Голосовые агенты в реальном времени с Stream Vision Agents и Amazon Nova 2 Sonic

Материал подготовлен совместно с Neevash Ramdial, руководителем технического маркетинга в Stream
Создание производственных голосовых агентов, которые звучат естественно и реагируют без задержек, — сложная инженерная задача. Нужно согласовать speech-to-speech модели, управлять потоковой передачей аудио с низкой задержкой и контролировать жизненный цикл соединения. Также требуется обеспечивать одинаковый опыт в вебе, на мобильных устройствах и на десктопе.
В этом материале показано, как объединить open-source фреймворк Stream Vision Agents с Amazon Bedrock и Amazon Nova 2 Sonic, чтобы за считанные минуты собрать голосовых агентов реального времени, готовых к использованию в production. Вы узнаете, как работает эта интеграция под капотом, разберете примеры кода и познакомитесь с расширенными возможностями, включая function calling, автоматическое переподключение и поддержку нескольких языков.
Проблема
Разработка AI-приложений с голосовым интерфейсом требует координации нескольких сложных систем, которые должны надежно работать вместе. Нужно одновременно управлять инфраструктурой потоковой передачи аудио в реальном времени и интегрировать распознавание речи, языковые модели и сервисы text-to-speech. У каждого из этих компонентов — свои характеристики задержки и свои сценарии отказа. Типичный голосовой диалог включает захват звука с микрофона пользователя, передачу его в speech-to-text сервис, обработку транскрипта языковой моделью, генерацию ответа, преобразование ответа обратно в речь и доставку пользователю. Все это должно происходить в течение нескольких сотен миллисекунд, чтобы взаимодействие ощущалось естественным. Задержки в таком конвейере могут разрушить разговорный поток и раздражать пользователей.
Помимо основного AI-конвейера, production-приложения для голоса должны учитывать сложные реалии реальной эксплуатации: нестабильные сетевые соединения, проблемы совместимости браузеров, тайм-ауты сессий и корректную деградацию при недоступности сервисов. Часто на реализацию логики переподключения, управление WebRTC-соединениями и обработку крайних случаев уходит больше времени, чем на саму AI-функциональность. Эта инфраструктурная нагрузка приводит к тому, что команды либо месяцами строят собственное решение, либо используют ограниченные готовые продукты, которые не закрывают их задачи. Vision Agents абстрагирует инфраструктурную сложность и при этом сохраняет гибкость для настройки AI-опыта.
Обзор решения
Решение объединяет три ключевых компонента:
- Amazon Nova 2 Sonic — базовая speech-to-speech модель, доступная через Amazon Bedrock, которая обеспечивает двунаправленную потоковую передачу аудио в реальном времени, встроенное определение turn-taking и функцию function calling. Nova 2 Sonic берет на себя весь speech-to-speech конвейер: принимает аудиовход и выдает аудиовыход. Это устраняет необходимость в отдельных STT- и TTS-сервисах.
- Stream Vision Agents — open-source Python-фреймворк для создания голосовых и видео AI-агентов в реальном времени. Он предлагает плагинную архитектуру с более чем 25 интеграциями, инструменты для production-развертывания и client SDK для React, iOS, Android, Flutter и React Native. Система изначально построена вокруг гибкости. Можно использовать глобальную edge-сеть Stream для эффективной работы или подключить предпочитаемого провайдера real-time communication (RTC). Vision Agents обрабатывает спецификации конкретных провайдеров через аккуратный интерфейс на основе декораторов, что позволяет с минимальным количеством шаблонного кода реализовывать сценарии вроде агентов поддержки, автоматизации рабочих процессов и действий, запускаемых через API. С Vision Agents можно строить AI-приложения на основе open-source фреймворка, сторонних поставщиков моделей и telephony-сервисов.
- Stream Edge Network — глобально распределенная edge-сеть, которая обычно обеспечивает время подключения менее 500 мс и задержку аудио ниже 30 мс, формируя транспортный слой реального времени между клиентами и backend агента.
Вместе эти компоненты образуют полноценный стек: Stream отвечает за real-time media transport и клиентский опыт, Amazon Nova 2 Sonic предоставляет AI-интеллект, а Vision Agents связывает все части воедино.
