Обработка финансовых документов с Pulse AI и Amazon Bedrock

Финансовые учреждения ежедневно обрабатывают тысячи сложных документов. Ошибки оптического распознавания символов (OCR) в финансовых данных могут распространяться через взаимосвязанные расчеты и снижать точность аналитики. Если единичная OCR-ошибка в обычном юридическом документе часто требует лишь быстрой ручной правки, то такая же ошибка в финансовых данных может каскадом пройти через связанные вычисления, привести к систематическим ошибкам в анализе и стать дорогостоящей для организации.
Традиционные инструменты OCR критически плохо справляются со сложными финансовыми документами, которые учреждения обрабатывают каждый день, — балансами, отчетами о прибылях и убытках, материалами SEC, исследовательскими отчетами и аудиторскими документами. Такие материалы содержат сложные табличные структуры со слиянием ячеек и иерархическими данными, многоколоночные макеты со взаимосвязанными ссылками и зависящую от контекста информацию, требующую семантического понимания. Традиционные подходы OCR рассматривают эти документы как изображения, упуская структурные связи и контекстные нюансы, которые делают финансовые документы осмысленными. В результате возникают цепочки ручных исправлений, задержки ввода данных и систематические аналитические ошибки.
В этом материале показано, как построить конвейер извлечения данных из документов и дообучения модели, который решает эти критические задачи. Объединив продвинутые возможности понимания документов от Pulse AI с мощными AI-сервисами Amazon Bedrock, организации могут добиться точности уровня enterprise и извлекать контекстно релевантные финансовые инсайты в масштабе. Amazon Bedrock обеспечивает полностью управляемую настройку моделей без накладных расходов на операции машинного обучения (ML), развертывание по требованию без планирования емкости, а семейство моделей Nova дает выгодное соотношение цены и производительности, чтобы команды могли сосредоточиться на инновациях, а не на инфраструктуре.
В отличие от традиционных монолитных OCR-конвейеров, Pulse объединяет vision language models с классическими ML-компонентами, специально созданными для понимания документов, и формирует интеллектуальное решение, которое извлекает структурированные данные с учетом семантики, создает улучшенные наборы данных для supervised fine-tuning в финансовой области и позволяет развертывать собственные большие языковые модели (LLMs), обученные на ваших финансовых данных. Pulse используется в глобальных компаниях, включая Samsung, Cloudera, Howard Hughes, а также в финансовых учреждениях из списка Fortune 500 и ведущих private equity-фирмах, которые обрабатывают большие объемы финансовых и операционных документов.
В одном внедрении партия из примерно 1 000 сложных финансовых документов, на обработку которых раньше уходило несколько дней, была обработана менее чем за три часа, при этом были получены структурированные, пригодные для аудита результаты, готовые для downstream-аналитики и AI-приложений.
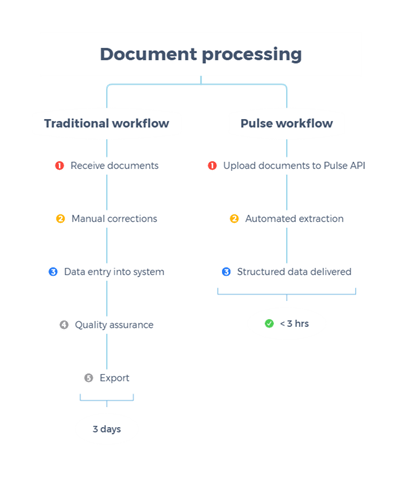
Рис. 1. Рабочие процессы обработки документов: традиционный подход против Pulse
В целом, совместно Pulse AI и Amazon Bedrock дают следующее:
- Pulse AI извлекает структурированные данные с учетом семантики из сложных финансовых документов, обрабатывая сложные таблицы, многоколоночные макеты и иерархические данные.
- Amazon Bedrock дообучает модели Amazon Nova на этих высококачественных данных, создавая доменно-специфичный интеллект для финансовых конвенций вашей организации.
- Затем пользовательские модели обрабатывают новые документы с учетом специфики организации, сокращая ручную проверку с дней до часов.
Ниже показан workflow-подход к созданию интеллектуальных финансовых приложений. Начиная с исходных финансовых документов, конвейер выстраивает сложную последовательность шагов — от обработки документов и fine-tuning до развертывания — чтобы создать собственное AI-решение, адаптированное для анализа финансовых данных и получения инсайтов.
