Nova Forge SDK, часть 2: практическое руководство по дообучению Nova с data mixing

Это практическое руководство проходит все этапы дообучения модели Amazon Nova с помощью Amazon Nova Forge SDK — от подготовки данных до обучения с использованием data mixing и последующей оценки, чтобы у вас был повторяемый сценарий, который можно адаптировать под собственную задачу. Это вторая часть серии Nova Forge SDK, которая опирается на введение в SDK и первую часть, где рассматривался запуск экспериментов по кастомизации.
Главная тема этого материала — data mixing: техника, которая позволяет дообучать модель на отраслевых данных, не жертвуя ее общими возможностями. В предыдущем посте было показано, почему это важно: смешивание данных клиентов с наборами, курируемыми Amazon, сохраняло почти базовый показатель Massive Multitask Language Understanding (MMLU) и давало прирост F1 на 12 пунктов в задаче классификации Voice of Customer по 1 420 конечным категориям. Напротив, дообучение open-source модели только на клиентских данных приводило почти к полной потере общих возможностей. Ниже мы показываем, как сделать это самостоятельно.
Обзор решения
Рабочий процесс состоит из пяти этапов:
- Настройка окружения — установка Nova Forge SDK и конфигурация ресурсов AWS
- Подготовка данных — загрузка, очистка, преобразование, проверка и разбиение обучающих данных
- Конфигурация обучения — настройка среды выполнения Amazon SageMaker HyperPod, отслеживания MLflow и коэффициентов data mixing
- Обучение модели — запуск и мониторинг supervised fine-tuning с Low-Rank Adaptation (LoRA)
- Оценка модели — запуск публичных бенчмарков и доменных тестов на дообученном checkpoint
Необходимые условия
Перед началом убедитесь, что у вас есть следующее:
- Учетная запись AWS с доступом к Amazon Nova Forge
- Кластер SageMaker HyperPod, развернутый на GPU-инстансах. В этом walkthrough используются инстансы
ml.p5.48xlarge. Настройка HyperPod включает конфигурацию кластера Amazon Elastic Kubernetes Service (Amazon EKS), подготовку вычислительных узлов и создание execution roles. Подробности см. в Getting started with SageMaker HyperPod. - Приложение Amazon SageMaker MLflow для отслеживания экспериментов
- IAM role с правами для SageMaker, Amazon Simple Storage Service (Amazon S3) и Amazon CloudWatch
- Ноутбук SageMaker Studio или похожее Jupyter-окружение
С учетом стоимости: В этом walkthrough используются 4 инстанса ml.p5.48xlarge для обучения и оценки. Это высокопроизводительные GPU-инстансы. Рекомендуем начать с короткого тестового прогона (max_steps=5), чтобы проверить конфигурацию, прежде чем запускать полноценное обучение. Актуальные тарифы см. на странице Amazon SageMaker pricing page.
Шаг 1: Установите Nova Forge SDK и зависимости
SDK требует утилиты SageMaker HyperPod CLI. Скачайте и установите ее из S3-бакета дистрибутива Nova Forge, который предоставляется при подключении к Nova Forge, либо используйте следующий простой установочный скрипт, который ставит зависимости из приватного S3-бакета и создает виртуальное окружение.
# Download the HyperPod CLI Installer from Github (Only applicable for Forge)
curl –O https://github.com/aws-samples/amazon-nova-samples/blob/main/customization/nova-forge-hyperpod-cli-installation/install_hp_cli.sh
# Run the Installer
bash install_hp_cli.sh
Затем в том же виртуальном окружении установите Nova Forge SDK (nova-forge-sdk), который предоставляет высокоуровневые API для подготовки данных, обучения и оценки.
pip install --upgrade botocore awscli
pip install amzn-nova-forge
pip install datasets huggingface_hub pandas pyarrow
После установки всех зависимостей активируйте виртуальное окружение и назначьте его ядром для использования в Jupyter notebook.
source ~/hyperpod-cli-venv/bin/activate
pip install ipykernel
python -m ipykernel install --user --name=hyperpod-cli-venv --
display-name="Forge (hyperpod-cli-venv)"
jupyter kernelspec list
Проверьте установку:
from amzn_nova_forge import *
print("SDK imported successfully")
Шаг 2: Настройте ресурсы AWS
Создайте S3 bucket для обучающих данных и выходных артефактов модели. Затем предоставьте вашему HyperPod execution role доступ к нему.
