Agentic AI-аналитика на Amazon SageMaker с Amazon Athena и Amazon Quick для lakehouse на TPC-H

Современные компании сталкиваются с растущими сложностями при получении прикладных выводов из огромных data lake и lakehouse, которые содержат петабайты структурированных и неструктурированных данных. Традиционная аналитика требует специализированных навыков в SQL, моделировании данных и инструментах бизнес-аналитики, создавая узкие места, которые замедляют принятие решений в розничной торговле, финансовых услугах, здравоохранении, Travel & Hospitality, производстве и многих других отраслях. Эта архитектура показывает, как agentic AI-ассистент из Amazon Quick превращает аналитику данных в самообслуживаемую функцию. Она демонстрирует, как бизнес-пользователи могут запрашивать сложные структурированные наборы данных и объединять их с неструктурированными данными, чтобы находить ценные инсайты и улучшать бизнес-результаты через интуитивные интерфейсы на естественном языке.
Чтобы показать работу решения, мы построили lakehouse на базе наборов данных TPC-H. Эта интегрированная архитектура использует Amazon Simple Storage Service (Amazon S3) для хранения, Amazon SageMaker и AWS Glue для lakehouse, Amazon Athena для бессерверных SQL-запросов по нескольким форматам хранения (S3 Table, Iceberg и Parquet), а также несколько возможностей Quick для построения дашборда и conversational AI-агентов, которые дают естественно-языковой доступ к инсайтам из данных. За счет интегрированных knowledge bases через Amazon Quick spaces это решение демократизирует доступ к данным lakehouse для бизнес-пользователей, сохраняя корпоративную безопасность, фреймворки управления и масштабируемость, необходимые для принятия решений на основе данных в масштабах всей организации.
Обзор решения
Следующая диаграмма показывает общую архитектуру и соответствующий поток данных, реализованные в этом материале.

Рисунок 1: Диаграмма общей архитектуры. Ниже приведены шаги для подробного end-to-end потока данных и сценариев взаимодействия с пользователем.
- Ввод источника данных: структурированные данные TPC-H служат основным источником данных и содержат эталонные наборы в формате реляционной базы данных. AWS разместила данные TPC-H в общедоступном S3 bucket (s3://redshift-downloads/TPC-H/2.18/100GB).
- Загрузка данных: Amazon Athena выполняет первый уровень запросов, запускает бессерверные SQL-запросы к структурированным данным TPC-H, чтобы извлечь и подготовить данные для обработки, загрузить данные в S3 и создать соответствующий каталог в Glue.
- Многоформатный слой хранения: чтобы показать гибкость data lake и lakehouse, мы сохранили данные в трех оптимизированных форматах хранения:
- Amazon S3 -CSV: использование внешней таблицы для создания таблицы Athena на основе существующих CSV-файлов.
- Amazon S3 (Apache Iceberg-parquet): ACID-совместимый формат таблиц, поддерживающий time-travel и эволюцию схемы.
- Amazon S3 Table: Amazon S3 Tables предоставляет первый облачный object store со встроенной поддержкой Apache Iceberg и упрощает хранение табличных данных в масштабе.
- Каталогизация метаданных: AWS Glue Catalog индексирует все три формата хранения, создавая единый слой метаданных, который обеспечивает бесшовный запрос по разным форматам данных.
- Слой запросов lakehouse: мы использовали SQL-запросы Amazon Athena по всем форматам хранения (S3 Table, Iceberg и Parquet) с метаданными Glue Catalog, предоставляя единый интерфейс запросов.
- Пайплайн бизнес-аналитики: структурированные данные TPC-H поступают в Amazon Quick, который интегрируется с Quick Sight для создания:
- Набора данных — мы использовали подключение Amazon Athena из Amazon Quick для извлечения структурированных данных и загрузки их в набор данных Quick SPICE (Super-fast, Parallel, In-memory Calculation Engine).
- Topic — организованные домены данных для бизнес-контекста.
- Dashboard Using Q — интерактивные визуализации с возможностями запросов на естественном языке для построения и публикации дашборда.
- Расширение AI-знаний: параллельно потоку структурированных данных Web Crawler для спецификаций TPC-H загружает неструктурированные данные (документацию, спецификации) и передает их в Knowledge Bases, чтобы обеспечить контекстное понимание.
- Слой conversational agentic AI: Knowledge Bases питают Amazon Quick spaces (совместные среды), которые, в свою очередь, дают Amazon Quick chat agents контекстную осведомленность и предметные знания для взаимодействия на естественном языке.
- Доступ конечных пользователей: пользователи взаимодействуют с системой через два основных интерфейса:
- Dashboard Using Q — визуальная аналитика и self-service Business Intelligence.
- Chat Agent — conversational AI для исследования данных на естественном языке.
Требования перед началом
Перед тем как начать, убедитесь, что у вас есть следующие предварительные условия:
- AWS account и Amazon Quick account
- Базовое понимание Amazon Simple Storage Service, Amazon SageMaker, AWS Lake Formation и Amazon Athena
- Консольная роль с правами на создание набора данных в S3, запуск запросов Athena, создание Glue catalog, права администратора Lake Formation и доступ к функциям Quick. Чтобы выбрать соответствующую политику или политики, смотрите документ с политиками.
Подготовка данных для lakehouse / data lake
В этом разделе мы будем имитировать многие возможности data lake, работая с external tables, которые позволяют выполнять запросы к данным, хранящимся в Amazon S3, без загрузки в управляемый слой хранения. Мы рассмотрим таблицы Open Table Format (OTF) с Apache Iceberg, чтобы изучить таблицы с поддержкой ACID-транзакций. Управляемые Amazon S3 Tables будут использоваться, чтобы показать, как Amazon нативно поддерживает управление Iceberg-совместимыми таблицами прямо внутри S3, упрощая lakehouse-архитектуру в масштабе. Во всех этих упражнениях мы будем использовать отраслевой стандарт TPC-H dataset — эталонную нагрузку, представляющую реалистичную бизнес-модель данных с заказами, клиентами и позициями заказов, чтобы наши примеры были и содержательными, и воспроизводимыми.
Для подготовки данных мы будем использовать Amazon Athena. Если вы впервые работаете с Amazon Athena, вам нужно создать Amazon S3 bucket для хранения результатов запросов. Athena использует S3 в качестве места вывода до запуска запросов. Следуйте официальному руководству AWS по началу работы, чтобы выполнить эту одноразовую настройку: Getting Started with Amazon Athena. В качестве альтернативы можно использовать функцию Managed query results.
Совет: выбирайте S3 bucket в том же AWS Region, что и ваши источники данных, чтобы избежать затрат на межрегиональный перенос данных и задержек.
После настройки S3 output location можно продолжать.
Создание базы данных Glue
Начните с создания базы данных Glue, которая будет служить каталогом метаданных для всех таблиц, используемых через Athena. Выполните следующий SQL в редакторе запросов Athena:
CREATE DATABASE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql COMMENT 'TPC-H database';
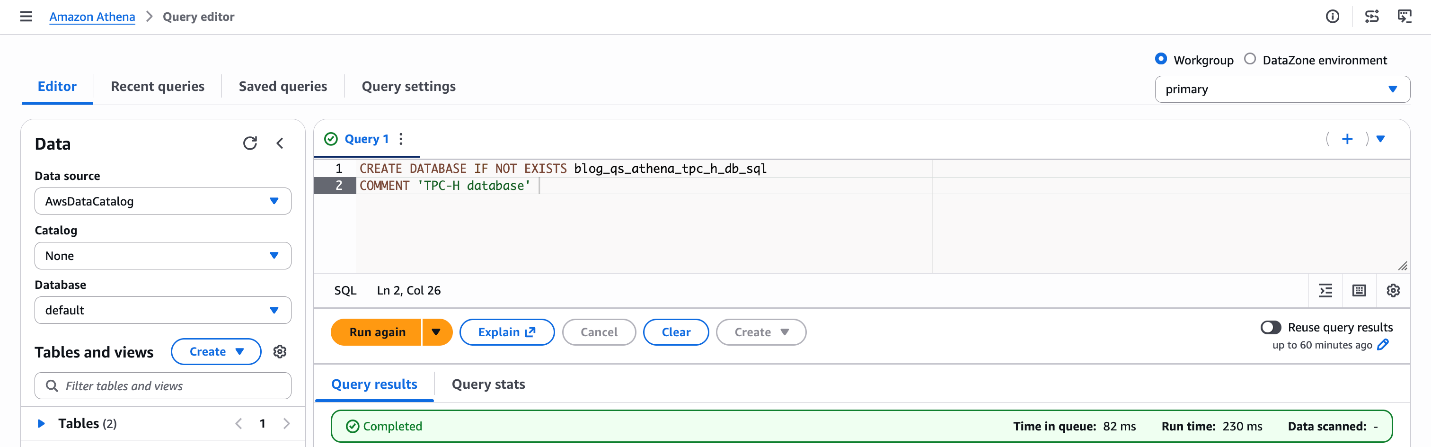
Рисунок 2: Создание базы данных blog_qs_athena_tpc_h_db_sql
Что это делает: это регистрирует логическую базу данных в AWS Glue Data Catalog, которую Athena использует для организации и поиска таблиц. Таблицы, созданные на следующих шагах, будут находиться в этой базе данных.
Создание внешней таблицы в S3
Далее создайте external table, указывающую на набор данных TPC-H “customer”, хранящийся в публичном S3 bucket ('s3://redshift-downloads/TPC-H/2.18/100GB/customer/'). Внешние таблицы в Athena не перемещают и не копируют данные — они запрашивают их напрямую из S3, что делает этот способ быстрым и экономичным для изучения сырых данных.
