Обучение LLM с Databricks Unity Catalog и Amazon SageMaker AI

Когда вы дообучаете большие языковые модели (LLM) в Amazon SageMaker AI и одновременно используете Databricks Unity Catalog, возникают особые задачи: как сохранить строгую управляемость данных и при этом использовать лучшие ML-сервисы.
Unity Catalog управляет метаданными и разрешениями, а сами данные в среде AWS для Databricks Workspace хранятся в Amazon Simple Storage Service (Amazon S3). Когда к этим данным обращается SageMaker AI Training job, важно не обходить модель тонкой авторизации Unity Catalog. Без структурированного шаблона интеграции возникают несогласованное применение политик, пробелы в аудите и риски для комплаенса. Например, если задачи обучения SageMaker AI читают объекты S3 в обход авторизации Unity Catalog, вы теряете видимость того, какие данные использовались для обучения каких моделей. Для регулируемых отраслей и production-нагрузок это особенно критично.
В этом материале показано, как построить безопасный и полноценный рабочий процесс дообучения LLM, который связывает Unity Catalog с Amazon SageMaker AI и использует Amazon EMR Serverless для предварительной обработки. Решение демонстрирует, как безопасно получать доступ к управляемым данным, сохранять сквозную lineage между сервисами, дообучать модель Ministral-3-3B-Instruct и регистрировать обученные артефакты обратно в Unity Catalog. Такой подход позволяет продолжать использовать существующие сервисы, сохраняя централизованное управление и отслеживание lineage без ущерба для требований безопасности и комплаенса.
Обзор решения
Этот workflow решает следующие задачи:
- Читает обучающие данные из таблицы под управлением Unity Catalog с корректными механизмами governance
- Предварительно обрабатывает данные с помощью EMR Serverless и Apache Spark
- Дообучает модель Ministral-3-3B-Instruct с использованием задач обучения SageMaker AI Training jobs
- Отслеживает lineage данных в Unity Catalog от исходных данных до обученной модели
Следующая диаграмма показывает архитектуру:
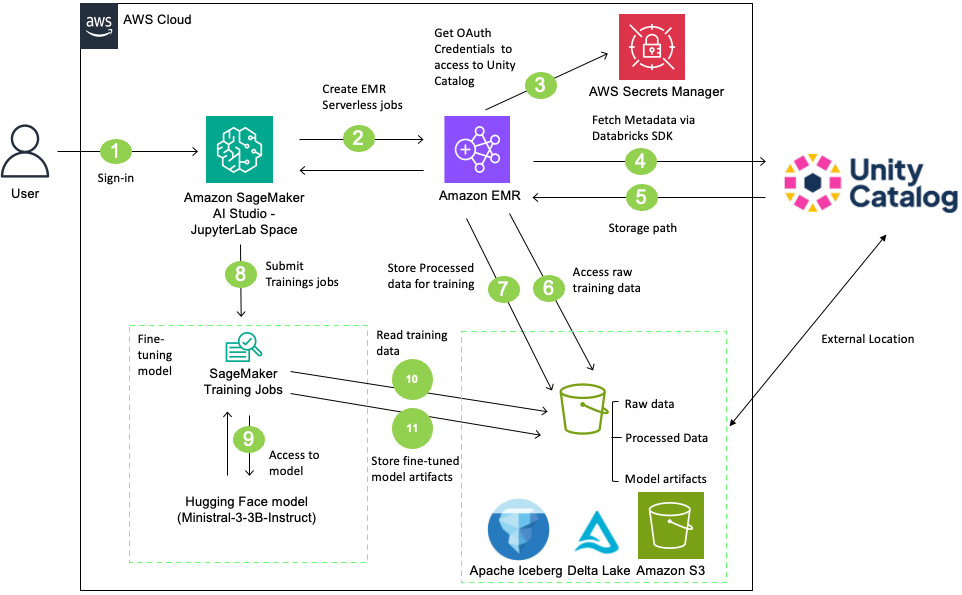
Рисунок 1: Архитектура решения, показывающая поток данных между SageMaker AI Studio, EMR Serverless и Databricks Unity Catalog
| Компонент | Назначение |
| Amazon SageMaker AI Studio – JupyterLab Space | Оркестрация workflow и обучение модели |
| Amazon EMR Serverless | Предварительная обработка данных на базе Spark без управления кластерами |
| Databricks Unity Catalog | Каталог метаданных, governance и отслеживание lineage |
| Hugging Face | Доступ к предварительно обученным моделям |
| Amazon S3 | Хранилище данных и артефактов модели |
| AWS Secrets Manager | Управление учетными данными |
В этом решении пользователи входят в SageMaker AI Studio и запускают предварительную обработку данных с помощью задания EMR Serverless. Это задание получает доступ к данным и обрабатывает их из S3-ведра под управлением Unity Catalog через Open REST APIs Unity Catalog с OAuth-учетными данными, хранящимися в AWS Secrets Manager. После обработки данных создается таблица в Unity Catalog с уже обработанными данными. Затем задача обучения SageMaker AI получает модель Ministral-3-3B-Instruct из Hugging Face, дообучает ее на обработанной таблице и сохраняет результирующие артефакты модели обратно в S3-ведро, управляемое Unity Catalog. В завершение модель регистрируется в Unity Catalog и для нее создается внешняя lineage. Этот полный workflow объединяет SageMaker AI, EMR Serverless и Databricks Unity Catalog для управляемого и масштабируемого дообучения LLM.
