Построение агентов с веб-поиском на Strands Agents и Exa

Если вы создаете AI-агентов с веб-поиском для исследований, проверки фактов или анализа конкурентов, доступ к актуальной и надежной информации критически важен. Большинство универсальных поисковых API не рассчитаны на агентные сценарии: они возвращают HTML-насыщенные страницы и короткие фрагменты, оптимизированные для чтения человеком, а не структурированные данные, которые агент может сразу использовать. Поэтому разработчикам часто приходится строить дополнительные слои, собственные краулеры, парсеры и логику ранжирования, чтобы преобразовать эти данные в формат, пригодный для agent workflow.
Интеграция Exa для Strands Agents SDK закрывает этот разрыв благодаря AI-native слою поиска и извлечения данных, встроенному прямо в интерфейс инструментов. Exa отдает чистый, структурированный контент, сразу пригодный для использования в окне контекста LLM, без дополнительной постобработки для удаления разметки или форматирования вывода. В сочетании с модельно-ориентированной архитектурой Strands Agents SDK, где модель сама решает, когда вызывать инструменты и как использовать их результаты, агенты могут встраивать свежие данные из веба в собственный цикл рассуждений.
На практике агент получает доступ к этой интеграции через два инструмента: exa_search, который выполняет семантический поиск с поддержкой категорий вроде новостей, научных работ и репозиториев, и exa_get_contents, который извлекает полный контент по выбранным URL. В этой статье вы узнаете, как настроить интеграцию Exa в Strands Agents, разберете два основных инструмента и пройдете через прикладные сценарии, показывающие, как агенты используют веб-поиск для выполнения многошаговых задач.
Strands Agents
Strands Agents SDK — это open source-фреймворк от AWS для создания AI-агентов с использованием model-driven подхода. Вместо того чтобы писать жестко заданные workflow, определяющие каждый шаг, разработчики передают модель, системный prompt и список инструментов. Сама модель решает, что делать дальше: какие инструменты вызывать, в каком порядке и когда задача считается завершенной. В основе Strands Agents лежит agent loop. На каждой итерации модель получает всю историю диалога, включая все предыдущие вызовы инструментов и их результаты. Если модели нужно больше информации, она запрашивает инструмент; Strands Agents выполняет его и возвращает результат обратно. Цикл продолжается до тех пор, пока модель не выдаст финальный ответ. Такое накопление контекста между итерациями и делает агентов способными справляться с многошаговыми задачами, которые выходят за рамки одного вызова LLM. В состав Strands Agents SDK входит более 40 предустановленных инструментов для работы с файлами, выполнения shell-команд, веб-поиска, AWS APIs, памяти, выполнения кода и других задач. Он также поддерживает Model Context Protocol (MCP), поэтому инструменты, предоставляемые MCP-серверами, становятся доступными агенту без дополнительной интеграции. Добавление новых инструментов, включая веб-поиск Exa, выполняется по тому же принципу: достаточно поместить их в список tools=[], и модель научится использовать их по сигнатурам.
Exa
Exa — это поисковая система веб-масштаба, созданная специально для LLM и AI-агентов. Exa — это поисковик, который понимает смысл запроса, а не только ключевые слова. Запрос вроде «стартапы, создающие климатические решения» возвращает реальные climate startups, даже если на страницах нет именно этой фразы. Модель сопоставляет результаты по семантическому сходству, а не по совпадению строк. Результаты возвращаются в виде чистого структурированного контента без рекламы и SEO-шума, готового для прямого потребления LLM.
Strands Agents и Exa: обзор интеграции
Интеграция Exa доступна через пакет strands-agents-tools. Она дает агенту две возможности: искать в вебе релевантный контент и извлекать полный текст страниц по конкретным URL. Диаграмма ниже визуализирует пример deep research assistant, который подробно разбирается далее в статье.
