Автоматическая генерация схем для intelligent document processing в IDP Accelerator

Прежде чем извлекать информацию из документов с помощью методов intelligent document processing (IDP), для каждого класса документов нужна схема, определяющая, что именно извлекать. Но как создавать схемы, если у вас тысячи документов и вы не знаете, какие классы вообще существуют? На таком масштабе это требует значительных ручных усилий, из-за чего последующие инициативы в области IDP становится сложно обосновать.
В этом материале мы показываем, как функция multi-document discovery решает эту задачу. Она работает как автоматический этап предварительной обработки: анализирует неизвестные документы, группирует их по типам и создает схемы, готовые для IDP Accelerator. Вы узнаете, как новая возможность использует visual embeddings для автоматической кластеризации и агенты для генерации схем. Мы также покажем, как запустить решение на собственной коллекции документов.
IDP Accelerator
IDP Accelerator — это масштабируемое, serverless, open-source решение для автоматизированной обработки документов и извлечения информации. Чтобы адаптировать решение под конкретные типы документов, нужен файл конфигурации, в котором задаются классы и поля. Минимальный пример конфигурации приведен в GitHub-репозитории IDP Accelerator.
Если вы плохо понимаете, какие именно типы документов есть в коллекции, такую схему создать непросто. В IDP Accelerator есть Discovery Module, который может сформировать конфигурацию класса на основе одного примера документа. Однако в этом случае вам уже нужно знать свои классы документов и уметь находить представительный пример для каждого класса. Представленная в этом материале multi-document discovery убирает это ограничение и ускоряет путь к применению IDP Accelerator к коллекции неразмеченных документов.
Обзор решения
Следующее видео показывает решение в консоли IDP Accelerator.
Функция multi-document discovery автоматизирует преобразование не классифицированных коллекций документов в структурированные схемы, готовые для дальнейших инициатив в области IDP. Решение встроено в существующий Discovery Module IDP accelerator и добавляет новую возможность Multiple Document рядом с функцией Single Document discovery. Для оркестрации и serverless-вычислений используются AWS Step Functions state machine и AWS Lambda. Решение обрабатывает документы из корзины Amazon Simple Storage Service (Amazon S3) или из загруженного Zip-архива. Модели, доступные через Amazon Bedrock, генерируют схемы, которые автоматически интегрируются в файл конфигурации IDP Accelerator. На следующей диаграмме показан полный workflow.
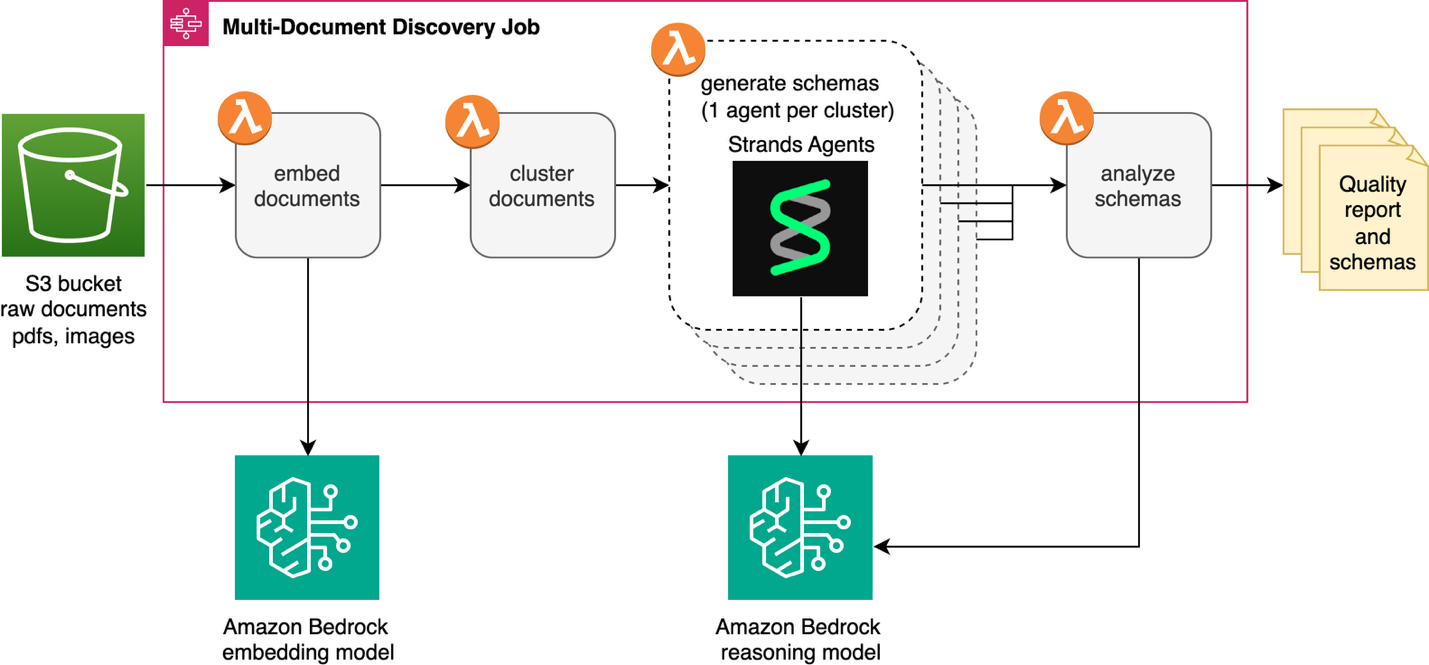
