ИИ-агенты не ломаются: ломается слой координации и событийная шина

by Сринниваса Редди Хулебиду Редди
Автор
ИИ-агенты не терпят неудачу. Сбой происходит на уровне координации
мнение
10 апр. 2026 8 мин
Когда несколько ИИ-агентов соревнуются вместо того, чтобы сотрудничать, проблема не в агентах — проблема в отсутствующем стержне, который их связывает.

Фото: Studio Romantic / Shutterstock
Наша многоагентная ИИ-система впечатляла в демонстрациях. Один агент обрабатывал запросы клиентов. Другой управлял расписанием. Третий обрабатывал документы. Каждый прекрасно работал по отдельности.
В рабочей среде они мешали друг другу. Агент планирования бронировал встречи, пока агент запросов еще собирал требования. Агент документов обрабатывал файлы, используя устаревший контекст из разговора, который уже ушел на два хода вперед. Сквозная задержка выросла примерно со 200 миллисекунд почти до 2,4 секунды, поскольку агенты ждали друг друга через разовые вызовы API, которые никто не проектировал для масштабирования.
Проблема была не в агентах. Каждый отдельный агент хорошо справлялся в своей области. Проблемой была отсутствующая инфраструктура координации между ними — то, что я теперь называю «Event Spine», которая позволяет агентам работать как система, а не как набор отдельных исполнителей, конкурирующих за одни и те же ресурсы.
Среди моих коллег, которые запускают производственный ИИ в корпоративном масштабе в телекоммуникациях и здравоохранении, повторяется та же картина. Распространение агентов — это реальность. Инструменты для координации этих агентов не успевают за ней.
Сринниваса Редди Хулебиду Редди
Почему прямое взаимодействие агент-агент ломается
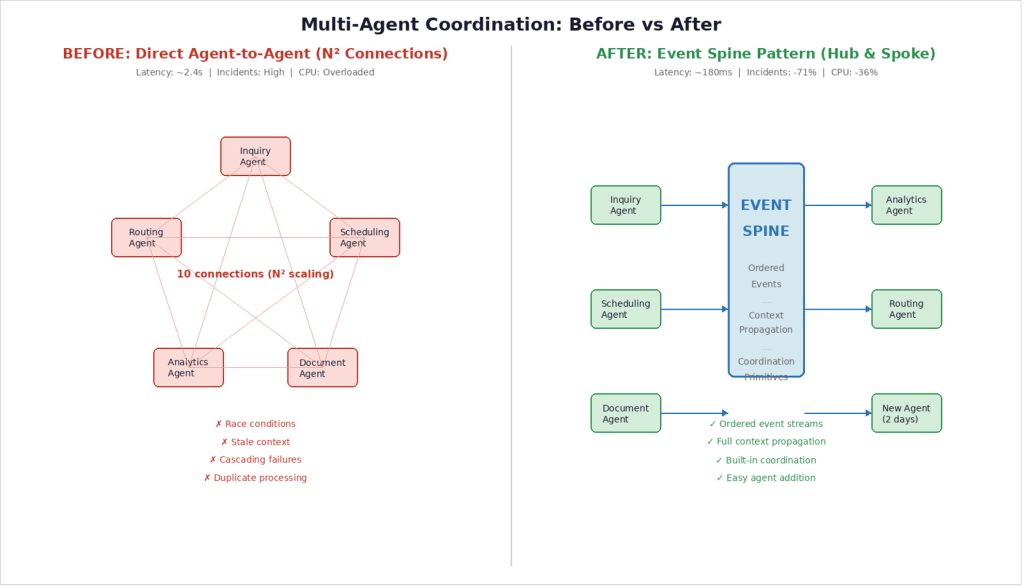
Интуитивный подход к многоагентным системам — это прямое взаимодействие. Агент A вызывает API агента B. Агент B отвечает. Простая точечная интеграция. Это похоже на то, как большинство команд изначально строят микросервисы, и это нормально работает, когда у вас два или три агента.
Но математика быстро перестает сходиться. По мере роста числа агентов число соединений растет квадратично. Пять агентов требуют 10 соединений. Десять — 45. Двадцать — 190. Каждое соединение — это потенциальная точка отказа, источник задержки и проблема координации, которую кто-то должен поддерживать.
Еще хуже то, что прямое взаимодействие создает скрытые зависимости. Когда Агент A вызывает Агент B, A должен понимать состояние B, его доступность и текущую нагрузку. Это знание жестко связывает агентов, сводя на нет саму идею распределения возможностей по специализированным компонентам. Измените контракт API B — и каждому агенту, который вызывает B, потребуется обновление.
Мы уже видели этот фильм раньше. Микросервисы прошли через ту же эволюцию — от прямых вызовов сервис-сервис к шинам сообщений, затем к service mesh. ИИ-агенты идут по тому же пути, только сжатому до месяцев вместо лет.
Паттерн Event Spine
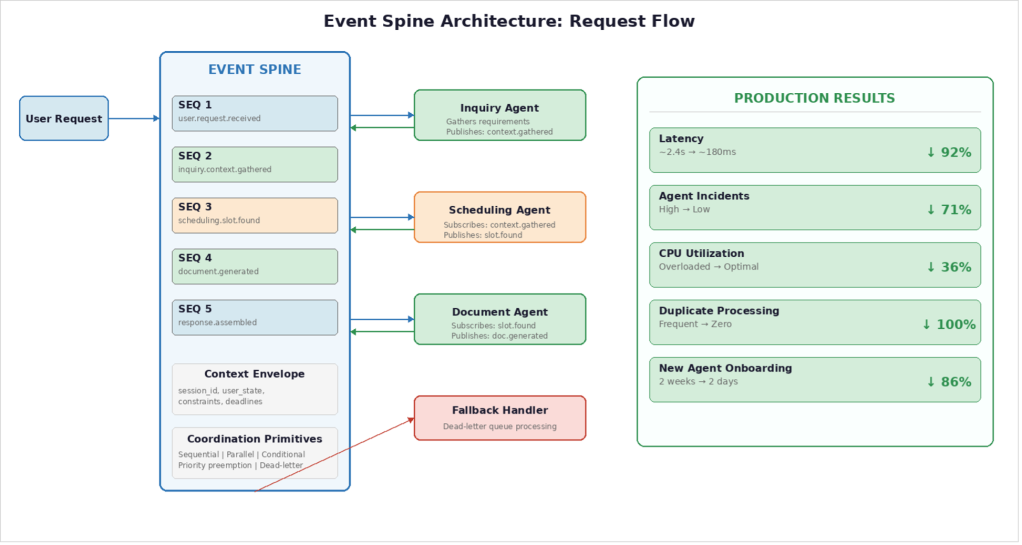
