Как Dataset Q&A в Amazon Quick помогает принимать решения на основе данных без новых дашбордов

Руководители компаний в разных отраслях опираются на операционные дашборды как на общий источник истины, на который ежедневно ориентируются команды. Но дашборды создаются для ответа на известные вопросы. Когда командам нужно исследовать данные глубже — задать спонтанный, многомерный или неожиданный вопрос, — возникает узкое место. Они ждут часы или дни, пока BI-команды создадут новые представления или обновят отчеты. Функция Dataset Q&A устраняет этот разрыв. Можно задавать вопросы на естественном языке, получать точные ответы за секунды, без создания новых дашбордов и без ожидания в очереди. Это просто интерактивный диалог с существующими наборами данных, который не нарушает работу дашбордов, на которые уже полагаются команды.
Проблема
Клиенты AWS ожидают быстрой и обоснованной поддержки, когда оценивают новые технологии, устраняют проблемы в production или планируют переход в cloud. Чтобы предоставлять такой опыт в масштабе, техническим field-командам AWS нужны немедленные ответы на сложные операционные вопросы: где растет спрос клиентов? У каких команд есть нужная экспертиза, чтобы ответить? Достаточно ли быстро решаются обращения клиентов? И где возникают новые пробелы, которые могут повлиять на результаты для клиентов?
Программа AWS Technical Field Communities (TFC) ежегодно поддерживает сотни тысяч таких клиентских взаимодействий в десятках специализированных технологических доменов. Для руководителей программы и field-команд понимание пульса этих взаимодействий — это не просто отслеживание метрик; это вопрос о том, чтобы в нужное время и в нужных местах были нужные навыки, помогающие клиентам добиваться успеха. Но по мере роста масштаба этих взаимодействий росла и сложность вопросов, на которые должны были отвечать руководители. Традиционные статические дашборды начали не справляться с более сложными, многомерными запросами. Участникам процесса приходилось перемещаться между множеством разных систем, вручную сопоставлять наборы данных, чтобы получить ясную картину того, как лучше обслуживать клиента. Добраться до «почему» за данными — не всегда сложная техническая задача, часто это проблема рабочего процесса. Вопрос руководителя становится прерыванием для BI-инженера: тот откладывает запланированную работу, выполняет агрегацию и возвращает ответ, который неизбежно порождает следующий вопрос. Реальная потеря времени происходит не в самом запросе. Она возникает на передаче между человеком с вопросом и человеком с инструментами для ответа. Руководители задавали сложные вопросы в реальном времени, которые пересекали организационные и технические границы.
Хотя данные существовали, они часто были «заперты» за жесткими визуализациями, которые не могли заранее учесть все нюансы потребностей руководителя программы. Кроме того, наличие персонально идентифицируемой информации (PII) означало, что определенные качественные детали — именно тот контекст, который делает данные пригодными для действий, — оставались ограниченными и их было трудно безопасно показать.
Представляем TARA: будущее разговорной аналитики
Чтобы устранить этот разрыв, AWS разработала TARA (Technical Analysis Research Agent). Хотя TARA создана для внутренних аналитических потребностей AWS, возможности Dataset Q&A, которые мы использовали, доступны клиентам Quick, сталкивающимся с похожими задачами. Созданная командой Specialist Data Lens (SDL), TARA — это AI-помощник для аналитики, который использует возможности custom chat agent в Quick. TARA служит единым разговорным интерфейсом, через который можно исследовать несколько интегрированных наборов данных, live system APIs и специализированные research agents с помощью естественного языка. Используя MCP для безопасного соединения структурированных наборов данных с внешними системами и предметно-специфичными research agents, TARA устраняет разрыв между количественными метриками и качественным контекстом. Это позволяет руководителям связывать количественные показатели с реальным положением дел в field, обогащая аналитические выводы оперативным контекстом в реальном времени и одновременно защищая чувствительные данные PII.
Мы развивали разговорную аналитику TARA, положив в ее основу Dataset Q&A для семантической генерации запросов и выдачи инсайтов. Этот материал рассказывает об этом пути и о том, как бизнес-пользователи взаимодействуют с данными более естественным образом. За счет внедрения семантических определений прямо в набор данных и привязки генерации SQL к бизнес-смыслу данных Dataset Q&A заметно улучшила качество и надежность инсайтов. Это улучшение дало более чем на 48 % более высокую точность ответов, снизило число сбоев запросов почти до нуля и сократило время анализа с часов до минут.
Представляем Dataset Q&A
Это стало возможным благодаря архитектурному отличию. Вместо того чтобы пропускать запросы через заранее настроенные field definitions и business rules, Dataset Q&A динамически интерпретирует намерение пользователя, определяет релевантные наборы данных и генерирует улучшенный SQL в момент запроса, что дает системе гибкость для обработки сложного многомерного анализа, с которым прежняя Topic based model не справлялась.
Команда SDL участвовала в раннем тестировании, и результаты проявились сразу. Чтобы измерить точность запросов, мы провели структурированное ground truth testing, сравнивая сгенерированные TARA ответы с вручную проверенными SQL-запросами и ожидаемыми результатами, подтвержденными аналитиками, на репрезентативном наборе реальных сценариев. Выделились три улучшения:
- Точность: точность запросов улучшилась примерно на 48 % по результатам ground truth-бенчмарков.
- Надежность: сложные аналитические вопросы, которые раньше завершались сбоем, начали выполняться успешно, а число ошибок запросов снизилось почти до нуля.
- Скорость: время ответа сократилось с минут (около 2–3 мин) до секунд (около 10 сек), то есть более чем на 90 %, что обеспечило почти мгновенное исследование данных.
Вместе эти улучшения превратили TARA из полезного помощника по отчетности в надежный инструмент поддержки решений для руководителей программ AWS.
Как начать
Перед тем как внедрять прямой dataset Q&A в своей среде, убедитесь, что у вас есть:
- Аккаунт AWS. Инструкции по настройке см. в разделе Getting Started with AWS.
- В аккаунте включена Amazon Quick Enterprise Edition как минимум с одним пользователем Enterprise и одним пользователем Professional. Подробности см. в разделе Amazon QuickSight editions and pricing.
- Понимание концепций Amazon QuickSight, таких как datasets и chat interface. Начать можно с документации Amazon QuickSight.
Технический разбор: архитектура TARA
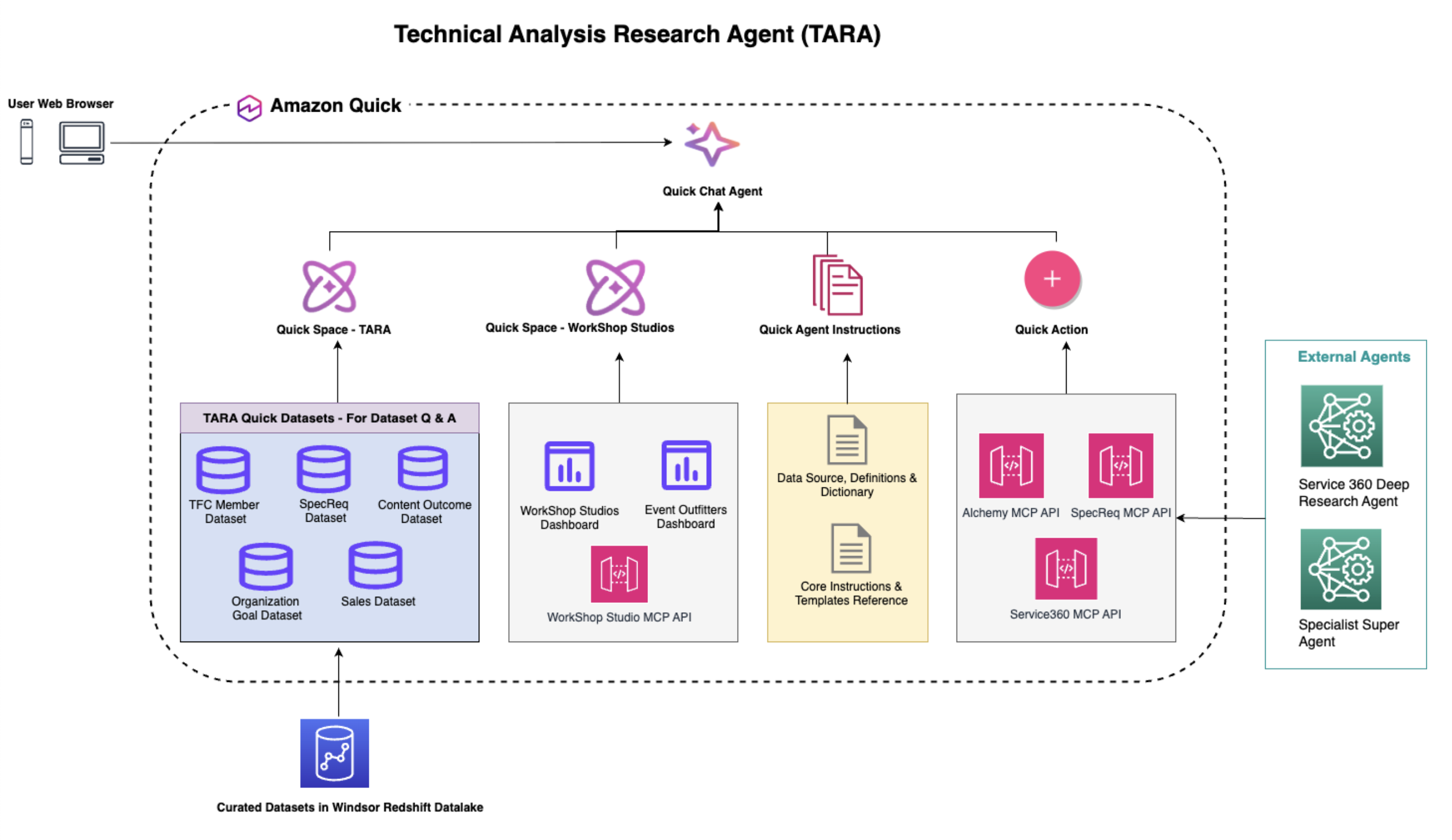
Системная архитектура и связанная интеллектуальность
Архитектура TARA построена на Amazon Quick и спроектирована так, чтобы объединить структурированную аналитику, операционные системы и институциональные знания в одном разговорном интерфейсе. В центре этого опыта находится Amazon Quick Chat Agent, который одновременно выступает точкой входа для пользователя и оркестрационным узлом для запросов. Через простой интерфейс на естественном языке руководители AWS могут получать доступ к отобранным бизнес-наборам данных, live system APIs и специализированным research agents без переключения между инструментами.