Задача discovery начинается с преобразования каждого документа в Amazon S3 в векторное embedding с помощью модели embedding, доступной в Amazon Bedrock, после чего похожие документы объединяются в кластеры. Агент, созданный с помощью Strands Agents и LLM в Amazon Bedrock, анализирует каждый кластер, чтобы определить тип документа и сгенерировать схему. Затем выполняется этап reflection, который совместно проверяет схемы на наличие пересечений и несоответствий перед финальной ручной проверкой.
Технические детали
Ниже мы последовательно разберем каждый этап процесса и выделим ключевые решения и особенности реализации.
Генерация embedding
Workflow создает embedding для каждого документа, преобразуя визуальные признаки в числовые представления. Для многостраничных документов используется только первая страница. Сейчас workflow применяет visual embeddings, а не OCR-based text, потому что visual embeddings лучше улавливают макет, форматирование и структурные признаки, по которым различаются типы документов, даже если текстовое содержимое похоже. По умолчанию для задачи discovery используется Cohere Embed v4 через Amazon Bedrock. Этап embedding автоматически обрабатывает распространенные сложности, такие как сжатие изображений, повторные попытки и ограничение частоты запросов.
Кластеризация документов
Функция multi-document discovery определяет, сколько типов документов содержится в вашей коллекции, с помощью silhouette score. В данном контексте silhouette score показывает, насколько хорошо кластеры отделены друг от друга и насколько компактны документы внутри каждого кластера. С использованием k-means clustering агент по умолчанию тестирует значения k от 2 до 20 и выбирает группировку с наивысшим silhouette score. Здесь k — это количество различных типов документов в вашей коллекции. Чтобы кластеры были осмысленными, в каждом должно быть не менее двух документов. При необходимости верхняя граница k снижается ниже 20, чтобы соблюсти это ограничение.
Бенчмаркинг embedding и кластеризации
Чтобы проверить подход к embedding и кластеризации, мы провели эксперименты с Cohere Embed v4 на подмножестве набора данных OCR-benchmark dataset, доступного в корзине тестового набора, развернутой вместе со стеком IDP Accelerator CloudFormation. Чтобы найти имя своей корзины, откройте консоль CloudFormation, выберите стек IDP Accelerator, перейдите на вкладку Outputs и найдите ключ S3TestSetBucketName.
Этот набор данных состоит из одностраничных типов документов. Развернутое подмножество включает 293 документа по 9 типам: bank check, commercial lease agreement, credit card statement, delivery note, equipment inspection, glossary, petition form, real estate и shift schedule.