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.customer_csv
(
C_CUSTKEY INT,
C_NAME STRING,
C_ADDRESS STRING,
C_NATIONKEY INT,
C_PHONE STRING,
C_ACCTBAL DOUBLE,
C_MKTSEGMENT STRING,
C_COMMENT STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/customer/'
TBLPROPERTIES ('classification' = 'csv');
Проверьте таблицу, просмотрев несколько строк:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.customer_csv LIMIT 10;
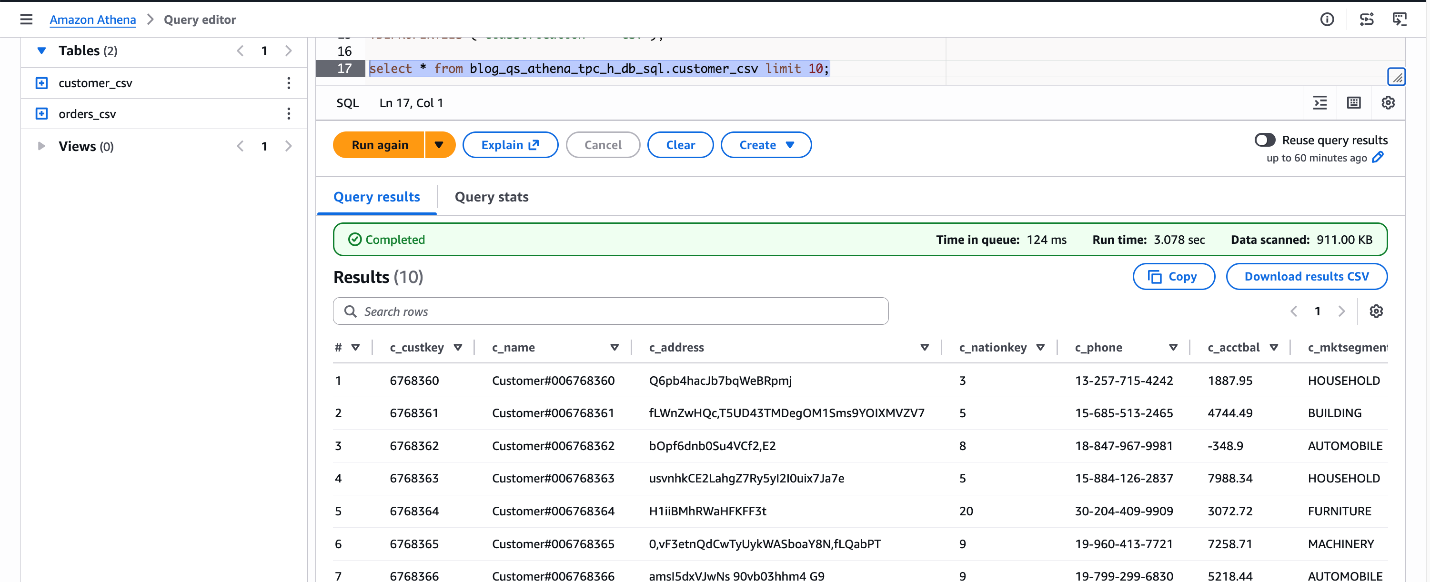
Рисунок 3: проверка blog_qs_athena_tpc_h_db_sql.customer_csv
Создание таблицы Apache Iceberg
Далее мы смоделируем таблицу с использованием Apache Iceberg — открытого формата таблиц, который добавляет ACID-транзакции, time travel и эволюцию разделов в ваш data lake, что делает его подходящим для production-нагрузок. Это трехшаговый процесс.
Шаг 1: создайте S3 bucket — перед тем как писать SQL-запросы, настройте слой хранения. Вы можете создать S3 bucket через AWS Management Console или AWS CLI.
Для этого материала я использую S3 bucket: amzn-s3-demo-bucket
Примечание: имя вашего bucket будет другим, поскольку имена S3 bucket должны быть глобально уникальными во всех AWS account.
Шаг 2: создайте внешнюю CSV-таблицу для заказов — сначала зарегистрируйте сырые данные о заказах как external table в их исходном формате, в нашем случае это CSV.
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.orders_csv
(
O_ORDERKEY BIGINT,
O_CUSTKEY BIGINT,
O_ORDERSTATUS STRING,
O_TOTALPRICE DOUBLE,
O_ORDERDATE STRING,
O_ORDERPRIORITY STRING,
O_CLERK STRING,
O_SHIPPRIORITY INT,
O_COMMENT STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = '|')
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/orders/'
TBLPROPERTIES ('classification' = 'csv');
Проверим набор данных.
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_csv LIMIT 10;
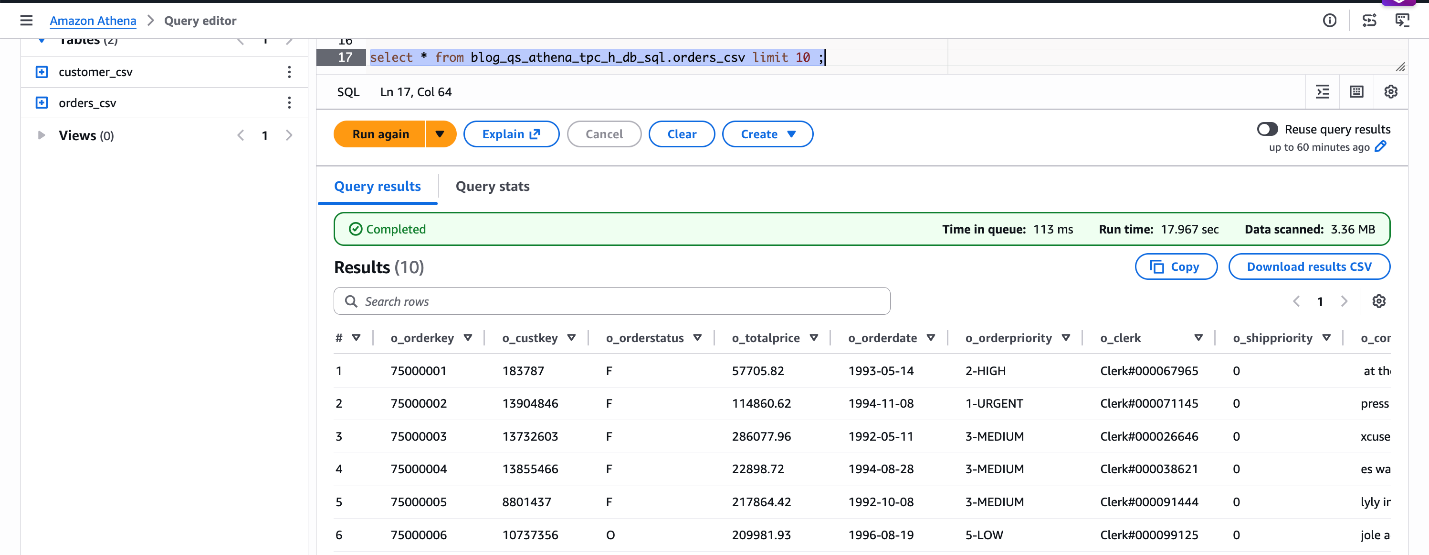
Рисунок 4: проверка blog_qs_athena_tpc_h_db_sql.orders_csv
Шаг 3: создайте таблицу Iceberg с помощью CREATE TABLE AS SELECT (CTAS) — используйте CREATE TABLE AS SELECT (CTAS), чтобы создать самоуправляемую таблицу Iceberg в формате Parquet, разделенную по дате заказа. Мы загрузим диапазон дат O_ORDERDATE BETWEEN ‘1998-06-01’ AND ‘1998-12-31’.
CREATE TABLE blog_qs_athena_tpc_h_db_sql.orders_iceberg
WITH (
table_type = 'ICEBERG',
format = 'PARQUET',
is_external = false,
partitioning = ARRAY['o_orderdate'],
location = 's3://amzn-s3-demo-bucket/tpch_iceberg/orders/')
AS
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_csv
WHERE O_ORDERDATE BETWEEN '1998-06-01' AND '1998-12-31';
Проверьте данные Iceberg-таблицы:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_iceberg LIMIT 10;
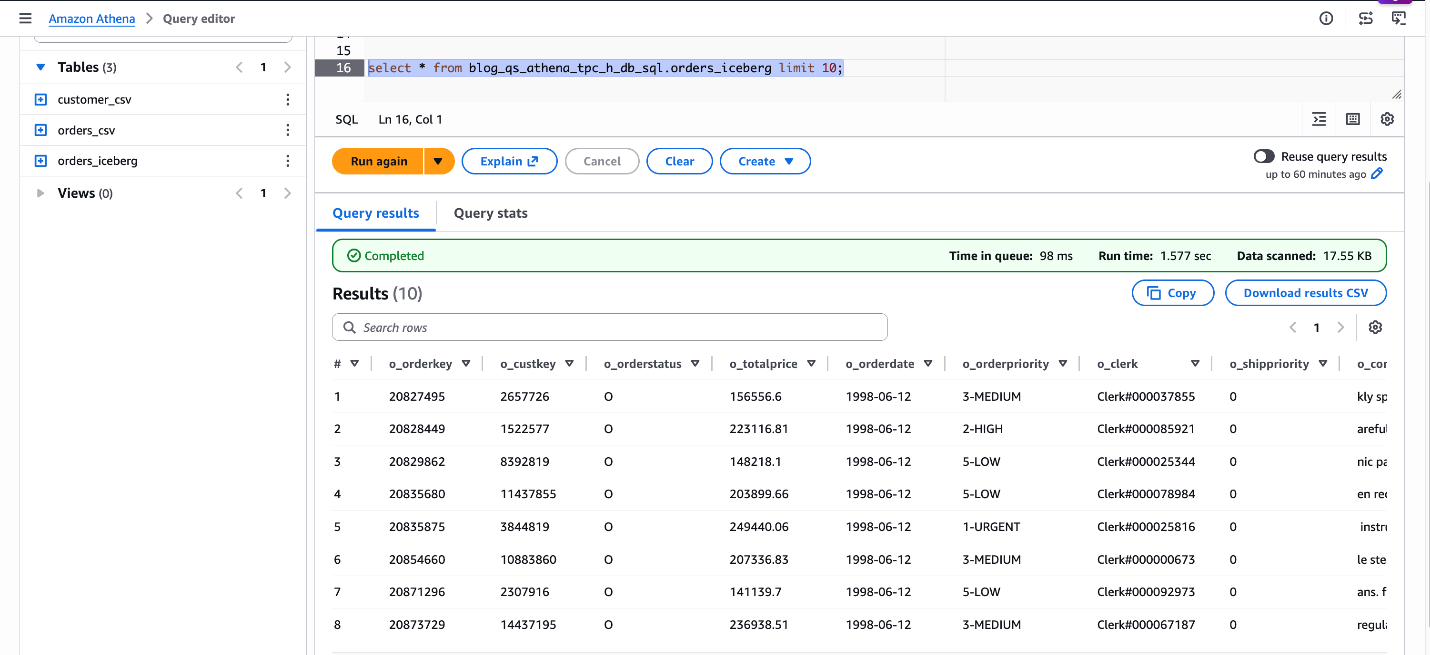
Рисунок 5: проверка blog_qs_athena_tpc_h_db_sql.orders_iceberg
Создание Amazon S3 Table
Amazon S3 Tables — это специально созданные, полностью управляемые таблицы со встроенной поддержкой Apache Iceberg. Они обеспечивают высокую производительность запросов без необходимости управлять такими операциями сопровождения, как compaction, управление snapshot и удаление неиспользуемых файлов. Это трехшаговый процесс.
