Amazon Finance автоматизирует регуляторные запросы с помощью генеративного AI на AWS и Amazon Bedrock
Команды Finance Technology (FinTech) в Amazon создают и поддерживают системы, которые помогают подразделениям Amazon обрабатывать регуляторные запросы в соответствии с требованиями разных юрисдикций. Такие запросы поступают от органов власти и отличаются по формату документов, требованиям и уровню сложности.
Обработка этих запросов включает анализ документации, извлечение нужной информации, поиск подтверждающих данных в нескольких системах внутри инфраструктуры Amazon и подготовку ответов в установленные регуляторами сроки. По мере роста числа запросов и усложнения бизнеса Amazon потребовался более масштабируемый подход.
В этом материале показано, как команды Amazon FinTech используют Amazon Bedrock и другие сервисы AWS, чтобы построить масштабируемое AI-приложение, меняющее процесс обработки регуляторных запросов. Каждая команда, использующая это решение, создает и поддерживает собственную отдельную базу знаний, наполненную документами и справочными материалами именно своей команды.
Проблемы
Масштаб и сложность управления регуляторными запросами создавали несколько взаимосвязанных проблем:
Фрагментация знаний и сложность поиска
Для регуляторных запросов необходимо сводить воедино информацию из тысяч исторических документов. Эти документы существуют в разных форматах (PDF, PPT, Word, CSV) и содержат предметную терминологию. Командам нужен был способ быстро находить релевантные прецеденты и подтверждающую информацию в этом огромном массиве, сохраняя точность и соответствие требованиям регуляторов.
Контекст диалога и управление состоянием
Регуляторные запросы требуют многоходовых разговоров, где контекст из предыдущих взаимодействий критически важен для точного ответа. Сложность добавляют сохранение состояния между сессиями и отслеживание того, как ответы меняются по мере того, как сотрудники уточняют их в ходе итераций.
Наблюдаемость и непрерывное улучшение
В системах на базе generative AI важно понимать не только сам ответ, но и то, почему он был сгенерирован. Командам нужна была полная видимость процесса поиска, решений модели и действий пользователей, чтобы находить точки улучшения и соблюдать принципы ответственного использования AI. Например, нужно выявлять случаи, когда модель галлюцинирует и выдает сведения, которых нет в исходных документах, или когда система извлекает устаревшие рекомендации по комплаенсу, способные привести к нарушениям. Точность AI-систем со временем меняется по мере изменения моделей, prompt и корпуса документов, поэтому требуется постоянный мониторинг.
Обзор решения
Чтобы решить эти задачи, команда Amazon FinTech построила интеллектуальную систему автоматизации ответов на регуляторные запросы с использованием Amazon Bedrock, AWS Lambda и вспомогательных сервисов AWS. Решение реализует Retrieval Augmented Generation (RAG) с помощью Amazon Bedrock Knowledge Bases и Amazon OpenSearch Serverless для хранения векторов, что позволяет извлекать информацию из тысяч исторических документов. Диалоги в реальном времени, работающие на Claude Sonnet 4.5 через Converse Stream API в сочетании с Amazon DynamoDB для хранения истории разговора, обеспечивают контекстно-осведомленные многоходовые беседы. Полная наблюдаемость через OpenTelemetry и self-hosted Langfuse обеспечивает непрерывный мониторинг и улучшение производительности AI-системы. Система не кэширует ответы large language model (LLM) и промежуточные результаты, поскольку регуляторные запросы сильно зависят от контекста и обычно дают низкую долю попаданий в cache.
