Оптимизация video semantic search с помощью дистилляции моделей Amazon Nova на Amazon Bedrock

Оптимизация моделей для video semantic search требует баланса между точностью, стоимостью и задержкой. Более быстрые и компактные модели не обладают достаточной логикой маршрутизации, а более крупные и точные модели добавляют заметные накладные задержки. В первой части этой серии мы показали, как построить мультимодальную систему video semantic search на AWS с интеллектуальной маршрутизацией намерений с использованием модели Anthropic Claude Haiku в Amazon Bedrock. Хотя модель Haiku обеспечивает высокую точность распознавания пользовательского намерения поиска, она увеличивает end-to-end время поиска до 2–4 секунд. Это составляет 75% общей задержки.
Рисунок 1: Пример разбивки сквозной задержки запроса
Теперь рассмотрим, что происходит по мере усложнения логики маршрутизации. Корпоративные метаданные могут быть гораздо сложнее, чем пять атрибутов в нашем примере (заголовок, подпись, люди, жанр и временная метка). Клиенты могут учитывать углы съемки, настроение и тональность, окна лицензирования и прав, а также другие отраслевые таксономии. Более тонкая логика означает более требовательный prompt, а более требовательный prompt приводит к более дорогим и медленным ответам. Именно здесь помогает настройка модели. Вместо выбора между моделью, которая быстрая, но слишком простая, и моделью, которая точная, но слишком дорогая или медленная, можно получить все три качества, обучив небольшую модель выполнять задачу точно при гораздо меньшей задержке и стоимости.
В этом посте мы показываем, как использовать Model Distillation — технику кастомизации моделей в Amazon Bedrock, — чтобы перенести routing intelligence из большой teacher model (Amazon Nova Premier) в значительно меньшую student model (Amazon Nova Micro). Этот подход сокращает стоимость инференса более чем на 95% и снижает задержку на 50%, сохраняя при этом тонкую качество маршрутизации, необходимую для этой задачи.
Обзор решения
Мы пройдем весь пайплайн дистилляции от начала до конца в Jupyter notebook. На высоком уровне notebook включает следующие шаги:
- Подготовка обучающих данных — 10 000 синтетических размеченных примеров с использованием Nova Premier и загрузка набора данных в Amazon Simple Storage Service (Amazon S3) в формате дистилляции Bedrock
- Запуск job дистилляции — настройка задания с идентификаторами teacher и student моделей и отправка через Amazon Bedrock
- Развертывание distilled model — развертывание кастомной модели с использованием on-demand inference для гибкого доступа с оплатой по факту использования
- Оценка distilled model — сравнение качества маршрутизации с базовой Nova Micro и исходной базовой линией Claude Haiku с помощью Amazon Bedrock Model Evaluation
Полный notebook, скрипт генерации обучающих данных и утилиты оценки доступны в репозитории GitHub.
Подготовка обучающих данных
Одна из ключевых причин, по которой мы выбрали model distillation вместо других техник кастомизации, таких как supervised fine-tuning (SFT), заключается в том, что она не требует полностью размеченного набора данных. При SFT каждому примеру обучения нужен созданный человеком ответ в качестве ground truth. При дистилляции нужны только prompts. Amazon Bedrock автоматически вызывает teacher model для генерации качественных ответов. Он применяет методы синтеза и аугментации данных за кулисами, чтобы создать разнообразный тренировочный набор данных до 15 000 пар prompt-response.
При этом вы можете при желании предоставить размеченный набор данных, если хотите больше контролировать обучающий сигнал. Каждая запись в JSONL-файле соответствует схеме bedrock-conversation-2024, где роль user (входной prompt) обязательна, а роль assistant (желаемый ответ) — необязательна. Смотрите следующие примеры и обратитесь к Prepare your training datasets for distillation для подробностей:
{
"schemaVersion": "bedrock-conversation-2024",
"system": [{ "text": "Верните JSON с весами visual, audio, transcription, metadata (сумма=1.0) и обоснованием для данного video search query." }],
"messages": [
{
"role": "user",
"content": [{ "text": "Olivia talking about growing up in poverty" }]
},
{
"role": "assistant",
"content": [{ "text": " {\"visual\": 0.2, \"audio\": 0.1, \"transcription\": 0.6, \"metadata\": 0.1, \"reasoning\": \"Запрос сосредоточен на устном содержании ('talking about'), поэтому transcription наиболее важен. Visual и audio элементы вторичны, так как они поддерживают контекст, а metadata минимален.\"}"}]
}
]
}
Для этого поста мы подготовили 10 000 синтетических размеченных примеров с использованием Nova Premier — самой большой и самой способной модели в семействе Nova. Данные были сгенерированы с сбалансированным распределением по запросам на visual, audio, transcription и metadata сигналы. Примеры охватывают весь диапазон ожидаемых поисковых запросов, представляют разные уровни сложности, включают крайние случаи и вариации и предотвращают переобучение на узкие шаблоны запросов. Следующая диаграмма показывает распределение весов по четырем модальным каналам.