import boto3
import time
import json
TIMESTAMP = int(time.time())
S3_BUCKET = f"nova-forge-customisation-{TIMESTAMP}"
S3_DATA_PATH = f"s3://{S3_BUCKET}/demo/input"
S3_OUTPUT_PATH = f"s3://{S3_BUCKET}/demo/output"
sts = boto3.client("sts")
s3 = boto3.client("s3")
ACCOUNT_ID = sts.get_caller_identity()["Account"]
REGION = boto3.session.Session().region_name
# Create the S3 bucket
if REGION == "us-east-1":
s3.create_bucket(Bucket=S3_BUCKET)
else:
s3.create_bucket(
Bucket=S3_BUCKET,
CreateBucketConfiguration={"LocationConstraint": REGION}
)
# Grant HyperPod execution role access
HYPERPOD_ROLE_ARN = f"arn:aws:iam::{ACCOUNT_ID}:role/<your-hyperpod-execution-role>
"bucket_policy = {
"Version": "2012-10-17",
"Statement": [{
"Sid": "AllowHyperPodAccess",
"Effect": "Allow",
"Principal": {"AWS": HYPERPOD_ROLE_ARN},
"Action": ["s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucket"],
"Resource": [
f"arn:aws:s3:::{S3_BUCKET}",
f"arn:aws:s3:::{S3_BUCKET}/*"
]
}]
}
s3.put_bucket_policy(Bucket=S3_BUCKET, Policy=json.dumps(bucket_policy))
Шаг 3: Подготовьте обучающий набор данных
Nova Forge SDK поддерживает форматы JSONL, JSON и CSV. В этом walkthrough мы используем общедоступный набор данных MedReason из Hugging Face. Набор содержит медицинские рассуждения и примерно 32 700 пар вопрос-ответ, чтобы показать дообучение для доменного сценария.
Скачайте и очистите данные
Nova Forge SDK выполняет валидацию на уровне токенов для обучающих данных. Некоторые токены конфликтуют с внутренним chat template модели, в частности специальные разделители, которые Nova использует для отделения системных, пользовательских и ассистентских ходов во время обучения. Если ваши данные содержат буквальные строки вроде System: или Assistant:, модель может интерпретировать их как границы ходов, что исказит обучающий сигнал. Ниже приведенный шаг очистки вставляет пробел перед двоеточием, например System: → System :, чтобы разорвать совпадение с шаблоном, сохраняя читаемость, и удаляет специальные токены вроде [EOS] и <image>, которые имеют зарезервированное значение в словаре модели.
from huggingface_hub import hf_hub_download
import pandas as pd
import json
import re
Скачайте набор данных jsonl_path = hf_hub_download( repo_id=”UCSC-VLAA/MedReason”, filename=”ours_quality_33000.jsonl”, repo_type=”dataset”, local_dir=”.” ) df = pd.read_json(jsonl_path, lines=True)
Токены, конфликтующие с chat template модели INVALID_TOKENS = [ “System:”, “SYSTEM:”, “User:”, “USER:”, “Bot:”, “BOT:”, “Assistant:”, “ASSISTANT:”, “Thought:”, “[EOS]”, “<image>”, “<video>”, “<unk>”, ]
def sanitize_text(text):
for token in INVALID_TOKENS:
if “:” in token:
word = token[:-1]
text = re.sub(rf’\b{word}:’, f'{word} :’, text, flags=re.IGNORECASE)
else:
text = text.replace(token, “”)
return text.strip()
Запишите очищенный JSONL with open(“training_data.jsonl”, “w”) as f: for _, row in df.iterrows(): f.write(json.dumps({ “question”: sanitize_text(row[“question”]), “answer”: sanitize_text(row[“answer”]), }) + “\n”)
print(f”Dataset saved: training_data.jsonl ({len(df)} examples)”)
Чтобы проверить, содержит ли ваш набор данных какие-либо зарезервированные ключевые слова, запустите этот скрипт.
Загрузите, преобразуйте и проверьте данные с помощью SDK
SDK предоставляет JSONLDatasetLoader, который преобразует ваши сырые данные в структуру, ожидаемую моделями Nova. Когда вы вызываете transform(), SDK оборачивает каждую пару вопрос-ответ в формат Nova chat template — структурированный формат с ходами диалога, который модели Nova ожидают во время обучения. Ваши сырые данные из простых пар Q&A превращаются в полностью оформленные многоходовые диалоги с нужными role tags и разделителями.