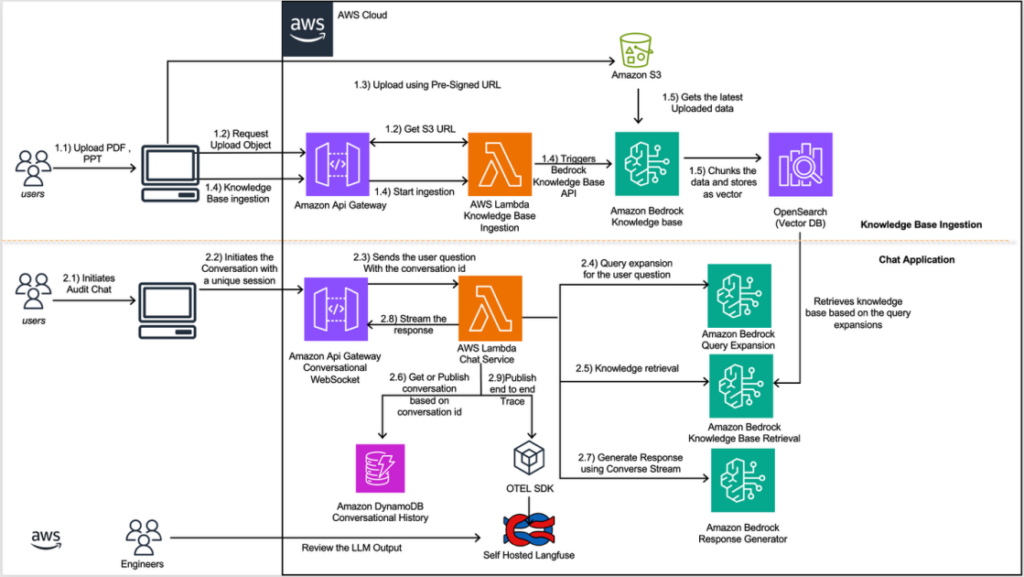
На следующей диаграмме показано, как можно использовать Amazon Bedrock Knowledge Bases в рабочем процессе вместе с Converse API и другими инструментами, чтобы предоставлять необходимую информацию для регуляторных запросов:

Поток загрузки базы знаний
Поток загрузки базы знаний обеспечивает автоматизированный конвейер обработки документов, который запускается после того, как пользователь загружает документ. Его задача — встроить данные документа в Amazon Bedrock Knowledge Base. Вот как выглядит этот процесс:
Этот рабочий процесс можно использовать для массовой загрузки документов и преобразования их в searchable vector embeddings через автоматизированный конвейер. Подробный процесс показан на предыдущей схеме.
- Загрузка документа пользователем: пользователи загружают документы через клиентское приложение.
- Создание pre-signed URL: клиентское приложение отправляет запрос в Amazon API Gateway, который вызывает AWS Lambda-функцию загрузки базы знаний для создания pre-signed S3 URL.
- Загрузка документа: клиентское приложение использует созданный pre-signed URL для загрузки документа.
- Запуск загрузки и обработка данных: после успешной загрузки документа в Amazon Simple Storage Service (Amazon S3) клиентское приложение инициирует Amazon API Gateway, чтобы запустить AWS Lambda для обработки документа, которая выполняет преобразование формата и управляет параллельной загрузкой документов. Предобрабатывать изображения, диаграммы и таблицы в этих документах не требуется, поскольку Amazon Bedrock Knowledge Base настроена с Amazon Bedrock Data Automation (BDA), чтобы эффективно извлекать этот multimodal content. Затем AWS Lambda вызывает Amazon Bedrock Knowledge Bases.
- Хранение векторов: Amazon Bedrock Knowledge Base разбивает содержимое документа на фрагменты с помощью hierarchical chunking strategy, генерирует embeddings с помощью Amazon Titan Text Embeddings и сохраняет полученные векторы в OpenSearch Serverless. Hierarchical chunking создает вложенные отношения parent-child, повторяющие секционную структуру финансовых документов. Этот подход хорошо работает со структурированными и сложными документами, потому что индексирует небольшие фрагменты для точного поиска, а затем возвращает более крупные parent chunks, чтобы обеспечить достаточный контекст для связных ответов.
Построение автоматизированного конвейера загрузки решает базовую проблему фрагментации знаний, эффективно обрабатывая тысячи исторических документов в разных форматах и одновременно оптимизируя индексирование контента для релевантных AI-ответов. Такой параллелизованный подход позволяет системе масштабироваться, поддерживая растущий год к году объем регуляторных запросов и сохраняя стабильную производительность обработки при больших объемах документов.
Приложение для чата
Приложение для чата предоставляет интерфейс разговоров в реальном времени на базе серверless-архитектуры AWS и позволяет взаимодействовать с системой на естественном языке. Мы выбрали потоковую передачу ответов пользователям, чтобы они могли начинать читать AI-ответ раньше, реализовав это через WebSocket-соединения. Благодаря этим WebSocket-соединениям и модели Claude Sonnet 4.5 приложение выдает релевантные по контексту ответы, сохраняя состояние разговора в DynamoDB. Рабочий процесс выглядит так:
- Инициация чат-сессии: пользователи начинают новую сессию чата или открывают существующую через клиентское приложение.