Event Spine — это централизованный уровень координации с тремя свойствами, специально разработанными для многоагентных ИИ-систем.
Во-первых, упорядоченные потоки событий. Каждое действие агента порождает событие с глобальным порядковым номером. Любой агент может восстановить текущее состояние системы, прочитав поток событий. Это устраняет необходимость агентам напрямую запрашивать друг друга, а именно там в нашей системе и скрывалась задержка.
Во-вторых, распространение контекста. Каждое событие несет контекстный пакет, включающий исходный запрос пользователя, текущее состояние сессии и любые ограничения или дедлайны. Когда агент получает событие, у него есть полная картина без дополнительных вызовов. В нашей прежней архитектуре агенты делали от трех до пяти round-trip-вызовов только для того, чтобы собрать достаточно контекста для действия по одному запросу. В-третьих, примитивы координации. Spine предоставляет встроенную поддержку распространенных шаблонов: последовательные передачи между агентами, параллельный fan-out с агрегацией, условная маршрутизация на основе оценок уверенности и приоритетное вытеснение, когда поступают срочные запросы. Иначе эти шаблоны пришлось бы реализовывать отдельно для каждой пары агентов, дублируя логику и создавая несогласованность.
from collections import defaultdict
import time
class EventSpine:
def __init__(self):
self.sequence = 0
self.subscribers = defaultdict(list)
def publish(self, event_type, payload, context):
self.sequence += 1
event = Event(
seq=self.sequence,
type=event_type,
payload=payload,
context=context,
timestamp=time.time()
)
for handler in self.subscribers[event_type]:
handler(event)
return event
def subscribe(self, event_type, handler):
self.subscribers[event_type].append(handler)
Сринниваса Редди Хулебиду Редди
3 проблемы, которые решает Event Spine
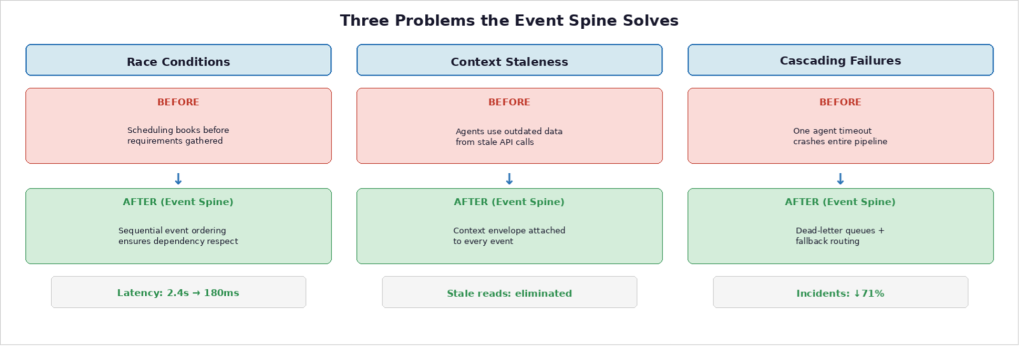
Проблема первая: состояния гонки между агентами. Без координации наш агент планирования бронировал встречи до того, как агент запросов завершал сбор требований. Клиенты получали приглашения в календарь на встречи, в которых отсутствовали критически важные детали. Event Spine решил это, обеспечив последовательную обработку зависимых операций. Агент планирования подписывается на события завершения сбора требований и действует только после подтверждения, что агент запросов собрал все необходимое.
Проблема вторая: устаревание контекста. Решения, принятые агентами на основе устаревшей информации, были нашим вторым по частоте режимом отказа. Клиент мог исправить номер телефона в ходе разговора, но агент документов — который получил контекст тремя ходами раньше — создавал бумаги со старым номером. Event Spine решил это, прикрепляя к каждому событию текущий контекстный пакет. Когда агент запросов публикует обновление, прикрепленный контекст отражает последнее состояние. Нижестоящие агенты никогда не работают с устаревшими данными.