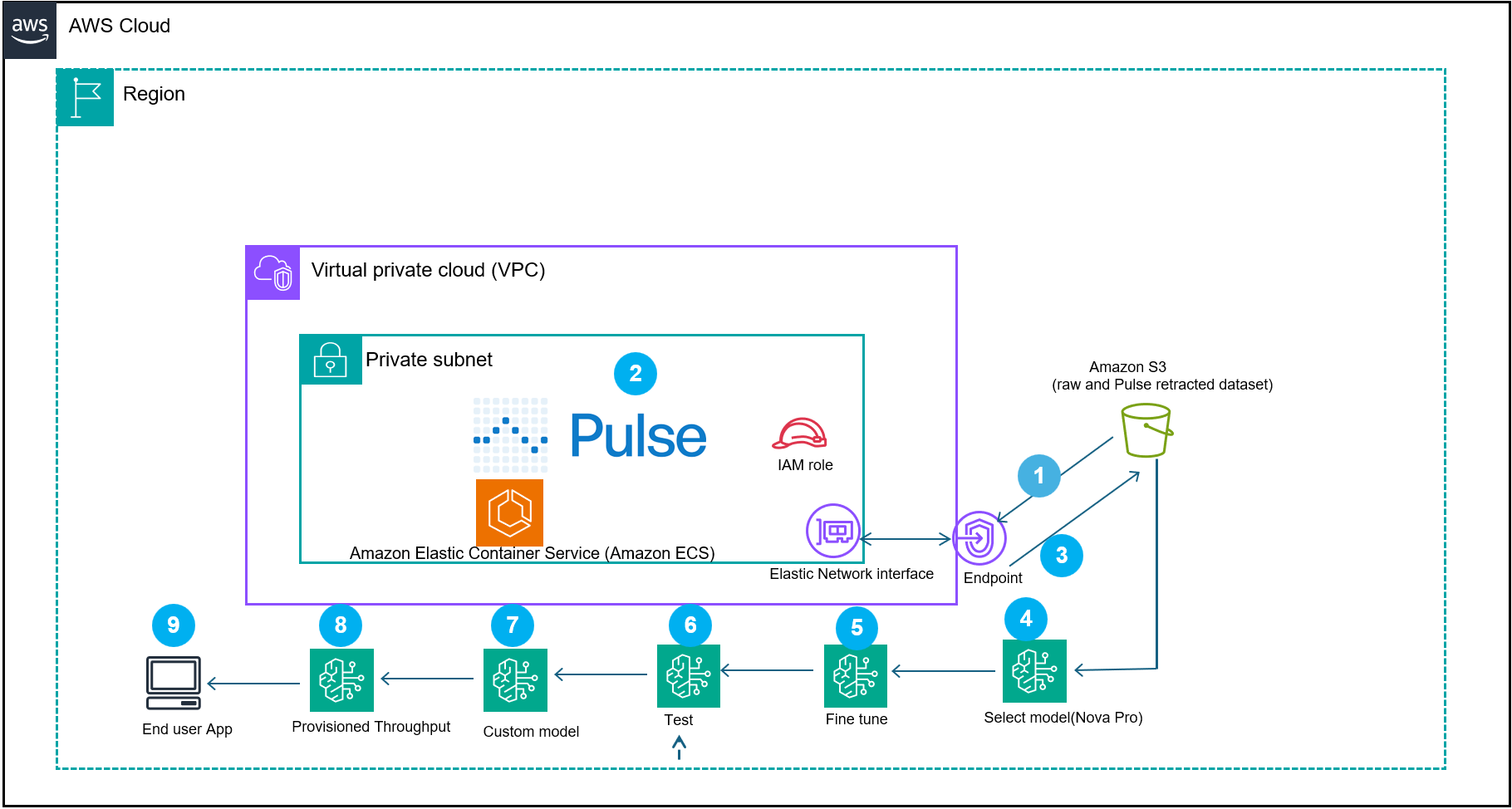
Рис. 2. Рабочий процесс reference architecture для обработки документов, демонстрирующий, как Pulse AI, интегрированный с сервисами AWS, создает доменные модели для intelligent document processing (IDP)
Система начинается с шага 1: документы загружаются в контейнер Pulse в вашем VPC или в предложении Pulse software as a service (SAAS). Модель Pulse обрабатывает финансовые документы (шаг 2). Выходные данные извлеченной информации преобразуются в формат supervised fine-tuning для Amazon Bedrock Nova Micro и затем сохраняются в Amazon Simple Storage Service (Amazon S3) (шаг 3).
Далее workflow использует дополнительные расширенные возможности Amazon Bedrock:
Запускается задача supervised fine-tuning с использованием Amazon Nova Micro (amazon.nova-micro-v1:0) — экономичной модели, предназначенной для задач текстового извлечения, с окном контекста 128K (шаги 5 и 6). Nova Micro обеспечивает конкурентную стоимость и производительность. После завершения задания разверните итоговую модель для on-demand inference. Для критически важных рабочих нагрузок, которым нужна стабильная производительность, можно также использовать Provisioned Throughput. Используйте Test in Playground, чтобы оценить и сравнить ответы. Итоговая пользовательская модель импортируется в Amazon Bedrock (шаг 8) и развертывается с provisioned throughput (шаг 9), чтобы поддерживать масштабируемое конечное приложение (шаг 10). Эта архитектура объединяет доменный финансовый датасет с пользовательской supervised fine-tuned моделью, чтобы организации могли строить production-ready AI-приложения, понимающие финансовый контекст, при этом сохраняя производительность и экономическую эффективность.
Предварительные условия
Чтобы повторить этот материал, вам потребуются следующие предварительные условия.
- AWS Account — требуется для доступа к сервисам AWS, включая Amazon Bedrock и хранилище S3 для ваших наборов данных.
- Политики AWS Identity and Access Management (IAM), разрешающие Amazon Bedrock доступ к наборам данных в S3 — предоставляют необходимые разрешения, чтобы Amazon Bedrock мог безопасно читать и обрабатывать данные, хранящиеся в корзинах S3.