Предварительные требования
Перед началом убедитесь, что у вас есть следующее:
| Сервис | Требование | Детали |
| AWS | Аккаунт AWS | Разрешения для следующих сервисов AWS
|
| Amazon VPC | VPC и security groups, настроенные с доступом в интернет | |
| Databricks | Настроить Unity Catalog для Workspace | Настройте Unity Catalog для вашего Workspace. |
| Настроить внешний доступ | Настройте внешний доступ к данным в вашем Metastore. По умолчанию эта опция выключена. | |
| Сгенерировать OAuth-учетные данные | Создайте OAuth-учетные данные (Client ID и secret) для программного доступа к Databricks. |
Пошаговое руководство
В этом разделе описан полный процесс дообучения LLM на данных, которыми управляет Unity Catalog. Скачайте полный ноутбук LLM_Finetunig_SageMaker_AI_Unity_Catalog.ipynb и запустите его в SageMaker AI Studio, выполнив следующие шаги:
- Перейдите в консоль Amazon SageMaker AI.
- Создайте SageMaker Studio Domain с помощью Quick Setup, если у вас еще нет существующего домена.
- Войдите в SageMaker AI Studio.
- Создайте JupyterLab Space со следующей конфигурацией:
- Тип инстанса: ml.m5.2xlarge
- Image: Sagemaker Distribution 3.8.0
- Хранилище: 5 GB
- Загрузите скачанный Jupyter notebook.
- Откройте notebook, выбрав Python3 (ipykernel) в качестве kernel.
Следующие разделы на высоком уровне описывают ключевые шаги. Полную реализацию кода смотрите в notebook.
Шаг 1: Настройка AWS
К концу этого шага вы выполните следующие настройки.
| Требование | Детали |
| Amazon S3 Buckets | Создайте S3 Bucket, который будет управляться Unity Catalog, и загрузите данные |
| AWS Secrets Manager | Создайте secret для хранения OAuth-учетных данных Databricks |
| AWS IAM Roles | Создайте SageMaker AI Execution Role и EMR Serverless job runtime Role |
Настройка S3 bucket / Загрузка набора данных
В notebook используются данные SEC EDGAR filings data (U.S. Securities and Exchange Commission Electronic Data Gathering, Analysis, and Retrieval) для дообучения LLM. SEC EDGAR — это публичная база корпоративной отчетности SEC. Решение получает формы 10-K и 10-Q компаний из S&P 500 за 2023–2024 годы через публичные API SEC, загружает документы отчетности, извлекает раздел Risk Factors и загружает данные в S3 bucket Amazon. Файлы сохраняются в формате JSON; каждая запись содержит идентификатор компании (CIK), тикер, имя компании, тип отчета, финансовый период и полный текст раскрытия факторов риска, где компании описывают потенциальные бизнес-, финансовые, регуляторные и операционные риски. После загрузки данных в вашем S3 bucket будет следующая структура:
| s3://aws-blog-smai-uc-bucket-ACCOUNTID/├── raw/│ └── risk_factors/│ ├── form_type=10-K/│ │ └── fiscal_year=2024/│ │ └── cik=0000320193/│ │ └── risk_factors.json│ └── form_type=10-Q/│ └── fiscal_year=2024/│ └── quarter=1/│ └── cik=0000320193/│ └── risk_factors.json├── curated/└── ml/ |
Хранение учетных данных Databricks
Databricks поддерживает несколько методов аутентификации и авторизации для управления доступом к ресурсам. В этом решении используется OAuth для service principals (OAuth M2M), который выдает короткоживущие OAuth-токены для service principals. Использование OAuth 2.0 — предпочтительный протокол авторизации для доступа к Databricks вне console. Для OAuth-авторизации нужны client id и client secret. Когда service principal проходит аутентификацию и получает consent, OAuth выдает access token для SDK или другого инструмента. Сначала создайте Service Principal и сгенерируйте OAuth Secret, следуя документации Databricks. Затем сохраните client id и secret в AWS Secrets Manager, чтобы безопасно управлять и извлекать эти учетные данные.
