Процессное внедрение автоматизации и ИИ с измеримым эффектом
Автор: Наумов Д
Эта статья описывает подход, в котором автоматизация (включая ИИ‑агентов) внедряется как управляемый процесс улучшений: с заранее определёнными метриками, дизайном оценки влияния и экономической моделью TCO/LCCA. Такой подход снижает риск “сделали — а стало ли лучше?” и превращает инновации в повторяемый конвейер решений “масштабировать / доработать / остановить”. Практика масштабных онлайн‑экспериментов показывает, что способность доверять измерению и быстро фильтровать идеи создаёт долгосрочное преимущество: эксперименты требуют не только статистики, но и организационных, инженерных и механизмов надёжности (доверие к данным и измерению). [1]
Для ИИ‑компонент ключевой момент — эксплуатация: NIST подчёркивает необходимость мониторинга после внедрения (после внедрения) из‑за реальных динамик и недетерминированности выходов, а также указывает, что лучшие практики мониторинга пока “разрозненны” и незрелы — значит, их нужно закладывать в модель владения заранее. [2]
Чтобы избегать “экономии через увольнения”, в модели следует явно различать экономию затрат (прямую экономию расходов) и предотвращение затрат (избежание будущих затрат, то есть избежание будущих затрат/найма), а высвобожденное время формализованно реинвестировать в приоритеты процесса — это допустимая управленческая практика и должна быть отражена в бизнес‑кейсе. [3]
Навигация
- Ценностное предложение и принципы
- Итерационный процесс внедрения
- Метрики, статистическая валидность и дизайны оценки
- Экономическая модель, формулы и критерии остановки
- Пример: ИИ‑агент поддержки транспортной компании
- Реальные кейсы и применение рамки
- Выводы и что делать дальше
Ценностное предложение и принципы
Что продаётся заказчику. Не “функция” и не “чат‑бот”, а процесс внедрения: от бизнес‑намерения до доказанного эффекта и управляемой эксплуатации. На уровне “лучшей практики” это означает: (1) гипотезы и метрики фиксируются до разработки, (2) влияние оценивается причинно (A/B или квази‑эксперимент), (3) решение принимается по четырём критериям: статистика + практическая значимость + экономика + риск. [4]
Почему именно измеримость становится преимуществом. В работе про эксперименты “в большом масштабе” подчёркивается, что массовые контролируемые эксперименты дают возможность ускорять инновации, находить действительно работающие идеи и избегать вредных релизов — но для этого нужно решать задачи культуры, инженерии и доверия к данным (доверие к данным и измерению). [1] Это хорошо переносится на бизнес‑автоматизацию: многие решения “кажутся очевидными”, но без корректной оценки легко закрепить дорогостоящие ошибки.
Роль инженера/консультанта. Инженерная роль — не “исполнить запрос”, а: прояснить “зачем?”, предложить альтернативы, спроектировать измерение, собрать MVP, обеспечить корректный пилот и эксплуатацию. Такой подход согласуется с тем, что зрелые экспериментальные программы требуют дисциплины измерения и доверия к результатам, а не только разработки. [5]
Почему высокие показатели ИИ не равны улучшению бизнеса
Высокая точность ИИ — полезный, но промежуточный сигнал. Для внедрения важны не только метрики качества модели, но и метрики процесса, а итоговое решение должно приниматься по OEC — единому интегральному критерию, который измерим в коротком окне и причинно связан с долгосрочной бизнес‑целью. Иначе команда начинает оптимизировать то, что легко посчитать, а не то, что действительно влияет на экономику. В клиентской поддержке это особенно заметно: CSAT и AHT нельзя трактовать изолированно от исходов процесса и стоимости обслуживания. [7] [9] [10]
Практически это означает простое разделение. точность, распознавание намерений, доля галлюцинаций и задержка ответа — метрики качества компонента. FCR, ART, AHT, доля эскалаций и CSAT — метрики процесса. стоимость одного решённого обращения, предотвращённый найм, срок окупаемости и ROI — уже бизнес‑метрики. Масштабирование имеет смысл только тогда, когда качественный ИИ переводится в улучшение OEC и экономика единицы, а не просто показывает высокий балл на тестовом наборе. [7]
Показатель качества ИИ = Корректные ответы / Проверенные ответы
Месячный бизнес-эффект ≈ Подходящий объём * Доля использования * Доля авторазрешения * Изменение стоимости на обращение
+ Объём обращений с ИИ-подсказкой * Экономия времени * Стоимость минуты
+ Избежанные расходы
- Операционные расходы на ИИ
- Расходы на контроль качества и поддержку- Показатель качества ИИ — доля корректных ответов среди проверенных
- Месячный бизнес-эффект — итоговая оценка экономического эффекта за месяц
- Подходящий объём — число обращений, где автоматизация в принципе применима
- Доля использования — доля пользователей, которые реально доходят до решения
- Доля авторазрешения — доля обращений, закрытых без участия человека
- Изменение стоимости на обращение — экономия или рост себестоимости на одно обращение
- Объём обращений с ИИ-подсказкой — поток, где ИИ помогает сотруднику, а не заменяет его
- Экономия времени — сколько минут удаётся сэкономить на одном обращении
- Стоимость минуты — стоимость одной минуты работы сотрудника
- Избежанные расходы — затраты, которых удалось не допустить, например найм
- Операционные расходы на ИИ — стоимость модели, инфраструктуры и эксплуатации
- Расходы на контроль качества и поддержку — QA, сопровождение и регулярные доработки
Из этой логики видно, почему ИИ с очень хорошей точностью может не дать эффекта. Если в процессе мало реально автоматизируемого потока, пользователи редко доходят до агента, доля эскалаций велика, а поддержка модели дорога, сильный показатель качества не превращается в бизнес‑результат.