Шаг 1: создайте S3 Table bucket и namespace — перейдите в S3 → Table Buckets в AWS Console, чтобы создать bucket blog-qs-athena-tpc-h-db-sql-s3-table-mar-3 и namespace. В качестве альтернативы можно использовать AWS CLI для автоматизированной настройки.
Примечание: эти шаги можно пропустить, если у вас уже есть S3 table bucket и namespace.
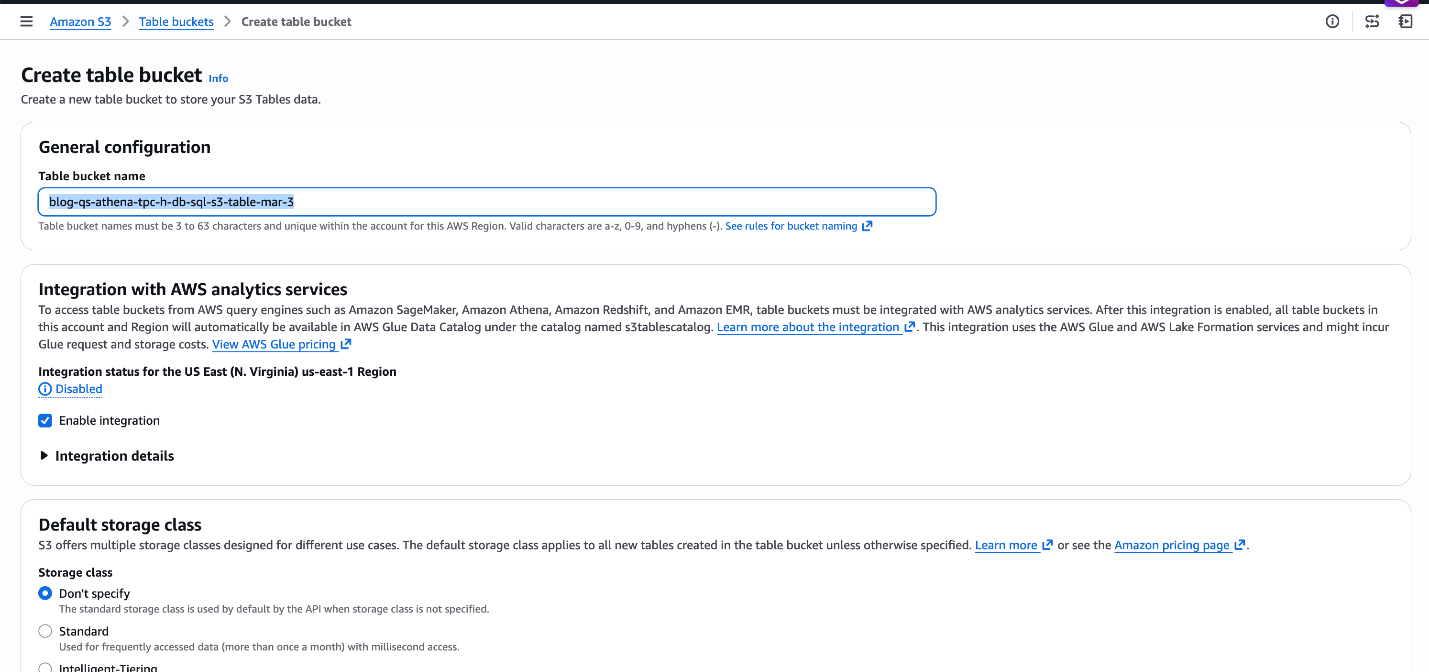
Рисунок 6: Создание S3 Table bucket blog-qs-athena-tpc-h-db-sql-s3-table-mar-3
Теперь создадим namespace blog_qs_athena_tpc_h_namespace , связанный с этим S3 table bucket, перейдя по blog-qs-athena-tpc-h-db-sql-s3-table-mar-3.
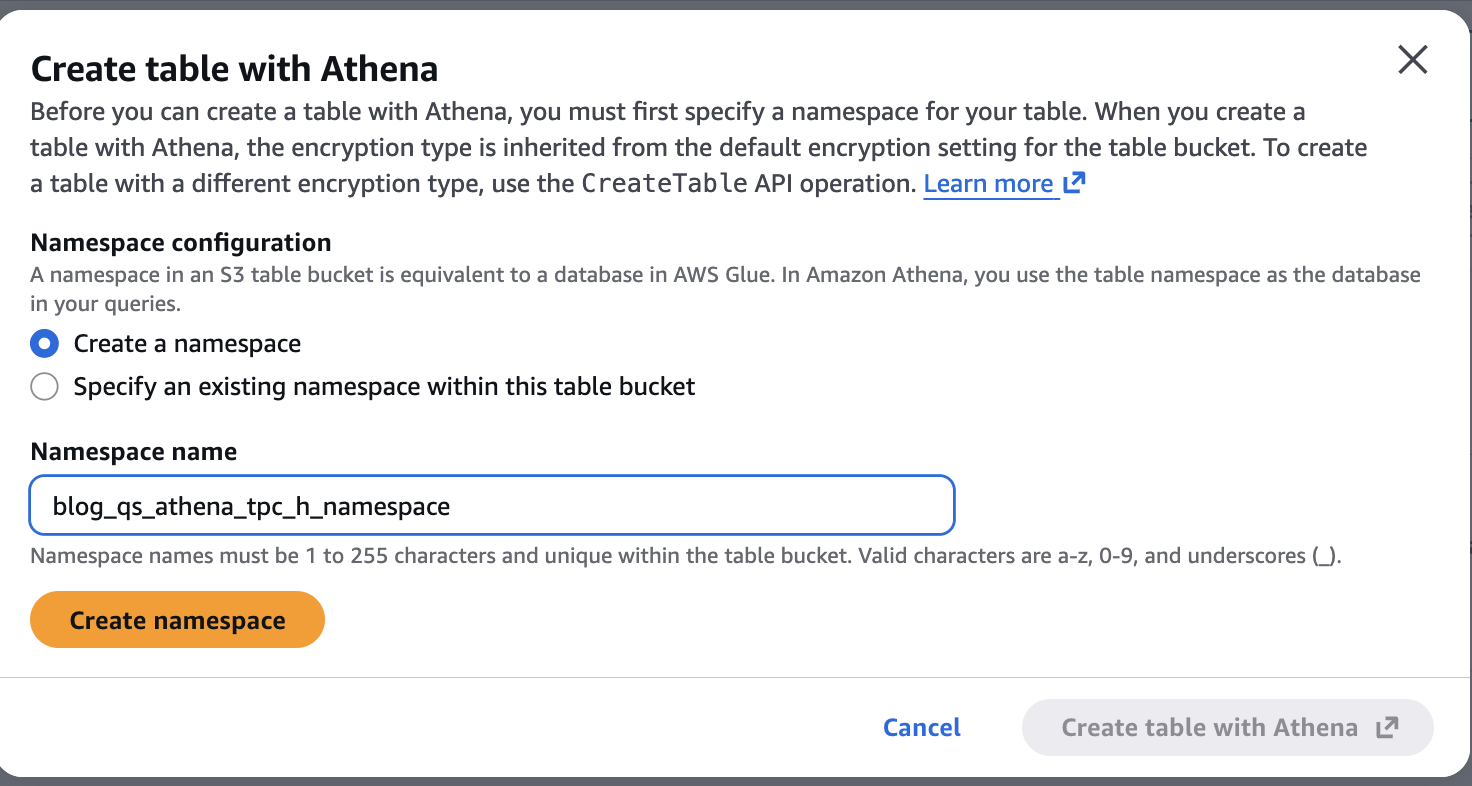
Рисунок 7: Создание namespace S3 table blog_qs_athena_tpc_h_namespace
Шаг 2: создайте внешнюю CSV-таблицу для line items — используйте Athena для регистрации набора данных TPC-H line items как external table:
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.lineitem_csv
(
L_ORDERKEY BIGINT,
L_PARTKEY BIGINT,
L_SUPPKEY BIGINT,
L_LINENUMBER INT,
L_QUANTITY DECIMAL(15,2),
L_EXTENDEDPRICE DECIMAL(15,2),
L_DISCOUNT DECIMAL(15,2),
L_TAX DECIMAL(15,2),
L_RETURNFLAG STRING,
L_LINESTATUS STRING,
L_SHIPDATE STRING,
L_COMMITDATE STRING,
L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING,
L_SHIPMODE STRING,
L_COMMENT STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/lineitem/'
TBLPROPERTIES ('skip.header.line.count' = '0');
Предпросмотрим данные:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.lineitem_csv LIMIT 10;
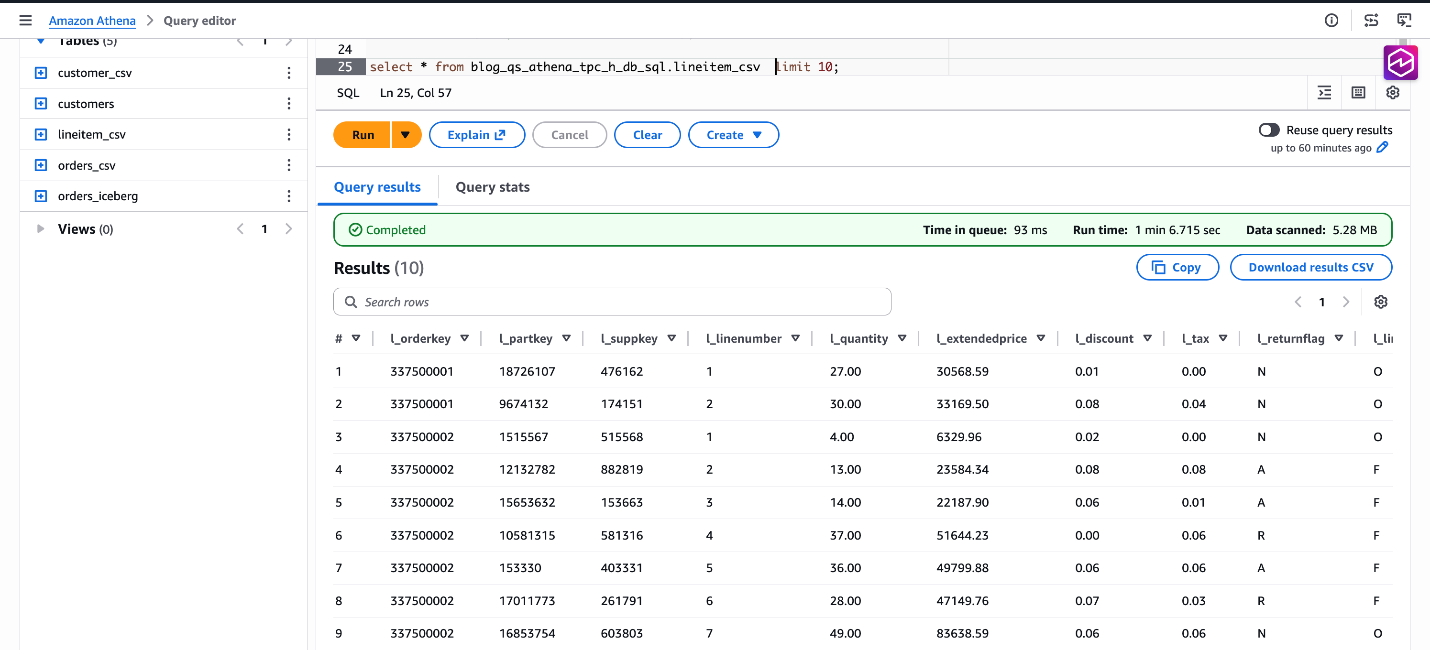
Рисунок 8: проверка данных blog_qs_athena_tpc_h_db_sql.lineitem_csv
Шаг 3: создайте S3 Tables table с помощью CTAS — наконец, создайте Parquet-форматированную S3 Tables в новом каталоге с использованием CTAS. Мы фильтруем диапазон дат, чтобы ограничить начальную загрузку, используя CAST(L_SHIPDATE AS DATE) BETWEEN DATE(‘1998-06-01’) AND DATE(‘1998-12-31’).