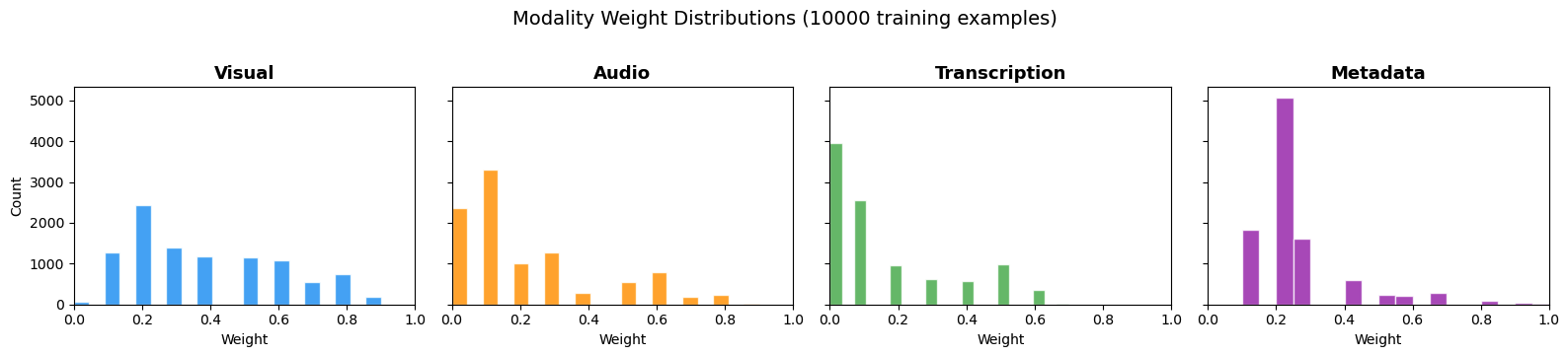
Рисунок 2: Распределение весов по 10 000 обучающих примеров
Если вам нужны дополнительные примеры или вы хотите адаптировать распределение запросов под собственную предметную область, предоставленный скрипт generate_training_data.py можно использовать для синтетической генерации дополнительных обучающих данных с помощью Nova Premier.
Запуск job дистилляции
После загрузки обучающих данных в Amazon S3 следующий шаг — отправить job дистилляции. Model distillation работает так: на основе ваших prompt сначала генерируются ответы от teacher model. Затем эти пары prompt-response используются для дообучения student model. В этом проекте teacher — Amazon Nova Premier, а student — Amazon Nova Micro, быстрая и экономичная модель, оптимизированная для высокопроизводительного инференса. Решения teacher по маршрутизации становятся обучающим сигналом, который формирует поведение student.
Amazon Bedrock автоматически управляет всей оркестрацией обучения и инфраструктурой. Не требуется ни разворачивания кластера, ни настройки hyperparameter, ни построения пайплайна teacher-to-student model. Вы указываете teacher model, student model, путь S3 к обучающим данным и роль AWS Identity and Access Management (IAM) с необходимыми правами. Остальное Bedrock берет на себя. Ниже приведен пример кода для запуска job дистилляции:
import boto3
from datetime import datetime
bedrock_client = boto3.client(service_name="bedrock")
teacher_model = "us.amazon.nova-premier-v1:0"
student_model = "amazon.nova-micro-v1:0:128k"
job_name = f"video-search-distillation-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
model_name = "nova-micro-video-router-v1"
response = bedrock_client.create_model_customization_job(
jobName=job_name,
customModelName=model_name,
roleArn=distillation_role_arn,
baseModelIdentifier=student_model,
customizationType="DISTILLATION",
trainingDataConfig={"s3Uri": training_s3_uri},
outputDataConfig={"s3Uri": output_s3_uri},
customizationConfig={
"distillationConfig": {
"teacherModelConfig": {
"teacherModelIdentifier": teacher_model,
"maxResponseLengthForInference": 1000
}
}
}
)
job_arn = response['jobArn']
Job выполняется асинхронно. Вы можете отслеживать прогресс в консоли Amazon Bedrock в разделе Foundation models > Custom models или программно:
status = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn)['status']
print(f"Job status: {status}") # Training, Complete, or Failed
Время обучения зависит от размера набора данных и выбранной student model. Для 10 000 размеченных примеров с Nova Micro ожидайте завершения job в течение нескольких часов.