Архитектура
Система построена на четком разделении обязанностей: инфраструктура Stream отвечает за real-time media transport и подключение клиентов, а Amazon Nova Sonic работает в собственном AWS account клиента и предоставляет AI-интеллект. Такое разделение помогает сохранить чувствительные данные и бизнес-логику под контролем клиента, а глобально распределенная edge-сеть Stream обеспечивает ожидаемо низкую задержку при передаче медиа. Edge-сеть Stream выступает как медиаброкер между устройствами конечных пользователей и worker-процессами Vision Agent. Когда пользователь говорит, аудио захватывается, шифруется и передается в виде RTP поверх UDP на ближайший Stream SFU (Selective Forwarding Unit). SFU завершает WebRTC-соединение, обрабатывает NAT traversal и оценку пропускной способности, а затем пересылает аудиодорожки в Vision Agent worker так, как будто это еще один участник вызова. Благодаря этому агент естественно встраивается в модель звонка. Агент — это еще один peer, который принимает и отправляет аудио через ту же инфраструктуру, что и люди.
Аудиоданные проходят через систему в обоих направлениях: входящая речь пользователя декодируется Vision Agent worker в необработанный PCM, затем передается в Amazon Nova Sonic через Bedrock real-time API, а аудиокадры ответа от Nova Sonic перекодируются, упаковываются в RTP и возвращаются через SFU на клиентское устройство. Сквозная задержка обычно составляет менее 500 миллисекунд. Voice activity detection (VAD) запускается в worker, чтобы определять границы речи и события barge-in, а эхоподавление в браузере помогает не допустить повторного срабатывания VAD на собственный голос агента.
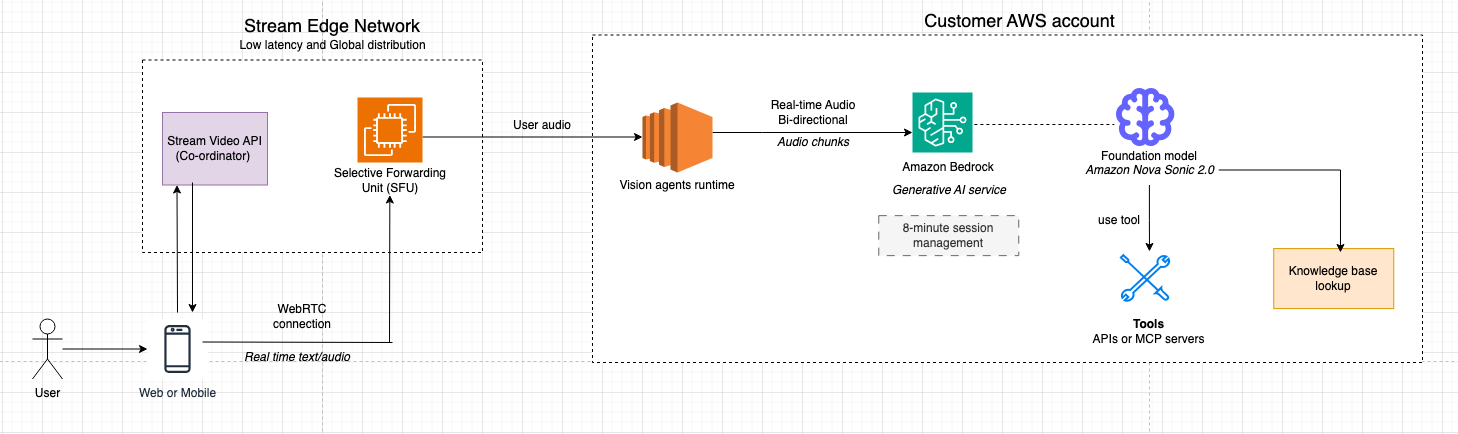
Границы аккаунтов
- Customer AWS account
- Бизнес-логика и оркестрация (политики агента, инструменты, доступ к данным).
- Интеграция Amazon Bedrock для доступа к моделям Amazon Nova.
- Stream AWS account
- Глобальный WebRTC/SFU media plane, TURN/STUN и signaling.
- Vision Agent runtime (worker-процессы), которые завершают WebRTC как robot peers и связывают интеграцию Amazon Bedrock клиента.
