Как Miro использует Amazon Bedrock для повышения точности маршрутизации багов и сокращения времени решения с дней до часов

Этот материал подготовлен совместно с Philipp Pavlov, Dmytro Romantsov, Evgeny Mironenko и Gowri Suryanarayana из Miro.
Miro — это инновационное рабочее пространство на базе ИИ, которым пользуются более 95 миллионов человек по всему миру и которое помогает командам превращать неструктурированные идеи в организованные рабочие процессы. Чтобы поддерживать такой масштаб и дальше улучшать систему, команда developer experience в Miro решила создать собственное инновационное рабочее пространство для Miro с использованием современных технологий для повышения продуктивности разработчиков. Одна из ключевых задач команды — эффективно направлять баги в ответственные команды. Быстрая и точная маршрутизация багов убирает лишние переключения контекста, снижает раздражение разработчиков, сокращает time-to-resolution и в итоге помогает выпускать более качественный продукт и делать клиентов более довольными. В Miro значительная доля багов не укладывается во внутренние SLA по устранению в основном из-за неверной маршрутизации и повторных переназначений между командами. По оценке компании, это приводит к примерно 42 годам суммарно потерянной продуктивности в год из-за задержек и повторных расследований. Чтобы решить эту проблему, Miro вместе с командой AWS Prototyping and Cloud Engineering (PACE) разработала BugManager — решение на базе ИИ для автоматической triaging-обработки багов.
В этом материале мы подробно разбираем архитектуру и методы, которые помогли улучшить маршрутизацию багов в Miro: количество переназначений между командами сократилось в шесть раз, а time-to-resolution стал в пять раз короче благодаря Amazon Bedrock.
Проблема: точная маршрутизация баг-репортов примерно в 100 software teams
Автоматизация triaging багов в современных программных средах — сложная задача. Баг-репорты часто бывают неаккуратными, без контекста и содержат разнородные данные, включая текст, stack trace, скриншоты и даже видео. Сложность многократно возрастает в компаниях, ориентированных на разработку ПО, где много команд: задача превращается в multi-class classification с большим числом возможных меток. Инженерная организация Miro состоит почти из 100 команд, каждая из которых отвечает за свои части продукта. Для высокой точности классификации багов нужно обогащать отчеты релевантной информацией о продукте из разных источников, включая GitHub pull request, документацию Confluence, README-файлы и ранее закрытые тикеты. Кроме того, организационная структура динамична: команды объединяются, появляются новые, продукты развиваются, а обязанности команд постоянно меняются. То же самое относится к функциям продукта, которые добавляются, обновляются или выводятся из эксплуатации. Традиционные текстовые классификаторы на основе NLP, такие как дообученные модели BERT или дообученные классификаторы на основе больших языковых моделей (LLM), в таких динамичных средах сталкиваются с серьезными ограничениями. Им требуется переобучение при организационных изменениях, а также размеченные данные, которые могут отсутствовать для новых структур. Miro столкнулась с быстрым падением качества существующего решения на основе дообученной модели GPT. Осознав эти сложности, Miro выбрала подход на базе LLM, который сочетает оптимизированные промпты для классификации по командам с Retrieval Augmented Generation (RAG) для получения контекста, создав более гибкое, не требующее обучения и более точное решение для triaging багов: BugManager.
BugManager: triaging багов на основе RAG с Amazon Bedrock
BugManager использует подход на базе LLM для классификации багов. Когда поступает новый баг-репорт, система классификации BugManager начинает работу. Сначала BugManager парсит нетекстовые данные, такие как скриншоты или записи экрана, с помощью мультимодальных возможностей понимания изображений и видео в Amazon Nova Pro. Затем система обогащает разобранный отчет важным контекстом из нескольких knowledge bases с использованием Amazon Bedrock Knowledge Bases и RAG. Эти knowledge bases содержат, например, ранее решенные задачи Jira, GitHub pull request, документацию Confluence и GitHub README. Используя Claude Sonnet 4 от Anthropic на Amazon Bedrock, система объединяет обогащенное описание бага вместе с подробной текстовой информацией о каждой команде и ее обязанностях в один оптимизированный промпт для классификации, который выполняет маршрутизацию в нужную команду. В качестве дополнительной функции система может также генерировать подробный root cause analysis, используя собранную информацию в сочетании с извлечением из соответствующих репозиториев исходного кода, чтобы дать более глубокое понимание проблемы и предложить гипотезы по способу ее устранения.