До transform (ваш исходный JSONL):
{
"question": "What are the causes of chest pain in a 45-year-old patient?",
"answer": "Chest pain in a 45-year-old can result from cardiac causes such as..."
}
После transform (формат Nova chat template):
{
"messages": [
{"role": "user", "content": "What are the causes of chest pain in a 45-year-old patient?"},
{"role": "assistant", "content": "Chest pain in a 45-year-old can result from cardiac causes such as..."}
]
}
Метод validate() затем проверяет преобразованные данные на наличие проблем, убеждаясь, что структура chat template корректна, что не осталось недопустимых токенов и что данные соответствуют требованиям выбранной модели и метода обучения.
# Initialize the loader, mapping your column names
loader = JSONLDatasetLoader(
question="question",
answer="answer",
)
loader.load("training_data.jsonl")
# Preview raw data
loader.show(n=3)
# Transform into Nova's expected chat template format
loader.transform(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
# Preview transformed data to verify the structure
loader.show(n=3)
# Validate — prints "Validation completed" if successful
loader.validate(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
train_path = loader.save(f"{S3_DATA_PATH}/train.jsonl")
print(f"Training data: {train_path}")
Шаг 4: Настройте и запустите обучение с data mixing
Когда вы включаете data mixing, Nova Forge автоматически смешивает ваши отраслевые обучающие данные с наборами, курируемыми Amazon, во время дообучения. Это помогает модели не забыть общие способности, пока она осваивает вашу предметную область.
Примечание о методах обучения: LoRA против full-rank SFT
Nova Forge поддерживает несколько подходов к fine-tuning. В этом walkthrough мы используем supervised fine-tuning (SFT) с LoRA (TrainingMethod.SFT_LORA) — параметрически эффективный метод, который обновляет только небольшой набор low-rank adapter weights, а не все параметры модели. LoRA дает более быстрое обучение, более низкие вычислительные затраты и является рекомендуемой отправной точкой для большинства сценариев.
Nova Forge также поддерживает full-rank SFT, при котором обновляются все параметры модели и может быть усвоено больше знаний из предметной области. Однако этот подход требует больше вычислений и более подвержен catastrophic forgetting, поэтому data mixing становится еще важнее. Предыдущий пост этой серии показывает результаты с full-rank SFT. Выбирайте full-rank, когда LoRA не дает достаточного качества на доменной задаче или когда нужна более глубокая адаптация модели.
Настройте runtime и MLflow
from amzn_nova_customization_sdk.model.model_enums import Platform
cluster_name = "nova-forge-hyperpod"
instance_type = "ml.p5.48xlarge"
instance_count = 4
namespace = "kubeflow"
runtime = SMHPRuntimeManager(
instance_type=instance_type,
instance_count=instance_count,
cluster_name=cluster_name,
namespace=namespace,
)
MLFLOW_APP_ID = "<your-mlflow-app-id>" # e.g., "app-XXXXXXXXXXXX"
mlflow_app_arn = f"arn:aws:sagemaker:{REGION}:{ACCOUNT_ID}:mlflow-app/{MLFLOW_APP_ID}"
mlflow_monitor = MLflowMonitor(
tracking_uri=mlflow_app_arn,
experiment_name="nova-sft-datamix",
)
Создайте customizer с включенным data mixing
Передайте data_mixing_enabled=True при создании NovaModelCustomizer:
customizer = NovaModelCustomizer(
model=Model.NOVA_LITE_2,
method=TrainingMethod.SFT_LORA,
infra=runtime,
data_s3_path=f"{S3_DATA_PATH}/train.jsonl",
output_s3_path=f"{S3_OUTPUT_PATH}/",
mlflow_monitor=mlflow_monitor,
data_mixing_enabled=True,
)
Поймите и настройте конфигурацию data mixing
Data mixing управляет тем, как формируются обучающие батчи. Параметр customer_data_percent определяет, какая доля каждого батча берется из ваших доменных данных. Остальная часть заполняется наборами, курируемыми Nova, причем каждый параметр nova_*_percent управляет относительным весом соответствующей категории возможностей внутри доли Nova.