Небольшая гипотетическая иллюстрация: даже если ассистент отвечает корректно в 95% случаев, но у процесса только 2 000 подходящих обращений в месяц, базовая стоимость контакта равна 120 ₽, а без человека закрывается лишь половина из них, то валовый месячный эффект от сокращения обращений (снятия нагрузки) составит всего 120 000 ₽. При OPEX решения в 400 000 ₽ проект всё равно будет отрицательным.
Итерационный процесс внедрения
Ниже — компактный цикл из восьми шагов (повторяемый для автоматизации без ИИ и для ИИ‑агентов; различие — в объёме TEVV/мониторинга для ИИ).
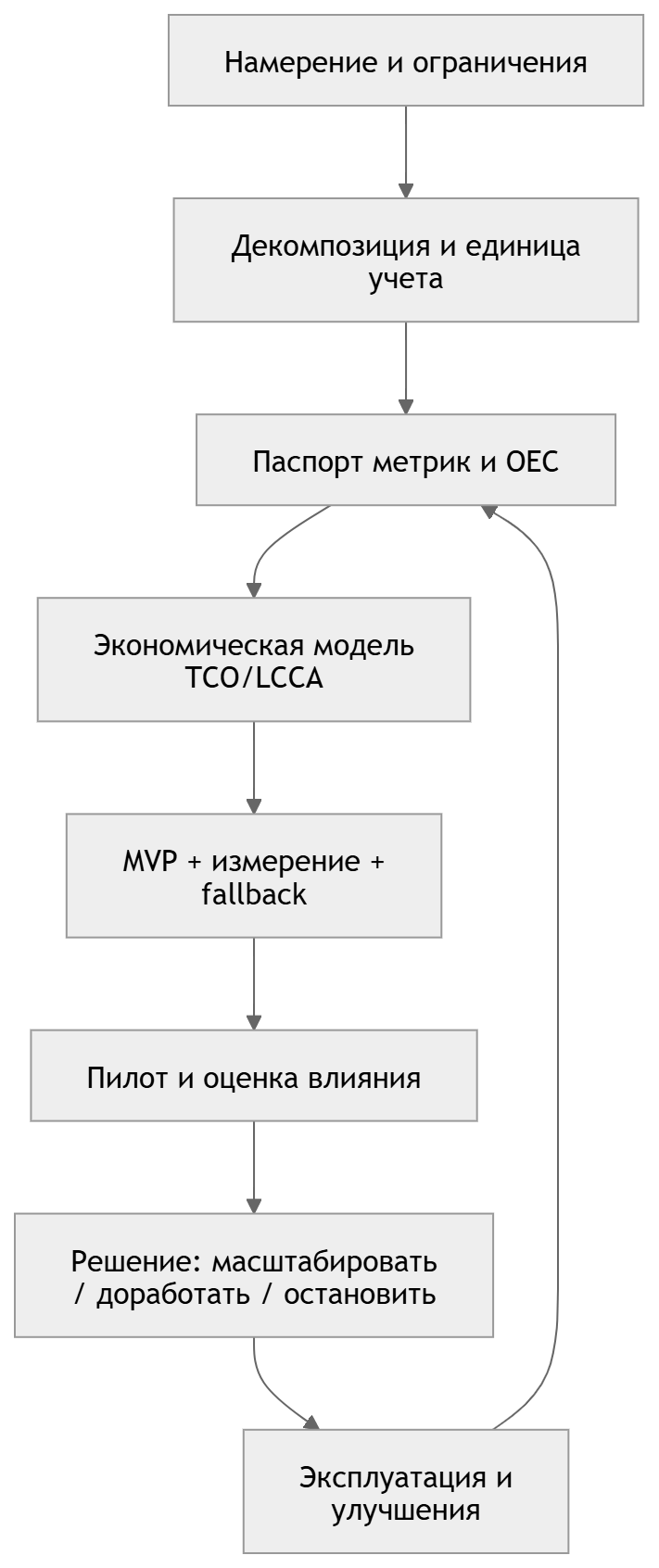
Смысл шагов (в одном абзаце).