Архитектура состоит из четырех тесно связанных слоев:
1. Слой доступа пользователя и оркестрации
Пользователи взаимодействуют с TARA через web browser, используя Amazon Quick Chat Agent. Этот chat interface выступает основным клиентом для разговорной аналитики, безопасно аутентифицирует пользователей через их аккаунты AWS и направляет запросы по всей среде TARA. Он действует как интеллектуальный слой оркестрации, который определяет, следует ли отвечать на запрос с помощью структурированных дашбордов, управляемых datasets, операционных APIs или внешних agents.
2. Слой Dataset Q&A и интеграции с рабочими пространствами
Основу аналитики TARA составляют отобранные datasets, размещенные в data lake Windsor Amazon Redshift и представленные через Amazon Quick Spaces, которые организуют данные в безопасные логические домены для поиска и повторного использования между командами. Ключевая возможность TARA — использование функции Dataset Q&A в Amazon Quick, которая позволяет задавать естественным языком вопросы к операционным метрикам, показателям участников, запросам специалистов, результатам контента, организационным целям и данным по продажам. Подключая datasets напрямую к Quick Spaces, привязанным к TARA, система делает доверенные инсайты мгновенно доступными без необходимости понимать schema, dashboards или логику запросов. Основное Space TARA хранит базовые бизнес-наборы данных для операционного и performance-анализа, а отдельное Workshop Studio Space предоставляет доступ к данным о проведении workshop и event delivery через integration с dashboard и MCP. Такая межпространственная конструкция показывает, как Amazon Quick обеспечивает безопасную федерацию data assets между организационными границами при сохранении владения и governance.
3. Семантическая интеллектуальность через custom agent instructions
Ключевое отличие архитектуры TARA — слой семантической интеллектуальности, основанный на тщательно разработанных custom agent instructions. Этот слой определяет business logic, отраслевую терминологию, правила интерпретации метрик и бизнес-семантику так, чтобы ответы были контекстно точными и последовательными. Вместо того чтобы полагаться только на raw schema или имена таблиц, TARA использует reasoning на основе инструкций, чтобы интерпретировать намерение пользователя в бизнес-терминах. Например:
- «Active members» интерпретируются на основе status flags, а не membership tier
- Уровни завершения specialist request вычисляются только по завершенным обращениям, без учета отмененных requests
- «Current month» по умолчанию означает самый последний месяц с полными данными, а не текущий календарный месяц
Эти наборы инструкций работают как семантический слой перевода между бизнес-языком и базовыми структурами данных. Это критично для построения доверия к executive-facing инсайтам и для получения последовательных, надежных ответов у разных пользователей.
4. Слой связанных систем и действий
Помимо структурированной аналитики, TARA выходит в операционные workflows и глубокие исследования через Amazon Quick Actions и интеграции MCP. Этот слой действий позволяет TARA напрямую подключаться к системам, которые команды AWS уже используют, превращая ее в нечто большее, чем reporting assistant.
Текущие интеграции включают:
- Alchemy: поддерживает поиск приоритетных customer use case и курирует активы решений AWS и партнеров, ресурсы для технической валидации и sales plays.
- SpecReq: поддерживает прием, маршрутизацию, отслеживание и выполнение specialist request в рамках технических support engagement.
- Service 360 Deep Research Agent: выполняет глубокий анализ запросов на функции продукта, трендов specialist request и болевых точек клиентов, чтобы находить инсайты за пределами стандартных дашбордов.
TARA также спроектирована с учетом будущего расширения, и запланированные интеграции включают:
- Specialist Super Agent: framework AI-agents, предоставляющий техническую экспертизу по запросу более чем в 30 технологических доменах.
- InstructAI: сервис автоматизации workflows и business intelligence для данных о выручке, pipeline и производительности.
Такая многоуровневая архитектура делает TARA больше, чем традиционный аналитический помощник. Это connected intelligence system, объединяющая управляемые данные, нативную разговорную аналитику, семантическое reasoning, оперативный контекст в реальном времени и специализированные AI-возможности, чтобы помогать руководителям AWS принимать более быстрые и обоснованные решения.
Обзор решения
TARA объединяет несколько структурированных наборов данных в единый разговорный опыт аналитики через прямую возможность Dataset Q&A. Реализация состоит из четырех этапов:
Этап 1: Настройка custom chat agent
TARA настроена как custom Amazon Quick chat agent с адаптированными инструкциями, которые определяют бизнес-семантику, предметную экспертизу и поведение ответов. Как описано в предыдущем разделе об архитектуре, эти инструкции обеспечивают последовательную интерпретацию пользовательских вопросов в контексте business logic SDL. Настроенные на следующих этапах Spaces и Actions затем связываются с этим agent.
Этап 2: Подготовка и интеграция datasets
Основные аналитические datasets подключаются напрямую к Amazon Quick Space. Чтобы настроить это, перейдите в раздел Spaces на боковой панели Amazon Quick и создайте новое Space. После задания имени Space и описания его назначения добавьте соответствующие QuickSight datasets из доступных data assets. В случае TARA это семь datasets, охватывающих membership, tracking компетенций, обработку specialist request и метрики производительности, отчетность на уровне домена и данные об индивидуальном вкладе. Эти datasets сохраняют свою исходную schema, определения столбцов и типы данных, без необходимости отдельного semantic modeling. Поскольку datasets обновляются по уже существующим расписаниям, TARA постоянно запрашивает актуальные данные.
Этап 3: Интеграция действий через MCP
Чтобы расширить TARA за пределы структурированных datasets, внешние системы подключаются через Amazon Quick Actions. Эти Actions интегрируются с MCP-серверами разных систем, позволяя TARA получать live operational data и контекстную информацию в момент запроса. Чтобы настроить это, создайте новое Action в разделе Integrations в Amazon Quick, подключите его к целевому MCP server и свяжите Action с chat agent TARA.
Этап 4: Обработка запросов на естественном языке
Когда пользователь задает вопрос, Dataset Q&A engine интерпретирует намерение на естественном языке и генерирует оптимизированные SQL-запросы напрямую к подключенным datasets. Engine динамически определяет релевантные datasets, устанавливает joins и условия фильтрации, применяет агрегации и строит запрос во время выполнения. Для контекстных вопросов, требующих данных операционных систем, TARA автоматически направляет запросы к соответствующему MCP Action. Например, вопрос об уровнях завершения specialist request генерирует SQL по структурированным datasets, а запрос о недавних деталях взаимодействия с клиентом направляется к соответствующей MCP-интеграции для получения live context.