- WebSocket-соединение: приложение использует WebSocket для установления постоянного двустороннего соединения с Amazon API Gateway.
- Отправка сообщения: приложение передает вопросы пользователя через WebSocket-соединение, после чего они поступают в AWS Lambda-функцию Chat service.
- Улучшение запроса: AWS Lambda-функция Chat Service использует модель Claude 3.5 Haiku со query expansion strategy, чтобы сгенерировать несколько вариантов вопроса пользователя.
- Поиск знаний: Lambda-функция Chat Service вызывает Amazon Bedrock Knowledge Bases Retrieve API для каждого расширенного запроса. API выполняет поиск векторов по сходству в базовом индексе OpenSearch Serverless и возвращает наиболее релевантные фрагменты документов вместе с метаданными источника и оценками релевантности.
- Сбор контекста: AWS Lambda-функция Chat Service извлекает историю разговора из Amazon DynamoDB (для существующих разговоров, на основе конкретного conversation ID) и объединяет ее с результатами из базы знаний и вопросом пользователя.
- Генерация ответа: AWS Lambda-функция Chat Service использует Converse Stream API с Claude Sonnet 4.5 и prompt для генерации ответа, чтобы сформировать релевантный по контексту ответ на основе собранного контекста.
- Взаимодействие с пользователем: AWS Lambda-функция Chat Service передает сгенерированный ответ обратно в клиентское приложение в формате Markdown format через WebSocket-соединение и сохраняет всю беседу в Conversational History Table в Amazon DynamoDb.
- Наблюдаемость: на всем протяжении процесса Chat Service публикует end-to-end traces в self-hosted экземпляр Langfuse с помощью OpenTelemetry (OTEL) SDK. Это позволяет собирать подробные telemetry-данные, включая метрики задержки, использование токенов, шаблоны prompt и ответы модели.
Многоходовой разговорный опыт
Обсуждения регуляторных запросов часто развиваются через несколько обменов, по мере того как команды уточняют ответы и обращаются к дополнительным источникам данных. Чтобы поддержать этот итеративный процесс, команда Amazon FinTech реализовала многоходовой conversational workflow с использованием Amazon API Gateway (WebSocket APIs), AWS Lambda и Amazon DynamoDB, интегрированный с Amazon Bedrock ConverseStream API для диалога с низкой задержкой и учетом контекста. Каждая чат-сессия надежно аутентифицируется через Amazon Cognito и получает уникальный conversation ID. DynamoDB хранит сообщения в хронологическом порядке, чтобы сохранять контекст между сессиями, поэтому пользователи могут бесшовно возобновлять предыдущие обсуждения и сохранять непрерывность.
Когда пользователь отправляет запрос, система очищает входные данные, чтобы предотвратить prompt injection attacks. После очистки система классифицирует intent и определяет, нужен ли поиск в Amazon Bedrock Knowledge Base. Это решение принимает вызов LLM, который относит запрос пользователя либо к conversational, либо к knowledge intensive. Для сложных knowledge-intensive вопросов workflow применяет query expansion strategy, которая учитывает распространенное использование пользователями аббревиатур и сокращенных форм вопросов. Этот слой генерирует до пяти вариантов запроса с помощью Claude 3.5 Haiku, а затем выполняет параллельные вызовы Retrieve API к Knowledge Base, извлекая релевантные результаты через поиск по сходству векторів OpenSearch. Чтобы поддерживать производительность на масштабе, workflow реализует параллельную обработку этих вызовов на основе multi-threading. Эта оптимизация сократила задержку поиска с 10 секунд при последовательной обработке до менее чем 2 секунд, что сделало разговоры отзывчивыми. Извлеченная информация — вместе с недавней историей диалога — передается в Claude Sonnet 4.5 через ConverseStream API, дополненный Amazon Bedrock Guardrails, которые реализуют фильтры sensitive information для автоматического обнаружения и удаления PII и финансовых данных как во входных, так и в выходных сообщениях. Это критично для защиты регуляторной документации. Когда обнаруживаются попытки prompt injection, система отвечает: «Извините, модель не может ответить на этот вопрос», обеспечивая безопасное и compliant взаимодействие без потери разговорной плавности.
