Halliburton ускорила создание сейсмических рабочих процессов с помощью Amazon Bedrock и генеративного ИИ

Сейсмический анализ данных — важная часть разведки энергоресурсов, однако настройка сложных рабочих процессов обработки традиционно была трудоемкой и подверженной ошибкам задачей. Halliburton Seismic Engine, облачное приложение для обработки сейсмических данных, — мощный инструмент, который ранее требовал ручной настройки примерно 100 специализированных инструментов для создания рабочих процессов. Этот процесс был не только длительным, но и требовал глубокой экспертизы, что потенциально ограничивало доступность и эффективность ПО.
Чтобы решить эту задачу, Halliburton объединилась с AWS Generative AI Innovation Center для разработки ассистента на базе ИИ для Seismic Engine. Решение использует Amazon Bedrock, Amazon Bedrock Knowledge Bases, Amazon Nova и Amazon DynamoDB, чтобы превратить создание сложных рабочих процессов в диалог. Геонаучные специалисты и data scientists могут настраивать инструменты обработки через взаимодействие на естественном языке вместо ручной конфигурации.
В этом материале мы рассмотрим, как был создан proof-of-concept, который преобразует запросы на естественном языке в исполняемые сейсмические workflows и одновременно дает возможность отвечать на вопросы по инструментам и документации Seismic Engine. Мы разберем технические детали решения, поделимся результатами оценки, показывающими ускорение создания workflows до 95%, и обсудим ключевые выводы, которые помогут другим организациям улучшать сложные технические процессы с помощью генеративного ИИ.
Наше сотрудничество с AWS сыграло важную роль в ускорении workflows для интерпретации недр. Интегрировав сервисы Amazon Bedrock с Halliburton Landmark DS365 Seismic Engine, мы смогли сократить традиционно длительные задачи по построению workflows в десять раз. Этот ассистент на базе генеративного ИИ не только повышает эффективность и точность, но и делает наши продвинутые геофизические инструменты более доступными для более широкого круга пользователей. Масштабируемая облачная архитектура на AWS позволила нам создать бесшовный разговорный опыт, который принципиально повышает продуктивность во всех workflows для работы с недрами.
— Phillip Norlund, менеджер по технологиям недр, Halliburton Landmark— Slim Bouchrara, старший product owner по R&D в области недр, Halliburton Landmark
Обзор решения
Наша задача состояла из двух ключевых целей: преобразование запросов на естественном языке в исполняемые сейсмические workflows и создание интеллектуальной системы вопросов и ответов (Q&A) для документации Seismic Engine. Для этого мы разработали решение на базе Amazon Bedrock, которое позволяет геонаучным специалистам взаимодействовать со сложными сейсмическими инструментами в формате естественного общения. Основа системы — приложение FastAPI, развернутое в AWS App Runner, которое обрабатывает запросы пользователей через потоковый интерфейс. Когда пользователь отправляет запрос, маршрутизатор намерений на базе Amazon Nova Lite анализирует его и определяет, относится ли он к генерации workflow или к технической информации. Для запросов Q&A система использует Amazon Bedrock Knowledge Bases с Amazon OpenSearch Serverless, чтобы выдавать релевантные ответы из проиндексированной документации. Для запросов на создание workflows агент генерации с Anthropic Claude на Amazon Bedrock создает YAML workflows, выбирая из 82 доступных инструментов Seismic Engine.
Чтобы сохранять контекст и поддерживать многоходовые диалоги, мы интегрировали Amazon DynamoDB для истории чата и журнала взаимодействий. Система поддерживает потоковые ответы как для Q&A, так и для генерации workflows, обеспечивая немедленную обратную связь пользователю по мере обработки запроса. Такая архитектура позволяет создавать и изменять сложные технические workflows через естественный диалог, при этом сохраняя точность управления, необходимую для обработки сейсмических данных. На следующей схеме показана архитектура решения.