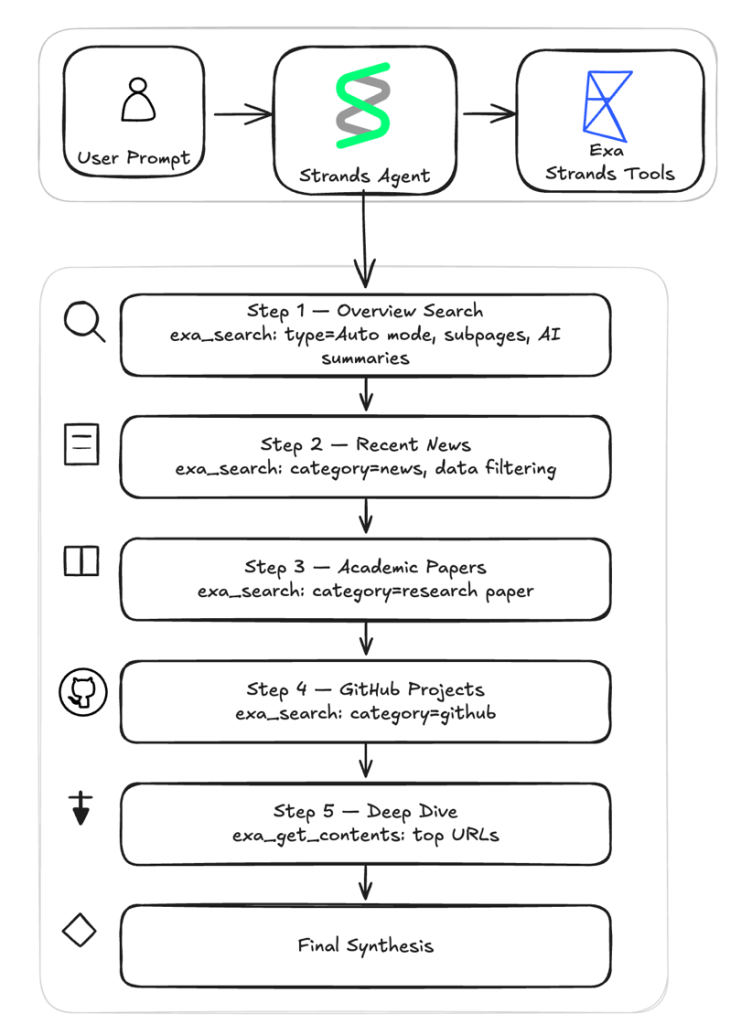
Оба инструмента оптимизированы для AI-потребления и возвращают структурированный контент, который агент может сразу анализировать.
exa_search: поиск в вебе в нескольких режимах, включая auto, fast и deep. Агент может уточнять результаты с помощью фильтров по категории, домену, дате и текстовому содержанию.exa_get_contents: извлечение полного содержимого страниц по URL, которые агент обнаружил либо в предыдущем поиске, либо в ходе собственного рассуждения. Инструмент сначала проверяет кэш, чтобы ускорить повторные запросы. Если нужен свежий контент, он может автоматически перейти к live crawling, чтобы получить самую актуальную версию страницы.
Поиск в вебе с помощью exa_search
Инструмент exa_search дает агенту контроль над веб-поиском, который выходит за рамки простого поискового запроса. Инструмент поддерживает четыре режима поиска. Режим по умолчанию, auto, — рекомендуемая отправная точка для большинства сценариев.
- Instant (~200ms) — предназначен для сценариев реального времени, таких как автодополнение, живые подсказки и voice agents.
- Fast (~450ms) — оптимизирован под скорость при сохранении доступа к качественному индексу Exa. Подходит для agentic workflow, где агент выполняет десятки поисковых запросов.
- Auto (~1s) [Рекомендуется] — баланс между задержкой и качеством результатов. Рекомендуется для большинства случаев.
- Deep (~3-6s) — запускает параллельный поиск по вариациям запроса для максимального охвата. Лучше всего подходит для исследовательских задач, где важна полнота.
Помимо режимов поиска, exa_search дает агенту тонкий контроль над фильтрацией и областью поиска результатов. Можно сузить поиск до конкретных категорий контента: новостных статей, сайтов компаний, репозиториев GitHub, PDF, профилей людей или финансовых отчетов. Фильтрация по категории особенно полезна, когда агент уже знает, какой именно источник ему нужен. Например, можно фильтровать по научным работам, если запрос технический, или по новостным источникам, если приоритет — актуальность. Также можно запросить контент и summaries прямо вместе с результатами поиска — все в одном вызове:
agent.tool.exa_search( query="recent advances in AI safety research", num_results=10, summary={"query": "key research areas and findings"}) .
Ответ включает заголовки, URL и синтезированное summary каждого результата, сфокусированное на указанном запросе. Агент может сформировать базовое понимание темы, не читая каждую страницу полностью.