Примечание: убедитесь, что для выполнения следующих запросов используете s3tablescatalog, как показано на скриншоте ниже.
CREATE TABLE lineitem_csv_s3_table
WITH ( format = 'PARQUET')
AS
SELECT * FROM AwsDataCatalog.blog_qs_athena_tpc_h_db_sql.lineitem_csv
WHERE CAST(L_SHIPDATE AS DATE) BETWEEN DATE('1998-06-01') AND DATE('1998-12-31');
Проверьте результат:
SELECT * FROM lineitem_csv_s3_table LIMIT 10;
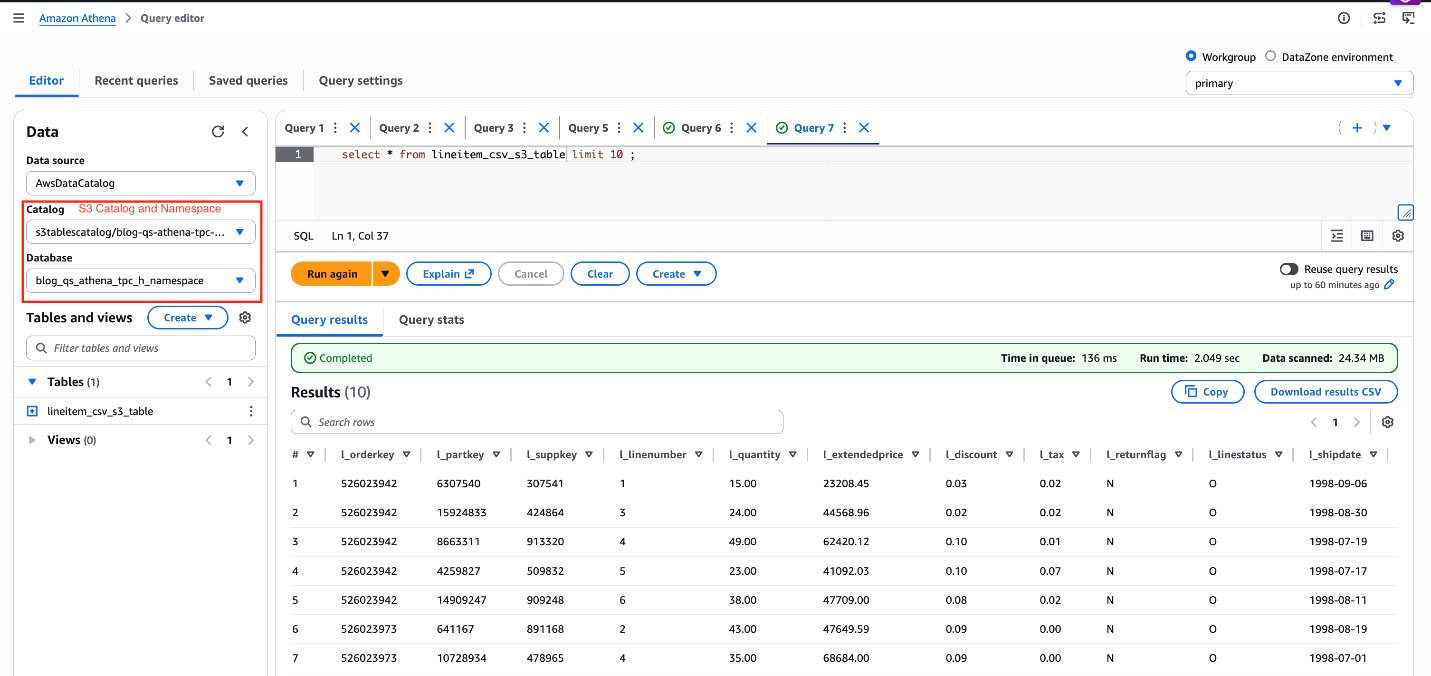
Рисунок 9: проверка данных lineitem_csv_s3_table
Подготовка набора данных в Amazon Quick
Ваши таблицы Athena зарегистрированы и доступны для запросов. Теперь пришло время перенести эти данные в Amazon Quick — подключить их, сформировать и заставить говорить на языке бизнеса. Этот раздел пошагово объясняет весь процесс: подключение к источнику Athena, создание наборов данных и их импорт в SPICE, объединение трех наборов SPICE, настройку Quick Topic для Q&A на естественном языке, создание и публикацию дашборда с Amazon Q и настройку Knowledge Base, которая питает agentic-слой.
Создание источника данных
Прежде чем Amazon Quick сможет запрашивать ваши три таблицы в data lake, нужно создать единое подключение к источнику Athena. Вы можете обращаться ко всем трем таблицам — внешней CSV-таблице, самоуправляемой Iceberg Parquet-таблице и управляемой S3 Tables Iceberg-таблице — через одно и то же подключение, потому что все они каталогизированы в AWS Glue Data Catalog и доступны через один и тот же Athena workgroup.
Шаги:
- В Amazon Quick перейдите в Datasets → Data sources → Create data source.
- Выберите Amazon Athena в качестве типа источника данных.
- Введите описательное имя, например
tpch-lakehouse-athena. - Выберите Athena workgroup, который ваша команда использует для production-запросов. Использование отдельного workgroup обеспечивает контроль затрат на запросы и отделяет трафик запросов Quick от других нагрузок.
- Нажмите Validate connection. Quick подтверждает, что может достичь Athena и Glue Data Catalog.
- Нажмите Create data source.
Создание наборов данных и загрузка в SPICE
После создания источника Athena создайте по одному набору Quick dataset для каждой таблицы. Импортируйте каждый набор данных в SPICE — Super-fast, Parallel, In-memory Calculation Engine Quick — чтобы обеспечить субсекундную производительность запросов в дашбордах и agentic workflow, независимо от того, насколько большим станет исходный объем данных в S3.
Права Lake Formation
Перед созданием наборов данных убедитесь, что заданы соответствующие права доступа к данным:
- Если Lake Formation не включен: права управляются на уровне service role Quick через стандартный IAM-based S3 access control. Убедитесь, что service role Quick (например,
aws-quicksight-service-role-v0) имеет IAM-права на чтение для нужных S3 bucket и ресурсов Athena. Дополнительная настройка Lake Formation не требуется. - Если Lake Formation включен: Lake Formation выступает как центральный слой авторизации, перекрывая стандартные IAM-based S3 permissions. Предоставьте права напрямую автору Amazon Quick или IAM role:
- Откройте AWS Lake Formation console.
- Выберите Permissions → Data permissions → Grant.
- Выберите пользователей и группы SAML.
- Введите Quick user ARN.
- Выберите Named Data Catalog resources.