Сначала фиксируется бизнес-цель и ограничения (качество, SLA, комплаенс, риск-толерантность). Затем процесс декомпозируется до измеряемой единицы (тикет, отправка, заказ, диалог). Далее создаётся паспорт метрик и при необходимости OEC — единый критерий оценки успеха. После этого строится экономическая модель (TCO/LCCA) и задаются целевые пороги. Затем собирается MVP, в котором уже есть логирование, метрики и резервный сценарий с эскалацией. Запускается пилот с причинной оценкой и проверками доверия к данным и измерению, включая SRM. Итог — решение и перевод в эксплуатацию с циклом улучшений. [6]
Метрики, статистическая валидность и дизайны оценки
Каркас метрик
Подход “в четыре слоя” хорошо согласуется с практиками экспериментирования: метрики должны быть измеримы в окне эксперимента, достаточно чувствительны, а при множестве целей — сводиться в OEC, который предполагаемо причинно связан с долгосрочными целями. [7]
- Целевая метрика результата (итог). То, ради чего внедрение: стоимость обслуживания клиента, пропускная способность, SLA, ошибки/штрафы.
- OEC. Единый критерий “успех/неуспех” (например: стоимость на решённый запрос ↓ при CSAT ≥ базовый уровень и критические ошибки ≤ порога). [7]
- Прокси‑метрики (опережающие индикаторы). То, что быстро реагирует: доля самообслуживания, FCR, FRT, AHT, повторные обращения. Формулы можно брать из общепринятых KPI поддержки:
- FCR = (запросы, решённые с первого обращения ÷ всего запросов) × 100.[8]
- FRT = суммарное время до первого ответа ÷ число взаимодействий.[9]
- AHT (включая разговор/ожидание/работу после звонка) = (сумма всех компонентов) ÷ число взаимодействий.[10]
- Ограничители и инварианты (защитные рамки и инварианты). Метрики “нельзя ухудшать” (CSAT, жалобы, критические ошибки, комплаенс) + проверки валидности измерения (например SRM). [11]
Статистические аспекты, которые фиксируются заранее
MDE и статистическая мощность. Входом дизайна пилота должен быть MDE (минимально значимый эффект) и требуемая статистическая мощность (1−β), иначе пилот рискует стать “дорогим наблюдением без выводов”. У NIST электронный справочник есть формализация параметров для расчёта объёма выборки при тестах долей (α, β, δ=|p1−p0|), что удобно для метрик типа “доля решённых без человека”. [12]
p‑value не равен бизнес‑решению. ASA подчёркивает, что p‑value не измеряет вероятность истинности гипотезы и что решения нельзя принимать, опираясь только на “статистическую значимость”; требуется оценивать размер эффекта, дизайн, качество данных и контекст. [13]
SRM как “фильтр доверия”. Microsoft Research прямо рекомендует не доверять результатам A/B теста с SRM до диагностики корневой причины; “пропавшие пользователи” часто оказываются теми, кого изменение затронуло сильнее всего, что системно искажает выводы. [14] Практическая таксономия причин SRM в KDD’19 описывает, что SRM может парализовать “запускать / не запускать” решение, если нет отлаженной диагностики по стадиям эксперимента. [15]
Дизайны оценки влияния и когда применять
A/B (рандомизированный эксперимент). Применять, когда можно случайно распределить поток кейсов/клиентов/каналов на контроль и тест и обеспечить корректное логирование. Масштабные контролируемые эксперименты рассматриваются как способ ускорить инновации и избежать вредных релизов при наличии инженерии и практик доверия к данным и измерению. [5]
метод разницы разниц (DiD). Применять, когда рандомизация невозможна, но есть сопоставимая контрольная группа и данные “до/после”. Columbia подчёркивает, что ключевое предположение — параллельные тренды (без вмешательства разница между группами постоянна), строгого теста нет, но полезны визуальные проверки при наличии многих временных точек. [16]
ступенчатое внедрение (ступенчатый поэтапный запуск по кластерам). Применять, когда в итоге нужно раскатить всем, но хочется сохранить причинную оценку: все кластеры стартуют в контроле и переходят к вмешательству в порядке, определённом рандомизацией; переход односторонний. [17] Этот дизайн часто выбирают, когда внедрение “по‑всем сразу” организационно невозможно, но требуется строгая оценка и управляемая логистика. [17]
Экономическая модель, формулы и критерии остановки
TCO и LCCA как основы
TCO. IBM определяет полную стоимость владения как расчёт полной стоимости продукта/сервиса на жизненном цикле, включая прямые и косвенные затраты, кратко‑ и долгосрочные расходы и экономию. [18]
LCCA. Whole Building Design Guide описывает анализ стоимости жизненного цикла как метод выбора альтернатив, которые удовлетворяют одинаковым требованиям, но отличаются начальной и операционной стоимостью; выбирают вариант, максимизирующий чистую экономию. [19]