- Требование к региону AWS:
us-east-1. - Python 3.12 или более поздняя версия.
- Тип инстанса:
t3.medium. - Экземпляры Amazon Elastic Compute Cloud (Amazon EC2) тарифицируются почасово. Не забудьте завершить инстанс после выполнения этого руководства, чтобы избежать дальнейших расходов.
- Amazon Linux 2023 (последняя версия).
- Публичная финансовая выписка: https://www.impact-bank.com/user/file/dummy_statement.pdf.
- Корзина S3 для обучающих данных:
s3://<your s3 bucket>/training-data/.
Примечание: это руководство создает ресурсы AWS, за которые взимается плата, включая: инстанс EC2 (почасово), хранение S3 (за GB-месяц), fine-tuning в Amazon Bedrock (за час обучения), развертывание provisioned throughput (почасово) и AWS Secrets Manager (за один секрет в месяц).
Пошаговая реализация
Выполните следующие шаги, чтобы настроить и сконфигурировать конвейер обработки финансовых документов с использованием Pulse AI и Amazon Bedrock.
- Перейдите в Pulse console и создайте учетную запись.
- Запустите инстанс EC2 через AWS Console.
- Перейдите в консоль EC2.
- Выберите Launch Instance.
- На экране выбора AMI выполните поиск Amazon Linux 2023 AMI.
- Выберите Amazon Linux 2023 AMI.
- На экране выбора типа инстанса выберите t3.medium.
- Создайте новую key pair для SSH-доступа к Linux-инстансу.
- В конфигурации security group добавьте правило для разрешения SSH (порт 22) с вашего IP-адреса.
- Выберите Launch.
- Сохраните идентификатор инстанса, который появится в сообщении об успешном создании.
- Создайте API key в RunPulse.
- Чтобы найти публичный DNS вашего инстанса:
- Перейдите в консоль EC2.
- Выберите свой инстанс.
- Скопируйте значение Public IPv4 DNS на вкладке Details.
- Чтобы подключиться к инстансу EC2, выполните следующую SSH-команду. Замените
YOUR_KEY_FILE.pemна имя вашего файла key pair, аYOUR_INSTANCE_DNS— на значение Public IPv4 DNS из шага 4a:ssh -i YOUR_KEY_FILE.pem ec2-user@YOUR_INSTANCE_DNS Example: ssh -i my-keypair.pem ec2-user@ec2-54-123-45-67.compute-1.amazonaws.com - На инстансе EC2 настройте учетные данные AWS, выполнив
aws configure. Когда система запросит данные, введите Access Key ID, secret access key, регион (us-east-1) и формат вывода (json). - Сохраните свой Pulse API key в AWS Secrets Manager с помощью указанной команды:
aws secretsmanager create-secret --name pulse-api-key --secret-string "your-api-key" - Запишите ARN, поскольку он потребуется для policy разрешений.
Примечание: AWS Command Line Interface (AWS CLI) version 2 по умолчанию уже предустановлен в Amazon Linux 2023 AMIs.
- На инстансе EC2 установите SDK runpulse.
- Установите pip:
sudo yum install pip - Установите Pulse Python SDK:
pip install pulse-python-sdk
- Установите pip:
- На инстансе EC2 создайте в текущем рабочем каталоге файл bedrock-trust-policy.json с конфигурацией, показанной в следующем разделе. Можно использовать текстовый редактор nano или vi:
nano bedrock-trust-policy.json.- Создайте
bedrock-trust-policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "bedrock.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "aws:SourceAccount": "your-aws-account-ID" }, "ArnLike": { "aws:SourceArn": "arn:aws:bedrock:us-east-1:your-aws-account-ID:model-customization-job/*" } } } ] } - Создайте
bedrock-permissions.json{ "Version": "2012-10-17", "Statement": [ { "Sid": "S3AccessForFineTuning", "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::your-bucket-name", "arn:aws:s3:::your-bucket-name/*" ] }, { "Sid": "SecretsManagerAccess", "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue", "secretsmanager:PutSecretValue", "secretsmanager:CreateSecret", "secretsmanager:UpdateSecret", "secretsmanager:DescribeSecret" ], "Resource": [ "arn:aws:secretsmanager:us-east-1:your-aws-account-ID:secret:your-secret-name-*" ] } ] } - Затем создайте роль:
aws iam create-role --role-name AmazonBedrock-FineTuning-S3-Role --assume-role-policy-document file://bedrock-trust-policy.json --description "Role for Bedrock fine-tuning with S3 and Secrets Manager access"Ожидаемый вывод: JSON с ARN роли, ID и временной меткой создания. Затем:
- Создайте
- Создайте policy разрешений:
aws iam put-role-policy --role-name AmazonBedrock-FineTuning-S3-Role --policy-name Bedrock-S3-Access-Policy --policy-document file://bedrock-permissions.json
- Просмотрите роль и trust policy:
aws iam get-role --role-name AmazonBedrock-FineTuning-S3-Role
- Чтобы извлечь набор данных из reference financial document, выполните следующую команду на инстансе EC2
Получение API key из Secrets Manager. Лучшая практика безопасности: не встраивайте учетные данные в код. Извлекайте их из AWS Secrets Manager.