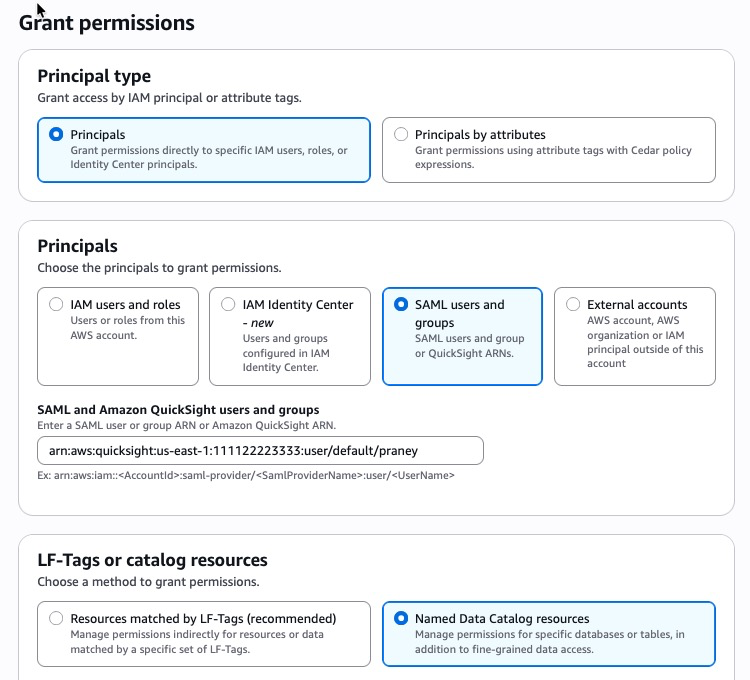
Рисунок 10: Права Lake Formation
-
- Выберите необходимые базы данных, таблицы и столбцы.
- Предоставьте как минимум SELECT; добавьте DESCRIBE для создания набора данных.
- Повторите для каждого пользователя или роли, которым нужен доступ.
Пошаговые инструкции см. в материалах Securely analyze your data with AWS Lake Formation and Amazon Quick Sight и Accessing Amazon S3 Tables through Amazon Quick with AWS Lake Formation Permissions.
Для S3 Tables отдельно сервисная роль Quick также требует дополнительную inline policy glue:GetCatalog для доступа к нестандартному каталогу s3tablescatalog — точную формулировку политики см. в Visualizing S3 table data with Amazon Quick.
Набор данных 1 — CSV external table (customer_csv)
- В источнике Athena выберите Create dataset.
- Выберите Glue database и таблицу, например
customer_csv. - Выберите Edit/Preview data, чтобы открыть среду подготовки данных.
- Проверьте типы данных столбцов и при необходимости внесите изменения. Примечание: если вы используете новую среду подготовки данных, откройте вкладку Preview, чтобы просмотреть данные перед продолжением.
- Установите Query mode в SPICE.
- Назовите набор данных
TPC-H Customer (CSV)и выберите Save & publish.
Набор данных 2 — самоуправляемый Iceberg Parquet (orders_iceberg)
- В том же источнике Athena выберите Create dataset.
- Выберите Glue database и таблицу, например
orders_iceberg. - Выберите Edit/Preview data, чтобы открыть среду подготовки данных.
- Проверьте типы данных столбцов и при необходимости внесите изменения. Примечание: если вы используете новую среду подготовки данных, откройте вкладку Preview, чтобы просмотреть данные перед продолжением.
- Установите Query mode в SPICE.
- Назовите набор данных
TPC-H Orders (Iceberg)и выберите Save & publish.
Набор данных 3 — управляемый Iceberg в S3 Tables (lineitem_csv_s3_table)
S3 Tables хранятся в нестандартном каталоге AWS Glue (s3tablescatalog), а не в стандартном AWSDataCatalog. Из-за этого визуальный браузер таблиц Quick не может отображать S3 Tables — они не появляются в панели “Choose your table”. Нужно использовать Custom SQL, чтобы запросить данные S3 Tables и создать из них набор данных Quick.
- В том же источнике Athena выберите Create dataset.
- Выберите Use custom SQL.
- Выберите Edit/Preview data, чтобы открыть среду подготовки данных.
- Введите SQL-запрос Athena, который ссылается на каталог S3 Tables с использованием синтаксиса
“s3tablescatalog/<table-bucket-name>”.”<namespace>”.”<table-name>”:
SELECT * FROM "s3tablescatalog/blog-qs-athena-tpc-h-db-sql-s3-table-mar-3"."blog_qs_athena_tpc_h_namespace"."lineitem_csv_s3_table"
- Выберите Apply. Quick выполнит запрос через Athena и покажет предварительный результат.
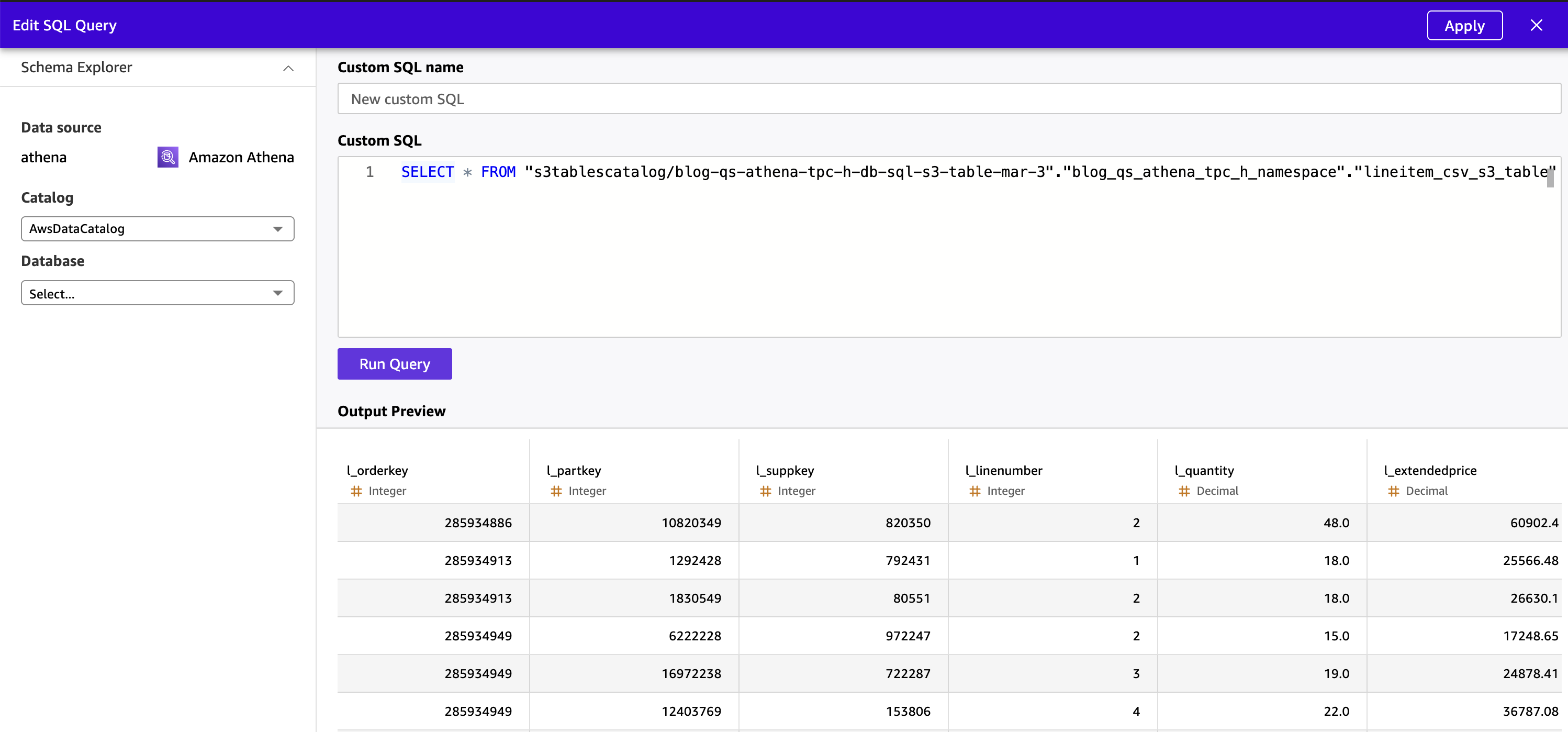
Рисунок 11: Предпросмотр данных S3 Table в Quick
- Проверьте типы данных столбцов и при необходимости внесите изменения.
- Установите Query mode в SPICE.
- Назовите набор данных
TPC-H Lineitem (S3 Tables)и выберите Save & publish.
Примечание: это требование Custom SQL относится именно к S3 Tables, поскольку они находятся в дочернем Glue catalog, зарегистрированном отдельно от стандартного AWSDataCatalog. Таблицы CSV и Iceberg в стандартном каталоге видны в браузере таблиц и не требуют Custom SQL.
Объединение наборов данных
Схема TPC-H по своей природе является star schema, а визуальная среда подготовки данных Amazon Quick поддерживает объединение наборов данных прямо в интерфейсе. В этом решении мы заранее объединяем все три таблицы в Athena с помощью Custom SQL и загружаем единый результат прямо в SPICE как один плоский набор данных. Это полностью снимает ограничение Quick на размер secondary table и переносит join в Athena, которая обрабатывает таблицы разного масштаба.
Примечание о лимите cross-source JOIN: если ваши вторичные таблицы (orders_iceberg + customer_csv) достаточно малы и вместе занимают менее 1 GB, вы можете выполнить join внутри визуальной среды подготовки данных Quick, открыв самую большую таблицу первой (сделав ее primary) и добавив меньшие таблицы как secondary joins. Для больших масштабов TPC-H, где доминирует таблица lineitem, ниже рекомендуется подход с предварительным объединением в Athena.
Шаги:
- В источнике Athena выберите Create dataset.
- Выберите Use custom SQL.
- Выберите Edit/Preview data, чтобы открыть среду подготовки данных.
- Введите следующий SQL-запрос Athena, который объединяет все три таблицы через стандартный Glue catalog (
blog_qs_athena_tpc_h_db_sql) и нестандартный catalog S3 Tables (s3tablescatalog):
SELECT
c.c_custkey,
c.c_name,
c.c_mktsegment,
c.c_nationkey,
o.o_orderkey,
o.o_orderdate,
o.o_orderstatus,
o.o_totalprice,
o.o_orderpriority,
l.l_linenumber,
l.l_partkey,
l.l_suppkey,
l.l_quantity,
l.l_extendedprice,
l.l_discount,
l.l_shipmode,
l.l_returnflag
FROM "s3tablescatalog/blog-qs-athena-tpc-h-db-sql-s3-table-mar-3"."blog_qs_athena_tpc_h_namespace"."lineitem_csv_s3_table" l
INNER JOIN "blog_qs_athena_tpc_h_db_sql"."orders_iceberg" o
ON l.l_orderkey = o.o_orderkey
INNER JOIN "blog_qs_athena_tpc_h_db_sql"."customer_csv" c
ON o.o_custkey = c.c_custkey;
Запрос объединяет три таблицы, используя внешние ключи TPC-H:
lineitem_csv_s3_table.l_orderkey = orders_iceberg.o_orderkey(Lineitem → Orders)orders_iceberg.o_custkey = customer_csv.c_custkey(Orders → Customer)
Совет: используйте явные двойные кавычки и для базы данных, и для имен таблиц в SQL Athena — это помогает избежать ошибок парсинга, вызванных дефисами или другими специальными символами в именах идентификаторов, особенно для путей каталога S3 Tables.