Например, при конфигурации ниже:
- 50% каждого обучающего батча составляют ваши доменные данные
- 50% составляют данные Nova, распределенные по категориям возможностей в соответствии с их относительными весами
Проценты стороны Nova должны в сумме давать 100. Каждое значение показывает долю этой категории в части батча, которая относится к данным Nova.
# View the default mixing ratios
customizer.get_data_mixing_config()
Вы можете изменить эти соотношения в зависимости от приоритетов:
customizer.set_data_mixing_config({
"customer_data_percent": 50,
"nova_agents_percent": 1,
"nova_baseline_percent": 10,
"nova_chat_percent": 0.5,
"nova_factuality_percent": 0.1,
"nova_identity_percent": 1,
"nova_long-context_percent": 1,
"nova_math_percent": 2,
"nova_rai_percent": 1,
"nova_instruction-following_percent": 13,
"nova_stem_percent": 10.5,
"nova_planning_percent": 10,
"nova_reasoning-chat_percent": 0.5,
"nova_reasoning-code_percent": 0.5,
"nova_reasoning-factuality_percent": 0.5,
"nova_reasoning-instruction-following_percent": 45,
"nova_reasoning-math_percent": 0.5,
"nova_reasoning-planning_percent": 0.5,
"nova_reasoning-rag_percent": 0.4,
"nova_reasoning-rai_percent": 0.5,
"nova_reasoning-stem_percent": 0.4,
"nova_rag_percent": 1,
"nova_translation_percent": 0.1,
})
Как думать о настройке смеси
| Параметр | Что он контролирует | Рекомендация |
customer_data_percent |
Доля ваших доменных данных в каждом обучающем батче. | Более высокие значения усиливают специализацию под домен, но повышают риск забывания. 50% — сбалансированная стартовая точка. |
nova_instruction-following_percent |
Вес примеров instruction-following в части Nova. | Держите этот показатель высоким, если модель должна выполнять структурированные запросы или форматы вывода в продакшене. |
nova_reasoning-*_percent |
Веса для различных возможностей reasoning — math, code, planning и т. д. | Увеличивайте их, если ваши downstream-задачи требуют многошагового reasoning. |
nova_rai_percent |
Данные выравнивания Responsible AI. | Всегда оставляйте это значение ненулевым, чтобы сохранить безопасное поведение. |
nova_baseline_percent |
Базовые фактические знания. | Помогает сохранять широкие знания о мире. |
Совет: Начните со значений по умолчанию, запустите обучение, оцените результат и на доменной задаче, и по MMLU, а затем итеративно корректируйте. Пост Building specialized AI without sacrificing intelligence показывает, что даже соотношение 75/25 между клиентскими и Nova-данными сохраняет почти базовый уровень MMLU (0.74 против базовых 0.75), одновременно давая прирост F1 на 12 пунктов в сложной задаче классификации.
Запустите обучение
Параметр overrides позволяет управлять ключевыми гиперпараметрами обучения:
| Параметр | Описание | Рекомендация |
lr |
Скорость обучения | 1e-5 — разумное значение по умолчанию для LoRA fine-tuning. |
warmup_steps |
Шаги линейного разгона learning rate от 0 | Обычно 5–10% от общего числа шагов. Подбирайте пропорционально max_steps. |
global_batch_size |
Число примеров на одно обновление градиента на всех GPU | Большие батчи дают более стабильные градиенты, но требуют больше памяти. |
max_length |
Максимальная длина последовательности в токенах | Задавайте по данным. 65536 подходит для long-context use cases; уменьшайте для более коротких данных, чтобы экономить память и ускорять обучение. |
max_steps |
Общее число шагов обучения | Начните с малого (5–10), чтобы проверить настройку, затем увеличивайте. Для примерно 23 тыс. обучающих примеров при batch size 32 один полный epoch ≈ 720 шагов. |
training_config = {
"lr": 1e-5,
"warmup_steps": 2,
"global_batch_size": 32,
"max_length": 65536,
"max_steps": 5, # Start small to validate; increase for production runs
}
training_result = customizer.train(
job_name="nova-forge-sft-datamix",
overrides=training_config,
)
training_result.dump("training_result.json")
print("Training result saved")
Следите за прогрессом обучения
Следить за задачей можно через SDK или CloudWatch:
# Check job status
print(training_result.get_job_status())
# Stream recent logs
customizer.get_logs(limit=50, start_from_head=False)
# Or use the CloudWatch monitor
monitor = CloudWatchLogMonitor.from_job_result(training_result)
monitor.show_logs(limit=10)
# Poll until completion
import time
while training_result.get_job_status()[1] == "Running":
time.sleep(60)
Метрики обучения, включая кривые loss и расписание learning rate, также доступны в вашем MLflow experiment для визуализации и сравнения между запусками.