curl -X POST https://api.runpulse.com/extract -H "x-api-key: $(aws secretsmanager get-secret-value --secret-id pulse-api-key --query SecretString --output text)" -H "Content-Type: application/json" -d '{ "file_url": "https://www.impact-bank.com/user/file/dummy_statement.pdf", "figureProcessing": {"description": true}, "extensions": {"altOutputs": {"returnHtml": true}} }'> pulse_output.json
Пример извлеченного фрагмента JSON от Pulse AI:
{"bounding_boxes":{"Header":[{"average_word_confidence":0.9940000000000001,"bounding_box":[0.7418,0.04248181818181818,0.8901529411764706,0.042281818181818184,0.8901764705882352,0.05528181818181818,0.741835294117647,0.05548181818181818],"content":"0a-Account # 12345678","id":"txt-8","original_content":"Account # 12345678","page_number":2}],"Page Number":[{"average_word_confidence":0.99425,"bounding_box":[0.8071411764705881,0.24754545454545454,0.889635294117647,0.2474909090909091,0.8896588235294117,0.2616454545454545,0.8071529411764706,0.2617],"content":"0a-Page 1 of 2","id":"txt-3","original_content":"Page 1 of 2","page_number":1},{"average_word_confidence":0.9925,"bounding_box":[0.8076235294117646,0.057600000000000005,0.8898117647058823,0.05738181818181818,0.8898705882352942,0.0704,0.8076823529411765,0.07061818181818182],"content":"0a-Page 2 of 2","id":"txt-9","original_content":"Page 2 of 2","page_number":2}],"Tables":[{"cell_data":[{"confidence":0.9772562500000003,"location":{"coordinates":[0.0906,0.44435454545454545,0.8865647058823529,0.44499090909090905,0.8865647058823529,0.4685,0.0906,0.4678636363636363],"page":1},"position":{"column":0,"row":0},"properties":{"spans_columns":4,"type":"header"},"text":"0t-"},
- Проверьте, что извлечение прошло успешно: убедитесь, что файл существует и содержит корректный JSON.
jq empty pulse_output.json &amp;&amp; echo "Valid JSON" || echo " Invalid JSON"
- Далее преобразуйте извлеченные данные в training dataset для Nova.
- Создайте новый файл convert_to_nova.py и вставьте следующий код.
import jsonINPUT_FILE = "pulse_output.json" OUTPUT_FILE = "nova_dataset.jsonl"MAX_TOKENS = 30000 # Buffer below 32,768 limitdef estimate_tokens(text): """Rough token estimation: ~4 characters per token""" return len(text) // 4def create_truncated_samples(data): """Creates smaller training samples within token limits""" samples = [] # Sample 1: Header and Page Number only if "bounding_boxes" in data: if "Header" in data["bounding_boxes"] and "Page Number" in data["bounding_boxes"]: header_sample = { "Header": data["bounding_boxes"]["Header"], "Page Number": data["bounding_boxes"]["Page Number"] } samples.append({ "document": header_sample, "extracted_data": header_sample }) # Samples 2-4: Individual tables (truncated to 20 cells) if "Tables" in data["bounding_boxes"]: for i, table in enumerate(data["bounding_boxes"]["Tables"][:3]): truncated_table = { "table_info": table.get("table_info", {}), "cell_data": table.get("cell_data", [])[:20] } samples.append({ "document": {"Tables": [truncated_table]}, "extracted_data": {"Tables": [truncated_table]} }) # Samples 5-7: Text chunks (3 items each) if "Text" in data["bounding_boxes"]: text_items = data["bounding_boxes"]["Text"] chunk_size = 3 for i in range(0, min(9, len(text_items)), chunk_size): text_chunk = {"Text": text_items[i:i+chunk_size]} samples.append({ "document": text_chunk, "extracted_data": text_chunk }) # Sample 8: Title only if "Title" in data["bounding_boxes"]: title_sample = {"Title": data["bounding_boxes"]["Title"]} samples.append({ "document": title_sample, "extracted_data": title_sample }) return samplesdef convert_to_nova_format(sample): """ Converts to Nova format with instructional prompts for domain-specific learning This function creates training samples that teach the model: 1. Financial document structure recognition (headers, tables, transactions) 2. Data type standardization (dates to ISO 8601, amounts to numbers) 3. Hierarchical relationship preservation (accounts → transactions → details) 4. Out-of-sequence detection (items marked with *) 5. Financial domain conventions (check numbers, terminal IDs, merchant data)""" doc_str = json.dumps(sample["document"]) extract_str = json.dumps(sample["extracted_data"]) total_tokens = estimate_tokens(doc_str) + estimate_tokens(extract_str) if total_tokens > MAX_TOKENS: print(f"Warning: Sample too large ({total_tokens} tokens), skipping...") return None return { "schemaVersion": "bedrock-conversation-2024", "messages": [ { "role": "user", "content": [{"text": doc_str}] }, { "role": "assistant", "content": [{"text": extract_str}] } ] }# Read inputwith open(INPUT_FILE, "r") as f: pulse_data = json.load(f)if isinstance(pulse_data, dict): pulse_data = [pulse_data]# Generate truncated samplesall_samples = []skipped = 0for record in pulse_data: truncated_samples = create_truncated_samples(record) for sample in truncated_samples: nova_record = convert_to_nova_format(sample) if nova_record: all_samples.append(nova_record) else: skipped += 1# Write to JSONLwith open(OUTPUT_FILE, "w") as f: for nova_record in all_samples: f.write(json.dumps(nova_record) + "\n")print(f"✓ Created {len(all_samples)} training samples")print(f"✓ Skipped {skipped} samples that were too large")print(f"✓ Output saved to: {OUTPUT_FILE}")print(f"All samples are under {MAX_TOKENS} tokens (limit: 32,768)")print(f"Next steps:")print(f"1. Verify: wc -l {OUTPUT_FILE}")print(f"2. Upload: aws s3 cp {OUTPUT_FILE} s3://anypulse/training-data/nova_dataset.jsonl")print(f"3. Create new fine-tuning job")"""TRAINING FORMAT EXPLANATION:What this fine-tuning teaches Nova Micro:This conversion script creates training samples in a format that teaches Nova Micro domain-specific financial document understanding through pattern learning. While the training samples use a direct JSON-to-JSON mapping (user message contains Pulse extracted JSON, assistant message contains the same structured JSON), the model learns several key capabilities:1. DOCUMENT STRUCTURE RECOGNITION - Hierarchical relationships: Headers → Tables → Text → Page Numbers - Bounding box spatial understanding: Coordinate systems and element positioning - Multi-page document handling: Page number tracking and cross-page references 2. FINANCIAL DATA PATTERNS - Table structure preservation: Row/column semantics, cell-level extraction - Confidence score interpretation: High-confidence fields (0.99+) vs. lower confidence - Data type consistency: Account numbers, dates, monetary amounts, check numbers 3. STRUCTURAL CONSISTENCY - Field naming conventions: "content", "confidence", "page_number", "bounding_box" - Nested object relationships: Tables contain cell_data arrays with position metadata - Metadata preservation: Original_content alongside normalized values for audit trails4. DOMAIN-SPECIFIC CONVENTIONS - Financial document sections: Headers, footers, transaction tables, summary sections - Out-of-sequence detection: Items marked with asterisk (*) in check numbers - Merchant data extraction: Terminal IDs, location information, transaction referencesLEARNING MECHANISM:The model learns through exposure to Pulse AI's high-quality structured extraction patterns. By seeing hundreds of examples of how Pulse structures financial document data (with confidence scores, bounding boxes, hierarchical relationships), Nova Micro internalizes these patterns and can apply them to new financial documents.This approach is effective because:- Pulse AI provides consistently structured, high-quality training data- The JSON schema is self-documenting (field names indicate purpose)- Repetition across samples reinforces structural patterns- Confidence scores teach the model which extractions are reliableALTERNATIVE APPROACHES:For production deployments requiring more explicit task framing, consider adding instructional prompts to the training samples: instructional_prompt = f'''You are a financial document extraction specialist. Extract structured information from the following financial document and return it as valid JSON. Requirements: - Extract all key financial data (accounts, balances, transactions, dates) - Use consistent field naming (snake_case format) - Convert dates to ISO 8601 format (YYYY-MM-DD) - Represent monetary amounts as numbers with currency metadata - Preserve hierarchical relationships - Detect out-of-sequence items (marked with *) Financial Document: {doc_str} Return only the extracted JSON without explanations.'''This instructional approach provides explicit requirements and task context, which can improve generalization to document types not seen during training. However, for workflows where Pulse AI handles extraction and the model primarily learns to replicate Pulse's output structure, the current direct mapping approach is sufficient and avoids token overhead from lengthy instructions.PRODUCTION CONSIDERATIONS:- Training dataset size: 100–500 samples for pilot, 5,000–10,000 for production- Evaluation metrics: Compare fine-tuned model output against Pulse baseline- Iterative improvement: Retrain quarterly with new document types and edge cases- Quality monitoring: Track confidence scores and manual review rates post-deployment"""
Запустите скрипт преобразования: python3 convert_to_nova.py
Это создаст файл jsonl: nova_dataset.jsonl
После fine-tuning Nova Micro должна научиться делать следующее по-другому: полное распознавание структуры документа, комплексное извлечение таблиц, интеграцию данных из разных документов и учет конвенций финансовых документов.
- Создайте S3 bucket для обучающих данных, если он еще не создан:
aws s3 mb s3://your-unique-bucket-name --region us-east-1
Включите versioning для защиты данных:
aws s3api put-bucket-versioning --bucket your-unique-bucket-name --versioning-configuration Status=Enabled
- Загрузите Nova training dataset в ваш S3 training bucket для fine tuning в Amazon Bedrock Nova
aws s3 cp nova_dataset.jsonl s3://<your s3 bucket>/training-data/
Примечание: задачи fine-tuning и развертывание пользовательских моделей в Amazon Bedrock тарифицируются. Перед продолжением ознакомьтесь с ценами Amazon Bedrock по адресу https://aws.amazon.com/bedrock/pricing/.