Проблема третья: каскадные сбои. Когда один агент в цепочке прямых вызовов выходит из строя, downstream-агенты либо зависают в ожидании ответа, либо ломаются сами. Один таймаут при обработке документов вызывал каскадный сбой в планировании и таймауты в обработке запросов. Event Spine внедрил очереди dead-letter, политики таймаутов и резервную маршрутизацию. Когда у агента обработки документов возникали всплески задержки, события автоматически перенаправлялись к упрощенному резервному обработчику, который ставил работу в очередь на более позднюю обработку вместо того, чтобы выводить из строя весь конвейер.
Сринниваса Редди Хулебиду Редди
Результаты
Совокупный эффект изменил профиль производительности нашей системы. Сквозная задержка снизилась примерно с 2,4 секунды до около 180 миллисекунд. Улучшение было достигнуто главным образом за счет устранения каскадных round-trip-вызовов между агентами. Вместо того чтобы пять агентов отправляли точечные запросы для построения контекста, каждый агент получает ровно то, что ему нужно, через поток событий.
Количество инцидентов в продакшене, связанных с агентами, снизилось на 71 процент в первый квартал после внедрения. Большая часть устраненных инцидентов — это состояния гонки и баги устаревшего контекста, которые структурно невозможны при событийной координации.
Использование CPU агентами снизилось примерно на 36 процентов, потому что агенты перестали выполнять дублирующую работу. В старой архитектуре несколько агентов независимо запрашивали одни и те же клиентские данные из общих сервисов. При распространении контекста через Spine эти данные запрашиваются один раз и передаются через контекстный пакет события.
Дублирующая обработка была полностью устранена. В нашей прежней архитектуре не было надежного способа определить, когда два агента одновременно действуют над одним и тем же запросом. Глобальная нумерация событий в Event Spine обеспечивает естественную дедупликацию. Производительность разработчиков тоже выросла, хотя это сложнее измерить. Добавление нового агента в систему теперь требует подписки на релевантные события, а не точечной интеграции с каждым существующим агентом. Наше последнее добавление агента заняло два дня от прототипа до продакшена, по сравнению с двумя неделями, которые требовались ранее.
# Пример: последовательная передача с резервным вариантом
class AgentCoordinator:
def __init__(self, spine: EventSpine):
self.spine = spine
spine.subscribe('inquiry.complete', self.on_inquiry_complete)
spine.subscribe('scheduling.complete', self.on_scheduling_complete)
spine.subscribe('agent.timeout', self.on_agent_timeout)
def on_inquiry_complete(self, event):
# Последовательно: планирование начинается только после запроса
self.spine.publish(
'scheduling.request',
payload=event.payload,
context=event.context # Передается свежий контекст
)
def on_agent_timeout(self, event):
# Резерв: отправка в очередь dead-letter
self.spine.publish(
'fallback.process',
payload=event.payload,
context={**event.context, 'fallback_reason': 'timeout'}
}
Что это означает для предприятий, масштабирующих ИИ-агентов