Создание IAM roles
На следующих этапах вы будете использовать EMR Serverless Job и SageMaker AI Training jobs. Для обоих требуются IAM role для доступа к другим сервисам AWS и выполнения задач. Ознакомьтесь с Job runtime roles for Amazon EMR Serverless и How to use SageMaker AI execution roles, чтобы понять, как EMR Serverless jobs и SageMaker AI работают с IAM. Ниже приведены примеры IAM policies для каждой IAM role. Полную реализацию см. в разделе 1-4 Create IAM Roles notebook.
EMR Serverless Runtime Role
emr_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
f"arn:aws:s3:::{UC_MANAGED_BUCKET}/*",
f"arn:aws:s3:::{UC_MANAGED_BUCKET}"
]
},
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
f"arn:aws:secretsmanager:{AWS_REGION}:{AWS_ACCOUNT_ID}:secret:databricks/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": f"arn:aws:logs:{AWS_REGION}:{AWS_ACCOUNT_ID}:*"
}
]
}
SageMaker AI Execution Role policy
sagemaker_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
f"arn:aws:s3:::{UC_MANAGED_BUCKET}/*",
f"arn:aws:s3:::{UC_MANAGED_BUCKET}"
]
},
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
f"arn:aws:secretsmanager:{AWS_REGION}:{AWS_ACCOUNT_ID}:secret:databricks/*" # All Databricks secrets
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogStreams"
],
"Resource": f"arn:aws:logs:{AWS_REGION}:{AWS_ACCOUNT_ID}:*"
},
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage"
],
"Resource": "*"
}
]
}
Шаг 2: Настройка Databricks Unity Catalog
Далее выполните следующие шаги настройки на стороне Databricks Unity Catalog и подтвердите доступ к таблице Unity Catalog через Databricks SDK.
| Требование | Детали |
| Configure External Location | Зарегистрируйте ваш S3 bucket как External Location в Unity Catalog, чтобы настроить доступ к данным в S3. |
| Create Unity Catalog database objects | Настройте следующие database objects в среде Unity Catalog:
|
| Grant Permissions |
Предоставьте необходимые privileges вашему Service Principal. Необходимые разрешения:
|
После завершения у вас будет следующая структура Unity Catalog с правильно настроенными разрешениями для вашего service principal:
| UNITY_CATALOG_NAME├── UNITY_SCHEMA_DATA (raw)│ └── UNITY_TABLE_NAME (external table pointing to UC_MANAGED_BUCKET/raw/)├── UNITY_SCHEMA_TRAINING (curated)│ └── (processed training data)└── UNITY_SCHEMA_MODEL (ml)└── (model artifacts and versions) |
После настройки Unity Catalog инициализируйте Databricks client и протестируйте соединение с Unity Catalog, прежде чем переходить к следующим шагам. Notebook использует AWS Secrets Manager для получения client ID и secret. После успешной аутентификации можно получить сведения о таблице Unity Catalog, такие как расположение хранилища и формат таблицы.
# Initialize Databricks client
from databricks.sdk import WorkspaceClient
w = WorkspaceClient(
host=UNITY_WORKSPACE_URL,
client_id=DATABRICKS_CLIENT_ID,
client_secret=DATABRICKS_CLIENT_SECRET
)
table_info = w.tables.get(f"{UNITY_CATALOG_NAME}.{UNITY_SCHEMA_DATA}.{UNITY_TABLE_NAME}")
print(f"Table: {table_info.name}")
print(f"Storage Location: {table_info.storage_location}")
print(f"Table Format: {table_info.data_source_format}")
Output:
Table: risk_factors
Storage Location: s3:// aws-blog-smai-uc-bucket-ACCOUNTID/raw/risk_factors
Table Format: DataSourceFormat.DELTA
Шаг 3: Настройка EMR Serverless application
На этом шаге вы создаете EMR Serverless application, используя VPC с доступом в интернет. Сначала решение определяет расположение S3 bucket в Unity Catalog, затем EMR Serverless job читает и записывает данные в Delta table в этом S3 bucket. Поскольку EMR Serverless по состоянию на февраль 2026 года не включает поддержку Delta Lake по умолчанию, Spark application должна загружать JAR-файлы Delta Lake из репозитория Maven Central через интернет на этапе инициализации. Без доступа в интернет эта загрузка завершится ошибкой, и Spark application не сможет распознать формат Delta table, из-за чего задача упадет уже на старте. Настройте EMR Serverless application так, чтобы она использовала существующие subnet с доступом в интернет, или обратитесь к разделу 1.4 Setup VPC and Internet Access notebook, чтобы выполнить эту настройку.