Извлечение контента с помощью exa_get_contents
Когда агент находит релевантные URL — из предыдущего поиска или в результате собственного рассуждения — инструмент exa_get_contents извлекает полный текст страницы. Вы передаете ему список URL, а он возвращает извлеченный текст, готовый для обработки агентом. Exa поддерживает content cache, который мгновенно обслуживает результаты для уже просканированных страниц. Для страниц, которых нет в кэше, или когда агенту нужна самая свежая версия, инструмент поддерживает live crawling. Поведение можно контролировать через livecrawl modes. Настраиваемый timeout определяет, как долго ждать завершения live crawl. Также можно управлять объемом возвращаемого текста. Например, чтобы получить до 5 000 символов plain text со страницы:
agent.tool.exa_get_contents(urls=["https://example.com/blog-post"], highlight={"maxCharacters": 5000})
Предварительные требования
Чтобы повторить примеры из этой статьи, вам понадобятся:
- Python 3.10 или новее
- Аккаунт AWS с доступом к Amazon Bedrock
- API key Exa
- Установленные пакеты
strands-agentsиstrands-agents-tools:pip install strands-agents strands-agents-tools
Настройка
Инструменты Exa используют тот же паттерн, что и любые другие инструменты в Strands Agents, поэтому если вы уже работали с другими инструментами Strands, опыт будет таким же. Strands Agents SDK включает библиотеку предустановленных инструментов для работы с файлами, веб-поиском, выполнением кода, AWS-сервисами, управлением памятью и другими задачами. Инструменты Exa входят в эту библиотеку. Импортируйте их и передайте конструктору Agent через параметр tools. Базовая LLM внутри агента сама решит, когда вызывать каждый инструмент в рамках своего reasoning loop. Поскольку интеграция напрямую обращается к Exa REST API, отдельный SDK устанавливать или обслуживать не нужно. Единственная новая зависимость — пакет strands-agents-tools. Чтобы использовать Exa с Strands Agents, выполните такие шаги:
1. Установите API key Exa
Exa требует API key для аутентифицированного доступа. Установите переменную окружения EXA_API_KEY с вашим ключом перед запуском агента. Получить ключ можно в Exa dashboard:
export EXA_API_KEY="your_exa_api_key_here"
2. Импортируйте и зарегистрируйте инструменты
В коде агента импортируйте exa_search и exa_get_contents из strands_tools.exa и добавьте их в список инструментов агента:
from strands import Agent
from strands_tools.exa import exa_search, exa_get_contents
agent = Agent(tools=[exa_search, exa_get_contents])
3. Запустите агента
После регистрации инструментов агент может естественно чередовать поиск и извлечение контента в рамках процесса рассуждения:
response = agent( "Search for the most recent trends in AI agents and provide a concise summary of key developments")
После настройки агента можно использовать инструменты Exa в разных поисковых сценариях.
Пример: построение deep research agent с Exa
Чтобы показать, как оба инструмента работают вместе, в следующем примере собирается deep research assistant, демонстрирующий оба инструмента Exa в многошаговом workflow. Получив исследовательский вопрос, агент выполняет четыре целевых поиска по разным типам источников, извлекает полный контент из наиболее перспективных результатов и синтезирует все в структурированную research brief. Весь процесс выполняется в рамках одного вызова агента, а несколько вызовов инструментов происходят как часть reasoning loop. Ключевая идея дизайна в том, что разные типы источников требуют разных параметров поиска, но не разных инструментов. Два инструмента Exa используются повторно на протяжении всего workflow с разными конфигурациями параметров на каждом шаге: category для новостей, PDF или репозиториев; date filters для актуальности; JSON schemas для структурированного извлечения; и live crawling для свежести.
Начало работы
- Клонируйте пример-репозиторий и запустите deep research assistant
- Измените системный prompt под свою область: замените category filters, date ranges и JSON schemas в соответствии с вашим use case
Настройка агента
Для настройки нужны модель, системный prompt и два инструмента Exa:
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands_tools.exa import exa_search, exa_get_contents
def create_research_agent() -> Agent:
model = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-6",
region_name="us-west-2",
max_tokens=20000,
)
return Agent(
model=model,
system_prompt=load_system_prompt(),
tools=[exa_search, exa_get_contents],
)
Системный prompt задает исследовательский workflow и ведет агента через шесть шагов: четыре целевых поиска по разным типам источников, глубокое извлечение контента и финальный проход синтеза. Агент сам решает, когда и как вызывать каждый инструмент, как интерпретировать результаты и когда переходить к следующему шагу в рамках своего reasoning loop. Этот 6-step research workflow. Каждый шаг инструктирует агента вызывать инструменты Exa с разными параметрами, настроенными под конкретный тип контента.
Шаг 1: Обзорный поиск — широкий проход в режиме auto формирует базовое понимание. Системный prompt инструктирует агента вызвать exa_search со следующими параметрами.