- Теперь запустите training job в Amazon Bedrock
aws bedrock create-model-customization-job --job-name my-fine-tuning-job-nova-micro --custom-model-name my-custom-pulse-model-nova-micro --role-arn arn:aws:iam::<Your-AWS-Account>:role/AmazonBedrockNovaFineTuningRole --base-model-identifier amazon.nova-micro-v1:0:128k --training-data-config s3Uri=s3://<your-s3-bucket>/training-data/nova_dataset.jsonl --output-data-config s3Uri=s3://<your-s3-bucket>/output/ --hyper-parameters '{"epochCount":"2","learningRate":"0.00001","learningRateWarmupSteps":"10"}'
- Ход обучения можно отслеживать через консоль

Или выполнив следующую команду
export CUSTOM_MODEL_ARN=$(aws bedrock get-model-customization-job --job-identifier "<JobArn>" --region us-east-1 --query 'outputModelArn' --output text)
echo "Your custom model ARN: $CUSTOM_MODEL_ARN"
jobArn можно получить в консоли или из вывода запущенной задачи.
После завершения консоль отразит статус

- Чтобы развернуть новую пользовательскую модель, выполните:
aws bedrock create-custom-model-deployment --model-deployment-name "my-custom-pulse-model-deployment" --model-arn "$CUSTOM_MODEL_ARN" --region us-east-1
- Чтобы проверить статус развертывания пользовательской модели
aws bedrock get-custom-model-deployment --custom-model-deployment-identifier "your-deployment-name-or-arn" --region us-east-1
Статус “Active” подтверждает завершение развертывания
Убедитесь, что модель готова:
aws bedrock get-provisioned-model-throughput --provisioned-model-id <model-id> --region us-east-1
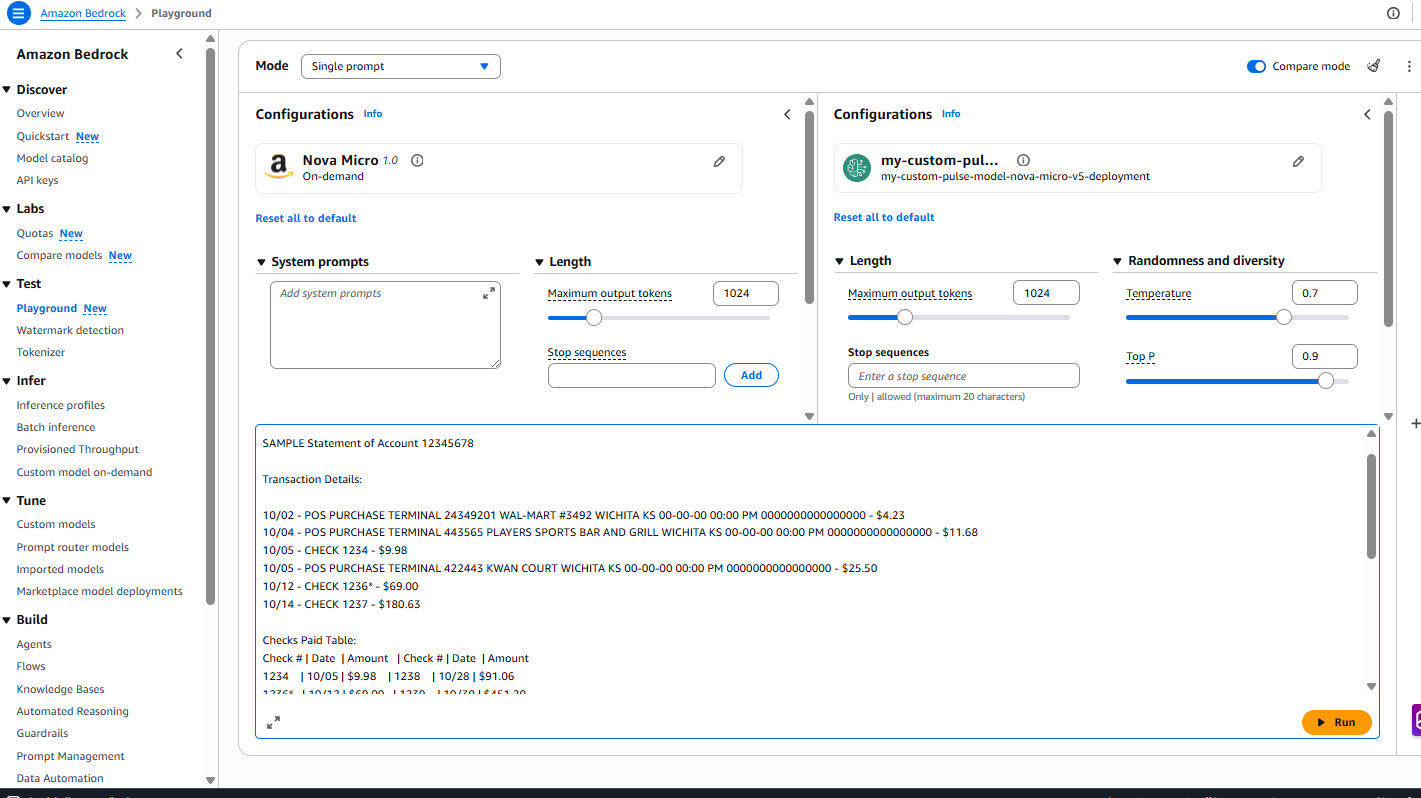
Перед тестированием подтвердите, что статус показывает “InService”. Тестирование выполняется в Amazon Bedrock playground.