Шаг 5: Оцените дообученную модель
Оценка критически важна при использовании data mixing, потому что нужно одновременно измерять две вещи: улучшилась ли модель на вашей доменной задаче и сохранила ли она общие возможности. Если измерять только одно направление, нельзя понять, работает ли смесь. После завершения обучения получите путь к checkpoint модели из output manifest:
from amzn_nova_forge.util.checkpoint_util import extract_checkpoint_path_from_job_output
checkpoint_path = extract_checkpoint_path_from_job_output(
output_s3_path=training_result.model_artifacts.output_s3_path,
job_result=training_result,
)
Настройте инфраструктуру оценки
Для оценки нужен только один GPU-инстанс, тогда как для обучения использовались 4:
eval_infra = SMHPRuntimeManager(
instance_type=instance_type,
instance_count=1,
cluster_name=cluster_name,
namespace=namespace,
)
eval_mlflow = MLflowMonitor(
tracking_uri=mlflow_app_arn,
experiment_name="nova-forge-eval",
)
evaluator = NovaModelCustomizer(
model=Model.NOVA_LITE_2,
method=TrainingMethod.EVALUATION,
infra=eval_infra,
output_s3_path=f"s3://{S3_BUCKET}/demo/eval-outputs/",
mlflow_monitor=eval_mlflow,
)
Запустите оценки
Nova Forge поддерживает три взаимодополняющих подхода к оценке:
1. Публичные бенчмарки (используются для измерения сохранения общих возможностей)
Они показывают, выполняет ли data mixing свою работу. Если MMLU заметно падает относительно базового уровня, в смеси недостаточно данных Nova. Если падает IFEval, увеличьте вес instruction-following.
# MMLU — broad knowledge and reasoning across 57 subjects
mmlu_result = evaluator.evaluate(
job_name="eval-mmlu",
eval_task=EvaluationTask.MMLU,
model_path=checkpoint_path,
)
# IFEval — ability to follow structured instructions
ifeval_result = evaluator.evaluate(
job_name="eval-ifeval",
eval_task=EvaluationTask.IFEVAL,
model_path=checkpoint_path,
)
2. Bring-your-own-data (измерение качества на доменной задаче)
Используйте отложенный тестовый набор, чтобы проверить, улучшило ли дообучение качество на реальной задаче:
byod_result = evaluator.evaluate(
job_name="eval-byod",
eval_task=EvaluationTask.GEN_QA,
data_s3_path=f"s3://{S3_DATA_PATH}/eval/gen_qa.jsonl",
model_path=checkpoint_path,
overrides={"max_new_tokens": 2048},
)
3. LLM как судья (для доменов, где автоматические метрики недостаточны, можно использовать другую LLM для оценки качества ответа)
Проверьте результаты и получите артефакты
# Check job status
print(mmlu_result.get_job_status())
print(ifeval_result.get_job_status())
print(byod_result.get_job_status())
# Retrieve the S3 path containing detailed evaluation results
print(mmlu_result.eval_output_path)
Путь к результатам оценки содержит подробные результаты в JSON. Скачайте и изучите их, чтобы увидеть фактические оценки.
Кроме того, метрики можно публиковать на MLflow tracking servers, если при создании задания указать URI сервера отслеживания. Так можно сохранять и сравнивать метрики между экспериментами.