Многоагентный ИИ — это не концепция будущего. Это сегодняшняя реальность для любого предприятия, где используется более двух ИИ-способностей. Если у вас есть чат-бот, рекомендательная система и обработчик документов, у вас уже многоагентная система — независимо от того, проектировали ли вы ее так или нет.
Проблема координации будет только расти по мере увеличения числа агентов. Каждое предприятие, с которым я общаюсь, добавляет ИИ-возможности быстрее, чем инфраструктуру координации. Этот разрыв и порождает инциденты в продакшене.
Паттерн Event Spine обеспечивает архитектурную основу, которая не дает распространению агентов превратиться в агентный хаос. Это тот же урок, который индустрия усвоила с микросервисами десять лет назад: распределенным системам нужна явная инфраструктура координации, а не просто добрые намерения и API-контракты между командами.
Предприятия, которые успешно масштабируют ИИ, — это те, кто уже сейчас инвестирует в архитектуру координации, пока сложность еще управляема. Те, кто будет ждать, в итоге все равно построят ее — только под большим давлением, с большим числом инцидентов и более высокой стоимостью.
Эта статья опубликована в рамках Foundry Expert Contributor Network.Хотите присоединиться?
Искусственный интеллектМикросервисыCloud-NativeОблачные вычисленияПодходы к разработкеРазработка программного обеспечения
by
Сринниваса Редди Хулебиду Редди
Автор
Сринниваса Редди Хулебиду Редди — бывший ведущий инженер-программист в AT&T Services Inc., где он разрабатывал платформы взаимодействия с клиентами на основе ИИ. Его работа сосредоточена на практических задачах внедрения ИИ в корпоративном масштабе — балансе производительности, стоимости и надежности для систем, обслуживающих миллионы пользователей.
Имея более 13 лет опыта в телекоммуникациях, здравоохранении и финансовых услугах, Сринниваса руководил командами в ходе сложных технологических преобразований, включая миграцию на облачно-нативные архитектуры и интеграцию больших языковых моделей в производственные рабочие процессы. Он также является рецензентом Wiley-IEEE Press и Manning Publications и старшим членом IEEE.
Еще от этого автора
Показать еще
новости
AWS нацелена на разрастание ИИ-агентов с новым Bedrock Agent Registry
By Anirban Ghoshal10 апр. 20264 мин
Amazon Web ServicesИскусственный интеллектIaaS

мнение
Облачные степени переходят в онлайн
By David Linthicum10 апр. 20266 мин
КарьераОблачные вычисленияТехнологическая индустрия

мнение
ИИ-агенты не терпят неудачу. Сбой происходит на уровне координации
By Sreenivasa Reddy Hulebeedu Reddy10 апр. 20268 мин
Cloud-NativeПодходы к разработкеМикросервисы

видео
Новый тип frozendict в Python

видео
Как повысить производительность приложения с помощью ленивого импорта в Python 3.15

видео
Как запустить свой собственный маленький локальный Claude Code (вроде того!)
26 мар. 20267 мин
Python

Материал — перевод статьи с английского.
Оригинал: AI agents aren’t failing. The coordination layer is failing