TARA в действии:
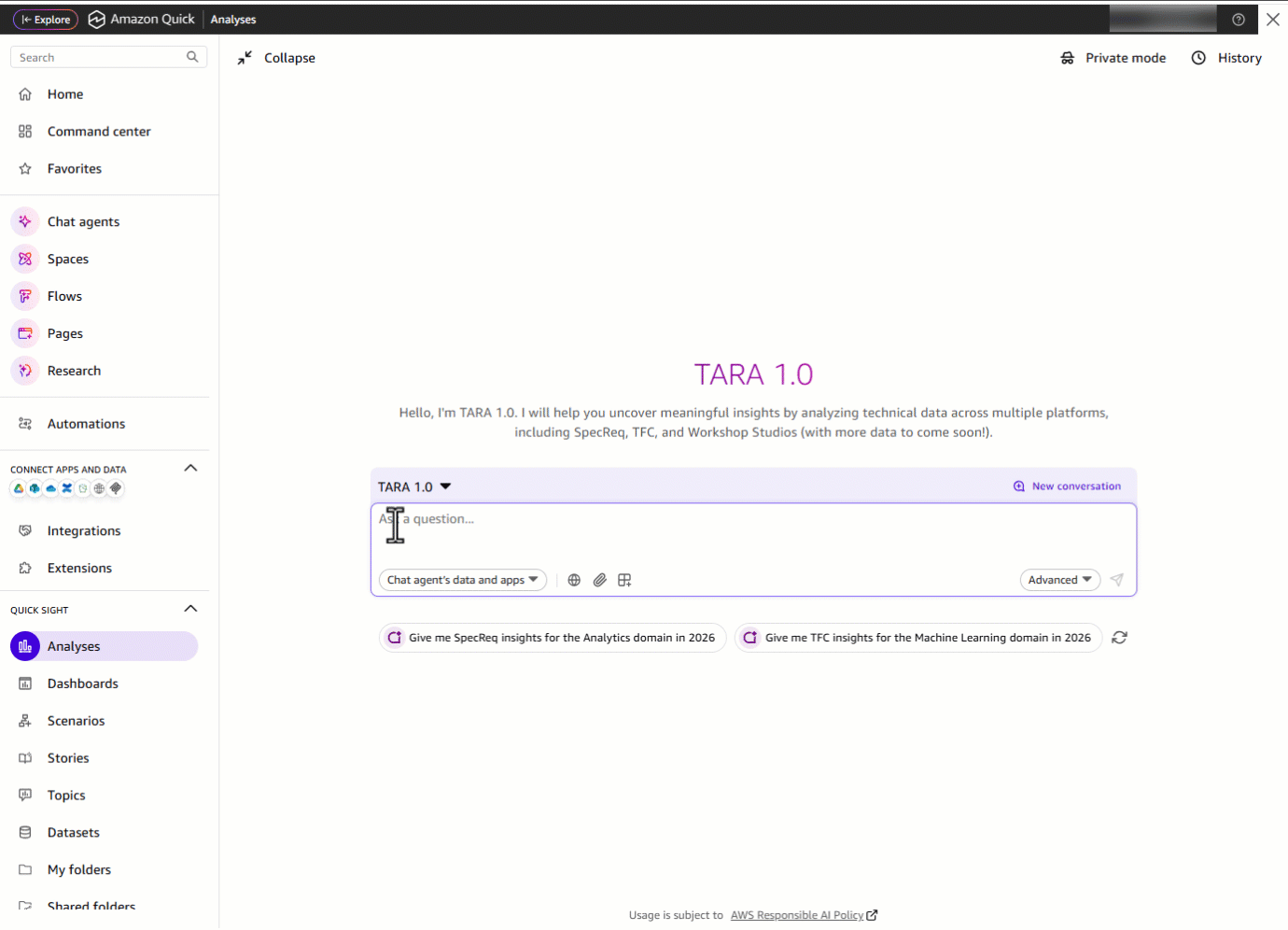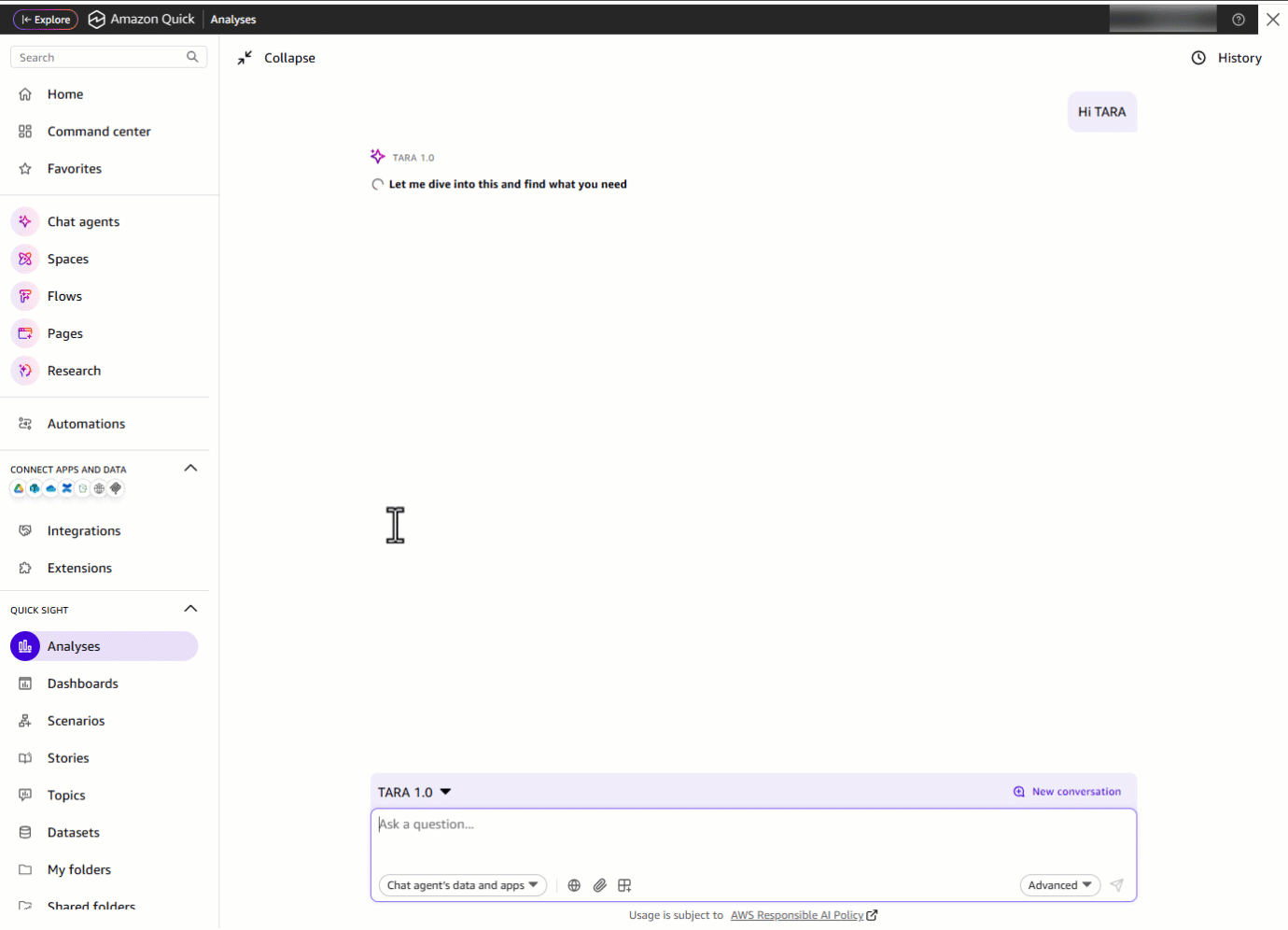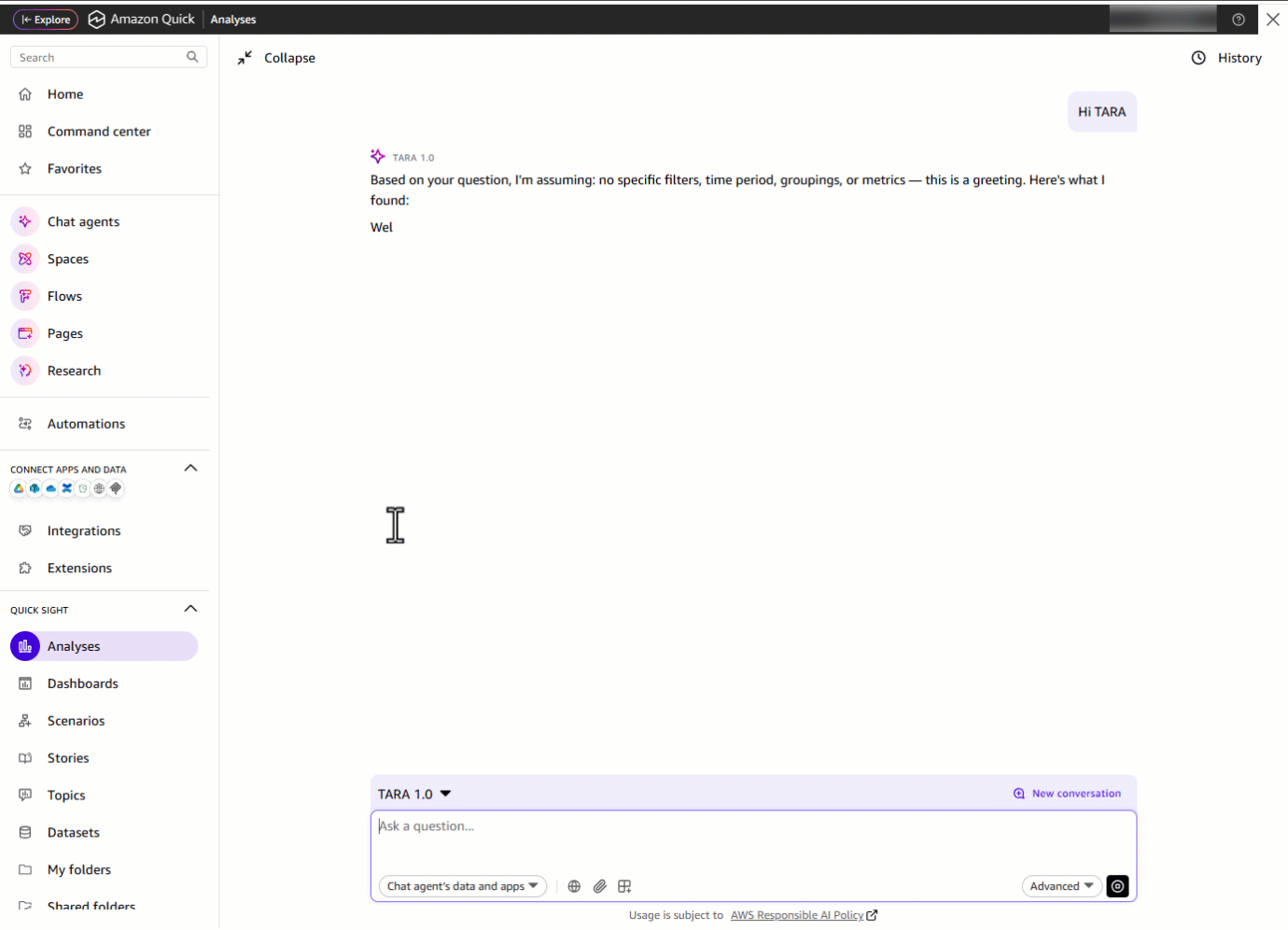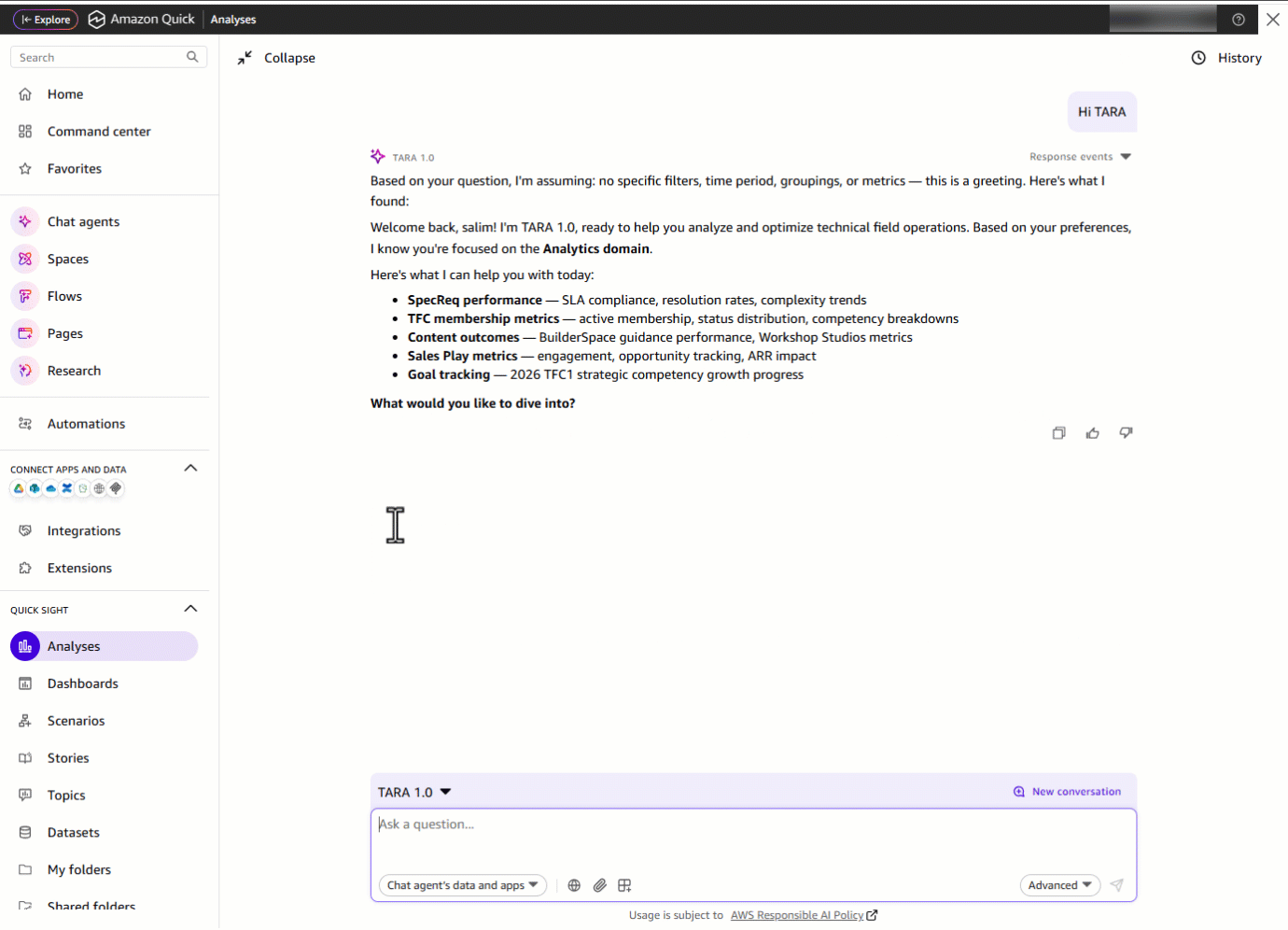
Представим руководителя домена, которому нужно оценить результаты своего технологического домена. Раньше это означало переход между несколькими вкладками дашбордов, применение фильтров и ручную сборку данных — трудоемкий процесс. С TARA весь этот workflow превращается в один диалог. Руководитель домена открывает TARA и начинает с «Hi TARA!». TARA приветствует его и сразу показывает ключевые области данных, доступные в одном месте и не только.
Введите «Hi TARA!»