Prompt, использованный для тестирования:
Extract detailed transaction information from this bank statement:
SAMPLE Statement of Account 12345678
Transaction Details:
10/02 - POS PURCHASE TERMINAL 24349201 WAL-MART #3492 WICHITA KS 00-00-00 00:00 PM 0000000000000000 - $4.23
10/04 - POS PURCHASE TERMINAL 443565 PLAYERS SPORTS BAR AND GRILL WICHITA KS 00-00-00 00:00 PM 0000000000000000 - $11.68
10/05 - CHECK 1234 - $9.98
10/05 - POS PURCHASE TERMINAL 422443 KWAN COURT WICHITA KS 00-00-00 00:00 PM 0000000000000000 - $25.50
10/12 - CHECK 1236* - $69.00
10/14 - CHECK 1237 - $180.63
Checks Paid Table:
Check # | Date | Amount | Check # | Date | Amount
1234 | 10/05 | $9.98 | 1238 | 10/28 | $91.06
1236* | 10/12 | $69.00 | 1239 | 10/30 | $451.20
1237 | 10/14 | $180.63 | 1246* | 10/30 | $37.07
For each POS purchase, extract:
1. Terminal ID
2. Merchant name
3. Location (city, state)
4. Transaction reference number
5. Amount
For each check, extract:
1. Check number
2. Date cleared
3. Amount
4. Sequence status (normal or out-of-sequence marked with *)
Provide output as structured JSON with nested objects for transaction details.
Результаты:
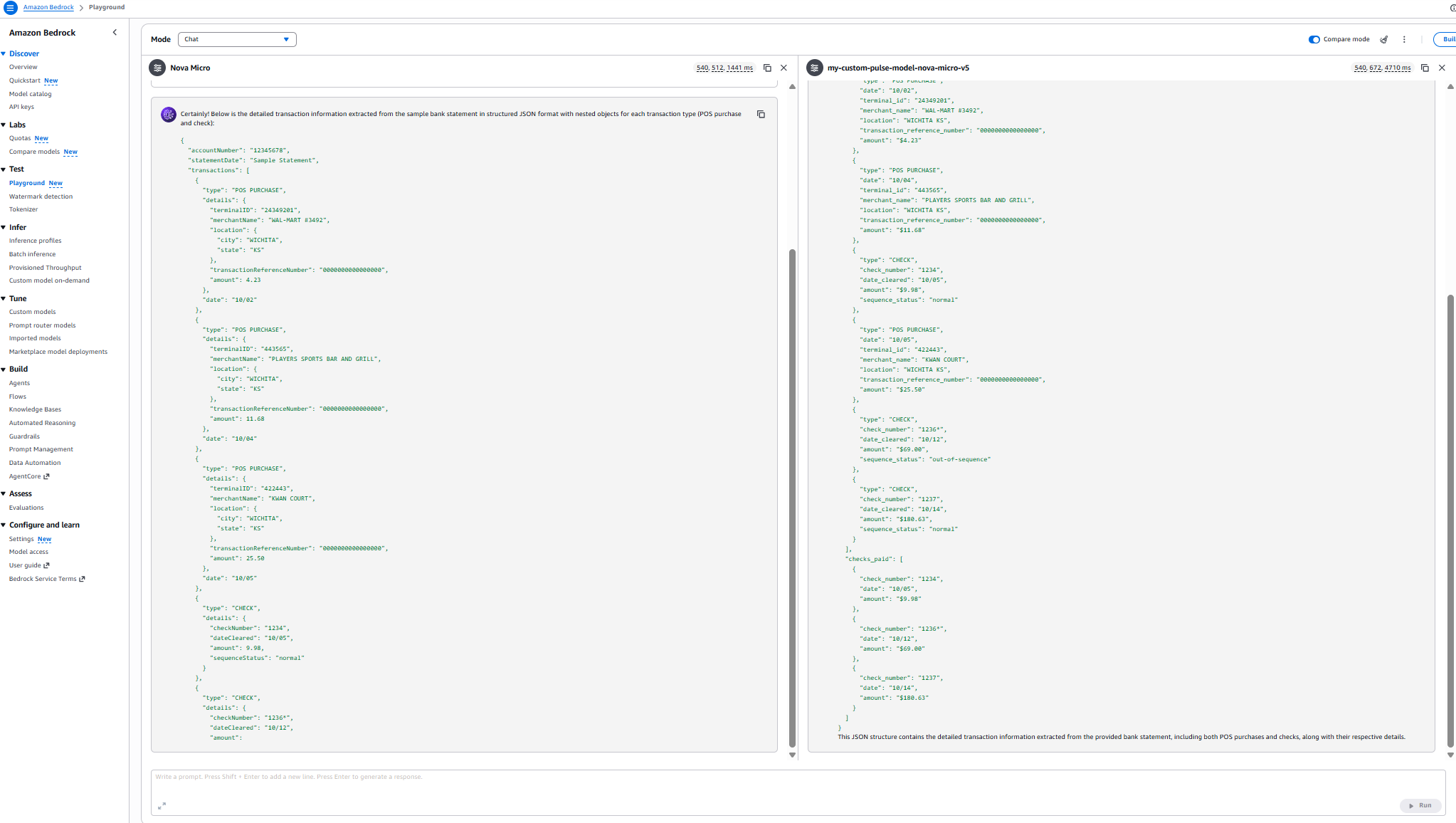
Сравнение производительности
Сравнение моделей: оценка доменных знаний
| Метрика | Nova Micro (Base) | my-custom-pulse-model-nova-micro-v5 |
| Задержка | 540,508 ms (~9 min) | 543,600 ms (~9 min 3.6 sec) |
| Извлечено чеков | 3 из 6 | 6 из 6 |
| Извлечено POS-покупок | 3 из 3 | 3 из 3 |
| Организация транзакций | Разделение по типам | Хронологический порядок |
| Полнота | 50% данных по чекам | 100% данных по чекам |
| Точность статуса последовательности | Частично (3 чека) | Полностью (все 6 чеков) |
| Структура JSON | Сегментированный формат | Единый список транзакций |
| Доменные знания | Базовое извлечение | Комплексное понимание документа |
Отказ от ответственности: эти метрики относятся только к набору примерных документов. Ваши результаты будут отличаться
Очистка ресурсов
Выполните следующие действия по очистке, чтобы избежать дополнительных расходов.
