewards, которая объективно оценивает и формат ответа, и математическую корректность без участия человека в разметке.
Ключевые гиперпараметры:
learning_rate: 1.84e-4 — learning rate, оптимизированный для обучения GRPOnum_train_epochs: 2 — число эпох, чтобы избежать переобученияper_device_train_batch_size: 16 сgradient_accumulation_steps: 2 — эффективный batch size 32max_seq_length: 2048 — окно контекста для 8-shot promptinglora_r: 16 иlora_alpha: 16 — параметры ранга и масштабирования LoRAwarmup_ratio: 0.1 с cosine scheduler — планирование learning ratelora_target_modules— нацеливание на attention-слои и MLP-слои для адаптации
Следующим шагом вы используете training job в SageMaker AI, чтобы поднять training cluster и запустить дообучение модели. SageMaker AI Model Trainer. ModelTrainer запускает training jobs на полностью управляемой инфраструктуре, беря на себя настройку среды, масштабирование и управление артефактами. Он также позволяет задавать training scripts, входные данные и вычислительные ресурсы без ручного развертывания серверов. Зависимости библиотек можно управлять через файл requirements.txt в папке scripts. ModelTrainer автоматически обнаружит этот файл и установит перечисленные зависимости во время выполнения.
Сначала настройте окружение. Здесь вы укажете тип экземпляра и число экземпляров для обучения, а также расположение training container.
from sagemaker.core import image_uris
from sagemaker.core.helper.session_helper import Session
sagemaker_session = Session()
bucket_name = sagemaker_session.default_bucket()
default_prefix = sagemaker_session.default_bucket_prefix
configs = load_sagemaker_config()
instance_type = "ml.g6.48xlarge"
instance_count = 1
config_filename = "Qwen2.5-0.5B.yaml"
image_uri = image_uris.retrieve(
framework="pytorch",
region=sagemaker_session.boto_session.region_name,
version="2.7.1",
instance_type=instance_type,
image_scope="training"
)
Далее настройте переменные окружения, расположение кода и пути к данным:
from sagemaker.train.configs import (
CheckpointConfig,
Compute,
OutputDataConfig,
SourceCode,
StoppingCondition,
)
from sagemaker.train.distributed import Torchrun
from sagemaker.train.model_trainer import ModelTrainer
env = {}
env["FI_PROVIDER"] = "efa"
env["NCCL_PROTO"] = "simple"
env["NCCL_SOCKET_IFNAME"] = "eth0"
env["NCCL_IB_DISABLE"] = "1"
env["NCCL_DEBUG"] = "WARN"
env["HF_token"] = os.environ['hf_token']
env["CONFIG_PATH"] = f"recipes/{config_filename}"
env["MLFLOW_EXPERIMENT_NAME"]= "grpo-rlvr"
env["MLFLOW_TAGS"] = '{"source.job": "sm-training-jobs", "source.type": "grpo-rlvr", "source.framework": "pytorch"}'
env["MLFLOW_TRACKING_URI"] = MLFLOW_TRACKING_SERVER_ARN
# Define the script to be run
source_code = SourceCode(
source_dir="./scripts",
requirements="requirements.txt",
entry_script="run_finetuning.sh",
)
# Define the compute
compute_configs = Compute(
instance_type=instance_type,