Одностраничная таблица “затраты vs выгоды”
| Компонент | Что включаем | Тип | Где берём данные | Как считаем / что проверяем |
|---|---|---|---|---|
| Обследование процесса и базовый уровень | карта процесса, сегменты, базовый уровень выгрузки | Внедрение | CRM/тикеты, контакт‑центр, BI | фиксируется базовый уровень и “паспорт метрик” до пилота [7] |
| Данные и интеграции | доступы, события, ETL, логирование | Внедрение | логи каналов, события доменных систем | полнота логов, инварианты, готовность к SRM‑контролю [14] |
| TEVV и QA для ИИ | тестовые наборы, проверка достоверности, стресс-тестирование | Внедрение + Эксплуатация | разметка, обратная связь, инциденты | NIST рекомендует историю TEVV (тестирование, оценка, валидация и верификация) и проверку фактов для GenAI [20] |
| Инфраструктура/лицензии | модели/API, наблюдаемость, безопасность | Эксплуатация | использование, счета, SLO | OPEX = использование×тарифы + наблюдаемость + безопасность [18] |
| Мониторинг после деплоя | дрейф, качество, инциденты, регресс‑тесты | Эксплуатация | мониторинг‑дашборды, инцидент‑лог | NIST: мониторинг нужен из‑за реальных динамик и недетерминированности; практики незрелы → планировать заранее [2] |
| Снижение числа обращений/перехват ботом | обращения решены без человека | Выгода | аналитика бота, CRM | Экономия ≈ количество предотвращённых обращений × базовая стоимость одного обращения [21] |
| Улучшение FCR | меньше повторных касаний | Выгода | CRM/тикеты | FCR = (решено с первого обращения/всего)×100; оценка по сегментам [8] |
| Снижение AHT/FRT | быстрее первый ответ и решение | Выгода | контакт‑центр / чат | AHT и FRT по стандартным формулам; контроль “качество≠скорость” [22] |
| Избежание затрат | избежание будущего найма/роста затрат | Выгода | прогноз объёма, модель мощностей | часы_сэкономлены×тариф; допускается реинвестирование экономии [3] |
Формулы для запуска проекта
Ниже — набор формул, который удобно использовать как базовый калькулятор запуска. Он связывает процессные KPI поддержки с TCO/LCCA и с моделью экономии затрат / избежания затрат. [3] [9] [10] [18] [19]
AHT = (Время разговора + Время ожидания + Время постобработки) / Число взаимодействий
FCR (%) = Обращения, решённые с первого контакта / Все обращения * 100
ART = Общее время решения по закрытым обращениям / Число взаимодействий
CSAT (%) = Довольные ответы / Все ответы * 100
Базовая стоимость обращения = Базовый AHT * Стоимость минуты работы + Канальные затраты
Экономия за счёт снятия нагрузки = Подходящие обращения * Доля снятия нагрузки * Базовая стоимость обращения
Экономия за счёт ИИ-ассиста = Обращения с ИИ-подсказкой * (Базовый AHT - AHT с ИИ-ассистом)
* Стоимость минуты работы
Избежанные расходы = Предотвращённый найм * Месячная стоимость одного FTE
Валовый эффект в месяц = Экономия за счёт снятия нагрузки + Экономия за счёт ИИ-ассиста + Избежанные расходы
Чистый эффект в месяц = Валовый эффект в месяц - Месячные расходы на ИИ - Месячные расходы на поддержку и QA
Срок окупаемости, мес. = Стоимость внедрения / Чистый эффект в месяц
ROI за 12 месяцев (%) = ((12 * Чистый эффект в месяц) - Стоимость внедрения)
/ Стоимость внедрения * 100
Порог валовой выгоды на одно подходящее обращение
= (Стоимость внедрения / 12 + Месячные операционные расходы) / Подходящие обращения
Предельный ROI итерации k (%)
= (ΔВаловая выгода_k - ΔВнедрение_k - 12 * ΔОперационные расходы_k)
/ ΔВнедрение_k * 100- AHT — среднее время обработки обращения
- FCR — доля обращений, решённых с первого контакта
- ART — среднее время полного решения обращения
- CSAT — индекс удовлетворённости клиентов
- Базовая стоимость обращения — сколько стоит обработка одного обращения до внедрения
- Экономия за счёт снятия нагрузки — эффект от обращений, полностью закрытых без человека
- Экономия за счёт ИИ-ассиста — выигрыш от ускорения работы сотрудника с помощью ИИ
- Избежанные расходы — расходы, которых удалось избежать, например найм
- Валовый эффект в месяц — сумма выгод до вычета эксплуатационных расходов
- Чистый эффект в месяц — эффект после вычета расходов на ИИ, поддержку и QA
- Срок окупаемости — за сколько месяцев окупится внедрение
- ROI за 12 месяцев — возврат на инвестиции на годовом горизонте
- Порог валовой выгоды на одно подходящее обращение — минимальная выгода, при которой проект имеет смысл
Гипотетический пример финансовой оценки
Возьмём условный процесс поддержки по статусу заказа или груза. Все цифры ниже — не обещание результата, а иллюстрация того, как считать проект до пилота.