Развертывание distilled model
После завершения job дистилляции кастомная модель становится доступной в вашем аккаунте Amazon Bedrock и готова к развертыванию. Amazon Bedrock предлагает два варианта развертывания кастомных моделей: Provisioned Throughput для предсказуемых высоконагруженных сценариев и On-Demand Inference для гибкого доступа с оплатой по мере использования без предварительных обязательств.
Для большинства команд, которые только начинают, рекомендуется on-demand inference. Не нужно поднимать endpoint, нет почасового обязательства и нет минимального требования к использованию. Ниже приведен код развертывания:
import uuid
deployment_name = f"nova-micro-video-router-{datetime.now().strftime('%Y-%m-%d')}"
response = bedrock_client.create_custom_model_deployment(
modelDeploymentName=deployment_name,
modelArn=custom_model_arn,
description="Distilled Nova Micro for video search modality weight prediction (4 weights)",
tags=[
{"key": "UseCase", "value": "VideoSearch"},
{"key": "Version", "value": "v2-4weights"},
],
clientRequestToken=f"deployment-{uuid.uuid4()}",
)
deployment_arn = response['modelDeploymentArn']
print(f"Deployment ARN: {deployment_arn}")
Когда статус покажет InService, вы сможете вызывать distilled model точно так же, как любую другую базовую модель, используя стандартный InvokeModel или Converse API. Вы платите только за потребленные токены по ставкам инференса Nova Micro: $0.000035 за 1 000 входных токенов и $0.000140 за 1 000 выходных токенов.
import boto3
import json
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
custom_model_arn = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn
)['outputModelArn']
response = bedrock_runtime.converse(
modelId=custom_model_arn,
messages=[
{
"role": "user",
"content": [{"text": query}]
}
]
)
routing_weights = json.loads(
response['output']['message']['content']['text']
)
print(routing_weights)
# {"visual": 0.7, "audio": 0.1, "transcription": 0.1, "metadata": 0.1}
Оценка distilled model
Прежде чем сравнивать с оригинальным router, стоит проверить, что дистилляция улучшила способность базовой модели выполнять routing task. В следующей таблице один и тот же prompt показан для base Nova Micro и distilled Nova Micro рядом.
| Запрос | Distilled Nova Micro | Base Nova Micro |
"CEO discussing quarterly earnings " |
{"visual": 0.2, "audio": 0.3, "transcription": 0.4, "metadata": 0.1, "reasoning": "Запрос сосредоточен на устном содержании (transcription) о доходах, но визуальные признаки (внешний вид CEO) и audio (тон/четкость) также важны..."} |
Вот JSON-представление информации, которую вы запросили, для video search query о CEO, обсуждающем квартальные доходы:
|
"sunset over mountains" |
{"visual": 0.8, "audio": 0.0, "transcription": 0.0, "metadata": 0.2, "reasoning": "Запрос сосредоточен на визуальной сцене (закат над горами), без аудио или transcription-элементов. Metadata может включать теги местоположения или времени."} |
Вот JSON-представление для video search query «sunset over mountains», которое включает visual, audio, transcription, metadata веса (sum=1.0) и reasoning:
|
Базовая модель испытывает трудности и с инструкциями, и с согласованностью формата вывода. Она выдает свободный текст, неполный JSON и нечисловые значения весов. Distilled model стабильно возвращает корректно сформированный JSON с четырьмя числовыми весами, которые в сумме дают 1.0, что соответствует схеме, требуемой routing pipeline.
При сравнении с оригинальным Claude Haiku router обе модели оцениваются на отложенном наборе из 100 размеченных примеров, сгенерированных Nova Premier. Мы используем Amazon Bedrock Model Evaluation для проведения сравнения в структурированном управляемом процессе. Чтобы оценить качество маршрутизации шире стандартных метрик, мы определили пользовательскую рубрику OverallQuality (см. следующий блок кода), которая инструктирует Claude Sonnet оценивать каждый прогноз по двум измерениям: точность весов относительно ground truth и качество reasoning. Каждое измерение соответствует конкретному 5-балльному порогу, поэтому рубрика штрафует и числовое отклонение, и шаблонные общие рассуждения.
"rating_scale": [
{"definition": "Weights within 0.05 of reference. Reasoning is specific and consistent.",
"value": {"floatValue": 5.0}},
{"definition": "Weights within 0.10 of reference. Reasoning is clear and mostly consistent.",
"value": {"floatValue": 4.0}},
{"definition": "Dominant modality matches. Avg error < 0.15. Reasoning is present but generic.",
"value": {"floatValue": 3.0}},
{"definition": "Dominant modality wrong OR avg error > 0.15. Reasoning vague or inconsistent.",
"value": {"floatValue": 2.0}},
{"definition": "Unparseable JSON, missing keys, or error > 0.30. No useful reasoning.",
"value": {"floatValue": 1.0}},
]
Модель distilled Nova Micro получила оценку large language model (LLM)-as-judge 4.0 из 5, практически идентичное качество маршрутизации по сравнению с Claude 4.5 Haiku при примерно вдвое меньшей задержке (833 мс против 1 741 мс). Преимущество в стоимости не менее значимо. Переход на distilled Nova Micro снижает стоимость инференса более чем на 95% как для входных, так и для выходных токенов, без предварительных обязательств при on-demand pricing. Примечание: Оценка LLM-as-judge недетерминирована. Баллы могут немного отличаться от запуска к запуску.