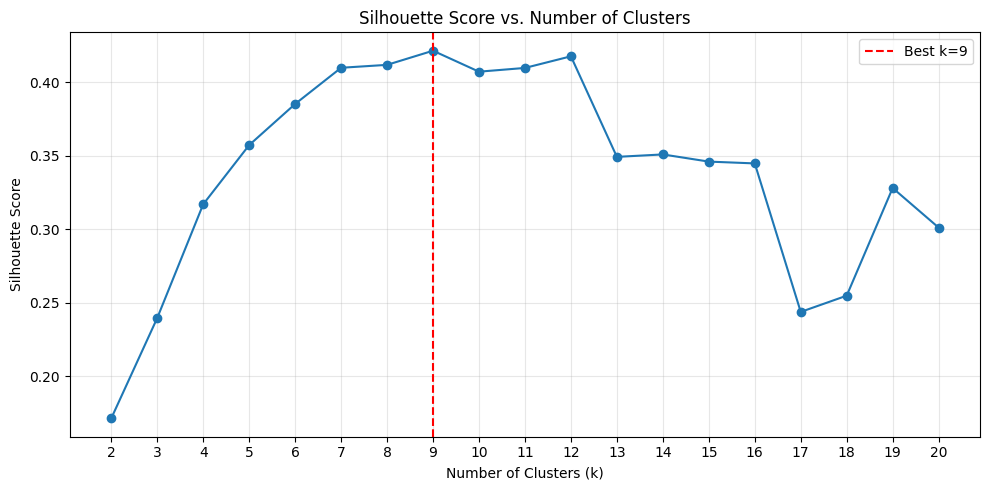
Чтобы оценить, может ли k-means clustering корректно определить эти группы с использованием модели Cohere embedding, мы проверили silhouette score как метрику выбора оптимального значения k. Мы запустили первые два этапа pipeline — embedding и кластеризацию — и проанализировали silhouette score для значений k от 2 до 20. Следующий график показывает распределение silhouette score по этим значениям k. Наивысший silhouette score наблюдается при k=9, что совпадает с истинным числом типов документов в наборе данных.
TSNE-plot (t-distributed Stochastic Neighbor Embedding plot, техника визуализации, которая снижает размерность высокоразмерных данных до 2D-пространства, сохраняя взаимосвязи между точками данных) показывает визуализацию этих embedding в двумерном пространстве, а классификация кластеров отображается в легенде.
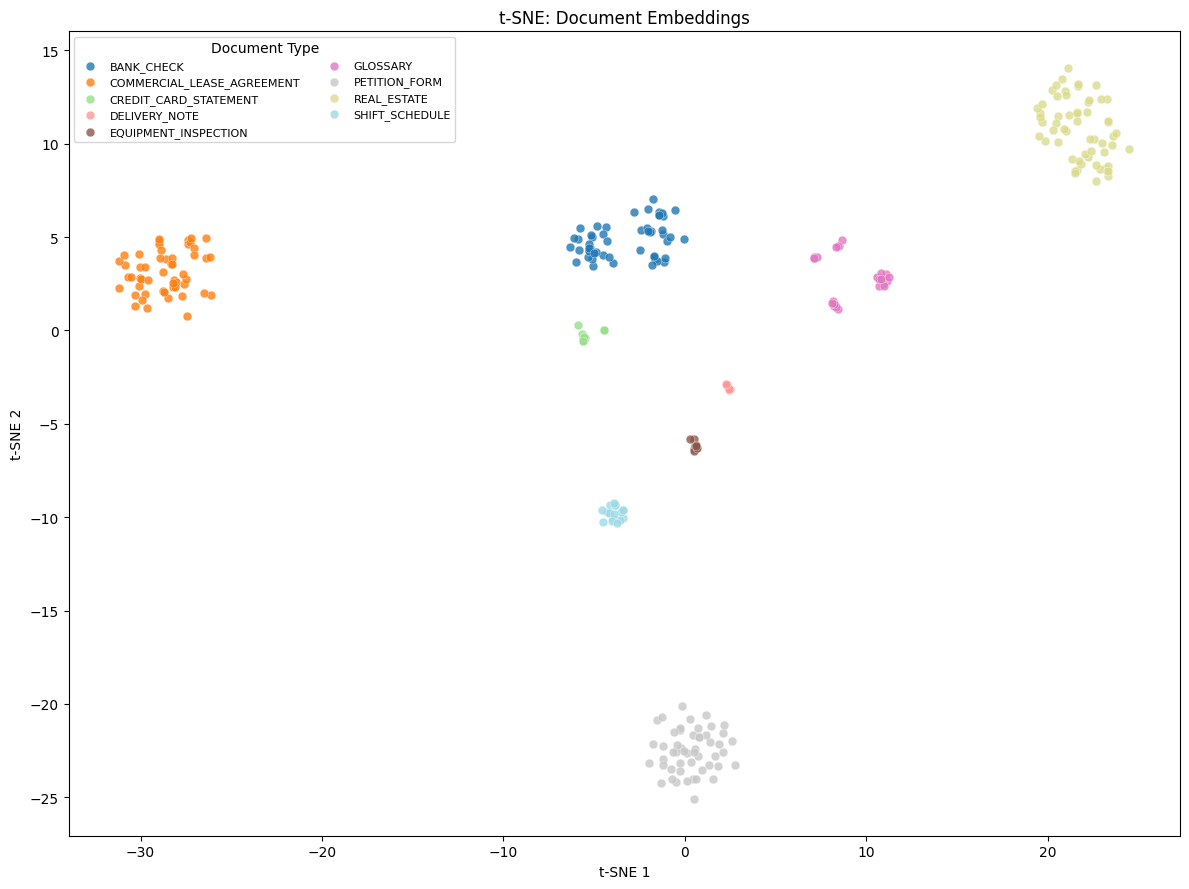
Кластеризация достигла идеальных показателей Adjusted Rand Index (ARI) и Normalized Mutual Information (NMI) на уровне 1.0. ARI показывает, насколько хорошо кластеризация соответствует истинным группам, а NMI измеряет объем информации, общую для предсказанных и фактических кластеров. Каждый кластер однозначно соответствует истинному классу документа при 100% чистоте. Эти результаты показывают, что качественные multimodal embeddings могут обеспечить полностью unsupervised классификацию документов. Embedding точно разделяют разные типы документов, такие как банковские чеки, формы недвижимости и выписки по кредитным картам, без размеченных обучающих данных.
Примечание: Результаты на этом бенчмарке не гарантируют аналогичную точность на ваших данных, поскольку характеристики конкретного набора данных напрямую влияют на качество итогов.
Agentic-генерация схем