Исходные данные.
Обращений в месяц = 30 000
Доля подходящих = 60%
Подходящих обращений = 18 000
Базовый AHT = 7 мин
Стоимость часа работы с нагрузкой = 1 200 ₽
Стоимость минуты работы с нагрузкой = 20 ₽
Канальные затраты = 10 ₽
Доля снятия нагрузки = 35%
AHT с ИИ-ассистом = 5 мин
Предотвращённый найм = 2 FTE
Месячная стоимость одного FTE = 150 000 ₽
Месячные расходы на ИИ = 750 000 ₽
Месячные расходы на поддержку и QA = 0 ₽
Стоимость внедрения = 5 200 000 ₽Расчёт.
Базовая стоимость обращения = 7 * 20 + 10 = 150 ₽
Экономия за счёт снятия нагрузки = 18 000 * 35% * 150 = 945 000 ₽ / месяц
Обращения с ИИ-подсказкой = 18 000 * 65% = 11 700
Экономия за счёт ИИ-ассиста = 11 700 * (7 - 5) * 20 = 468 000 ₽ / месяц
Избежанные расходы = 2 * 150 000 = 300 000 ₽ / месяц
Валовый эффект в месяц = 945 000 + 468 000 + 300 000 = 1 713 000 ₽ / месяц
Чистый эффект в месяц = 1 713 000 - 750 000 = 963 000 ₽ / месяц
Срок окупаемости = 5 200 000 / 963 000 ≈ 5,4 месяца
ROI за 12 месяцев = ((12 * 963 000) - 5 200 000) / 5 200 000 * 100 ≈ 122%- Базовая стоимость обращения — исходная стоимость до внедрения
- Экономия за счёт снятия нагрузки — эффект от полного автоматического закрытия части обращений
- Экономия за счёт ИИ-ассиста — эффект от сокращения времени работы сотрудника
- Избежанные расходы — затраты, которых удалось избежать за счёт предотвращённого найма
- Валовый эффект в месяц — суммарная выгода до вычета расходов на эксплуатацию
- Чистый эффект в месяц — выгода после вычета расходов на ИИ, поддержку и QA
- ROI за 12 месяцев — годовой возврат на инвестиции
Отдельно полезно считать порог входа для проекта.
Порог валовой выгоды на одно подходящее обращение = (5 200 000 / 12 + 750 000) / 18 000 ≈ 65,7 ₽- Порог валовой выгоды — нижняя граница выгоды на одно подходящее обращение, при которой проект остаётся экономически оправданным
В этом примере фактическая валовая выгода на один подходящий контакт равна.
Фактическая валовая выгода на одно подходящее обращение = 1 713 000 / 18 000 ≈ 95,2 ₽То есть проект проходит годовой порог окупаемости. Но это ещё не означает автоматическое масштабирование: если при этом CSAT падает ниже базового уровня, растёт доля критических ошибок или увеличивается доля жалоб, решение должно уходить в доработку или в стоп даже при формально положительной экономике. [7] [13]
Предельная эффективность и критерии остановки
Чтобы не “улучшать бесконечно”, вводится правило предельной эффективности:
- Каждая итерация имеет ΔВыгода и ΔЗатраты на внедрение (внедрение) + ΔЭксплуатационные затраты (эксплуатация).
- Продолжаем, если ожидаемая предельная чистая выгода положительна и ограничения по качеству не ухудшаются — логика соответствует выбору альтернатив, максимизирующих чистую экономию на горизонте владения.[19]
Останавливаем, если:
- эффект ниже порога практической значимости, даже если есть статистическая значимость; ASA предупреждает против решений только по p‑value.[13]
- эксперимент невалиден (SRM/проблемы с качеством данных), а стоимость исправления выше ожидаемой выгоды.[14]
- эксплуатационные затраты (мониторинг/инциденты/TEVV — тестирование, оценка, проверка и валидация) начинают «съедать» эффект; NIST подчёркивает, что мониторинг после внедрения критически важен, но масштабировать его сложно.[2]
Как избегать увольнений
Два механизма, которые нужно явно вшить в модель:
- Избежание затрат вместо «сократить людей». CMS описывает экономию и предотвращение затрат (прямую экономию расходов/предотвращения затрат) как часть бизнес-кейса и прямо допускает реинвестирование сэкономленного в программу, без «изъятия бюджета».[3]
- Реинвестирование времени и перераспределение ролей. BCG подчёркивает, что автоматизация задач не равна сокращению рабочих мест; часть ролей будет «переформатирована», а также предупреждает, что сокращение персонала «сверх замещения» может привести к падению производительности и потере институциональных знаний.[23]
Пример для публикации: ИИ‑агент поддержки транспортной компании
Сценарий. Клиент международной перевозки спрашивает: статус груза, события отслеживания, ориентировочный ETA, причины задержек, документы, ограничения, окно доставки. Хороший паттерн — «быстрые справки + трекинг + управляемая эскалация человеку».