- Нажмите Apply. Quick выполнит запрос через Athena и покажет объединенный результат.
- Проверьте типы данных столбцов и при необходимости внесите изменения. Скрывайте внутренние key columns (
c_custkey,o_custkey,o_orderkey,l_orderkey), которые бизнес-пользователям не нужно видеть в дашбордах или Q&A.
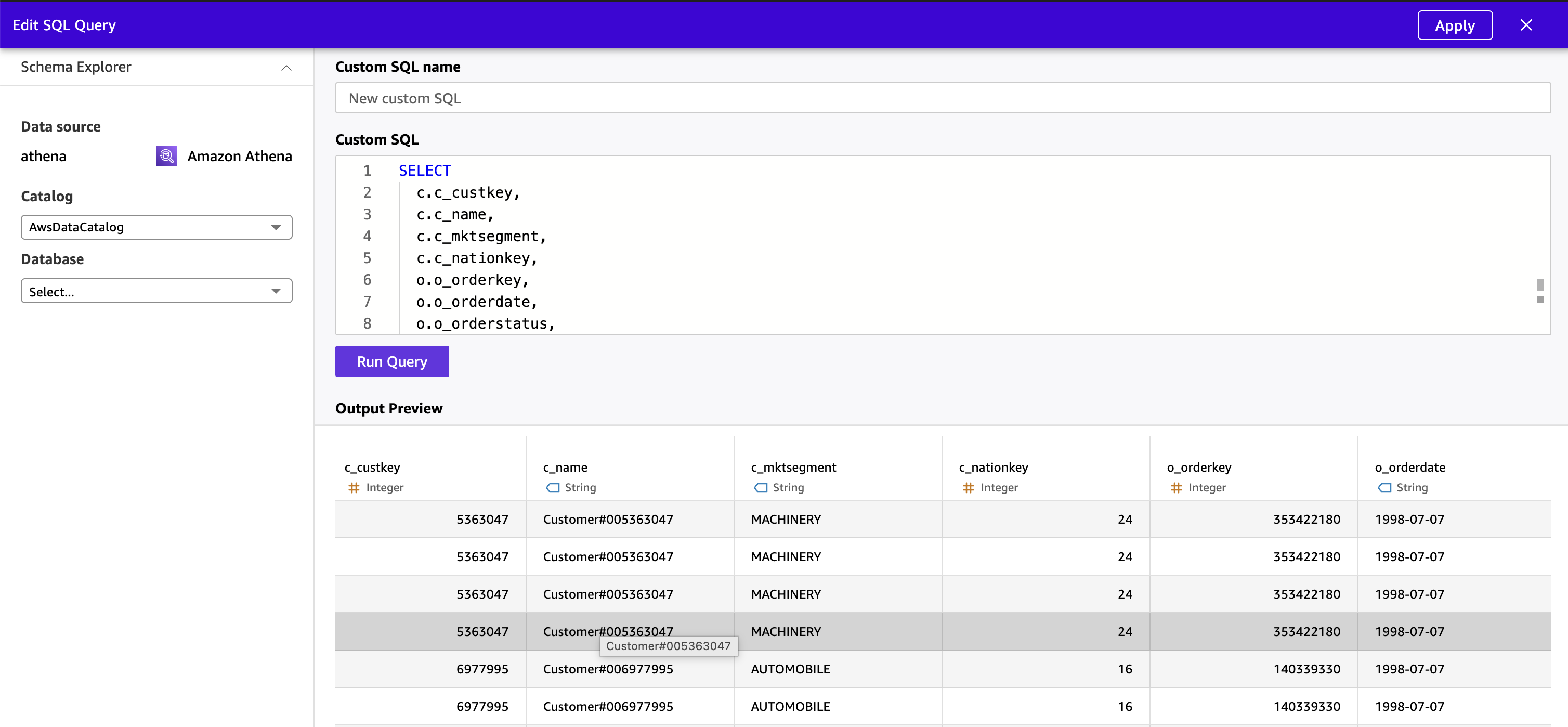
Рисунок 12: Предпросмотр денормализованных данных в Quick
- Установите Query mode в SPICE.
- Назовите набор данных
TPC-H Unified (Joined)и выберите Save & publish, затем дождитесь изменения статуса SPICE dataset на “Ready” (ожидаемое время 2–3 минуты).
Объединенный набор данных теперь представляет собой один денормализованный SPICE dataset, который объединяет customer, order и line item data во всех трех форматах таблиц — CSV external, self-managed Iceberg Parquet и управляемый S3 Tables Iceberg — и готов как для построения дашбордов, так и для Q&A на естественном языке.
Настройка Topic в Quick
Quick Topic — это семантический слой, который переводит имена столбцов в бизнес-понятия. Когда пользователь спрашивает: “Какой был общий доход в прошлом квартале по сегментам клиентов?”, Topic сопоставляет revenue с l_extendedprice, “last quarter” с фильтром по дате на o_orderdate, а “customer segment” с c_mktsegment. Без правильно настроенного Topic естественно-языковые запросы дают общие или неверные результаты. С ним они возвращают точные, подтвержденные ответы за секунды.
Шаги:
- Введите имя
TPC-H Analyticsи описание простым языком: “Customer, order, and line item data from the TPC-H benchmark dataset, covering revenue, pricing, discounts, order status, and customer market segments.” - Выберите набор данных
TPC-H Unified (Joined)в качестве источника данных. - Quick проанализирует набор данных и автоматически сгенерирует конфигурации полей (ожидаемое время выполнения 8–10 минут). Проверьте каждое поле на вкладке Data:
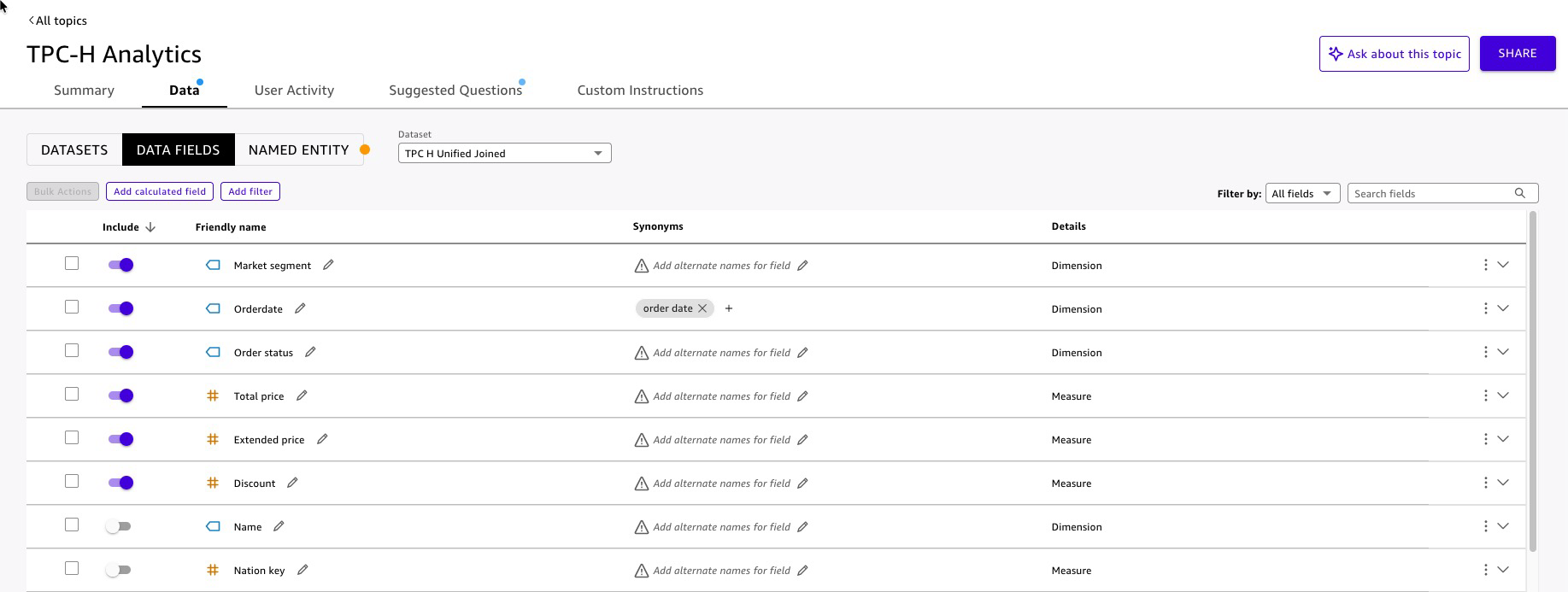
Рисунок 13: Улучшение Quick Topic
- Добавьте named entities для распространенных бизнес-группировок.
- Добавьте suggested questions, чтобы помочь новым пользователям:
- “What is total revenue by order status this year?”
- “Which customer segments placed the most orders last quarter?”
- “Show me the top 10 orders by total price last month.”