Поток медиа end-to-end
- Пользователь подключается из web или mobile.
- Приложение встраивает Stream audio client SDK, запрашивает доступ к микрофону и, при необходимости, камере и присоединяется к типу звонка, настроенному для участия AI.
- Медиа передается как RTP поверх UDP для предсказуемо низкой задержки и доставки без head-of-line blocking.
- Региональное завершение на SFU
- Узел Stream SFU в ближайшем регионе завершает WebRTC-соединение пользователя, выполняя оценку пропускной способности, simulcast и NAT traversal.
- SFU пересылает нужные аудиодорожки в Vision Agent worker так, будто это еще один участник звонка.
- Vision Agent worker
- Выделенный процесс Vision Agent worker хранит состояние PeerConnection для этой сессии.
- Он декодирует аудио в необработанный PCM, а worker потоково отправляет PCM-кадры в сервис Amazon Bedrock, который перенаправляет их в Amazon Nova 2 Sonic как real-time session в AWS account клиента.
- Интеграция Amazon Nova 2 Sonic с Vision Agents через Amazon Bedrock
- Amazon Nova 2 Sonic определяет границы речи и выполняет speech-to-speech modeling (понимание, рассуждение и TTS) с необязательными tool calls во внутренние системы клиента (RDS, API, knowledge bases).
- Она корректно обрабатывает barge-in и сохраняет полный conversational context, чтобы разговор оставался естественным и связным.
- Возврат потока ответа пользователю
- Когда Amazon Nova Sonic генерирует аудиокадры ответа, Vision Agent worker:
- нарезает их и оборачивает в RTP с монотонно возрастающими таймстампами, чтобы избежать разрывов и дрейфа;
- отправляет RTP-пакеты по той же WebRTC-сессии через SFU. WebRTC-стек браузера декодирует и воспроизводит звук с задержкой менее 500 мс.
- Когда Amazon Nova Sonic генерирует аудиокадры ответа, Vision Agent worker:
- Barge-in, транскрипты и дополнительные данные
- Эхоподавление в браузере помогает не допустить повторного запуска VAD на собственный вывод агента.
- Когда пользователь перебивает, новая речь отправляет interrupt signal через RTCDataChannel, из-за чего worker прекращает передачу вывода Amazon Nova Sonic и сбрасывает локальный буфер.
Такая архитектура может показаться сложной, но Vision Agents сильно упрощает ее реализацию. Посмотрим, как выглядит код:
Требования
Перед началом убедитесь, что у вас есть следующее:
- Учетные данные AWS, настроенные через переменные окружения, IAM role или профиль AWS Command Line Interface (AWS CLI). Для production-среды используйте IAM roles, прикрепленные к вашим вычислительным ресурсам, вместо долгоживущих учетных данных. Для локальной разработки используйте профили AWS CLI (aws configure) или AWS SSO. Не размещайте файлы .env с учетными данными в системе контроля версий.
- Аккаунт Stream с Audio API key и secret (предполагается, что вы получите 333 000 participant minutes в месяц без дополнительной платы).
- Установленный Python 3.12 или новее.
- Установленный менеджер пакетов uv package (
pip install uv). - Установленный Vision Agents (
uv add vision-agents).
Начало работы
Шаг 1: Создайте новый каталог проекта и установите Vision Agents с AWS plugin
mkdir voice-agent
cd voice-agentuv inituv add "vision-agents[getstream,aws]"
python-dotenv
Расширение vision-agents[aws] устанавливает Amazon Bedrock plugin вместе с зависимостями, включая boto3, aws-sdk-bedrock-runtime и Silero VAD для voice activity detection.
Шаг 2: Настройте переменные окружения
Создайте файл .env в корне проекта для управления конфигурацией. Для учетных данных AWS мы рекомендуем указывать в этом файле AWS_PROFILE, чтобы приложение могло использовать ваши креденшелы при работе с ресурсами AWS. Мы не рекомендуем хранить в этом файле ключи доступа AWS напрямую.
Для учетных данных Stream API можно использовать сторонние решения вроде HashiCorp Vault или AWS Secrets Manager, но вопросы безопасности не входят в рамки этого материала.