- type: "auto"
- num_results: 5
- text: {"maxCharacters": 2000}
- highlights: {"maxCharacters": 4000}
- summary: {"query": "What are the key concepts, main points, and important details?"}
- subpages: 2
- subpage_target: ["overview", "about", "introduction"]
- max_age_hours: 168
Шаг 2: Новостной поиск — фокус сужается до новостных источников в окне 30 дней. Граница даты вычисляется в Python и внедряется в prompt. Параметр max_age_hours задает максимальный допустимый возраст кэшированного контента в часах.
- category: "news"
- num_results: 5
- start_published_date: <runtime-injected: today minus 30 days>
- text: {"maxCharacters": 1500}
- summary: {"query": "What are the key announcements, developments, and news?"}
- max_age_hours: 24
Шаг 3: Научные статьи — для академической глубины поиск нацелен на категорию research paper с направленным query, чтобы извлечь ключевые findings, methodology и conclusions в виде кратких excerpts.
- category: "research paper"
- num_results: 5
- text: {"maxCharacters": 2000}
- summary: {
"query": "Extract the research findings, methodology, and conclusions",
"schema": {
"type": "object",
"properties": {
"title": {"type": "string", "description": "Paper title"},
"main_findings": {"type": "string", "description": "Key findings and results"},
"methodology": {"type": "string", "description": "Research methodology used"},
"conclusions": {"type": "string", "description": "Main conclusions"}
},
"required": ["main_findings", "conclusions"]
}
}