Какие метрики собирать и откуда брать данные
Источники данных (типовой минимум):
- CRM/система обработки обращений: категория обращения, исход (решено/эскалировано), повторные обращения.
- Каналы поддержки: чат‑логи, запись звонков/метаданные, времена ответа/решения.
- Доменные «источники истины»: статусы, события маршрута, сканы, исключения (задержки/задержание), расчёт ETA.
Прокси‑метрики и формулы:
- FCR: доля обращений, решённых «с первого касания» (одно касание / все обращения).[8]
- FRT: скорость первого ответа. [9]
- AHT: среднее время обработки обращения.[10]
- Снятие нагрузки / автоматическое закрытие: доля обращений, решённых ботом без участия человека (определение фиксируется в «паспорте метрик»). На практике такие метрики используются в индустрии виртуальных ассистентов и фигурируют в публичных материалах FedEx.[21]
OEC для данного кейса (пример формулировки).
Стоимость обработки одной успешно решённой заявки по отслеживанию/ETA ↓ при CSAT не ниже базового уровня и доле критических ошибок ≤ Y; доля эскалаций ≤ Z. Логика OEC соответствует рекомендациям по метрикам, измеримым в окне эксперимента и причинно связанным с долгосрочными целями. [7]
Когда внедрение оправдано и когда нет
Оправдано, когда:
- высока доля повторяющихся запросов “где груз/когда” и стоимость контакта значима;
- есть качественные данные трекинга, иначе бот будет производить критические ошибки;
- можно построить валидную оценку (A/B или пошаговое внедрение по волнам).[24]
Не оправдано, когда:
- объём обращений мал (нет масштаба для окупаемости TCO — совокупной стоимости владения);
- данные на входе слабые (ошибки в статусе/ETA несут высокую репутационную цену);
- нет ресурса на эксплуатацию: мониторинг и TEVV для ИИ должны быть запланированы как отдельная работа.[25]
Что взять из практики логистических игроков
DHL[26] публично описывает GenAI‑ассистента в myDHLi как чат-помощника 24/7, который помогает с вопросами и позволяет запрашивать, среди прочего, статус отправлений и контактные данные. [27]
Для Viva у DHL Freight публично описаны ограничения: нет доступа к вебу, не обрабатываются сложные запросы, есть передача человеку, а отслеживание строится по идентификатору отправления. [28]
Maersk[29] в публичных руководствах указывает доступность чат-бота 24/7 для пользователей, вошедших в систему, и возможность передать запрос сотруднику в рабочие часы — это хороший шаблон рабочей модели: бот решает типовые задачи, человек — сложные. [30]
Мониторинг и TEVV (проверка, оценка, валидация и верификация) для ИИ-агента
Для версии, публикуемой наружу, достаточно принципа: «предрелизные тесты не заменяют мониторинг в продакшене». NIST подчёркивает, что мониторинг после внедрения критически важен для проверки надёжности в реальных сценариях, отслеживания неожиданных результатов и последствий интеграции; также вводит категории мониторинга (функциональность/операционная работа/человеческий фактор/безопасность/соответствие/крупномасштабные последствия). [2]
Для генеративных систем профиль NIST GenAI рекомендует: сравнивать ответы с эталонными данными, внедрять и документировать техники проверки фактов, сохранять историю TEVV и обеспечивать архитектурную возможность мониторинга результатов и производительности. [31]
Реальные кейсы и применение рамки оценки
FedEx виртуальный ассистент как «эталон для оценки» поддержки
В историческом кейсе FedEx, представленном на конференции по интеллектуальным ассистентам, публично приводились примерно 6,7 млн разговоров, около 81% FCR, порядка 52% снижения нагрузки на операторов и около 26% перевода обращений на другой канал. Для рамки оценки это полезно как ориентир по диапазону зрелых косвенных метрик в поддержке, хотя это не аудированная корпоративная отчётность, а краткое описание кейса с конференции. [32]
- косвенные метрики (например, доля решённых без участия человека и доля переводов на оператора) подходят для OEC (общая экономическая ценность) как «стоимость одного решённого запроса при ограничителях по качеству»;[33]
- эксплуатация должна включать регулярный цикл улучшения контента и маршрутизации (в презентации FedEx это выделено как практический контур развития).[32]
Klarna: как «цифры эффекта» переводить в вашу модель
Klarna публично заявляла (февраль 2024): 2,3 млн диалогов за месяц, около двух третей чатов поддержки, эквивалент работы 700 FTE (штатных единиц), CSAT на уровне живых сотрудников, снижение повторных обращений на 25% и время решения менее 2 минут против 11 минут ранее. Компания также оценивала ожидаемое улучшение прибыли примерно на $40 млн в 2024 году. Это один из редких публичных кейсов, где операционные метрики связаны с заявленным экономическим эффектом. [35]