# Учетные данные Stream API
STREAM_API_KEY=test/geststream/api_key
STREAM_API_SECRET=test/getstream/api_secret
# Учетные данные AWS
AWS_PROFILE=your_aws_profile_name
AWS_REGION=us-east-1
Vision Agents автоматически обнаруживает эти переменные окружения при запуске, поэтому не нужно передавать их явно каждому клиенту.
Шаг 3: Создайте своего первого голосового агента
Создайте файл main.py со следующим кодом:
import asyncio
from dotenv import load_dotenv
from vision_agents.core import Agent, User, Runner
from vision_agents.core.agents import AgentLauncher
from vision_agents.plugins import aws, getstream
load_dotenv()
async def create_agent(**kwargs) -> Agent:
agent = Agent(
edge=getstream.Edge(),
agent_user=User(name="Helpful Assistant", id="agent"),
instructions="You are a helpful voice assistant. Be concise and friendly.",
llm=aws.Realtime(
model="amazon.nova-2-sonic-v1:0",
region_name="us-east-1",
voice_id="matthew",
),
)
return agent
async def join_call(agent: Agent, call_type: str, call_id: str, **kwargs) -> None:
call = await agent.create_call(call_type, call_id)
async with agent.join(call):
await asyncio.sleep(2)
await agent.llm.simple_response(
text="Greet the user warmly and ask how you can help."
)
await agent.finish() # Выполнять до завершения звонка
if __name__ == "__main__":
Runner(AgentLauncher(create_agent=create_agent, join_call=join_call)).cli()
Шаг 4: Запустите голосового агента
Запустите агента:
uv run main.py run
Менее чем за 30 строк кода вы получаете полнофункционального голосового агента реального времени на базе Amazon Nova Sonic, доступного через Stream client SDK.
Как работает интеграция Amazon Bedrock
Давайте подробнее рассмотрим, как плагин aws.Realtime работает под капотом.
Двунаправленная потоковая передача с Amazon Nova 2 Sonic
Amazon Nova 2 Sonic использует event-driven двунаправленный streaming API. Вместо request-response модели этот подход позволяет почти непрерывно передавать аудио в обоих направлениях одновременно. AWS plugin Vision Agents управляет этой сложностью через структурированную последовательность событий:
- Инициализация сессии — отправляется событие
sessionStartс конфигурацией инференса (temperature, max tokens, top-p). - Настройка prompt — событие
promptStartзадает формат аудиовывода (24kHz PCM), выбор голоса и определения инструментов. - Системные инструкции — системные инструкции отправляются как текстовый content block с ролью
SYSTEM. - Потоковое аудио — аудиокадры с микрофона, примерно по 32 мс каждый, передаются как события
audioInput. - Поток ответа — Nova Sonic возвращает события
audioOutputс сгенерированной речью. - Завершение сессии — события
promptEndиsessionEndкорректно закрывают соединение.
Каждый content block следует трехчастному шаблону: contentStart → payload → contentEnd. Такая иерархическая структура помогает модели сохранять корректный контекст на протяжении всего взаимодействия.
Вот как выглядит событие начала сессии в плагине:
def _create_session_start_event(self) -> Dict[str, Any]:
return {
"event": {
"sessionStart": {
"inferenceConfiguration": {
"maxTokens": 1024,
"topP": 0.9,
"temperature": 0.7,
}
},
"turnDetectionConfiguration": {
"endpointingSensitivity": "MEDIUM"
},
}
}
Добавление function calling
Одна из ключевых возможностей Amazon Nova 2 Sonic — нативный function calling во время разговоров в реальном времени. Это позволяет голосовому агенту выполнять действия вроде запросов к базам данных, вызовов API и запуска рабочих процессов, сохраняя естественный разговорный формат. Используйте декоратор @llm.register_function, чтобы определить функции, которые может вызывать модель:
import asyncio
from dotenv import load_dotenv
from typing import Dict, Any
from vision_agents.core import Agent, User, Runner
from vision_agents.core.agents import AgentLauncher
from vision_agents.plugins import aws, getstream
load_dotenv()
async def create_agent(**kwargs) -> Agent:
agent = Agent(
edge=getstream.Edge(),
agent_user=User(name="Weather Assistant", id="agent"),
instructions="""You are a helpful weather assistant. When users ask
about weather, use the get_weather function to fetch current conditions.