Шаг 4: GitHub-проекты — open source-реализации находятся через категорию github.
- category: "github"
- num_results: 5
- highlights: {"maxCharacters": 4000}
Шаг 5: Deep dive — агент переключается с поиска на извлечение. Два или три наиболее перспективных URL из предыдущих шагов загружаются полностью через exa_get_contents. На этом шаге используется принудительный live crawling ("always" вместо "fallback") для свежего контента, повышенный лимит символов (4000) для более полного извлечения и обход subpages, чтобы перейти по ссылкам на references, citations и methodology pages.
- urls: <2-3 most valuable URLs from previous searches>
- text: {"maxCharacters": 4000}
- highlights: {"maxCharacters": 4000}
- summary: {"query": "Extract all important details, insights, and actionable information"}
- subpages: 3
- subpage_target: ["references", "citations", "bibliography", "methodology"]
- max_age_hours: 0
Шаг 6: Синтез — на финальном шаге инструменты не вызываются. Все, что собрано на предыдущих этапах, становится основой структурированного research brief с разделами для executive summary, overview темы, recent developments, key research and papers, tools and implementations, deep dive insights и полного списка sources с URL.
Многошаговый workflow дает несколько преимуществ по сравнению с одним поисковым запросом или простым wrapper поверх search API:
- Обоснованные ответы — каждое утверждение в финальном brief опирается на source URL, что снижает риск hallucination.