Как интерпретировать результаты
Используйте следующую схему принятия решений для следующей итерации:
| Наблюдение | Что это означает | Что изменить |
| MMLU близок к базовому уровню (например, в пределах 0.01–0.02) | Data mixing успешно предотвращает catastrophic forgetting | Смесь работает — сосредоточьтесь на доменной производительности |
| MMLU заметно ухудшился | Модель забывает общие способности | Уменьшите customer_data_percent или увеличьте веса данных Nova |
| Качество на доменной задаче ниже ожиданий | Модель недостаточно учится на ваших данных | Увеличьте customer_data_percent, добавьте больше обучающих данных или увеличьте max_steps |
| IFEval ухудшился | Модель теряет способность следовать инструкциям | Увеличьте nova_instruction-following_percent |
| И MMLU, и доменная задача улучшились | Идеальный результат | Задокументируйте конфигурацию и переводите в production |
Для ориентира в этом посте приводятся результаты для Amazon Nova 2 Lite на задаче классификации VOC:
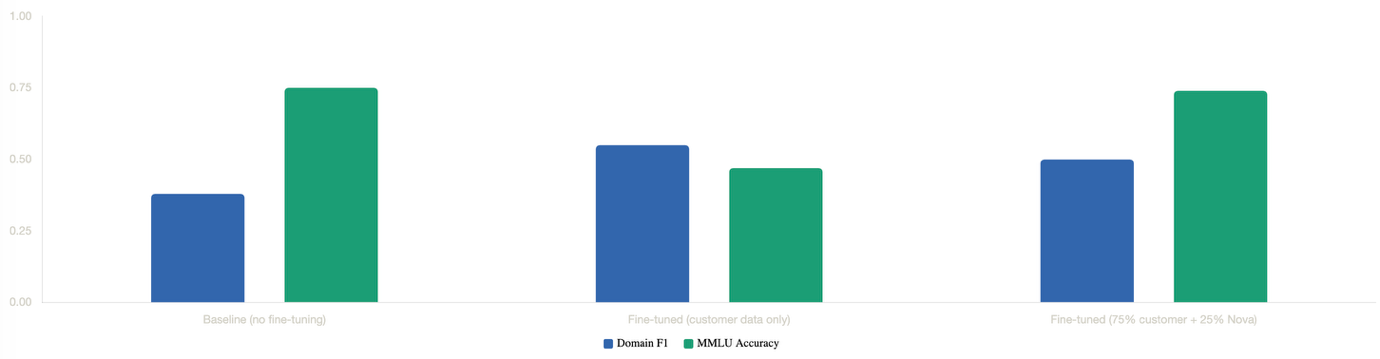
Главный вывод в том, что дообучение только на клиентских данных повышает Domain F1, но существенно снижает общий интеллект (MMLU падает с 0.75 до 0.47), тогда как смешанный подход (75% клиентских + 25% данных Nova) восстанавливает почти всю точность MMLU и при этом улучшает качество на доменной задаче.
Лучшие практики
- Начинайте с настроек смешивания по умолчанию. Значения по умолчанию подобраны для сбалансированного компромисса. Меняйте их только после того, как у вас будут базовые результаты для сравнения.
- Оценивайте модель по обеим осям. Запускайте как минимум один публичный бенчмарк (MMLU) вместе с доменной оценкой. Без обоих измерений нельзя понять, работает ли смесь.
- Используйте MLflow для сравнения экспериментов. При итерациях по коэффициентам смешивания и гиперпараметрам MLflow упрощает сравнение запусков и поиск лучшей конфигурации.
- Итеративно меняйте смесь, а не только гиперпараметры. Если модель забывает общие способности, настройка data mix часто эффективнее, чем подстройка learning rate или batch size.
- Начинайте с LoRA, переходите к full-rank только при необходимости. LoRA быстрее и дешевле. Переходите к full-rank SFT только если LoRA не дает достаточной адаптации под домен.
Очистка ресурсов
Чтобы избежать дальнейших расходов, удалите ресурсы, созданные в ходе этого walkthrough:
- Удалите S3 bucket и его содержимое.
- Остановите или удалите кластер SageMaker HyperPod, если он создавался для этого упражнения.
- Удалите приложение MLflow, если оно больше не нужно.
Заключение
В этом посте мы прошли end-to-end workflow дообучения моделей Amazon Nova с помощью Nova Forge SDK при включенном data mixing. SDK берет на себя подготовку данных, оркестрацию обучения на SageMaker HyperPod и многомерную оценку, чтобы вы могли сосредоточиться на своих данных и своей предметной области. Data mixing делает fine-tuning практичным для production. Вместо выбора между доменной экспертизой и общим интеллектом вы получаете и то, и другое. Важно подходить к этому итеративно: обучить, оценить по обеим осям, скорректировать смесь и повторять до тех пор, пока не найдете нужный баланс для своего сценария.
Чтобы начать, см. Nova Forge Developer Guide с подробной документацией и Nova Forge SDK с полной ссылкой на API.
Материал — перевод статьи с английского.