Эта архитектура обеспечивает непрерывность, прозрачность и масштабируемость. Пользователи получают ответы в реальном времени, в потоковом режиме, со статусными обновлениями на этапах поиска и генерации, что повышает вовлеченность и снижает задержку. Постоянные журналы в DynamoDB создают неизменяемый audit trail для проверки соответствия требованиям, а serverless- и event-driven-дизайн автоматически масштабируется для поддержки одновременных сессий. Вместе эти возможности позволяют команде Amazon FinTech вести сложные итеративные разговоры, получая контекстно релевантные, безопасные и соответствующие требованиям регуляторов ответы на базе Amazon Bedrock.
Наблюдаемость
Наблюдаемость играет критическую роль в понимании и улучшении AI-рабочих процессов. Чтобы получить полную видимость системы ответов на регуляторные запросы, AWS Lambda-функция Chat Service интегрировала OpenTelemetry (OTEL) с self-hosted экземпляром Langfuse для сбора подробных end-to-end traces каждого взаимодействия. Эта конфигурация дает инженерам и прикладным исследователям детализированную telemetry о том, как обрабатываются prompt, как извлекаются знания и как генерируются ответы. Это позволяет практически непрерывно улучшать производительность и точность системы. Решение использовать OTEL вместо нативного Langfuse SDK дает независимость от вендора и гибкость, позволяя направлять telemetry-данные в несколько observability-backend и адаптировать их к меняющимся требованиям мониторинга.
Во время выполнения каждая стадия AWS Lambda Chat Service вручную инструментируется с помощью OTEL Java SDK для записи задержки, использования токенов, решений модели и метаданных prompt в соответствии со OTEL Generative AI semantic standard. Spans публикуются в Langfuse почти в реальном времени, давая команде прозрачное представление о том, как Amazon Bedrock ConverseStream API, поиск по Knowledge Base и Claude Sonnet 4.5 взаимодействуют в рамках одного запроса. Подробная telemetry позволяет выявлять узкие места производительности, оптимизировать prompt-стратегии и повышать точность retrieval при сохранении responsible AI practices.
Этот framework наблюдаемости поддерживает доверие и подотчетность в поведении системы. Инженеры могут сопоставлять действия пользователей с результатами модели, отслеживать происхождение данных через несколько сервисов и точно настраивать конфигурации без нарушения работы. Объединяя совместимость OpenTelemetry с визуализацией и аналитикой Langfuse, команда Amazon FinTech получает масштабируемую и расширяемую основу для оценки generative AI-систем на масштабе, превращая каждое взаимодействие в практический инсайт для непрерывного улучшения.
На следующем скриншоте показан end-to-end trace, полученный в Langfuse, демонстрирующий, как решение наблюдаемости фиксирует весь workflow — от query expansion и поиска знаний до prompt модели, ответов и метрик задержки. Также он показывает цитаты из исходных документов, давая прозрачное представление о том, как контекстная информация проходит через систему во время генерации ответа

Ссылка: End-to-End Trace, опубликованный в Langfuse
Заключение
В этом материале вы увидели, как команда Amazon FinTech построила масштабируемое AI-решение на базе Amazon Bedrock, предназначенное для поддержки регуляторных запросов за счет автоматизации поиска знаний, conversational workflows и генерации ответов. Объединяя конвейер загрузки документов, многоходовые stateful conversations и детальную наблюдаемость через OpenTelemetry и Langfuse, архитектура помогает командам обрабатывать регуляторные запросы в управляемой, отслеживаемой и compliant форме.
Поскольку весь стек построен на serverless-сервисах AWS, он обеспечивает операционную масштабируемость, безопасность и эластичность, необходимые для enterprise-развертывания. Если вы работаете с юридическим комплаенсом, регуляторными запросами или высоконагруженными внутренними knowledge workflows, этот подход дает практическую основу, которую можно адаптировать и расширить под свою предметную область.
Если вы готовы модернизировать свои knowledge-intensive процессы с помощью generative AI, изучите документацию Amazon Bedrock, чтобы понять, как начать строить собственные secure, governed и scalable AI-powered workflows.
Материал — перевод статьи с английского.
Оригинал: How Amazon Finance streamlines regulatory inquiries by using generative AI on AWS