Чтобы обеспечить бесшовное внедрение и использование, BugManager доступен инженерному сообществу Miro через простой Slack-based workflow. На следующем скриншоте показан пример взаимодействия пользователя с BugManager. На основе первоначального описания бага BugManager предлагает до пяти подходящих команд в порядке приоритета вместе с обоснованием. По умолчанию баг направляется в наиболее вероятную команду, но пользователи могут вручную изменить выбор. При необходимости BugManager также предоставляет инженерам root cause analysis сообщенной проблемы, опираясь на информацию, извлеченную из полного code base Miro.
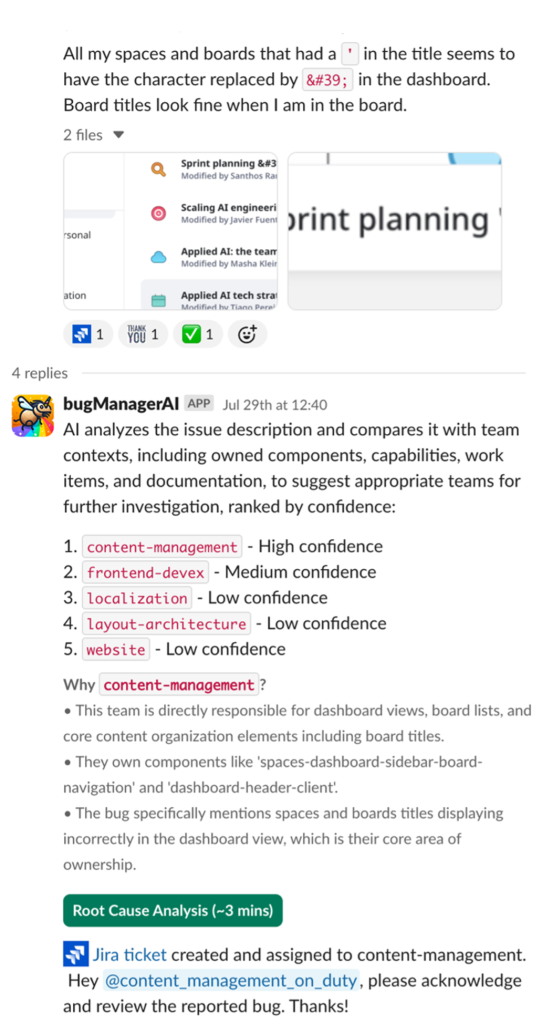
В следующих разделах мы подробно разберем архитектуру BugManager.
Подробный разбор архитектуры
BugManager в основном использует Amazon Bedrock — полностью управляемый сервис, который предоставляет выбор высокопроизводительных foundation models (FM) от ведущих AI-компаний через один API. С помощью Amazon Bedrock Knowledge Bases, Claude Sonnet 4 от Anthropic и Amazon Nova Pro на Amazon Bedrock мы построили end-to-end workflow, который преобразует описание бага, опубликованное в Slack, в issue, созданный в Jira и назначенный команде на устранение.
BugManager работает как Python microservice в кластере Amazon Elastic Kubernetes Service (Amazon EKS). Архитектура и поток приложения показаны на следующей схеме.
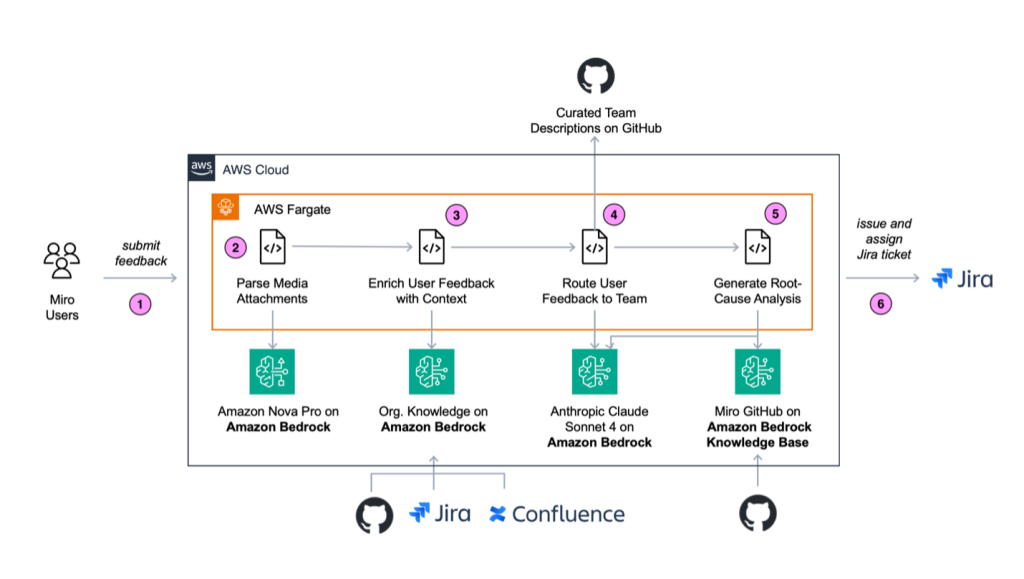
Рабочий процесс BugManager состоит из следующих шагов:
- Отправить отчет пользователя.