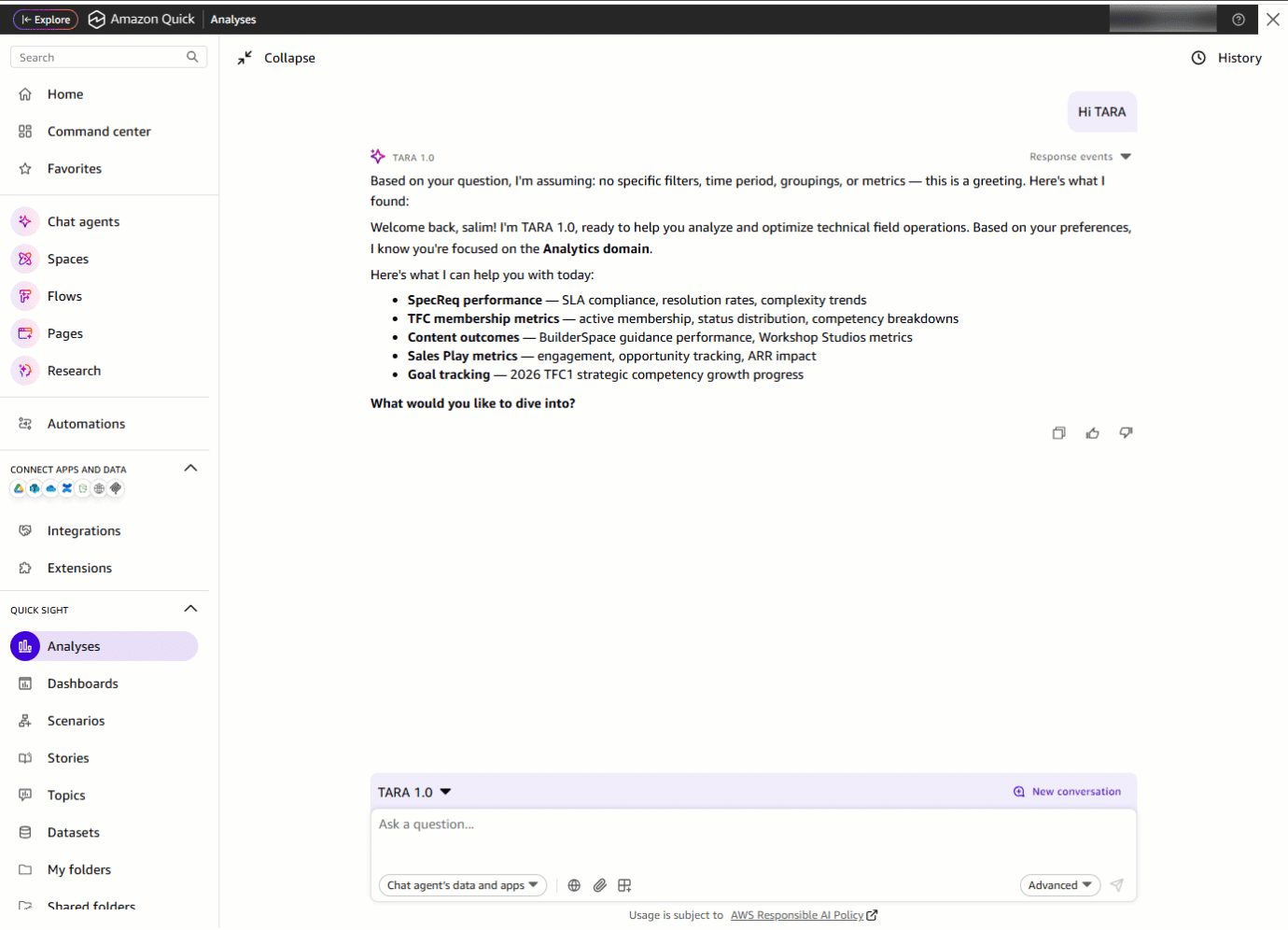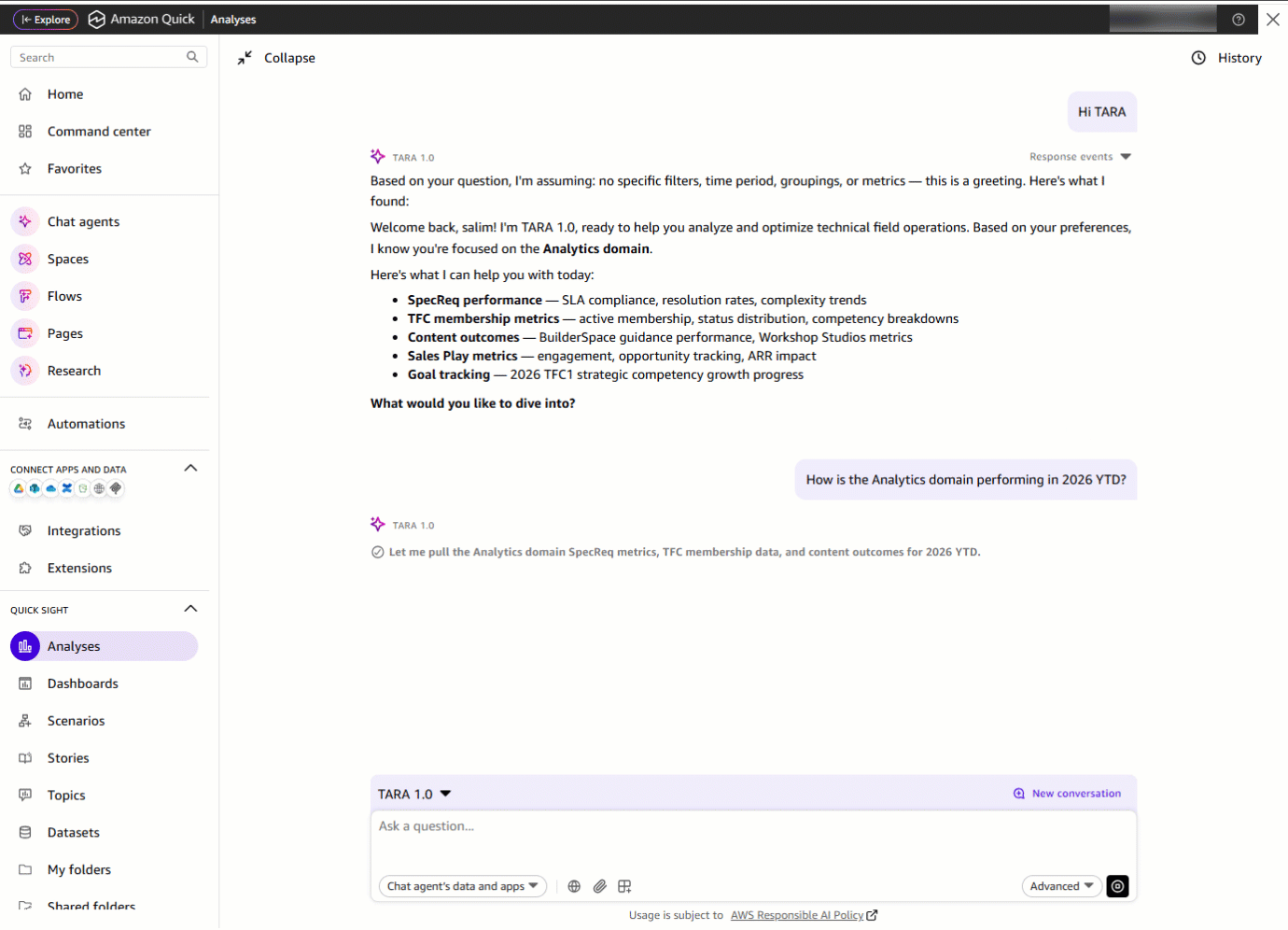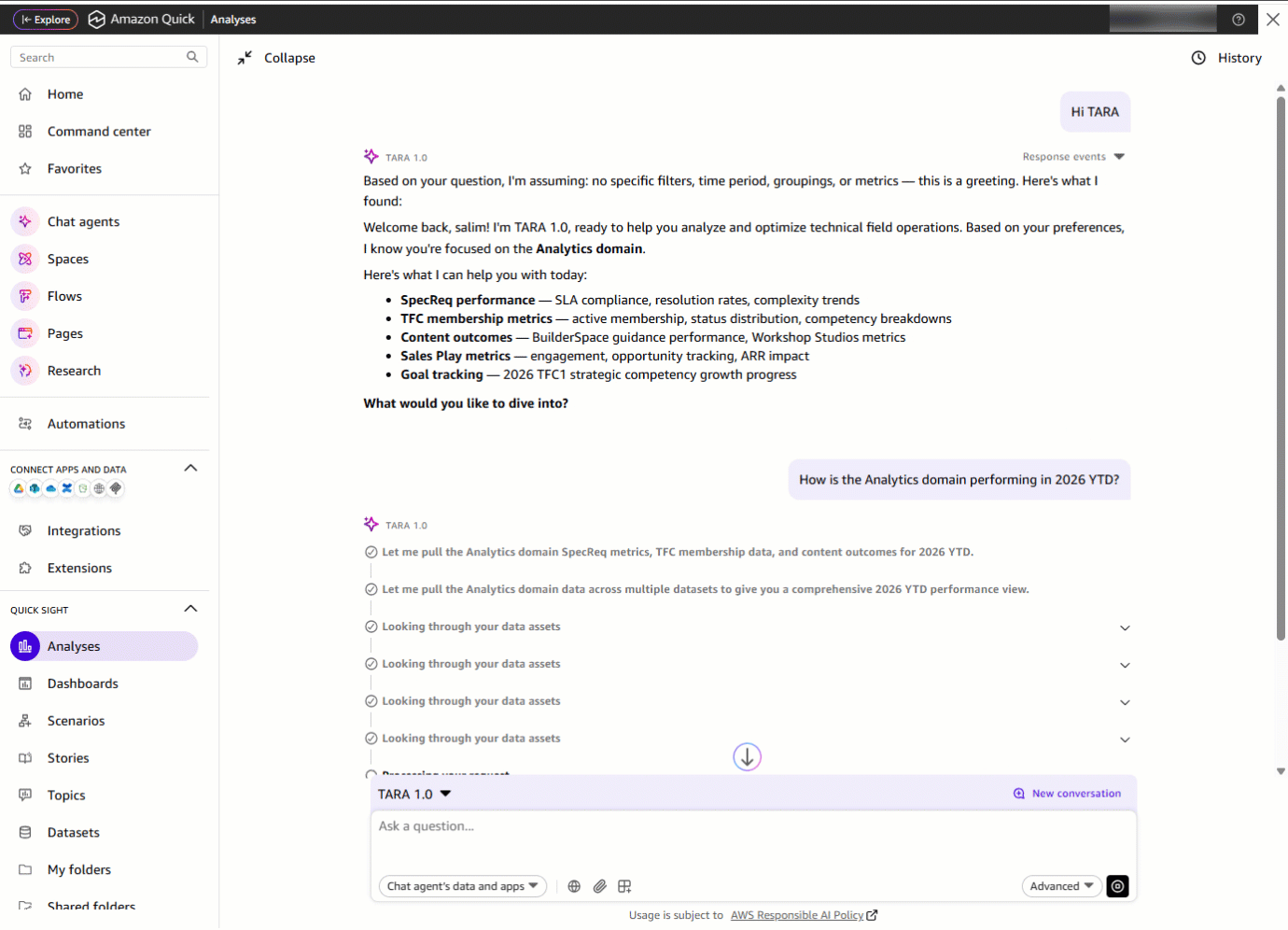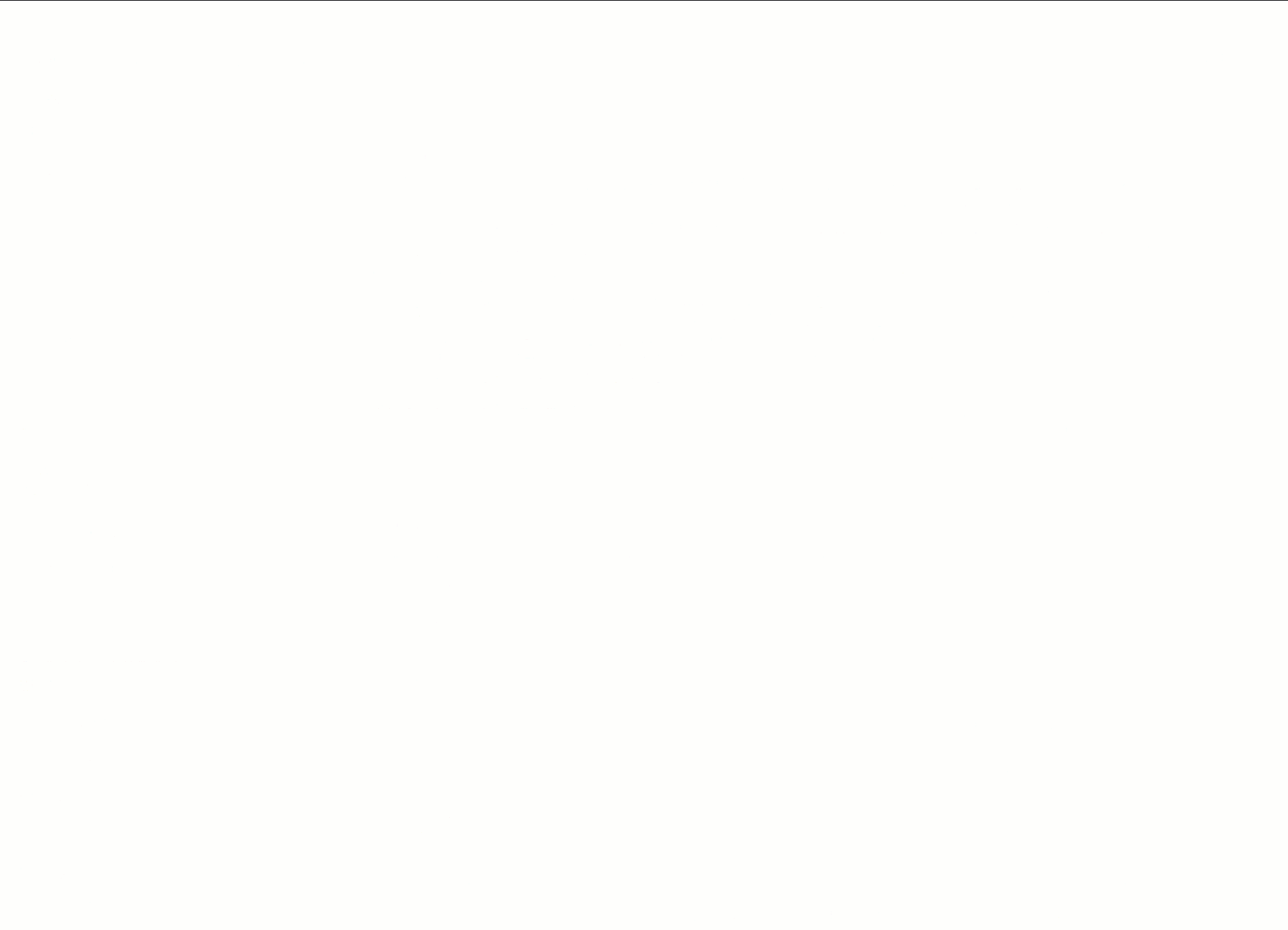
Затем он спрашивает: «How is the Analytics domain performing in 2026 YTD?» С одним запросом TARA собирает метрики из нескольких datasets. То, что раньше требовало открытия отдельных дашбордов, теперь становится единым сводным ответом, доставленным за секунды.
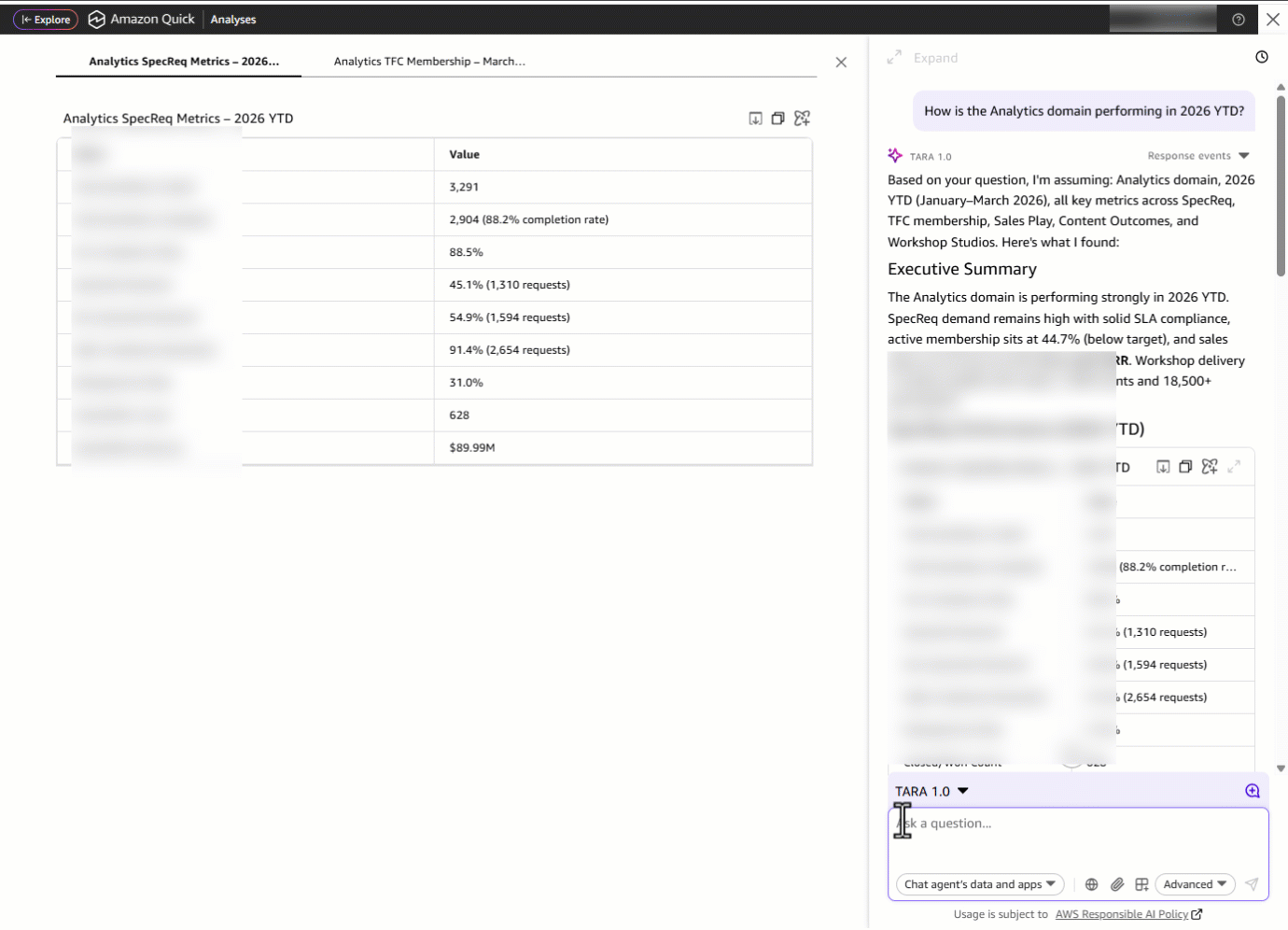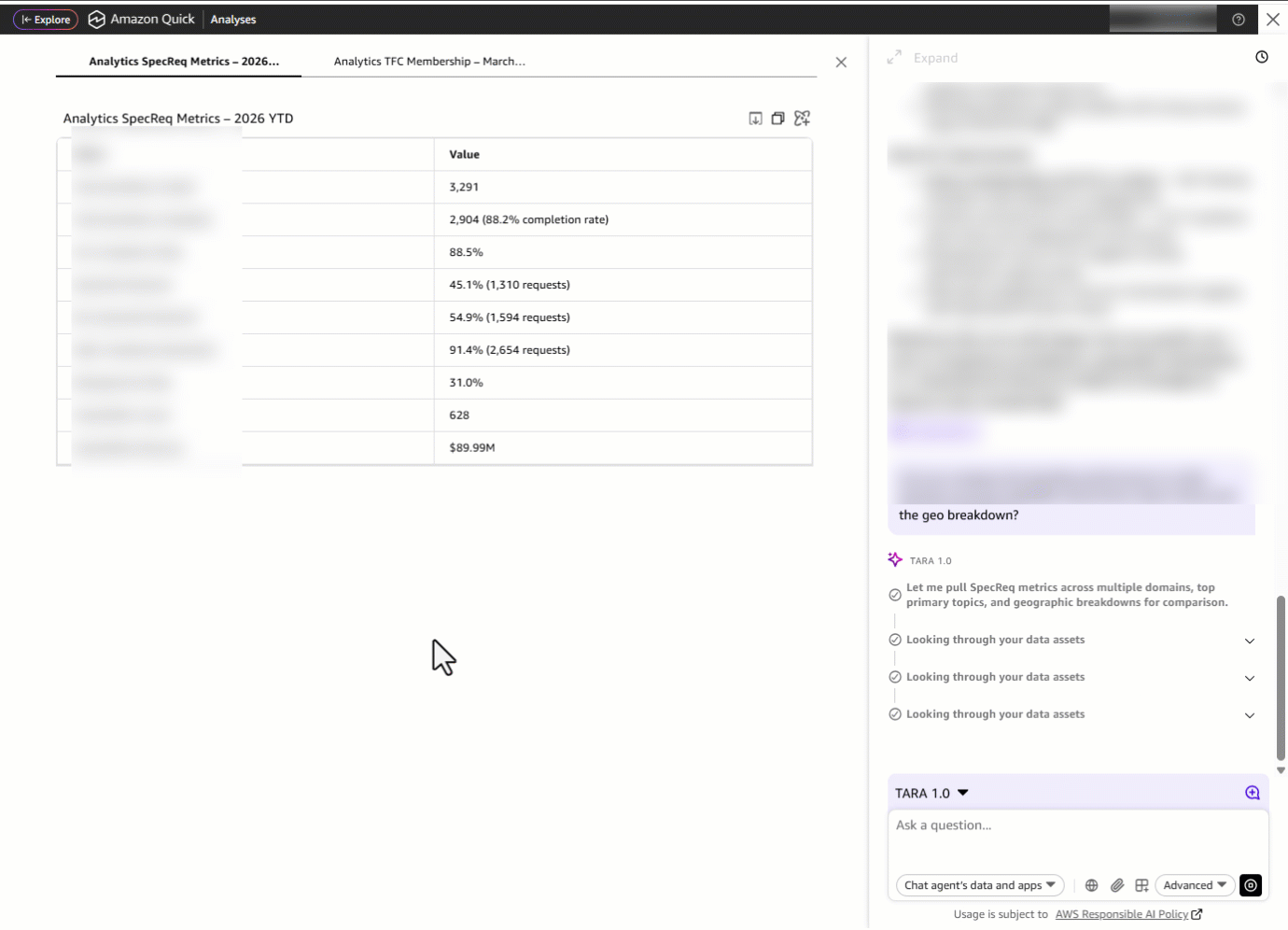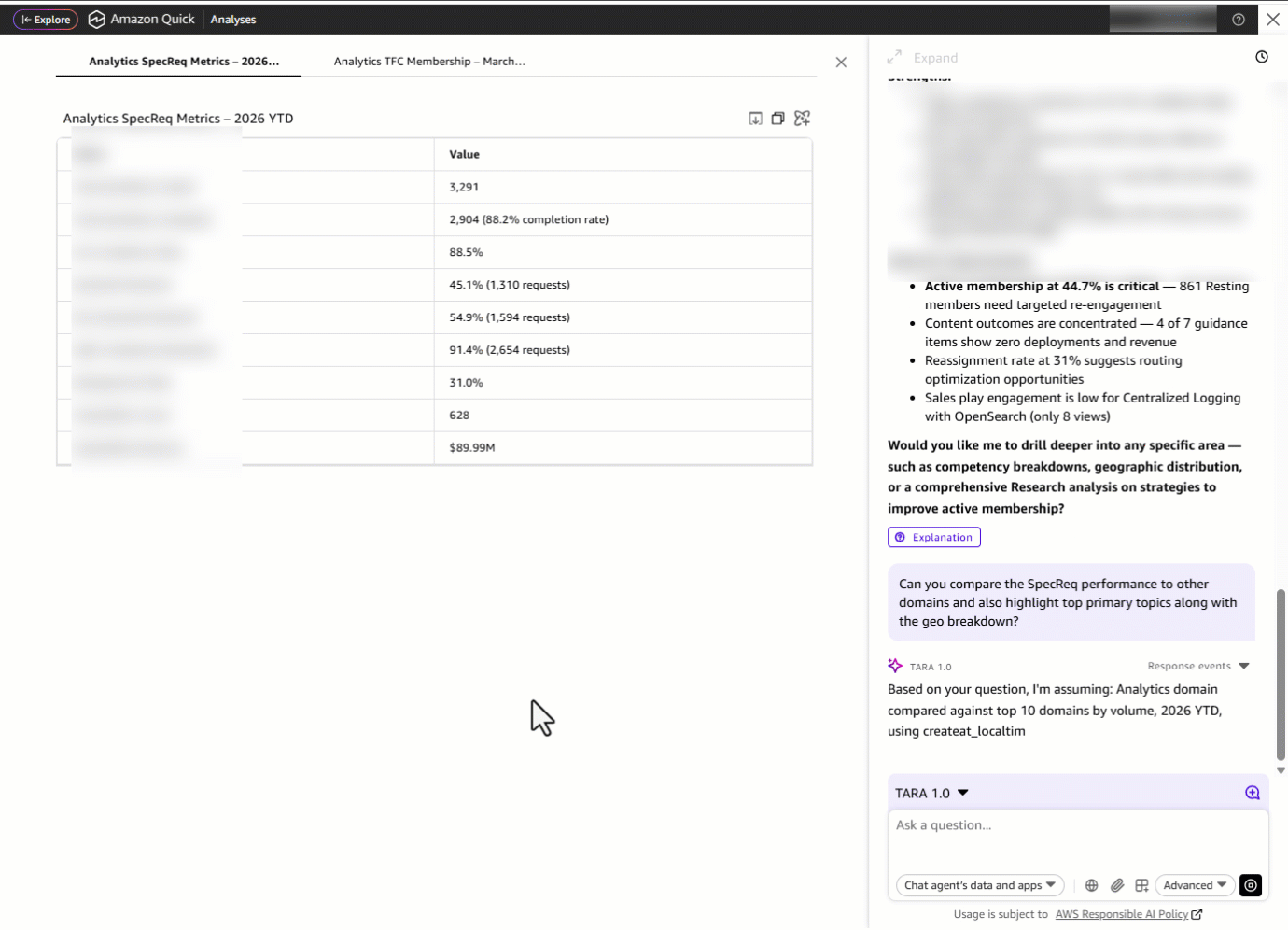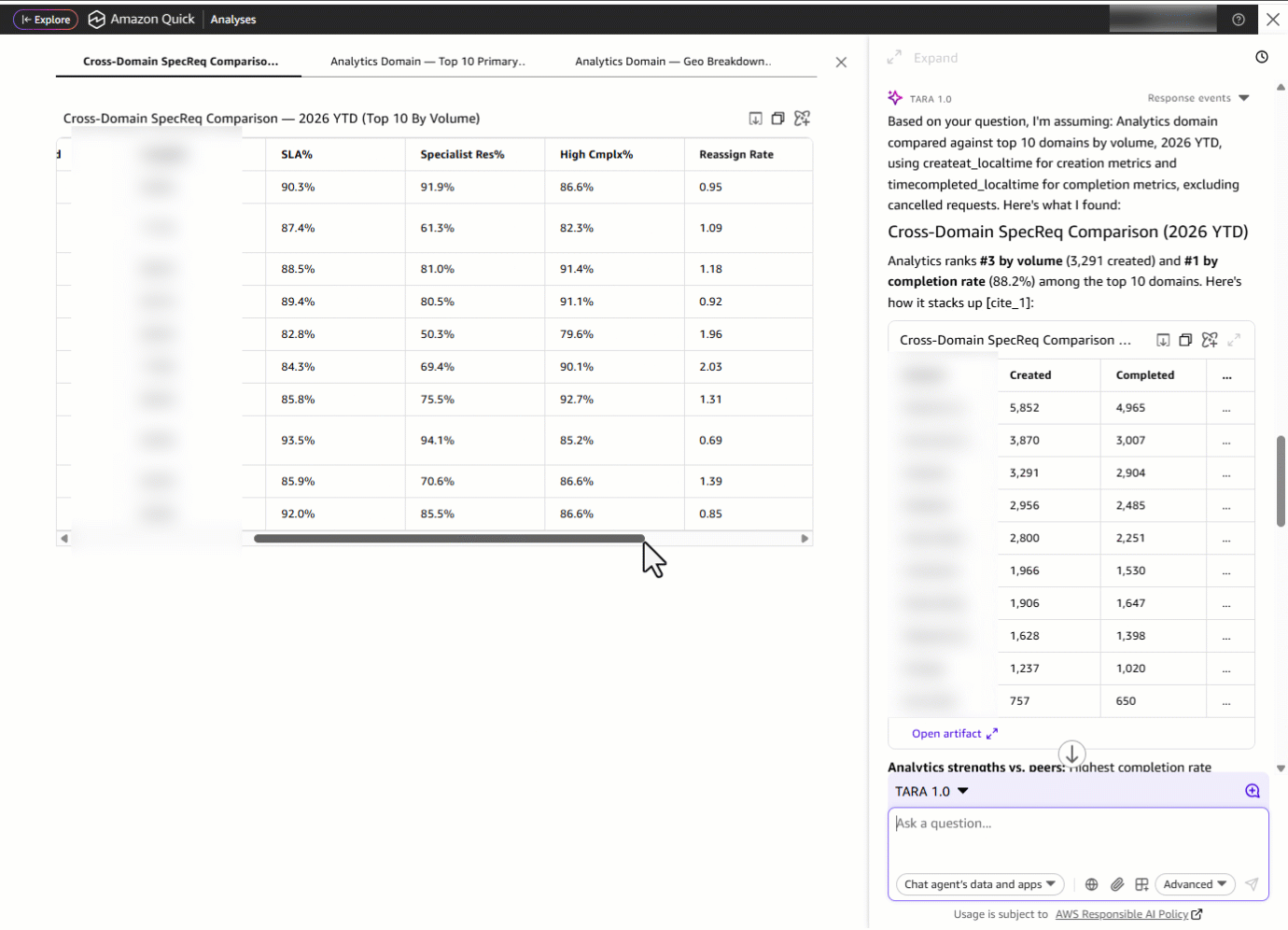
Затем он замечает, что метрика SLA показывает сильный результат — 92.7 percent. Это недавнее улучшение или стабильный уровень? Он спрашивает: «Deep dive into the SLA trends for the last 15 months.» TARA показывает помесячный тренд SLA с января 2025 — марта 2026, раскрывая, является ли текущий результат устойчивой траекторией или недавним всплеском, чтобы руководитель домена мог уверенно сообщить о прогрессе или обозначить новые риски.
Но TARA не просто показывает тренд, она показывает и то, как он был получен. Рядом с визуализацией раскрываемая панель объяснений подробно разбирает, как именно был рассчитан каждый datapoint: лежащая в основе formula (SLA Met ÷ Total SpecReqs), примененные