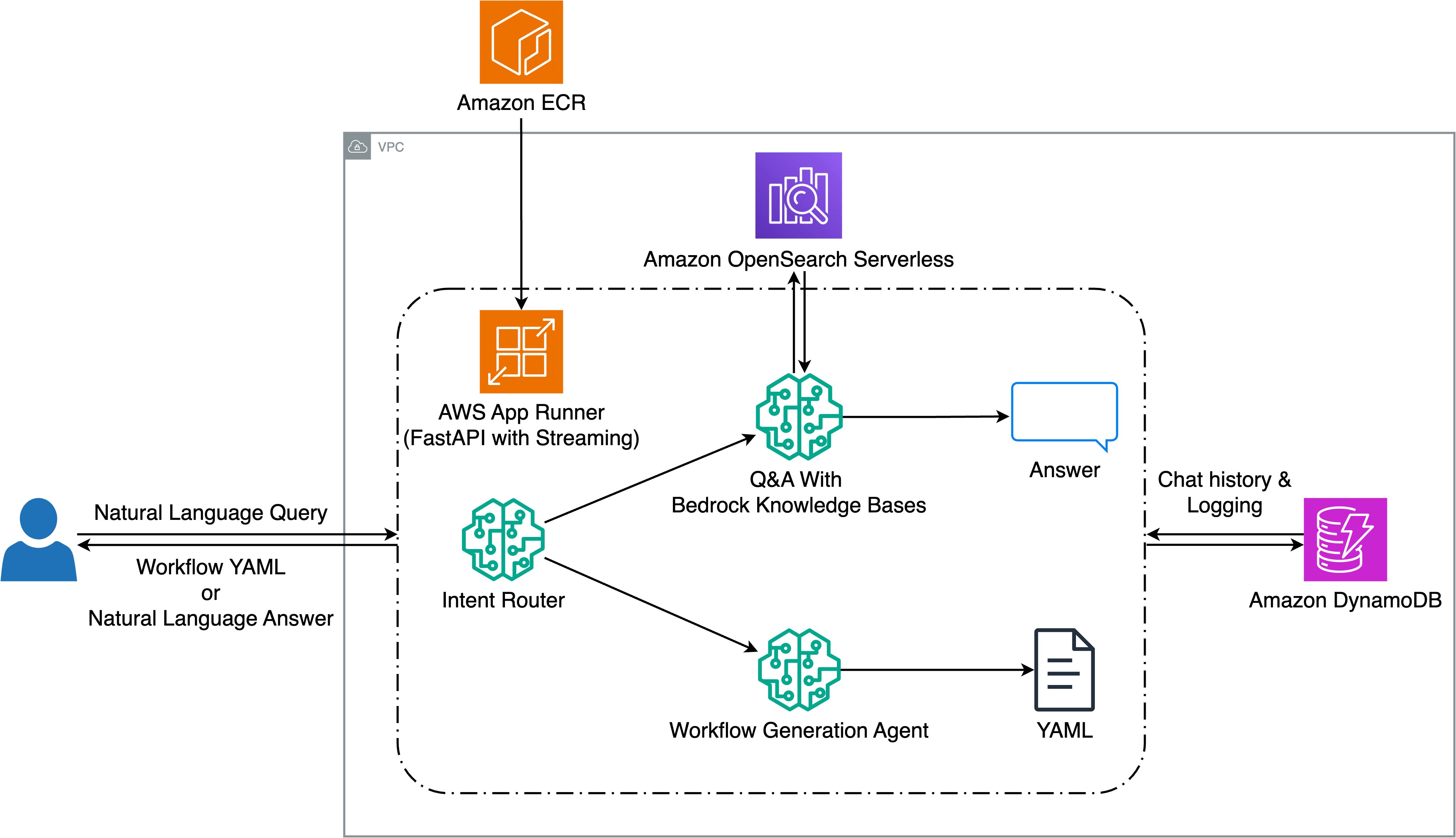
Маршрутизация запросов и классификация намерений
После того как пользовательский запрос поступает в систему, Intent Router классифицирует метку намерения данного запроса, вызывая Amazon Nova Lite через API Amazon Bedrock. Большой языковой моделью (LLM) задается подсказка, чтобы вернуть одну из трех меток намерения: «Workflow_Generation», «QnA» и «General_Question». Метка «Workflow_Generation» используется для маршрутизации запросов, связанных с генерацией workflows, включая чтение и загрузку наборов данных, операции обработки данных и различные запросы, связанные с изменением конкретных наборов данных. Метка намерения «QnA» используется для вопросов о конкретных инструментах, запросов на примеры workflows или вопросов по документации Seismic Engine. Метка «General_Question» зарезервирована для запросов, не относящихся к операциям Seismic Engine или workflows. В нашей реализации Amazon Nova Lite эффективно справлялась с задачей маршрутизации, обеспечивая хороший баланс между точностью и задержкой.