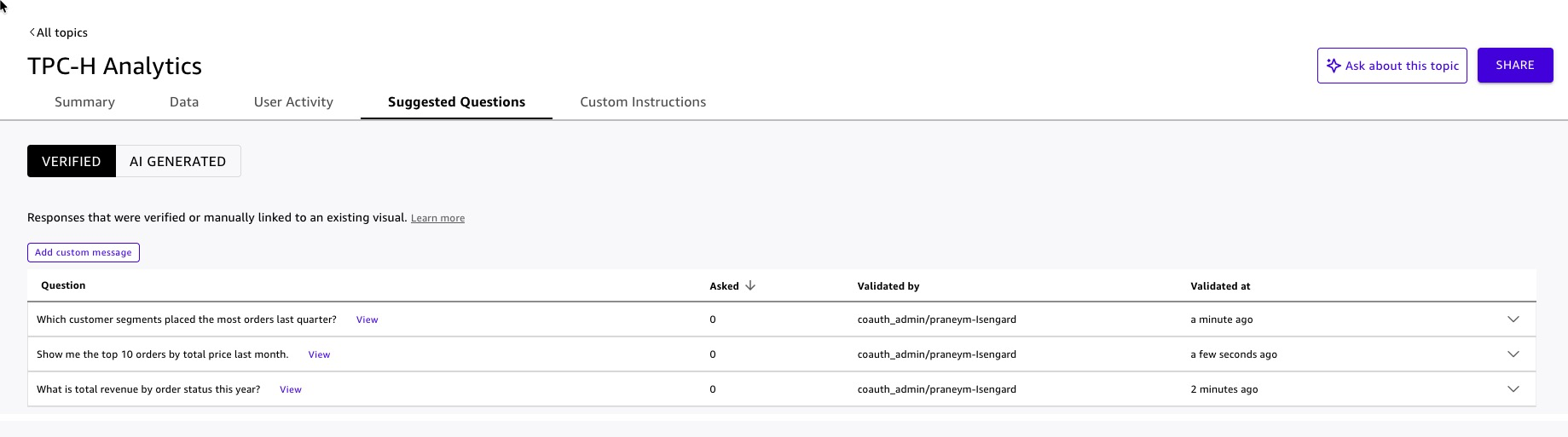
Рисунок 14: Suggested questions для Quick Topic
Создание и публикация дашборда с Amazon Q
Amazon Q в Quick позволяет авторам строить дашборды на естественном языке — опишите нужную визуализацию, и Q создаст ее. Это ускоряет разработку дашбордов с дней до минут и позволяет сосредоточиться на бизнес-истории, а не на настройке графиков.
Шаги:
- В Amazon Quick перейдите в Analyses → Create analysis.
- Выберите набор данных
TPC-H Unified (Joined). - Откройте панель Amazon Q.
- Используйте запросы на естественном языке, чтобы построить каждую визуализацию, и нажимайте Add to Analysis:
- “Show a KPI card for total revenue.”
- “Add a bar chart showing extended revenue by order status.”
- “Create a scatter plot of discount rate versus extended revenue by customer segment.”
- Для каждой созданной визуализации проверьте сопоставление полей и настройте заголовки, подписи осей и цветовое кодирование в соответствии со style guide вашей организации.
- Добавьте элемент фильтра для
o_orderdate, чтобы зрители дашборда могли ограничивать данные нужным временным диапазоном без запроса нового отчета. - Нажмите Manage Q&A, чтобы выбрать радиокнопку и выбрать topic
TPC-H Analyticsдля включения Dashboard Q&A. Это встраивает строку запросов на естественном языке прямо в опубликованный дашборд, позволяя пользователям задавать дополнительные вопросы, не покидая дашборд. Quick автоматически извлекает семантическую информацию из визуализаций дашборда для работы функции Q&A. - Выберите Publish, задайте имя
TPC-H Lakehouse Analytics. - При желании Quick позволяет поделиться дашбордом.
Рисунок 15: Поделиться дашбордом
Интеграция agentic AI с Amazon Quick
Ваши SPICE datasets загружены, Topic опубликован, а дашборд уже работает. Каждое из этих звеньев ценно само по себе. Вместе, объединенные внутри Quick Space, представленные через custom Chat Agent и индексированную Knowledge Base, они становятся качественно иной системой: agentic AI, которая отвечает на вопросы, извлекает контекст и помогает принимать действия — все из одного conversational интерфейса.
Настройка Knowledge Base
Knowledge Base дает Chat Agent доступ к неструктурированному контексту, который невозможно получить только из структурированных данных: словари данных, документацию по схемам, бизнес-правила и справочные материалы предметной области. Для этого решения Knowledge Base строится из TPC-H unstructured data: официального документа со спецификацией TPC-H, описывающего, как ваша организация сопоставляет поля TPC-H с бизнес-понятиями.
Шаги:
- В Amazon Quick перейдите в Integrations → Knowledge bases → Webcrawler.
- Добавьте URL содержимого документа TPC-H specification (PDF): https://www.tpc.org/tpc_documents_current_versions/pdf/tpc-h_v2.17.1.pdf.
- Назовите knowledge base
TPC-H Reference Knowledge Base. - Нажмите Create.
Quick индексирует документ и делает его доступным для поиска Chat Agent во время запроса. Агент извлекает релевантные фрагменты, а не весь документ целиком, поэтому ответы остаются точными и лаконичными.
Лучшая практика: держите каждый документ сфокусированным на одной теме. 5-страничный словарь данных полезнее агенту, чем 200-страничная объединенная спецификация, потому что агент извлекает по релевантности — более короткие и сфокусированные документы дают более точные извлечения.
Создание Space
Шаги:
- В Amazon Quick перейдите в Spaces → Create space.
- Назовите space
TPC-H Lakehouse Analytics Space. - Добавьте ресурсы в space:
Добавьте Topic:
- Выберите
TPC-H Analytics— Topic, настроенный в разделе Quick Topic Configuration. - Теперь агент может отвечать на вопросы по структурированным данным — revenue, orders, customer segments — запрашивая Topic через Space.
Добавьте Knowledge Base:
- Выберите Add knowledge → Knowledge bases.
- Выберите
TPC-H Reference Knowledge Base— knowledge base, настроенную в разделе Knowledge Base Configuration. - Теперь агент может извлекать неструктурированный контекст из документа со спецификацией TPC-H — включая бизнес-цель всех 22 эталонных запросов, определения запросов и концептуальную модель данных. Когда пользователь спрашивает “What is TPC-H Query 3 designed to measure?” или “What does the TPC-H specification say about order priority?”, агент извлекает соответствующий фрагмент из спецификации и цитирует его в ответе.
Добавьте Dashboard:
- Выберите Add knowledge → Dashboards.
- Выберите
TPC-H Lakehouse Analytics— дашборд, настроенный в разделе Dashboard Build and Publish with Amazon Q. - Агент может ссылаться на визуализации дашборда и направлять пользователей к конкретным представлениям при ответах на вопросы.
Теперь Space включает все, что нужно Chat Agent: структурированные данные через Topic, неструктурированный контекст через Knowledge Base и визуальные ссылки через Dashboard. Агент запрашивает Space; Space обеспечивает границы. Quick применяет те же правила безопасности к данным внутри Space — пользователи видят только те данные, которые разрешены их роли, независимо от того, как они формулируют вопрос.
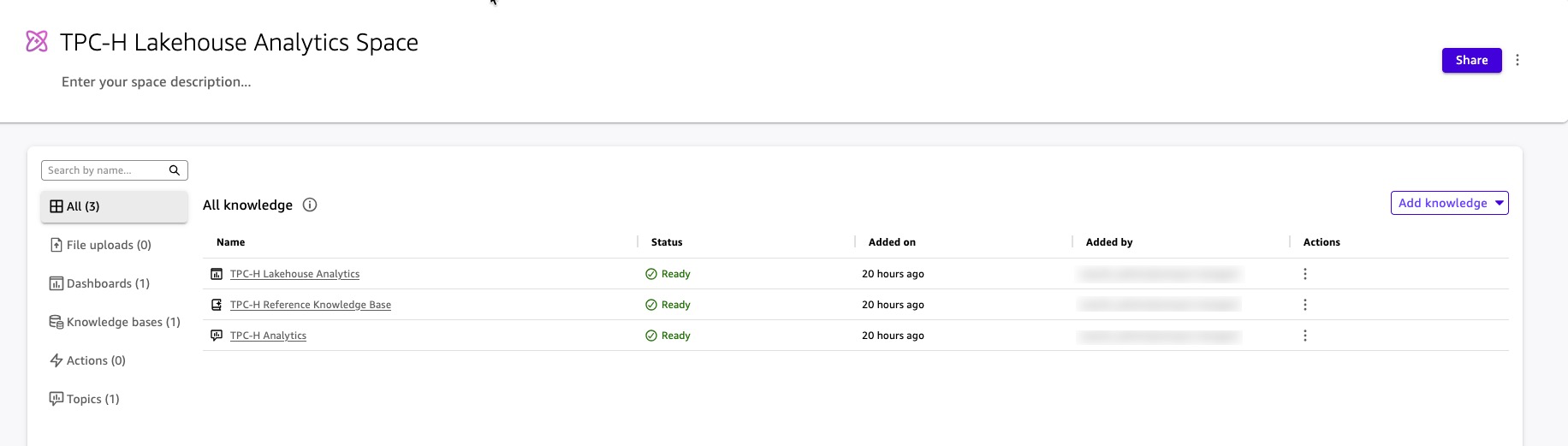
Рисунок 16: Артефакты в Space
Создание custom Chat Agent
Chat Agent — это интерфейс, с которым взаимодействуют ваши бизнес-пользователи. Это не общий ассистент — это специально созданный, управляемый AI-напарник, ограниченный пространством TPC-H Lakehouse Analytics Space. Пользователи задают вопросы на обычном английском. Агент рассуждает в пределах Space, извлекает правильную комбинацию структурированных данных и неструктурированного контекста и возвращает основанные на данных, цитируемые ответы.
Шаги:
- В Amazon Quick перейдите в Chat agents → Create chat agent.
- Напишите persona instructions простым языком:
“You are the TPC-H Analytics Agent for [Your Organization]. You help business analysts and data engineers answer questions about order revenue, supplier performance, line item pricing, and inventory availability using the TPC-H lakehouse dataset. Always ground your answers in data from the TPC-H Lakehouse Analytics Space. When a user asks a question that requires a chart or table, retrieve the answer from the Topic and present it clearly. When a user asks about schema definitions, query logic, or data dictionary terms, retrieve the answer from the Knowledge Base. Do not speculate. If you cannot find a grounded answer, say so and suggest a follow-up question.”
- Введите имя:
TPC-H Analytics Agent. - Подключите Space: Quick может определить и подключить
TPC-H Lakehouse Analytics Space. При желании вы можете добавить space по следующим шагам.- В разделе Knowledge sources выберите Link spaces.