instance_count=instance_count,
keep_alive_period_in_seconds=3600,
)
# define Training Job Name
job_name = f"train-{config_filename.split('/')[-1].replace('.', '-').replace('yaml', 'rlvr')}"
# define OutputDataConfig path
output_path = f"s3://{bucket_name}/{job_name}"
# Define the ModelTrainer
model_trainer = ModelTrainer(
training_image=image_uri,
environment=env,
source_code=source_code,
base_job_name=job_name,
compute=compute_configs,
stopping_condition=StoppingCondition(max_runtime_in_seconds=18000),
output_data_config=OutputDataConfig(s3_output_path=output_path),
checkpoint_config=CheckpointConfig(
s3_uri=output_path + "/checkpoint", local_path="/opt/ml/checkpoints"
),
)
Настройте каналы для обучающих и валидационных данных:
from sagemaker.train.configs import InputData
# Pass the input data
train_input = InputData(
channel_name="train",
data_source=train_dataset_s3_path, # S3 path where training data is stored
)
val_input = InputData(
channel_name="val",
data_source=val_dataset_s3_path, # S3 path where training data is stored
)
# Check input channels configured
data = [train_input, val_input]
Затем запустите обучение:model_trainer.train(input_data_config=data)Ниже показана структура каталогов исходного кода для этого примера:
scripts/
├── accelerate_configs/ # файлы конфигурации Accelerate
├── run_finetuning.sh # скрипт запуска распределенного обучения с Accelerate на SageMaker training jobs
├── run_grpo.py # основной training script для GRPO
├── utils/ # утилиты для загрузки данных и создания prompt
├── recipes/ # предопределенные training configuration recipes (YAML)
└── requirements.txt # зависимости Python, устанавливаемые во время выполнения
Чтобы дообучать на нескольких GPU, в примере training script используются Huggingface Accelerate и DeepSpeed ZeRO-3, которые вместе позволяют эффективнее обучать крупные модели. Huggingface Accelerate упрощает запуск распределенного обучения, автоматически управляя размещением устройств, процессами и настройками mixed precision. DeepSpeed ZeRO-3 снижает потребление памяти, распределяя состояния оптимизатора, градиенты и параметры по GPU, что позволяет моделям с миллиардами параметров помещаться в память и обучаться быстрее. Запустить GRPO trainer script с Huggingface Accelerate можно с помощью простого командного примера:
NUM_GPUS=$(nvidia-smi --list-gpus | wc -l)
echo "Detected ${NUM_GPUS} GPUs on the machine"
# Launch fine-tuning with Accelerate + DeepSpeed (Zero3)
accelerate launch \
--config_file accelerate_configs/deepspeed_zero3.yaml \
--num_processes ${NUM_GPUS} \
run_grpo.py \
--config $CONFIG_PATH
Результаты
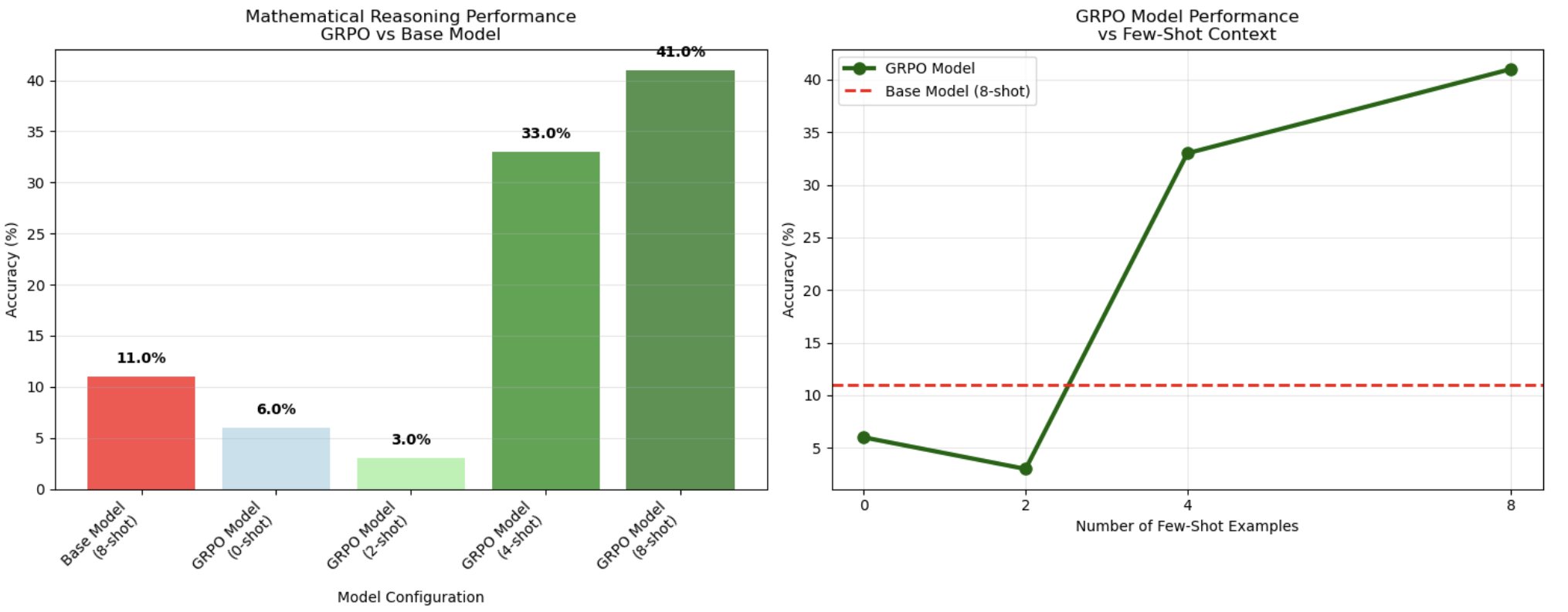
После оценки моделей на 100 test samples 8-shot модель, обученная с помощью GRPO, достигла точности 41% по сравнению с 11% у базовой модели, что означает 3.7x улучшение в chain-of-thought математическом рассуждении.