Шаг 4: Предварительная обработка данных с помощью EMR Serverless job
Далее создайте скрипт предварительной обработки и отправьте EMR Serverless job. Скрипт предварительной обработки читает risk factors SEC EDGAR из Delta table, фильтрует и очищает текстовые данные, форматирует их в prompt в стиле instruction для дообучения и записывает обработанные результаты в Delta table в S3.
Настройте sparkSubmitParameters в Spark-конфигурации EMR Serverless job, чтобы загрузить библиотеку Delta Lake из Maven Central repository и задать специфичные для Delta SQL extensions и catalog configurations, как показано ниже. Эти параметры позволяют Spark application в EMR Serverless читать и записывать Delta tables в S3 для предварительной обработки данных. Полную реализацию кода смотрите в разделе 4-3 Submit EMR jobs notebook.
jobDriver={
'sparkSubmit': {
'sparkSubmitParameters': ' '.join([
'--packages io.delta:delta-spark_2.12:3.2.0',
'--conf spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension',
'--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog'
])
}
После завершения EMR Serverless job зарегистрируйте предварительно обработанные training data как Delta table в curated schema Unity Catalog, указывая на обработанные данные в S3. Выполните SQL statements через Databricks Serverless SQL warehouse с помощью Databricks SDK, создав таблицу в curated schema внутри Unity Catalog.
Шаг 5: Дообучение с помощью SageMaker AI Training job
После подготовки dataset для обучения используйте SageMaker AI training job для дообучения LLM. В этом решении используется предварительно обученная модель Ministral-3-3B-Instruct-2512, размещенная на Hugging Face. Это компактная instruction-following модель Mistral AI с 3 миллиардами параметров, созданная для эффективного развертывания при сохранении высокой производительности в задачах reasoning.
Чтобы настроить SageMaker AI training job, сначала создайте training script и загрузите его в S3 bucket. Training script в notebook дообучает модель Ministral-3B-Instruct с использованием memory-efficient techniques. Он загружает модель в 8-bit floating point (FP8) quantization, чтобы снизить расход памяти, а затем применяет Low-Rank Adaptation (LoRA), обучая только 1–2% параметров вместо всех 3 миллиардов. Скрипт читает предварительно обработанные данные из предыдущих шагов и токенизирует их с контекстным окном 1 024 токена. Пример реализации см. в разделе 5.1 Create Training Script notebook.
Затем настройте и отправьте training job. В этом решении для обучения модели используется один инстанс ml.g5.16xlarge, а в качестве training input передается S3-location обработанных данных из предыдущих шагов. После завершения SageMaker AI training job загружает fine-tuned model artifacts в S3 bucket.
Шаг 6: Регистрация артефактов модели в Unity Catalog
После загрузки артефактов модели в S3 зарегистрируйте дообученную модель в ML schema Unity Catalog с использованием Managed MLflow на Databricks через SDK. В Unity Catalog можно создать объект Model для контроля доступа, управления жизненным циклом и поиска ML-моделей. Databricks предоставляет в Unity Catalog возможность MLflow Model Registry. Вы создаете MLflow experiment, чтобы записывать метаданные обучения (hyperparameters, source table, training job details), и регистрируете модель с версионированием и документацией, включая source data lineage, training service и model specifications. После регистрации модель можно просмотреть в консоли Unity Catalog.