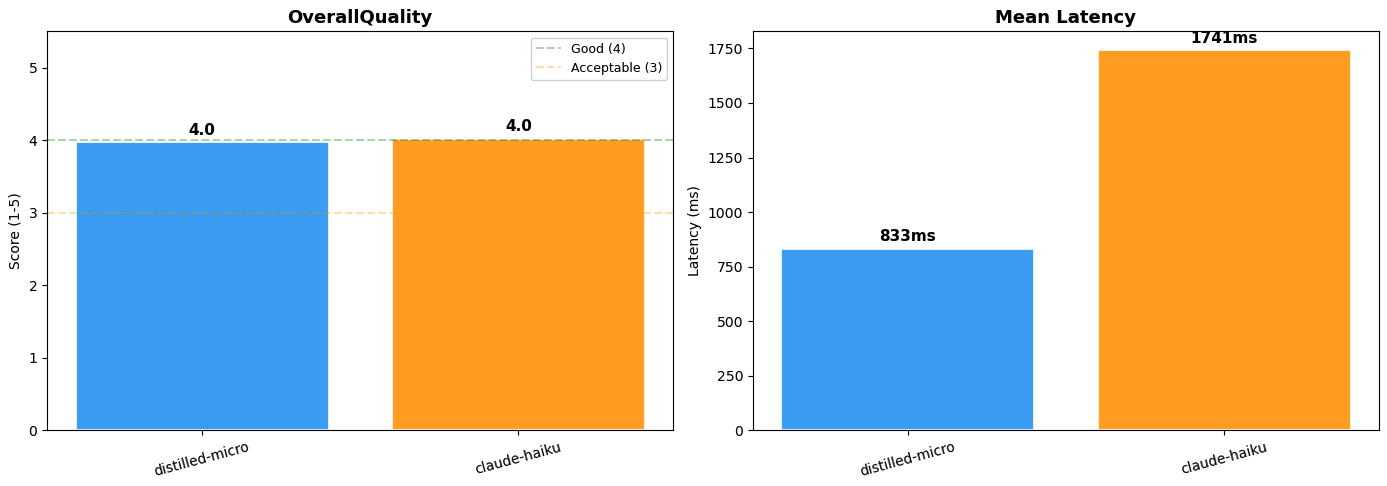
Рисунок 3: Сравнение производительности моделей (Distilled Nova Micro vs. Claude 4.5 Haiku)
Ниже приведена сводная таблица результатов side by side:
| Метрика | Distilled Nova Micro | Claude 4.5 Haiku |
| LLM-as-judge Score | 4.0 / 5 | 4.0 / 5 |
| Mean Latency | 833ms | 1,741ms |
| Input Token Cost | $0.000035 / 1K | $0.80–$1.00 / 1K |
| Output Token Cost | $0.000140 / 1K | $4.00–$5.00 / 1K |
| Output Format | Consistent JSON | Inconsistent |
Очистка ресурсов
Чтобы избежать постоянных расходов, запустите раздел очистки в notebook, чтобы удалить все подготовленные ресурсы, включая развернутые endpoints модели и любые данные, хранящиеся в Amazon S3.
Заключение
Этот пост — вторая часть двухчастной серии. Продолжая первую часть, этот материал посвящен применению model distillation для оптимизации слоя intent routing, построенного в решении video semantic search. Рассмотренные техники помогают решать реальные производственные компромиссы, такие как баланс между routing intelligence, задержкой и стоимостью при масштабировании при сохранении точности поиска. Дистиллировав routing behavior Amazon Nova Premier в Amazon Nova Micro с помощью Amazon Bedrock Model Distillation, мы снизили стоимость инференса более чем на 95% и сократили задержку preprocessing вдвое, сохранив при этом тонкую качество маршрутизации, необходимую для этой задачи. Если вы работаете с мультимодальным video search в масштабе, model distillation — это практичный путь к production-grade экономии без потери точности поиска. Чтобы изучить полную реализацию, посетите репозиторий GitHub и попробуйте решение сами.
Материал — перевод статьи с английского.
Оригинал: Optimize video semantic search intent with Amazon Nova Model Distillation on Amazon Bedrock