Следующая диаграмма показывает выраженный порог, связанный с длиной контекста, и указывает на оптимальный диапазон числа примеров для активации reasoning. Хотя конфигурации 0-shot (6%) и 2-shot (3%) работали плохо — даже хуже базовой модели — производительность резко улучшалась при 4-shot prompting (33%), а затем достигала пика при 8-shot контексте (41%). Эта нелинейная картина масштабирования показывает, что обучение GRPO формирует шаблоны рассуждения, которым требуется определенное число примеров для эффективной активации. Похоже, модель научилась использовать group comparisons на нескольких примерах, что согласуется с group-based policy optimization, где модель учится сравнивать и выбирать оптимальные пути рассуждения из нескольких сгенерированных решений.
Расширение RLVR на другие области
Хотя этот материал сосредоточен на математическом рассуждении с GSM8K, подход RLVR обобщается и на области, где результаты можно объективно проверить. Два перспективных направления демонстрируют эту универсальность:
Генерация кода с rewards на основе выполнения
Генерация кода естественно поддается проверке через выполнение. Частичные rewards можно начислять, когда код компилируется и запускается без ошибок, а полные rewards — когда результаты проходят полный набор unit tests. Эксперты предметной области задают требования с помощью текстовых prompt, а reward-модель автоматически оценивает корректность через выполнение кода, снимая необходимость в субъективной человеческой оценке.
Генерация текста для предметной области с семантической проверкой
Для специализированных областей, таких как медицинское или техническое письмо, keyword-based rewards могут направлять модели к правильной терминологии. Частичные rewards поощряют включение обязательных терминов, а полные rewards требуют полного набора ключевых слов в семантически уместном контексте. Например, при генерации медицинских текстов можно поощрять ответы, которые объединяют диагностические ключевые слова («symptoms», «diagnosis») с ключевыми словами лечения («therapy», «medication») в клинически корректных паттернах, обучая предметной лексике через измеримые цели. Эти примеры показывают, что verifiable rewards выходят за пределы математического рассуждения и подходят для задач, где корректность можно программно проверить, формируя основу для более широкого применения этого подхода к обучению.
Очистка ресурсов
Чтобы удалить ресурсы и не нести дополнительные расходы, выполните следующие шаги:
- Удалите все неиспользуемые ресурсы SageMaker Studio.
- При желании удалите domain SageMaker Studio.
- Удалите все созданные S3 bucket
- Убедитесь, что ваш training job больше не выполняется! Для этого в консоли SageMaker выберите Training и проверьте Training jobs.

Подробнее об очистке созданных ресурсов см. в разделе Clean up.
Заключение
В этом примере вы обучили модель Qwen2.5-0.5B с использованием GRPO (Group Relative Policy Optimization) на GSM8K — наборе из 8,500 школьных текстовых математических задач, требующих многошагового арифметического рассуждения и понимания естественного языка. Каждая задача содержит вопрос вроде «Janet’s ducks lay 16 eggs per day…» с пошаговыми решениями, заканчивающимися числовым ответом, что делает этот набор идеальным для обучения с verifiable rewards.
Эта реализация демонстрирует эффективность Reinforcement Learning with Verifiable Rewards (RLVR) для задач математического рассуждения. Модель Qwen2.5-0.5B, обученная с GRPO, показала улучшение в 3.7x по сравнению с базовой моделью, достигнув 41% точности на GSM8K против 11% в baseline. Результаты оценки подтверждают, что RLVR — перспективный подход для областей с объективно проверяемыми результатами и альтернатива методам обучения на основе предпочтений. Пороговое поведение указывает, что GRPO учится использовать group comparisons из нескольких примеров, что соответствует его group-based optimization. Эта работа закладывает основу для применения систем verifiable reward в других областях, требующих логической строгости и математической точности.
Дополнительную информацию о fully managed training в Amazon SageMaker AI можно найти в разделе обучения документации SageMaker AI. Поддерживающий код для этого материала доступен на GitHub.
Материал — перевод статьи с английского.