После определения кластеров pipeline переходит к agentic-фазе. Для каждого кластера вызывается Strands Agent, который определяет тип документа и генерирует схему. Мы выбрали Strands Agents за его model-driven подход. Он дает модели гибкость самостоятельно рассуждать над каждой схемой. Перед генерацией схемы агент должен стратегически просмотреть документы в разных частях кластера, чтобы охватить все разнообразие. Например, он изучает один документ ближе к центру, один на периферии и один на промежуточной дистанции. Более детерминированный подход с фиксированной выборкой здесь не подошел бы, потому что качество кластеризации сильно зависит от ваших конкретных документов. Для этого агент оснащен двумя специализированными инструментами:
- Cluster Analysis Tool — получает идентификаторы документов, отсортированные по расстоянию от центроида кластера, что позволяет агенту стратегически выбирать образцы по всему диапазону вариаций внутри кластера.
- Document Viewer Tool — извлекает и сжимает изображения документов для визуального просмотра, автоматически учитывая ограничения размера для контекстного окна модели.
Системный prompt агента содержит предметные знания о соглашениях JSON Schema и требованиях конфигурации IDP Accelerator. Он instructs the agent to:
- Стратегически выбирать документы, останавливаясь раньше, если уверенность в достаточном охвате высока.
- Генерировать JSON Schema с правильными метаданными, определениями типов и описаниями.
- Добавлять специфичные для IDP Accelerator аннотации, такие как
x-aws-idp-document-typeиx-aws-idp-evaluation-method.x-aws-idp-evaluation-methodиспользуется расширением оценки на базе Stickler. - Создавать переиспользуемые
$defsдля общих структур, таких как адреса, позиции в строках и налоговая информация. - Применять подходящие методы оценки в зависимости от типа поля:
EXACTдля строк,NUMERIC_EXACTдля чисел,LLMдля сложных или вложенных объектов.
Инструменты, prompt и модель дают агенту возможность рассуждать о собственной стратегии выборки. Эти агенты работают параллельно, поэтому вам не приходится ждать завершения одного кластера, чтобы начал обрабатываться следующий.