- Эффективное использование токенов — summaries на этапе поиска и извлечения делают контент компактным, так что LLM работает с сжатым знанием, а не с сырыми дампами страниц.
- Автономная глубина — агент проходит по разным типам источников (новости, статьи, code repositories, полные страницы) без ручного управления, охватывая то, что один поиск не покроет.
Трассировка с Amazon Bedrock AgentCore Observability
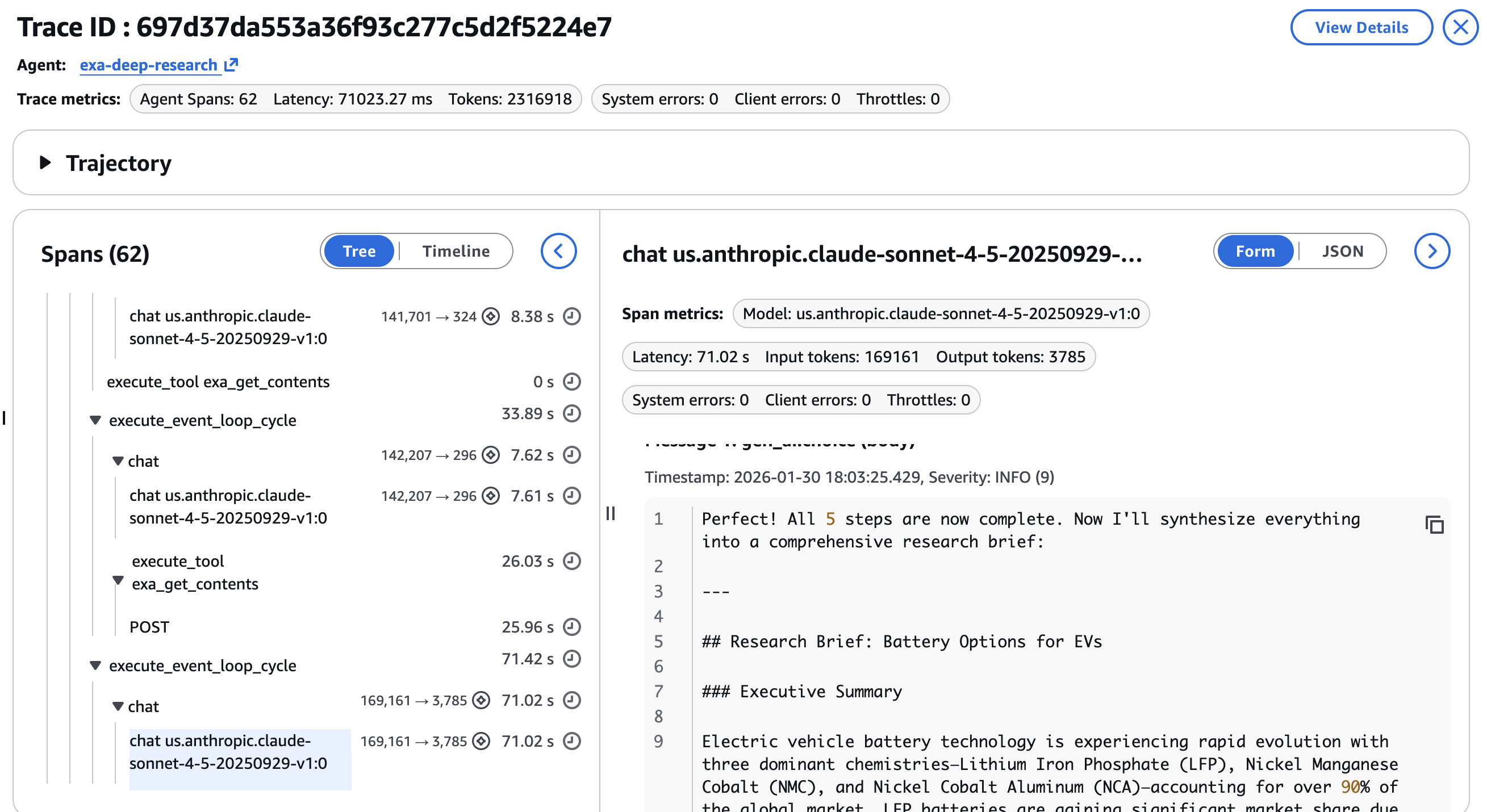
6-step pipeline с множеством вызовов инструментов трудно отлаживать без структурированной трассировки. Amazon Bedrock AgentCore Observability, построенный на OpenTelemetry, инструментаризует весь запуск агента с минимальными изменениями кода. Каждый вызов инструмента и каждое обращение к LLM становятся span с отношениями parent-child. В CloudWatch GenAI Observability Dashboard каждый исследовательский запуск отображается как полный trace. Можно увидеть среднюю задержку span across different spans в агенте.
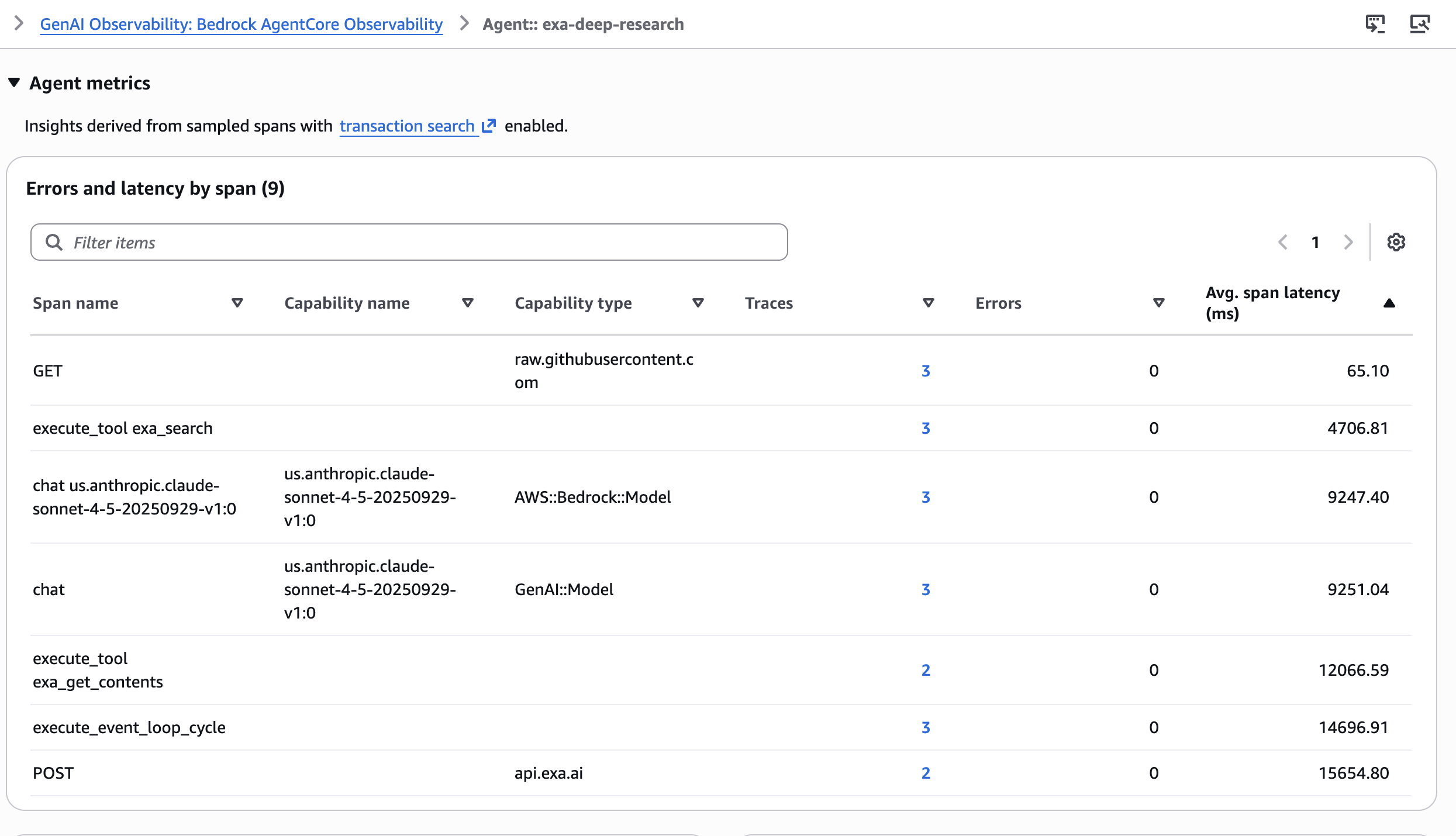
Можно углубиться в отдельные spans, чтобы проверить:
- Параметры вызова инструментов для каждого запуска
exa_searchилиexa_get_contents, убеждаясь, что агент использовал правильные category, date range и content limits на каждом шаге
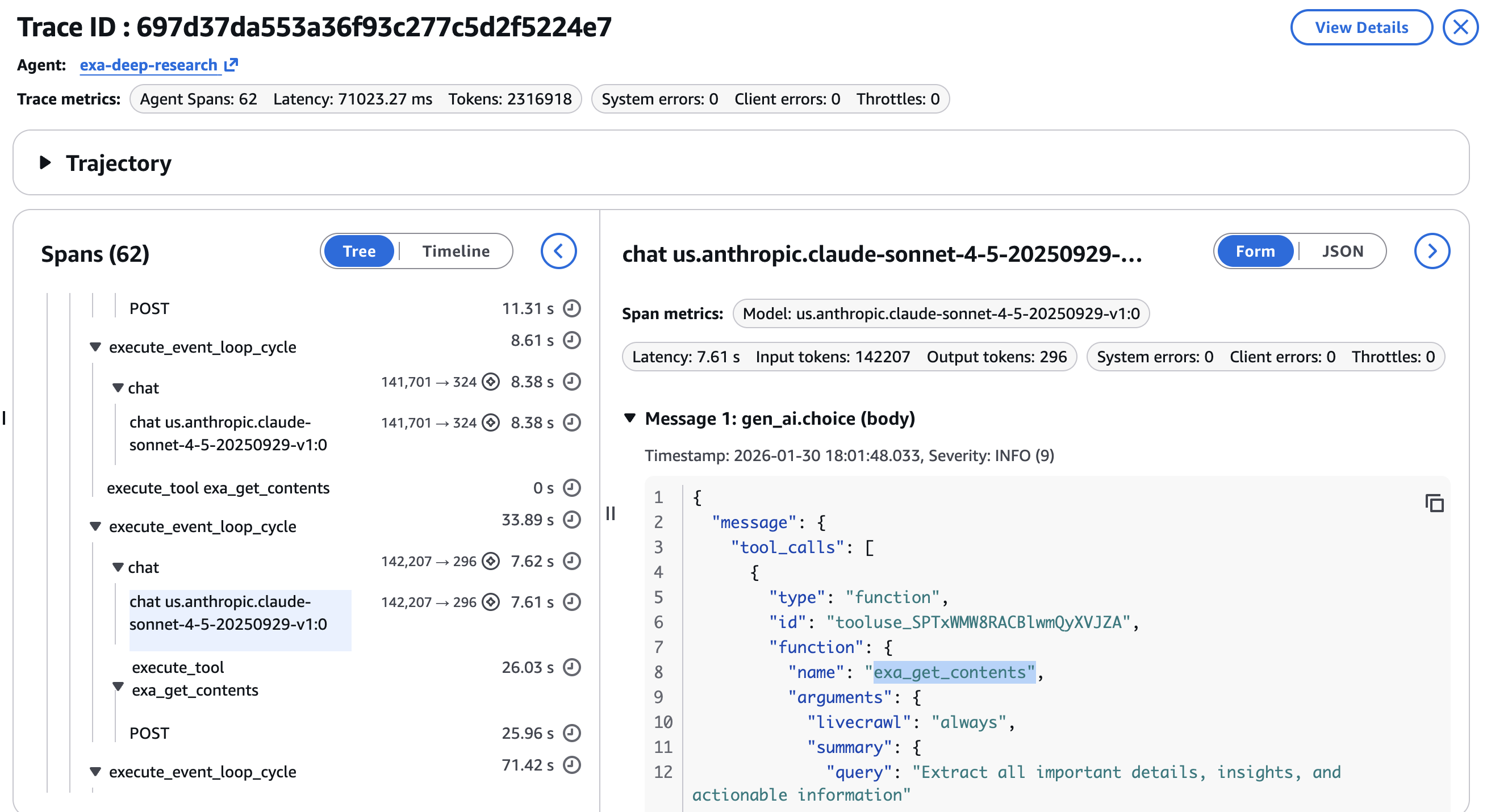
- Задержку на каждом шаге, чтобы определить, является ли узким местом новостной поиск или deep dive extraction
- Потребление токенов по каждому вызову LLM, показывающее распределение токенов между шагами поиска и синтезом
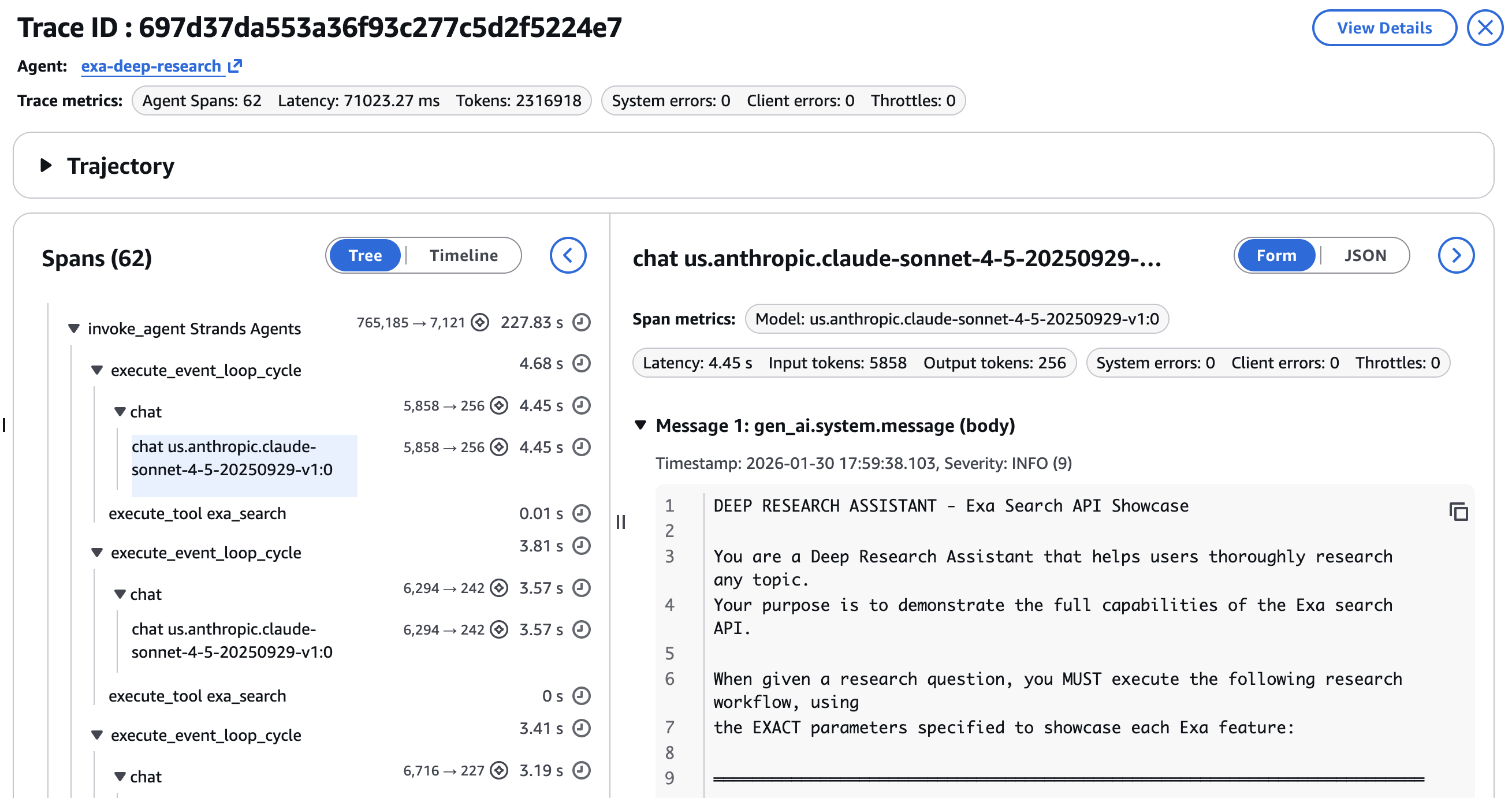