You can also help with simple calculations.""",
llm=aws.Realtime(
model="amazon.nova-2-sonic-v1:0",
region_name="us-east-1",
),
)
@agent.llm.register_function(
name="get_weather",
description="Get the current weather for a given city"
)
async def get_weather(location: str) -> Dict[str, Any]:
# В production используйте реальный weather API
return {
"city": location,
"temperature": 72,
"condition": "Sunny",
"humidity": "45%"
}
@agent.llm.register_function(
name="calculate",
description="Perform a mathematical calculation"
)
def calculate(operation: str, a: float, b: float) -> dict:
operations = {
"add": lambda x, y: x + y,
"subtract": lambda x, y: x - y,
"multiply": lambda x, y: x * y,
"divide": lambda x, y: x / y if y != 0 else None,
}
result = operations.get(operation, lambda x, y: None)(a, b)
return {"operation": operation, "a": a, "b": b, "result": result}
return agent
async def join_call(agent: Agent, call_type: str, call_id: str, **kwargs) -> None:
await agent.create_user()
call = await agent.create_call(call_type, call_id)
async with agent.join(call):
await asyncio.sleep(2)
await agent.llm.simple_response(
text="Greet the user and let them know you can check the weather."
)
await agent.finish()
if __name__ == "__main__":
Runner(AgentLauncher(create_agent=create_agent, join_call=join_call)).cli()
Как работает function calling с Amazon Nova 2 Sonic
Когда модель решает вызвать функцию, происходит следующая последовательность:
- Nova 2 Sonic генерирует событие
toolUseс названием функции и аргументами. - Плагин Vision Agents перехватывает это событие, десериализует аргументы и выполняет зарегистрированную Python-функцию.
- Результат отправляется обратно в Nova через событие
toolResult, обернутое в стандартный шаблонcontentStart→toolResult→contentEnd. - Nova 2 Sonic встраивает результат функции в свой ответ и продолжает разговор естественно.
С помощью этого подхода можно строить сложные многошаговые рабочие процессы. Например, голосовой агент может искать карточку клиента, проверять наличие товара на складе и оформлять заказ — все в рамках одного естественного диалога.
Использование стандартного LLM с Amazon Bedrock
Помимо real-time speech-to-speech, AWS plugin также предоставляет стандартную интеграцию LLM через aws.LLM. Это полезно для кастомных pipeline-архитектур, где нужно объединить модель Amazon Bedrock с отдельными провайдерами STT и TTS:
from vision_agents.core import Agent, User
from vision_agents.plugins import aws, getstream, cartesia, deepgram, smart_turn
agent = Agent(
edge=getstream.Edge(),
agent_user=User(name="Custom Pipeline Agent"),
instructions="Be helpful and concise.",
llm=aws.LLM(
model="anthropic.claude-3-haiku-20240307-v1:0",
region_name="us-east-1"
),
tts=cartesia.TTS(),
stt=deepgram.STT(),
turn_detection=smart_turn.TurnDetection(
buffer_duration=2.0,
confidence_threshold=0.5
),
)
Стандартный LLM поддерживает потоковые ответы через converse_stream(), полное управление историей диалога, vision inputs для моделей вроде Claude и многораундовый tool calling с максимум 3 раундами выполнения функций на один запрос.
Text-to-speech с Amazon Polly
Для кастомных pipeline-архитектур AWS plugin также включает интеграцию TTS с Amazon Polly. Это удобно, когда вы используете нерелуайм LLM, например Claude на Amazon Bedrock или другую модель, и вам нужен качественный синтез речи:
from vision_agents.plugins import aws
tts = aws.TTS(
region_name="us-east-1",
voice_id="Joanna",
engine="neural", # 'standard' или 'neural'
language_code="en-US"
)
Amazon Polly TTS поддерживает стандартный и neural engines, SSML input для точной настройки речи, а также несколько языков и голосов. Neural engine обеспечивает более естественное звучание, что делает его сильным выбором для построения собственного STT → LLM → TTS pipeline на AWS infrastructure.