Анализ схем
После того как каждый агент независимо генерирует схему, этап анализа схем оценивает общую различимость результатов. Он проверяет, хорошо ли отделены обнаруженные группы документов или они перекрываются, а также насколько полными и согласованными являются сгенерированные схемы. Он ищет повторы и дублирование между типами документов. На основе этих выводов система формулирует конкретные рекомендации, например объединить кластеры или уточнить определения полей. Она формирует сводный отчет, включая понятный человеку обзор классов. Этот quality report доступен в сведениях о Discovery Job в IDP Accelerator.
Запуск задачи на ваших документах
Чтобы запустить workflow multi-document discovery на собственных документах, выполните следующие шаги в консоли IDP Accelerator.
Шаг 1: Создайте новую конфигурацию
Начните с создания новой конфигурации в консоли IDP Accelerator:
- Перейдите в раздел Configuration и выберите View/Edit Configuration.
- Выберите Document Schema > Wipe All, чтобы создать новую пустую конфигурацию.
- Нажмите Save as Version, задайте описательное значение Version Name, затем снова выберите Save as Version.
Шаг 2: Запустите multi-document discovery
Когда конфигурация готова, запустите процесс discovery:
- Перейдите в раздел Discovery и выберите опцию Multiple Documents.
- Выберите только что созданную версию конфигурации.
- Настройте источник документов: выберите S3 Path или Zip Upload, затем выберите исходную корзину и укажите S3 prefix, где хранятся ваши документы.
Примечание: Чтобы использовать вариант Source Bucket, документы нужно добавить в одну из существующих корзин IDP Accelerator — Discovery Bucket, Test Bucket или Input Bucket.
- Нажмите Start Discovery, чтобы запустить state machine.
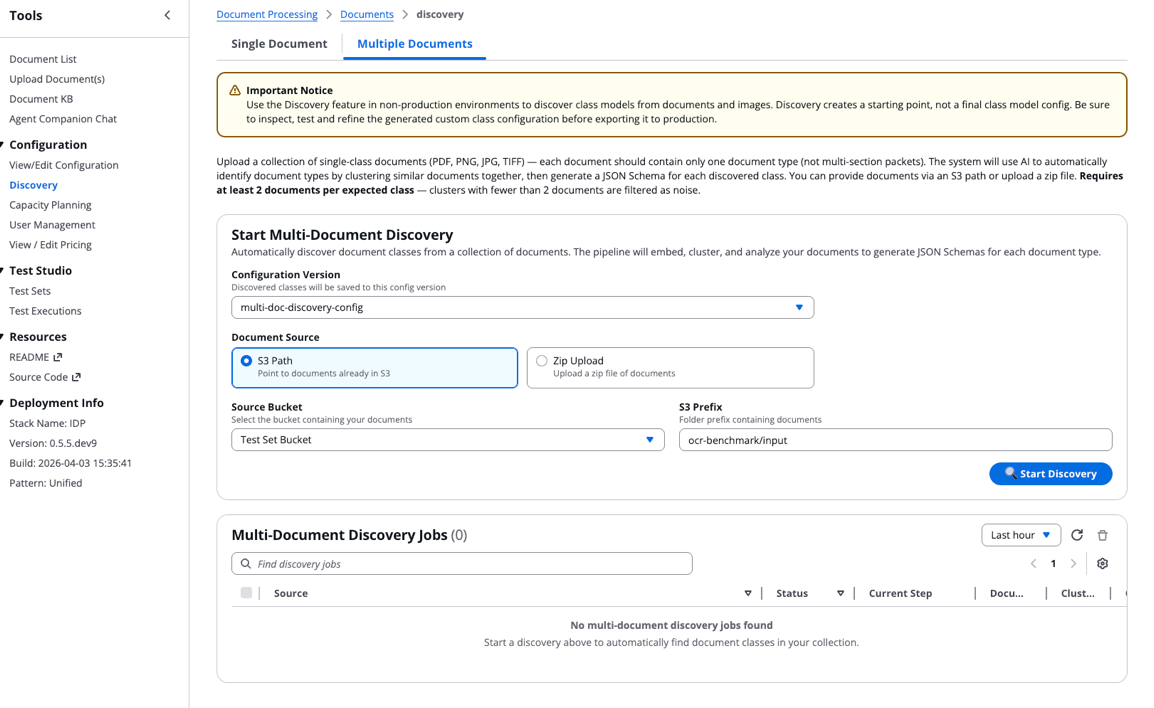
Шаг 3: Отслеживайте задачу discovery и просматривайте результаты
Следите за ходом выполнения задачи discovery:
- В таблице Multi-Document Discovery Jobs появится новая запись со статусом выполнения, текущим этапом и метаданными.