Реализация системы ответов на вопросы
Компонент Q&A обрабатывает запросы, связанные с Seismic Engine, с помощью Amazon Bedrock Knowledge Bases — полностью управляемого сервиса для сквозного рабочего процесса Retrieval Augmented Generation (RAG). Мы выбрали Bedrock Knowledge Bases, потому что он снимает операционные издержки, связанные с управлением векторными базами данных, стратегиями chunking и pipeline эмбеддингов. Будучи полностью управляемым сервисом, он автоматически обеспечивает масштабирование инфраструктуры, безопасность и обслуживание, чтобы наша команда могла сосредоточиться на разработке решения, а не на эксплуатации инфраструктуры RAG. Сервис предоставляет нативную поддержку нескольких стратегий chunking, включая hierarchical chunking, которая сохраняет отношения parent-child и помогает балансировать детальный поиск с более широким контекстом документа. Источники данных включают markdown-файлы документации инструментов и руководства Seismic Engine, хранящиеся в S3. Файлы документации инструментов мы оставили без chunking, поскольку они относительно короткие и позволяют сохранить полный контекст для каждого инструмента. Для более длинных документов, таких как руководства Seismic Engine, мы использовали hierarchical chunking с настройками по умолчанию. Для генерации embedding мы используем Amazon Titan Text Embeddings V2, а OpenSearch Serverless — в качестве векторной базы данных. Система также хранит метаданные, такие как имена файлов, URL и типы документов для каждого индексированного объекта, чтобы использовать их далее. Для поиска и генерации ответов мы используем API retrieve_and_generate Amazon Bedrock Knowledge Bases с Claude 3.5 Haiku в качестве модели. Система поддерживает многоходовые диалоги за счет сохранения контекста сеанса, а ответы форматируются с inline citations для лучшей прослеживаемости.
Примечание: это решение было разработано и оценено с использованием Claude 3.5 Sonnet V2 и Claude 3.5 Haiku. С тех пор их сменили Claude Sonnet 4.5 и, совсем недавно, Claude Sonnet 4.6, а также Claude Haiku 4.5, все доступные через Amazon Bedrock. Архитектура решения поддерживает обновление моделей без изменений кода, поэтому вы можете использовать новейшие возможности модели.
Такой подход позволяет системе выдавать релевантные ответы с учетом контекста на запросы пользователей о инструментах и workflows Seismic Engine.
Генерация workflows
Для запросов, классифицированных как «Workflow_Generation», наше решение использует LLM-агентов для преобразования естественного языка в исполняемые YAML workflows. Агент привязан к 82 инструментам, доступным в Seismic Engine. На основе пользовательского запроса и спецификаций инструментов, которые определяют входы, параметры и выходы, агент выбирает подходящие инструменты, определяет правильный порядок их выполнения и генерирует YAML workflow, соответствующий требованиям пользователя. На следующем рисунке показан процесс генерации workflows.
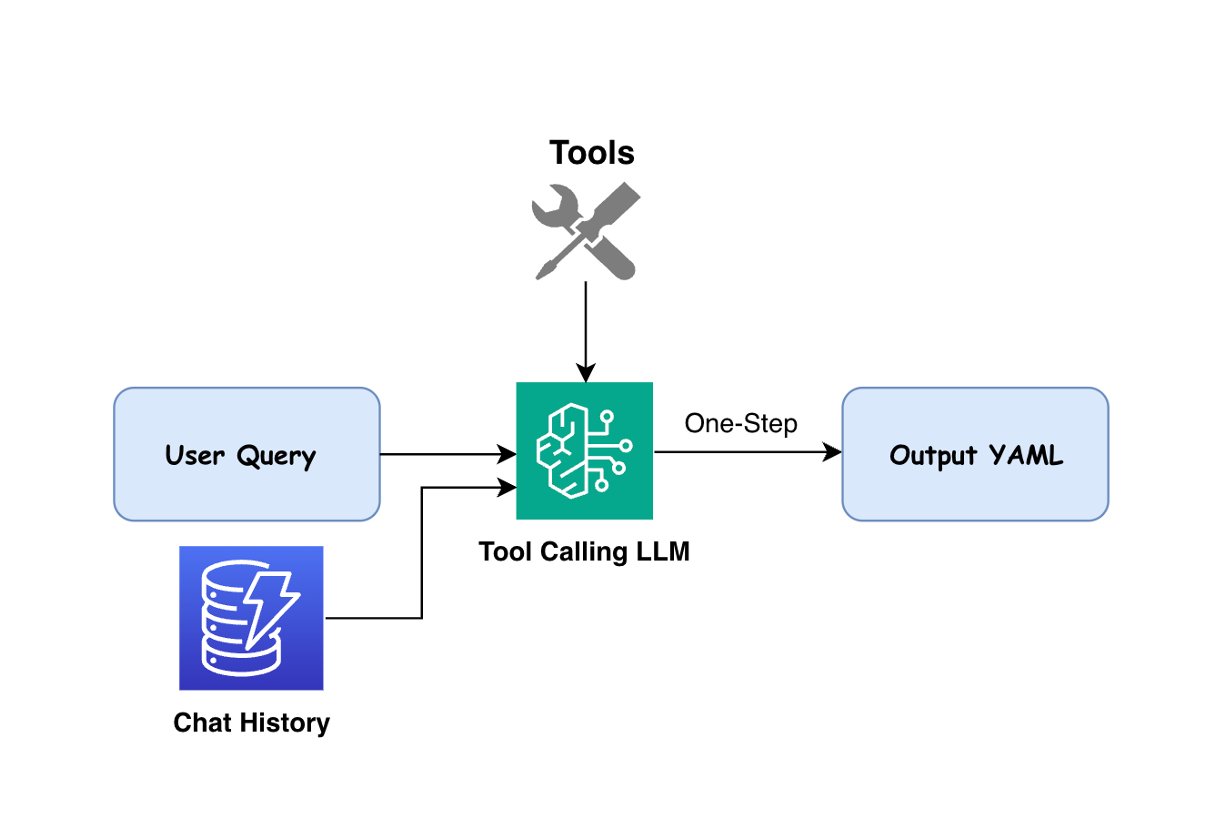