Как применять вашу модель (без притягивания “чужих цифр” как обещаний):
- Прокси-метрики: охват (доля обращений, обработанных ИИ), доля повторных обращений, время решения.[35]
- Результат/OEC: стоимость обслуживания одного решённого случая при ограничителях качества (CSAT/ошибки/переводы на оператора). Логика через OEC — из практик экспериментов.[7]
- Экономика: «эквивалент 700 FTE» в вашем кейсе превращается не в лозунг, а в два сценария:
- экономия затрат (если сокращается реальная оплачиваемая нагрузка),
- предотвращение затрат (если рост объёма не требует найма). Определение расчёта экономии времени «сэкономленные часы × ставка» и допустимость реинвестирования описаны в материале CMS.[3]
- Риск: для GenAI критичны TEVV, мониторинг и политика проверки фактов/эталонных данных.[36]
Логистические паттерны внедрения без раскрытой экономики
DHL описывает GenAI-ассистента в myDHLi как чат-бот 24/7 для статуса отправлений, контактных данных и общих тем поддержки. В публичном пресс-материале также говорится, что платформой пользуются более 20 000 клиентов, а в среднем отслеживается более 450 000 отправлений в месяц. Это хороший пример масштабного логистического кейса, где публично показываются внедрение и объём, но не раскрываются стоимость одного решённого обращения или срок окупаемости. [45]
DHL Viva отдельно интересен как пример зрелого ограничения области применения: бот отвечает 24/7, умеет отслеживание и FAQ, но сложные и персонализированные запросы переводятся на человека через явную передачу. [28]
Maersk показывает тот же паттерн: самообслуживание сначала проходит через виртуального ассистента, после чего пользователь может выбрать передачу запроса сотруднику. Для процессов, где полная автоматизация нецелесообразна, это хороший операционный подход: ИИ снимает повторяющийся поток и ускоряет маршрутизацию, а человек закрывает сложные кейсы. [30]
UPS использует виртуальный ассистент в поддержке по отслеживанию для типовых сценариев — отслеживание, исправление адреса, статус претензии, пропущенная доставка и другие частые запросы. Это хороший пример правильного старта: сначала автоматизируются узкие, частые и слаборисковые запросы, а уже затем расширяется область применения. [46]
FedEx и в текущих страницах поддержки (страницах поддержки) продолжает продвигать виртуальный ассистент поддержки как отдельный слой самообслуживания. Это важно не как разовый пилот, а как подтверждение устойчивой операционной модели (операционная модель): ассистент становится частью оказания сервиса, а не демонстрацией технологии. [47]
Общий вывод из кейсов прост: кейсы с числами полезны для калибровки разумных диапазонов снижения обращений (deflection), первого контакта без повторного обращения (FCR) и экономии времени (экономия времени); кейсы без публичной экономики — для проектирования охвата (границ решения), запасного сценария (резервный сценарий) и ограничений. Но ни те, ни другие не заменяют локальный эксперимент на собственных данных. [32] [35] [45]
Выводы и что делать дальше
Ключевые выводы.
- Автоматизация — с ИИ или без него — стоит рассматривать не как разработку отдельной функции, а как инвестиционный процесс с заранее заданной логикой оценки. [7] [18]
- Качество ИИ — необходимое, но недостаточное условие успеха проекта: решение о масштабировании должно опираться на OEC, процессные ограничения и защитные рамки, а также на удельную экономику (экономика единицы), а не только на высокий показатель модели (оценка модели).[7]
- Критерий успеха — переход от метрик качества к метрикам процесса и далее к бизнес-метрикам: от корректности ответа — к FCR, FRT, AHT и CSAT, а от них — к стоимости одного решённого обращения, предотвращённому найму, сроку окупаемости и ROI. [7] [9] [10] [18][7] [9] [10] [18]
- Инженер в такой модели не просто делает кнопку, а переводит намерение заказчика в гипотезу, OEC, архитектуру пилота и правило принятия решения: масштабировать, дорабатывать или остановить.[7]
Что делать дальше
- Выбрать один процесс с повторяющимся потоком, понятной единицей учёта и допустимым человеческим резервным вариантом (резервный сценарий с участием человека) — типично это отслеживание статуса (отслеживание статуса), FAQ, исключения по доставке (исключения по доставке), первичная сортировка претензий (первичная сортировка претензий) или первичная маршрутизация запросов.[28] [30] [46]
- До разработки зафиксировать паспорт метрик (паспорт метрик): OEC, прокси-метрики, защитные рамки, окно наблюдения и экономический порог.[7]
- До пилота посчитать базовую экономику процесса по простым формулам: базовая стоимость обращения, потенциал снятия нагрузки, сокращение AHT, предотвращённые затраты (избежание будущих затрат), ежемесячные операционные расходы, срок окупаемости и порог безубыточности в первый год.[18]