- После завершения задачи выберите поле Source, чтобы посмотреть результаты:
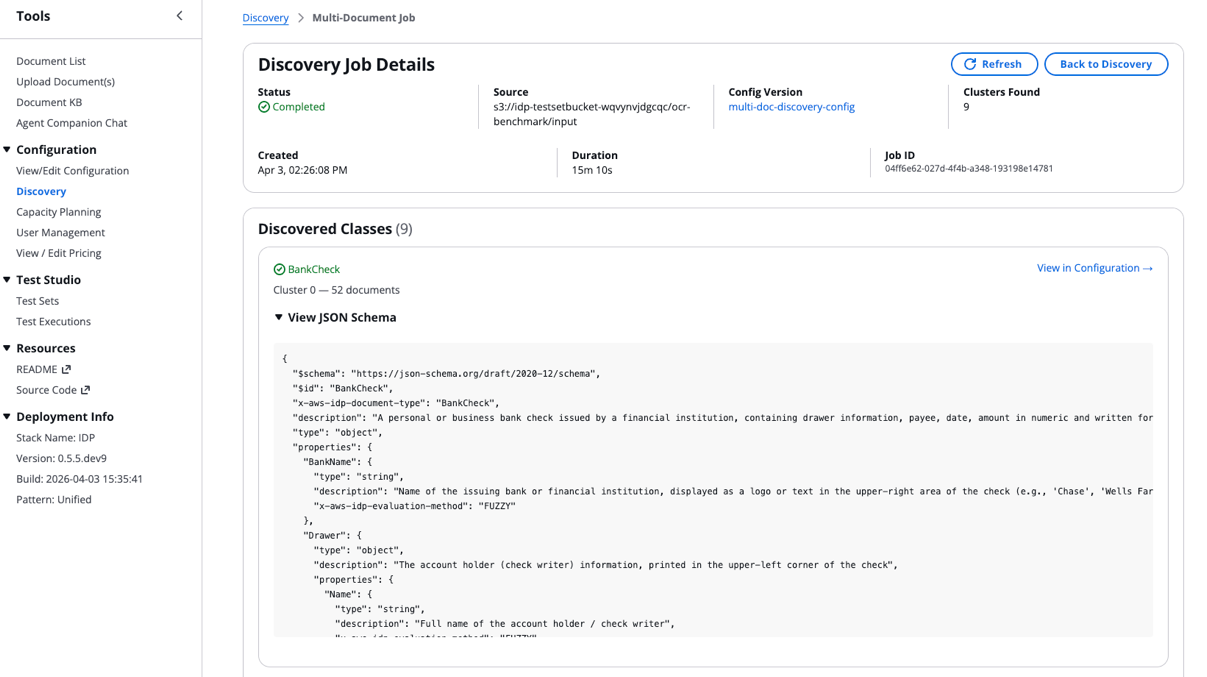
- Прокрутите вниз в Discovery Job Details, чтобы открыть Quality Report:
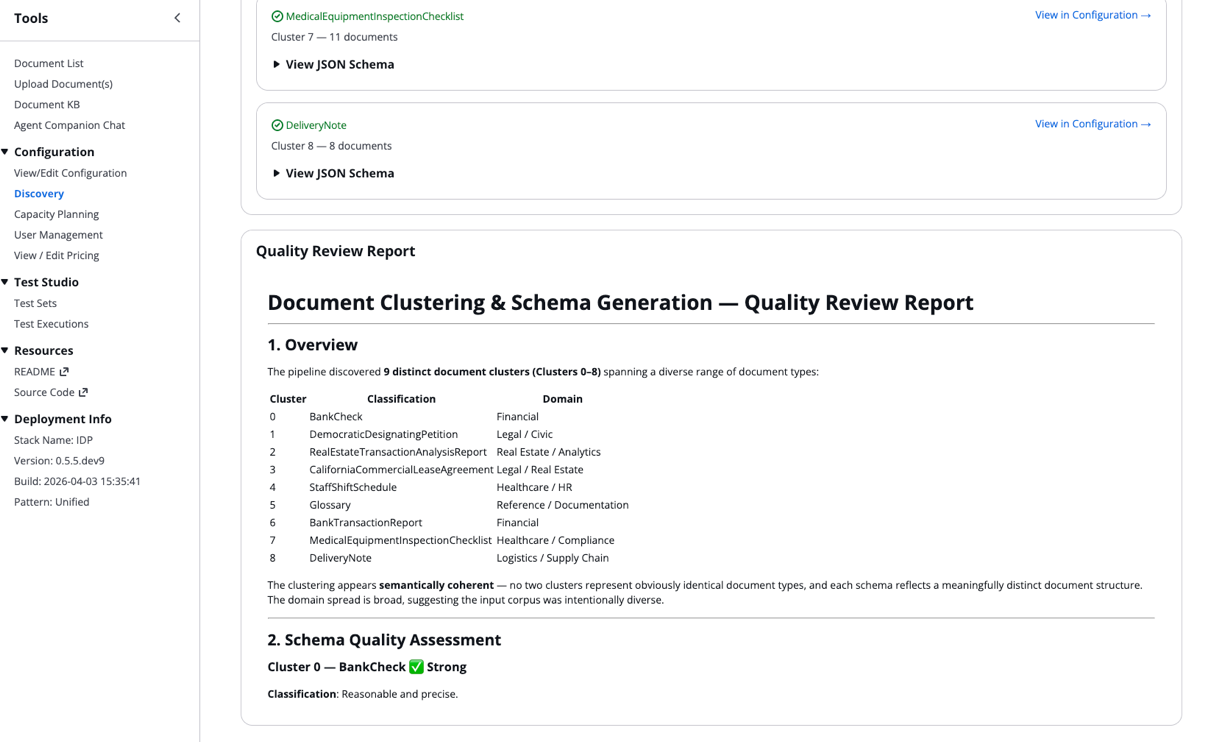
Обнаруженные классы и их JSON Schema автоматически интегрируются в ваш файл конфигурации.
Практики для лучших результатов
Перед запуском multi-document discovery в масштабе стоит помнить о нескольких рекомендациях. Поскольку workflow сейчас обрабатывает только первую страницу каждого PDF, убедитесь, что входные файлы представляют собой отдельные документы. Многостраничные пакеты документов пока не поддерживаются. После получения первых результатов внимательно изучите сводку quality report, чтобы до окончательного утверждения схем выявить проблемы вроде перекрывающихся кластеров или неравномерного распределения документов.
Следующие шаги
Дальнейшие действия зависят от того, что workflow обнаружил в ваших документах:
- Если схемы выглядят чисто, а quality report показывает низкий уровень пересечений, можно переходить к масштабному запуску IDP на ваших документах. Схемы автоматически добавляются в поле classes конфигурации IDP Accelerator.
- Если quality report указал на перекрывающиеся кластеры, изучите рекомендации и используйте их для доработки сгенерированных схем. Это может включать объединение похожих схем в один класс или изменение определений полей для снижения пересечений.
- Если качество схем заметно отличается между кластерами, проверьте, не является ли распределение типов документов в коллекции слишком неравномерным. Запуск discovery job на более сбалансированном подмножестве может помочь агенту сформировать более надежные кластеры и схемы.
Заключение
В этом материале мы показали, как multi-document discovery решает проблему, когда схемы нужны до обработки документов, но сами схемы невозможно построить без обработки документов. Решение объединяет visual embeddings, автоматическую кластеризацию и agentic-генерацию схем с использованием multimodal LLM. Оно превращает неочевидную коллекцию неизвестных документов в структурированные, готовые к проверке классы документов и схемы. Вы увидели, как workflow обрабатывает генерацию embedding, настройку кластеров и параллельную классификацию и генерацию схем. Вы также увидели, как этап reflection дает прозрачный анализ результатов агента для дальнейшей человеческой проверки.
Нам будет интересно узнать, как функция multi-document discovery работает на ваших коллекциях документов. Делитесь результатами, вопросами и предложениями в комментариях ниже. Если вы столкнетесь с проблемами или захотите внести вклад, откройте issue или pull request в GitHub-репозитории.
Материал — перевод статьи с английского.
Оригинал: Automate schema generation for intelligent document processing