фильтры, контекст объема и сравнения year-over-year. Такая встроенная explainability позволяет руководителю домена проследить улучшение на 3.0 percentage points до исходных данных, проверить допущения и прийти на встречу с руководством с полной уверенностью в истории, стоящей за метрикой.

Каждый ответ обеспечивается direct dataset Q&A в Amazon Quick, которая переводит естественный язык в SQL-запросы в реальном времени к исходным данным, выдавая отформатированную аналитику и визуализации за секунды.
Ключевое архитектурное отличие:
- Новые столбцы можно запрашивать сразу без обновления конфигурации
- Междатасетные запросы разрешаются автоматически на основе общих ключей и имен столбцов
- Business logic применяется контекстно, а не через жесткие предопределенные правила
- Накладные расходы на сопровождение падают почти до нуля, поскольку система органично адаптируется к изменениям schema
Такой архитектурный подход позволил TARA масштабироваться от поддержки нескольких заранее смоделированных шаблонов запросов до обработки тысяч уникальных многомерных вопросов по всему портфелю данных команды SDL.
Результаты и влияние
После внедрения direct Dataset Q&A команда SDL измерила следующие улучшения, используя сочетание системной телеметрии, структурированного ground truth testing и operational support metrics, собранных до и после запуска:
- Уровень успешного выполнения запросов: вырос с диапазона 80–85 процентов до более чем 95 процентов, исходя из доли пользовательских запросов, которые возвращали точные и пригодные к использованию ответы без необходимости переформулирования, вмешательства аналитика или ручной коррекции запроса.
- Среднее время разрешения запроса: сократилось примерно с 90 минут до менее чем 5 минут для сложных многомерных вопросов, что измерялось сравнением полного времени, необходимого для ответа на репрезентативные бизнес-вопросы до и после conversational Dataset Q&A в TARA.
- Накладные расходы на сопровождение: были обойдены 2–3 дня в месяц, которые раньше тратились на обновление семантических определений, уточнение сопоставлений и поддержку business logic для меняющихся потребностей в отчетности.
- Вовлеченность пользователей: более 15 000 участников TFC и руководителей AWS теперь получают аналитику через запросы на естественном языке, согласно активному использованию TARA.
Теперь руководители программ могут отвечать на стратегические вопросы за минуты, а не за часы. Система также справляется со сложными сценариями, для которых раньше требовались ручная агрегация данных, валидация и расчеты.
Очистка
Чтобы избежать постоянных расходов, удалите Spaces, Actions, MCP integrations, chat agents и другие Quick assets, созданные в ходе экспериментов. Инструкции см. в документации Amazon Quick.
Заключение
Прямой dataset Q&A меняет то, как пользователи работают с данными: он снимает накладные расходы на настройку и позволяет динамически генерировать запросы. Этот подход обеспечивает немедленную возможность запросов к сложным datasets без semantic modeling, применяет business logic контекстно во время выполнения, поддерживает сложный многомерный анализ через естественный язык и сохраняет соответствие корпоративным политикам безопасности — и все это при значительном снижении затрат на сопровождение. Такое архитектурное смещение позволило TARA масштабироваться от обработки заранее определенных шаблонов запросов до поддержки тысяч уникальных аналитических вопросов по всему полному портфелю данных команды SDL. Начните работу с Dataset Q&A уже сегодня, используя следующие ресурсы:
- Документация Amazon Quick
- Руководство по интеграции datasets в Amazon QuickSight
- Настройка Quick Spaces
- Запуск блога Dataset Q&A
Материал — перевод статьи с английского.
Оригинал: Beyond BI: How the Dataset Q&A feature of Amazon Quick powers the next generation of data decisions