- Удалите instance profile:
aws iam delete-instance-profile --instance-profile-name BedrockTutorialProfile - Завершите инстанс EC2:
aws ec2 terminate-instances --instance-ids <instance-id> - Удалите security group:
aws ec2 delete-security-group --group-id <security-group-id> --region us-east-1 - Удалите key pair:
aws ec2 delete-key-pair --key-name <key-pair-name> --region us-east-1 - Удалите развертывание пользовательской модели:
aws bedrock delete-custom-model-deployment --custom-model-deployment-identifier <deployment-name> --region us-east-1 - Удалите пользовательскую модель:
aws bedrock delete-custom-model --model-identifier $CUSTOM_MODEL_ARN --region us-east-1
Предупреждение: риск потери данных — следующие команды окончательно удалят все обучающие данные и результаты.
Перед продолжением: 1) убедитесь, что в S3 bucket находятся только данные из руководства, 2) сохраните резервные копии файлов, которые нужно оставить, 3) проверьте, что правильно записали имя bucket.
- Удалите обучающие данные fine-tuning из S3:
aws s3 rm s3://<your-bucket>/training-data/ --recursive - Удалите результаты fine-tuning из S3:
aws s3 rm s3://<your-bucket>/output/ --recursive - Удалите S3 bucket, если он больше не нужен:
aws s3 rb s3://<your-bucket> - Удалите IAM policies:
aws iam delete-role-policy --role-name AmazonBedrock-FineTuning-S3-Role --policy-name Bedrock-S3-Access-Policy
- Удалите secret в Secrets Manager:
aws secretsmanager delete-secret --secret-id pulse-api-key --force-delete-without-recovery --region us-east-1 - Остановите job fine-tuning:
aws bedrock stop-model-customization-job --job-identifier <job-arn> --region us-east-1
Этот блог AWS дает подробные инструкции по итеративному fine-tuning, так что вы можете улучшать уже настроенные модели без начала с нуля. Pulse преобразует неструктурированные документы в структурированные, выровненные по схеме выходные данные. Эти результаты можно программно экспортировать в датасеты JSONL, совместимые с требованиями Amazon Bedrock к fine-tuning для текстовых и vision-моделей. Это фактически позволяет Pulse брать на себя основную сложность извлечения и контроля качества данных, одновременно упрощая создание обучающих наборов, необходимых для кастомизации моделей в Amazon Bedrock.
Заключение
Объединив продвинутое понимание документов от Pulse AI с ML-возможностями AWS, можно построить системы обработки финансовых данных, которые быстрее, точнее и масштабируемее традиционных подходов. Эта архитектура демонстрирует production-ready подход к обработке финансовых документов с использованием Amazon Bedrock и Pulse AI. Начать работу с Pulse AI несложно.
Настоящая сила fine-tuning раскрывается, когда foundation models (FMs) дополняются уникальными финансовыми данными вашей организации. Обучая модели на собственных документах, терминологии и бизнес-процессах, вы создаете специализированные возможности, с которыми generic models обычно не могут сравниться. Этот подход превращает AI из универсального инструмента в стратегический актив, понимающий нюансы именно вашей финансовой области.
Дополнительные ресурсы
Чтобы глубже разобраться в supervised fine-tuning и изучить продвинутые стратегии реализации, обратитесь к AWS Nova Fine-tuning Guide и документации по настройке Amazon Nova Models. Эти материалы содержат технические детали по улучшению hyperparameter, лучшим практикам подготовки данных и схемам развертывания. Pulse API Documentation дает подробные рекомендации по интеграции production-grade возможностей извлечения данных из документов в существующие workflow.
Материал — перевод статьи с английского.
Оригинал: Build financial document processing with Pulse AI and Amazon Bedrock