- Обработать медиа-вложения.
- Обогатить отзыв пользователя контекстом.
- Направить отзыв пользователя в нужную команду.
- Сгенерировать root cause analysis.
- Вернуть результаты пользователю на проверку.
В следующих разделах мы рассмотрим эти шаги подробнее.
Шаг 1: отправка отчета пользователя
Пользователь публикует отчет о проблеме, например баге, в выделенный Slack-канал. Отчет может содержать текст и медиа-вложения. Медиа-вложения могут включать видео, обычно screen recording, которое описывает процесс воспроизведения бага, скриншот, показывающий баг, или скриншот страницы продукта для предложения по улучшению функции. Баг-репорт передается как JSON-объект, который включает содержимое (текст) и ссылку на вложения, размещенные в Amazon Simple Storage Service (Amazon S3).
Шаг 2: обработка медиа-вложений
Если сообщение содержит медиа-вложения, их нужно преобразовать в текст, чтобы на следующих этапах анализ и классификация бага выполнялись в одной модальности — текстовой. Мы используем возможности понимания изображений в Amazon Nova Pro, чтобы преобразовать описание медиа-вложения в текст. Одна из сложностей такого подхода в том, что LLM по умолчанию не обладает контекстом: ей не хватает информации о типе изображения, обычно это скриншот продукта Miro, чтобы интерпретировать его конкретно и полезно. Поэтому, чтобы предоставить нужный контекст, мы сначала запускаем RAG на основе текста бага и дополняем промпт информацией о конкретной функции, которая, вероятно, показана в медиафайле. Наш подход RAG использует Amazon Bedrock Knowledge Bases для автоматического извлечения данных из внутренней продуктовой документации Miro. Это заметно повышает точность и специфичность извлекаемой информации из вложения. После парсинга текстовое описание медиа-вложения добавляется к исходному тексту бага и передается на следующий шаг рабочего процесса.
Шаг 3: обогащение отзыва пользователя контекстом
Мы использовали Amazon Bedrock Knowledge Bases для автоматического извлечения данных из разных источников и предоставления foundation models контекстной информации из широкого набора внутренних и внешних источников данных Miro. Amazon Bedrock Knowledge Bases — это полностью управляемая возможность со встроенным управлением контекстом сессии и указанием источников, которая помогает реализовать весь workflow RAG — от ingestion до retrieval и prompt augmentation — без необходимости строить собственные интеграции с источниками данных и управлять потоками данных. В частности, мы использовали коннекторы Amazon S3 и Confluence в качестве источников данных. В качестве vector store мы настроили Amazon OpenSearch Serverless, бессерверный вариант по запросу в составе Amazon OpenSearch Service. В knowledge base мы проиндексировали следующие источники данных: документацию Confluence, статьи центра помощи Miro, решенные тикеты Jira, GitHub README и документы Backstage (техническую документацию и software catalog). Amazon Bedrock Knowledge Bases поддерживает инкрементальные повторные синхронизации, что упрощает поддержание базы знаний в актуальном состоянии при изменениях документации и делает это экономически эффективно: повторно встраиваются и индексируются только измененные документы.
Шаг 4: маршрутизация отзыва пользователя в нужную команду
С помощью Amazon Bedrock и Claude Sonnet 4 от Anthropic мы направили баг в ответственную команду. Контекст, который LLM получает для корректной классификации, состоит из обогащенного описания бага, обогащенного описания вложения, если вложение доступно, и описаний команд, централизованно курируемых и версионируемых в Backstage (на базе GitHub). Описания команд — это живые документы, которые можно обновлять по мере необходимости. Продуктовая и инженерная организация Miro — динамические структуры. Функции продукта добавляются или выводятся из эксплуатации, а обязанности команд меняются. Благодаря prompt-based подходу BugManager такие обновления можно вносить сравнительно легко, просто обновляя соответствующие описания команд — markdown-файл, написанный на английском языке. Изменения применяются немедленно. Ниже приведена упрощенная версия промпта, который мы использовали для классификации бага по командам. Обратите внимание на использование тегов <xml> в ответе, что позволяет надежно парсить результаты.
ROUTING_PROMPT = """
You are a bug report routing assistant for Miro, a software company providing a collaboration and canvas software. You are responsible for analyzing incoming bug reports and determining which software team should handle them. Your goal is to accurately route each bug report to the most appropriate Miro software team based on their areas of responsibility.