В нашей реализации мы использовали как Claude 3.5 Sonnet V2, так и Claude 3.5 Haiku, а оркестрация выполнялась через фреймворк LangChain для управления агентами и привязки инструментов. Модели получают подробные описания и спецификации инструментов, чтобы понимать возможности и требования каждого из них. При генерации workflows система учитывает не только явные требования в пользовательском запросе, но и добавляет необходимые параметры по умолчанию, когда конкретные значения не указаны. Процесс генерации workflows поддерживает многоходовые диалоги, чтобы пользователи могли изменять ранее созданные workflows с помощью запросов на естественном языке. Используя историю разговоров, хранящуюся в Amazon DynamoDB, LLM может либо создавать новые workflows, либо изменять существующие в соответствии с текущим запросом пользователя.
Оценка
Чтобы оценить эффективность решения, мы создали comprehensive тестовый набор пар запросов и workflows, включающий workflows низкой и средней сложности. Они были получены из реальных исторических workflows и проверены предметными экспертами, чтобы убедиться, что они точно отражают типичные запросы пользователей.
Результаты генерации workflows
| Модель | Сложность | Успешность | Среднее время генерации (с) | Медианное время генерации (с) |
| Claude Haiku 3.5 | простая | 84% | 8,3 | 5,9 |
| средняя | 90% | 12,4 | 9,1 | |
| Claude Sonnet 3.5 V2 | простая | 86% | 11,2 | 11,5 |
| средняя | 97% | 15,8 | 16,6 |
Обе модели показали высокую производительность, при этом Claude Sonnet 3.5 V2 продемонстрировала более высокую успешность, особенно для workflows средней сложности. Система выдает ответы в потоковом режиме, предоставляя пользователям немедленную обратную связь по мере генерации workflow, а готовые workflows доставляются за 5,9–16,6 секунды. Claude Haiku 3.5 обеспечивает более быстрое время генерации, предлагая компромисс между скоростью и точностью.
Сравнение с базовой производительностью
| Тип пользователя | % успеха | % неудач | Время создания простого workflow (мин) | Время создания сложного workflow (мин) |
| Новый пользователь | 70% | 20% | 4 | 20 |
| Опытный пользователь | 85% | 10% | 2 | 5 |
| Наше решение | 84-97% | 3-16% | 0,13-0,26 | 0,21-0,28 |
Наше решение на основе генеративного ИИ демонстрирует следующие улучшения:
- Показатели успешности 84-97% превосходят как новых, так и опытных пользователей.
- Время создания workflow сокращается с минут до секунд, что означает более чем 95-процентное сокращение времени.
Эти результаты показывают, что пользователи с любым уровнем опыта могут повысить продуктивность более чем на 95%, сохраняя или даже превосходя точность ручного создания workflows.
Заключение
В этом материале мы показали, как использовали Amazon Bedrock, чтобы превратить сложные технические процессы в естественный диалог. Внедрив ассистента на базе ИИ с интегрированными возможностями Q&A, мы достигли успешности генерации workflows на уровне 84-97% и сократили время создания более чем на 95% по сравнению с ручными процессами. Способность системы работать как с workflows низкой, так и средней сложности, в сочетании с контекстным пониманием инструментов Seismic Engine, показывает, как генеративный ИИ может улучшать удобство промышленного ПО без ущерба для точности.
Этот подход также хорошо переносится на другие области со сложными многошаговыми agentic workflows, где требуется специализированное знание инструментов и конфигурации. В качестве следующего шага стоит рассмотреть multi-agent architectures с использованием фреймворков вроде Strands Agents SDK и Amazon Bedrock AgentCore для повышения точности за счет специализированных подагентов.
Материал — перевод статьи с английского.
Оригинал: Halliburton enhances seismic workflow creation with Amazon Bedrock and Generative AI