Очистка ресурсов
Чтобы удалить звонок Stream и завершить запущенные процессы Vision Agent:
uv run main.py stop
Важно: за все API-вызовы к Amazon Nova 2 Sonic взимается плата Amazon Bedrock. Можно выполнить команду очистки, чтобы завершить сессии и избежать дальнейших расходов. Активные сессии могут продолжать генерировать затраты, пока их явно не завершить.
Сценарии использования
Теперь, когда техническая основа понятна, стоит посмотреть, где эти возможности могут дать ощутимый эффект в реальных задачах. Сочетание низколатентного голоса, управления диалогом и интеграции с инструментами открывает широкий спектр применений в отраслях, где естественное голосовое взаимодействие может заменить или дополнить традиционные интерфейсы.
Сценарий 1: Голосовые интерфейсы для сред без экрана и с низким вниманием
Vision Agents в сочетании с Amazon Nova 2 Sonic хорошо подходит для сценариев, где пользователи не могут надежно взаимодействовать с экраном, например во время вождения, выездного обслуживания, в логистике, здравоохранении или на объектах. В таких условиях голос становится основным интерфейсом, а не дополнительной функцией.
- С Amazon Nova 2 Sonic вы получаете speech-to-speech взаимодействие в реальном времени с низкой задержкой и естественным turn-taking, что позволяет пользователям свободно говорить, перебивать ответы и исправлять себя без нарушения потока.
- Vision Agents управляет состоянием разговора и логикой задач между ходами, преобразуя устную речь в структурированные действия вроде получения следующего задания, обновления статуса задачи, записи заметок или запроса помощи у человека.
Поскольку агент сохраняет контекст на протяжении всего взаимодействия, пользователи могут давать последующие команды и уточнения без повторения информации. Например, водитель доставки может спросить: «Какая у меня следующая остановка?», получить голосовые указания, затем сказать: «Отметь последнюю доставку как выполненную», а после этого добавить: «Позвони диспетчеру» — и все это без касания экрана, пока агент обновляет backend-системы в реальном времени.
Сценарий 2: Обработка большого потока входящих телефонных обращений
Vision Agents в сочетании с Amazon Nova 2 Sonic предназначен для работы с большим количеством входящих обращений, где человеческие операторы становятся узким местом. Суть этого сценария — масштаб: сокращение времени ожидания, снятие повторяющихся запросов и освобождение операторов для случаев, где требуется их участие.
- С Amazon Nova 2 Sonic звонящие могут вести low-latency speech-to-speech разговоры в реальном времени, описывая проблему естественно, а не проходя по скриптовым IVR-деревьям.
- Vision Agents оркестрирует определение намерения, состояние диалога и интеграции с backend-системами, такими как системы заказов, учетные записи или сервисы тикетов, чтобы типовые запросы можно было автоматически закрывать прямо во время звонка.
Когда проблема выходит за пределы заданных порогов уверенности или требует ручного вмешательства, агент переводит обращение человеку, прикладывая структурированный контекст, чтобы звонящему не пришлось повторяться. В часы пик сотни клиентов могут звонить с вопросами о задержках доставки. Вместо ожидания в очереди они сразу получают ответ от голосового агента, который проверяет статус заказа, объясняет задержку, предлагает следующие шаги и переводит на живого оператора только при обнаружении исключения. Так телефонная система превращается из центра затрат, основанного на очередях, в непрерывный слой первичной обработки обращений.
Заключение
В этом материале показано, как строить голосовых агентов реального времени с использованием Stream Vision Agents и Amazon Bedrock с Amazon Nova 2 Sonic. Мы рассмотрели архитектуру, протокол двунаправленной потоковой передачи, обработку автоматического переподключения, function calling, поддержку нескольких языков и production-развертывание. Сочетание low-latency edge-сети Stream и нативных speech-to-speech возможностей Amazon Nova Sonic дает надежную основу для создания voice AI-приложений. Фреймворк Vision Agents абстрагирует сложную оркестрацию жизненного цикла соединения, кодирования аудио, переподключения с учетом VAD и выполнения инструментов, чтобы вы могли сосредоточиться на логике агента и пользовательском опыте.
Материал — перевод статьи с английского.
Оригинал: Real-time voice agents with Stream Vision Agents and Amazon Nova 2 Sonic