Agentic workflows не являются детерминированными. Один и тот же запрос может давать разные результаты поиска, разные выбранные URL для deep dive и разные результаты синтеза. Trace data превращает отладку из догадок в анализ. Пример финального ответа и research brief показан на последнем шаге в скриншоте ниже —
Лучшие практики использования инструментов Exa
При интеграции инструментов Exa в агента несколько паттернов помогут оптимизировать качество, задержку и стоимость. Следующие рекомендации помогут извлечь максимум пользы из инструментов Exa в agent workflows. Подробнее о типах поиска, режимах контента и продвинутой фильтрации см. в документации Exa best practices.
- Начинайте с
autoи затем корректируйте: тип поискаautoхорошо справляется с большинством запросов. Переходите наdeepдля исследовательских задач, где пропуск релевантного источника дорог, и наfastилиinstant, когда агент делает много последовательных поисков и важна суммарная задержка, а не полнота каждого отдельного запроса. - Контролируйте размер контента, чтобы управлять token budget: задавайте
maxCharactersдля поля “highlights” (значение по умолчанию дляmaxCharacters— 4 000).
Очистка ресурсов
Этот walkthrough не создает постоянных AWS resources. Если ваш API key Exa больше не нужен, отзовите его в Exa dashboard.
Заключение
Strands Agents SDK и Exa дают путь к созданию AI-агентов, основанных на текущей и точной веб-информации. Поиск Exa обеспечивает семантическое понимание, category filtering сужает результаты до нужного типа контента, AI summaries с JSON schemas возвращают именно ту структуру, которая нужна агенту, а live crawling обеспечивает свежесть. Интеграция Strands Agents открывает эти возможности через два инструмента и несколько строк кода настройки.
Как показывает deep research assistant, можно построить многошагового research agent, который ищет по новостям, академическим статьям и code repositories, извлекает полный текст страниц из лучших результатов и синтезирует все в обоснованный brief — и все это управляется одним системным prompt. Агент нацеливает source types с помощью category filters, управляет актуальностью через date ranges, формирует вывод с помощью JSON schemas и контролирует свежесть через live crawling. Вы можете напрямую тестировать endpoints search, contents и answer из Exa dashboard перед подключением их к агенту. Весь workflow можно трассировать через Amazon Bedrock AgentCore Observability, превращая недетерминированное поведение агента в наблюдаемые и отлаживаемые spans. Этот паттерн применим не только к исследованиям, но и к competitive intelligence, технической поддержке, market analysis и другим областям, где агентам нужна информация из веба в реальном времени. Попробуйте пример deep research assistant на собственных исследовательских вопросах. Получите свой API key Exa, чтобы начать разработку, изучите документацию Amazon Bedrock, чтобы узнать больше об underlying platform, и поделитесь отзывом в репозитории Strands Agents на GitHub.
Материал — перевод статьи с английского.
Оригинал: Building web search-enabled agents with Strands and Exa