When analyzing a bug report, follow these steps:
1. Carefully read the provided team descriptions to understand each team's domain expertise and responsibilities
2. Analyze the bug report for:
- Affected systems or components
- Technical keywords and terminology
- Error messages or stack traces
- User impact and behavior
- Related capabilities, features or functionality
3. Compare the bug details against each team's responsibilities
4. Select the most appropriate Miro software team based on:
- Direct ownership of affected components
- Required technical expertise
- Historical handling of similar issues
- Cross-cutting concerns and dependencies
Return the five most appropriate software teams, provide a confidence of HIGH, MEDIUM, LOW and a rationale per each choice. Enclose your answers in <team>, <confidence> and <rationale> xml tags, respectively.
Details about the bug report and the responsibilities of each Miro software team are provided below:
Bug details and context:
<bug_report>
{bug_report}
</bug_report>
<parsed_bug_attachments>
{parsed_attachments}
</parsed_bug_attachments>
<context>
{parsed_attachments}
</context>
Miro software teams descriptions:
<teams_info>
{teams_info}
</teams_info>
Miro team descrip
Think step-by-step!
""".strip()
BugManager достигает top-1 accuracy для маршрутизации багов в команды выше 75% — это на 70% больше, чем у существующего внутреннего решения на основе дообученной NLP-модели. Средняя задержка классификации составляет 53 секунды, что оказалось практически приемлемо для production-использования. BugManager возвращает до пяти наиболее вероятных команд, отсортированных по confidence, точное число настраивается. Top-3 accuracy составляет 95%, и в сочетании с human-in-the-loop подходом это, как было показано, еще больше повышает точность triaging. Эти результаты стали возможны благодаря extended thinking в Claude от Anthropic, что дало дополнительный прирост точности на 7–9%.
Для каждой классификации решение также предоставляет подробное обоснование того, почему было принято то или иное решение о маршрутизации. Это заметно повысило принятие пользователями и уровень доверия по сравнению с дообученным NLP-решением, которое возвращало только одну команду без дальнейших пояснений.
Шаг 5: генерация root cause analysis
BugManager может по желанию генерировать root cause analysis бага. Для этого мы снова предоставляем необходимый контекст через Amazon Bedrock Knowledge Bases, но на этот раз опираемся на весь GitHub code base Miro для справки. Во время root cause analysis мы передаем LLM — Claude Sonnet 4 от Anthropic с включенным extended thinking — описание бага, ранее извлеченный контекст и выбранную software team, которой нужно устранить баг. Затем LLM получает соответствующие участки кода с помощью Amazon Bedrock Knowledge Bases и генерирует набор гипотез о причине наблюдаемой ошибки. Тем самым система избавляет инженеров от необходимой исследовательской работы, требуемой для определения дальнейших действий.
Шаг 6: возврат результатов пользователю на проверку
Результат классификации и root cause analysis, если он был запрошен, отправляется в Slack в ответ на исходное сообщение. Пользователи могут просмотреть результаты маршрутизации и при необходимости изменить выбор по умолчанию. После этого создается тикет Jira с исходным описанием бага и поддерживающей документацией, извлеченной из knowledge bases, а также с результатами root cause analysis, и он назначается выбранной команде.
Вывод
BugManager обладает рядом ключевых возможностей, которые делают его высокоэффективным решением для triaging багов на базе Amazon Bedrock, успешно внедренным в инженерной организации Miro. К таким возможностям относятся:
- Высокоточная маршрутизация бага в команду с первой попытки
- Дополнительный рост качества за счет multi-class prediction, поддерживающего принятие решений в human-in-the-loop режиме
- Прозрачные решения по маршрутизации, повышающие принятие пользователями
- Root cause analysis бага для ускорения устранения
- Обогащение постоянно обновляемыми организационными знаниями
- Устойчивость и гибкость к изменениям в обязанностях команд
BugManager уже успешно обработал тысячи багов и запросов в production, обеспечив выдающиеся результаты для workflow разработки Miro. Система снизила количество переназначений между командами для запросов клиентской поддержки в шесть раз и улучшила median time-to-resolution в пять раз, превратив процесс, который раньше занимал дни, в процесс, укладывающийся в часы. По прогнозу BugManager позволит ежегодно экономить годы суммарного времени ожидания и расследований, в конечном счете обеспечивая существенно более качественный опыт работы с продуктом Miro.
Чтобы уже сегодня начать создавать собственную систему маршрутизации отзывов, изучите ресурсы и примерные архитектуры по generative AI в Generative AI on AWS, где можно найти пошаговые руководства, reference implementations и best practices для ускорения перехода к операционной эффективности на базе ИИ.
Материал — перевод статьи с английского.