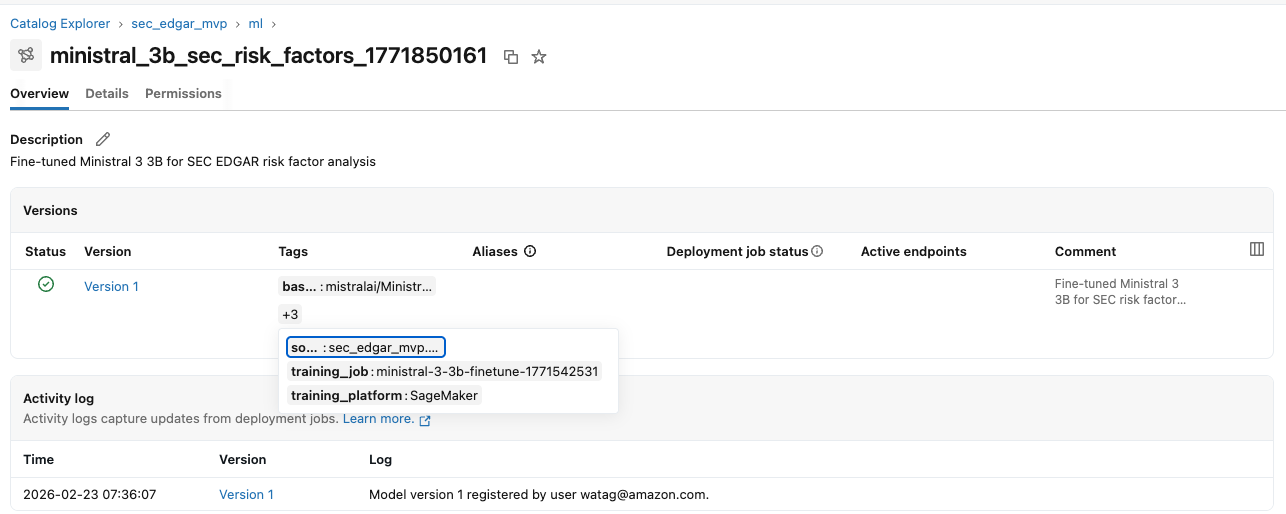
Шаг 7: Создание lineage данных в Unity Catalog
Наконец, создайте data lineage в Unity Catalog. Отслеживание lineage данных показывает, какие данные обучили каждую модель, формируя audit trail для комплаенса и governance. Это также упрощает отладку, позволяя проследить источник проблем. Особенно это важно для регулируемых отраслей и production ML-сред, где качество данных и надежность моделей критичны.
Databricks Unity Catalog автоматически фиксирует runtime data lineage для запросов, выполняемых в Databricks. Для рабочих нагрузок, выполняемых вне Databricks (например, EMR Serverless jobs, SageMaker AI training jobs), можно добавлять external metadata и lineage через External Metadata API и External Lineage API. Эта возможность «bring your own data lineage» (по состоянию на апрель 2026 года находится в public preview) дает полное представление о lineage в Unity Catalog.
Создайте external metadata для preprocessing job с EMR Serverless и fine-tuning job с SageMaker AI Training job. Затем создайте upstream и downstream lineage с использованием external lineage. Вам понадобятся следующие объекты:
- Объект external metadata для EMR Serverless job
- Upstream lineage (raw table → EMR Serverless job)
- Downstream lineage (EMR Serverless job → pre-processed table)
- Объект external metadata для SageMaker AI Training job
- Upstream lineage (pre-processed table → SageMaker AI Training job)
- Downstream lineage (SageMaker AI Training job → Model Version)
После создания external data lineage по этим шагам вы сможете увидеть граф lineage данных от исходных данных до дообученной модели в консоли Unity Catalog.

Очистка ресурсов
После тестирования решения удалите следующие ресурсы, чтобы избежать дальнейших расходов:
- EMR Serverless Application
- Amazon S3 Buckets and Objects
- IAM Roles and Policies
- AWS Secrets Manager Secrets
- VPC Resources
- Unity Catalog Resources (Catalog, Schema, Table, and Service Principal)
Пошаговые инструкции см. в разделе Step 8: Cleanup Resources notebook.
Заключение
В этом материале показано, как интегрировать Databricks Unity Catalog с Amazon SageMaker AI, чтобы добиться управляемого дообучения LLM между сервисами. Объединив Unity Catalog для централизованных метаданных, контроля доступа и lineage с Amazon EMR Serverless для предварительной обработки и SageMaker AI Training для масштабируемой разработки моделей, вы можете сохранить непрерывность governance, используя ML-возможности AWS. Мы показали, как безопасно получить доступ к данным под управлением Unity Catalog, предварительно обработать их с помощью Spark, дообучить модель Ministral-3-3B-Instruct, зарегистрировать модель обратно в Unity Catalog и собрать lineage между системами. Такой подход позволяет использовать специализированную архитектуру, не нарушая требования безопасности и комплаенса.
Чтобы начать, скачайте notebook, разверните reference architecture в своем аккаунте AWS и протестируйте workflow на dataset под управлением Unity Catalog. Используйте этот шаблон как основу для создания governed, production-ready ML и generative AI workloads в мультисервисной среде. Затем попробуйте применить этот подход к другим LLM и более крупным наборам данных. Есть вопросы? Поделитесь вопросами и отзывами в комментариях.
Материал — перевод статьи с английского.
Оригинал: Fine-tune LLM with Databricks Unity Catalog and Amazon SageMaker AI