- Выберите
TPC-H Lakehouse Analytics Space. - Теперь агент имеет доступ к Topic, Knowledge Base и Dashboard через Space — прямые подключения к наборам данных не нужны.
- Настройте параметры персонализации:
- Welcome message: добавьте приветствие, которое будет отображаться при первом открытии chat agent (например, “Hello! I’m your TPC-H Analytics Agent. Ask me about order revenue, customer segments, or line item pricing.”).
- Suggested prompts: добавьте 3–5 стартовых вопросов, чтобы показать пользователям, на что агент может отвечать (например, “What was total revenue last quarter?”, “Show me top customers by order volume”, “Explain the Shipping Priority Query”).
- Эти настройки помогают пользователям сразу понять возможности агента и снижают порог входа для первых взаимодействий.
- Предварительно просмотрите и протестируйте агента с помощью встроенной панели preview справа на странице настройки перед публикацией. Проверяйте вопросы, охватывающие оба источника данных:
- “What was total revenue for fulfilled orders last quarter?” — извлекается из Topic и Dashboard (структурированные данные).
- “What does the l_shipmode field represent?” — извлекается из Knowledge Base (TPC-H specification).
- “Show me the top 5 customer segments by order volume.” — извлекается из Topic и возвращает ранжированный результат.
- “What business question does the Shipping Priority Query answer?” — извлекается из Section 2.4.3 спецификации TPC-H в Knowledge Base.
- Выберите Launch chat agent, чтобы сохранить и опубликовать изменения.
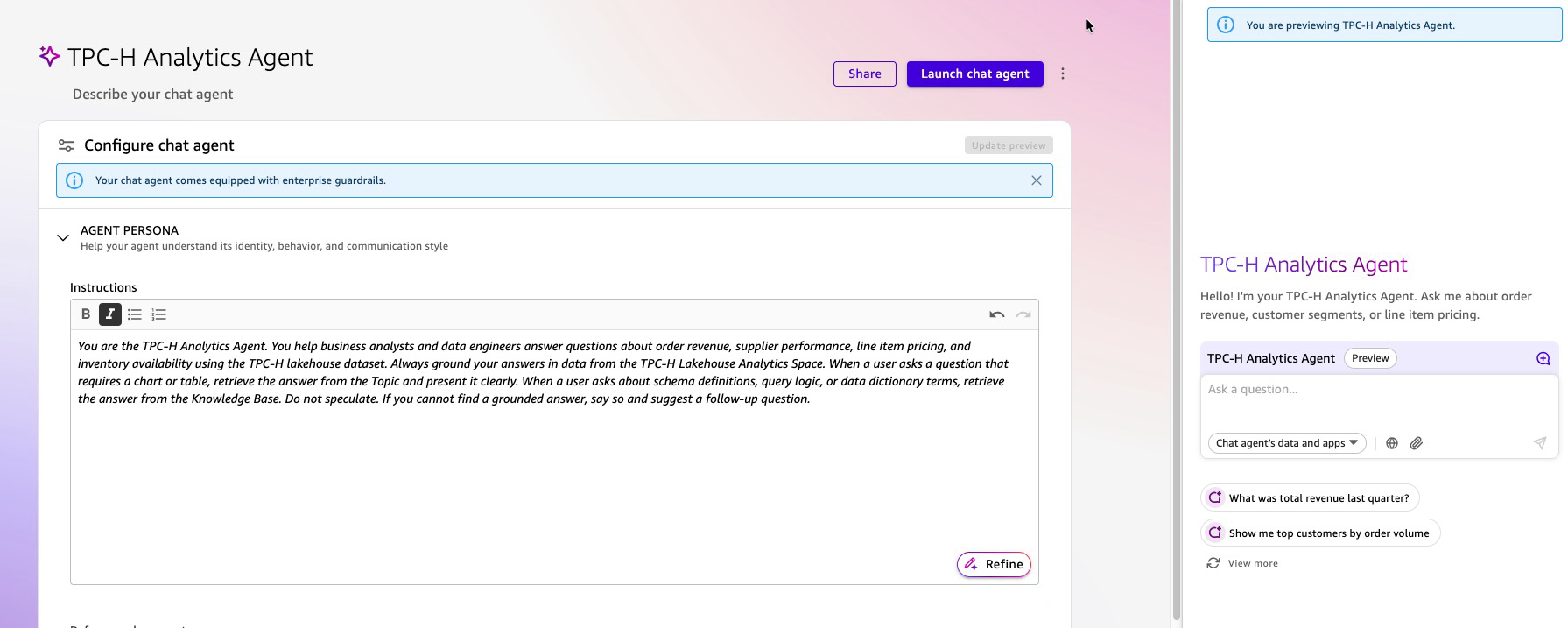
Рисунок 17: Взаимодействие с агентом
Что видят пользователи
Бизнес-аналитик открывает TPC-H Analytics Agent и вводит:
“Which customer segment drove the most revenue last month, and what does ‘market segment’ mean in the TPC-H schema?”
Агент:
- Запрашивает Topic
TPC-H Analyticsчерез Space по revenue в разрезеc_mktsegmentс фильтром по прошлому месяцу — возвращает ранжированный результат из SPICE. - Одновременно извлекает определение
c_mktsegmentиз TPC-H data dictionary в Knowledge Base. - Возвращает один единый ответ: ранжированный результат по revenue с цитатой на SPICE dataset, а затем определение схемы с цитатой на документ спецификации.
Никакого SQL. Никакой навигации по дашбордам. Никакого тикета в data team. Ответ приходит одним сообщением, основанным на двух источниках, и каждое утверждение можно отследить до исходного источника.
Очистка
Выполните следующие шаги, чтобы удалить артефакты, созданные этим материалом
Артефакты lakehouse / data lake
Выполните следующие шаги через Athena console
Удаление таблиц
DROP TABLE blog_qs_athena_tpc_h_db_sql.customer_csv;
DROP TABLE blog_qs_athena_tpc_h_db_sql.orders_csv;
DROP TABLE blog_qs_athena_tpc_h_db_sql.orders_iceberg;
DROP TABLE blog_qs_athena_tpc_h_db_sql.lineitem_csv;
DROP TABLE lineitem_csv_s3_table; --(use S3 catalog configuration)
Удаление баз данных
DROP DATABASE blog_qs_athena_tpc_h_db_sql;
Удаление S3 Table bucket
- Чтобы удалить таблицу
lineitem_csv_s3_table, используйте AWS CLI, AWS SDKs или Amazon S3 REST API. Подробнее - Чтобы удалить namespace
blog_qs_athena_tpc_h_namespace, используйте AWS CLI, AWS SDKs или Amazon S3 REST API. Подробнее - Чтобы удалить table bucket
blog-qs-athena-tpc-h-db-sql-s3-table-mar-3, используйте AWS CLI, AWS SDKs или Amazon S3 REST API. Подробнее
Удаление S3 bucket
Используйте S3 console, чтобы удалить S3 bucket amzn-s3-demo-bucket.
Артефакты Quick
Удаление custom Chat Agent
- В Amazon Quick перейдите в Agents.
- Выберите
TPC-H Analytics Agentи нажмите Delete. - Подтвердите удаление.
Удаление Space
- Перейдите в Spaces.
- Выберите
TPC-H Lakehouse Analytics Spaceи нажмите Delete.
Удаление дашборда
- Перейдите в Dashboards.
- Выберите
TPC-H Lakehouse Analyticsи нажмите Delete. - Подтвердите удаление.
Удаление Topic
- Выберите
TPC-H Analyticsи нажмите Delete. - Подтвердите удаление.
Удаление Knowledge Base
- Перейдите в Integrations → Knowledge bases.
- Выберите
TPC-H Reference Knowledge Baseи нажмите Delete knowledge base. - Подтвердите удаление. Это удалит Knowledge Base и проиндексированные документы.
Удаление наборов данных
- Перейдите в Datasets.
- Выберите каждый из следующих наборов данных и нажмите Delete:
TPC-H Unified (Joined)TPC-H Customer (CSV)TPC-H Orders (Iceberg)TPC-H Lineitem (S3 Tables)
- Подтвердите каждое удаление. Это удалит SPICE data и освободит связанную емкость SPICE.
Удаление источника данных
- Перейдите в Datasets → Data sources.
- Выберите
tpch-lakehouse-athenaи нажмите Delete. - Подтвердите удаление.
Заключение
Эта архитектура показывает, как agentic AI Amazon Quick превращает корпоративную аналитику данных из технического узкого места в доступную самообслуживаемую функцию. Интегрируя Amazon S3, AWS Glue Data Catalog, Amazon Athena и Amazon Lake Formation с conversational AI-агентами и дашбордами Amazon Quick, бизнес-пользователи теперь могут запрашивать сложные данные lakehouse через интерфейсы на естественном языке без необходимости знать SQL или BI-инструменты. Решение бесшовно объединяет структурированные наборы данных TPC-H в нескольких форматах хранения (S3 Table, Iceberg, Parquet) с неструктурированными данными из knowledge bases, обеспечивая более богатые контекстные инсайты. Такая демократизация доступа к данным ускоряет принятие решений в разных отраслях, сохраняя корпоративную безопасность, управление и масштабируемость для современных data-driven организаций.
Следующие шаги
Обратитесь к Getting started tutorial для дополнительных сценариев использования B2B, revenue, sales, marketing и HR datasets. Чтобы глубже изучить права Lake Formation в Quick, см. документацию AWS “Using AWS Lake Formation with Quick“ и блог “Securely analyze your data with AWS Lake Formation and Amazon Quick Sight”. Присоединяйтесь к Amazon Quick Community, чтобы находить ответы на вопросы, учебные материалы и мероприятия в вашем регионе.
Дополнительно см. следующие материалы:
Modernize Business Intelligence Workloads Using Amazon Quick
Best practices for Amazon Quick Sight SPICE and direct query mode
Accessing Amazon S3 Tables through Amazon Quick with AWS Lake Formation Permissions AWS security in Quick.
Материал — перевод статьи с английского.
Оригинал: Unleashing Agentic AI Analytics on Amazon SageMaker with Amazon Athena and Amazon Quick