- Запускать не полный продукт, а ограниченный пилот с полным логированием, явной передачей человеку и правилом продолжения: масштабировать, если OEC улучшен и следующая итерация тоже даёт положительный ROI; останавливать, если эффект не подтверждён или его съедает сопровождение.[28]
Список источников
- American Statistical Association. (2016, March 7). American Statistical Association releases statement on statistical significance and p-values. [13]
- Boston Consulting Group. (2026, April 3). AI will reshape more jobs than it replaces. [23]
- Campbell, M. J., Hemming, K., & Taljaard, M. (2019). The stepped wedge cluster randomised trial: what it is and when it should be used. Medical Journal of Australia. [17]
- Centers for Medicare & Medicaid Services. (n.d.). Training video: Cost savings and avoidance (transcript). [3]
- Columbia University Mailman School of Public Health. (n.d.). Difference-in-Difference Estimation. [16]
- Genesys Cloud Resource Center. (n.d.). Average handle time (AHT). [10]
- IBM. (2025, October 13). What is total cost of ownership (TCO)? [18]
- Intercom. (2024, September 23). Decoding customer service metrics: A straightforward guide. [9]
- Klarna. (2024, February 27). Klarna AI assistant handles two-thirds of customer service chats in its first month. [35]
- Kohavi, R., Deng, A., Frasca, B., Walker, T., Xu, Y., & Pohlmann, N. (2013). Online controlled experiments at large scale. [1]
- Maiden, G. (2017, September). Enhancing the FedEx experience: Leveraging virtual assistants, artificial intelligence and natural language understanding (presentation). [32]
- Microsoft Research. (2020, September 14). Diagnosing sample ratio mismatch in A/B testing. [14]
- NIST. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0) (NIST AI 100-1). [42]
- NIST. (2024). Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile (NIST AI 600-1). [43]
- NIST. (2026, March). Challenges to the monitoring of deployed AI systems (NIST AI 800-4). [2]
- NIST. (n.d.). AI Test, Evaluation, Validation and Verification (TEVV). [44]
- NIST/SEMATECH. (n.d.). e‑Handbook of Statistical Methods: Sample sizes required for testing proportions. [12]
- Whole Building Design Guide. (n.d.). Life-Cycle Cost Analysis (LCCA). [19]
- Zendesk. (2026, January 15). What is first contact resolution (FCR)? [8]
- DHL Group. (2024). For increased usability and efficiency, myDHLi meets GenAI. [45]
- FedEx. (n.d.). Email FedEx / customer support. [47]
- UPS. (n.d.). Tracking support. [46]
- [1] [4] [5] [6] [24] [37] [40] Controlled Experiments at Scale — https://www.exp-platform.com/Documents/2013%20controlledExperimentsAtScale.pdf
- [2] [25] Challenges to the monitoring of deployed AI systems: Center for AI Standards and Innovation — https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.800-4.pdf
- [3] [39] cms.gov — https://www.cms.gov/files/document/training-video-cost-savings-avoidance-transcript.pdf
- [7] Metrics for Experimentation and the Overall Evaluation Criterion (Chapter 7) — Trustworthy Online Controlled Experiments — https://www.cambridge.org/core/books/trustworthy-online-controlled-experiments/metrics-for-experimentation-and-the-overall-evaluation-criterion/4EA73D169EC43B58991D6824717E8FD3
- [8] [29] What is first contact resolution (FCR)? Benefits + best … — https://www.zendesk.com/blog/first-contact-resolution-friend-foe-frenemy/?utm_source=chatgpt.com
- [9] [22] Decoding Customer Service Metrics: A Straightforward Guide — https://www.intercom.com/learning-center/customer-service-metrics?utm_source=chatgpt.com
- [10] average handle time (AHT) — Genesys Cloud Resource Center — https://help.mypurecloud.com/glossary/average-handle-time-aht/?utm_source=chatgpt.com
- [11] [14] [41] Diagnosing Sample Ratio Mismatch in A/B Testing — Microsoft Research — https://www.microsoft.com/en-us/research/articles/diagnosing-sample-ratio-mismatch-in-a-b-testing/
- [12] NIST: Challenges to the Monitoring of Deployed AI Systems — https://www.linkedin.com/pulse/nist-challenges-monitoring-deployed-ai-systems-iason-vgj8f?utm_source=chatgpt.com
- [13] [38] American Statistical Association Releases Statement on Statistical Significance and P-Values — https://www.amstat.org/asa/files/pdfs/p-valuestatement.pdf
- [15] Microsoft Word — SRM Paper — Preprint — https://exp-platform.com/Documents/2019_KDDFabijanGupchupFuptaOmhoverVermeerDmitriev.pdf
- [16] Difference-in-Difference Estimation | Columbia Public Health | Columbia University Mailman School of Public Health — https://www.publichealth.columbia.edu/research/population-health-methods/difference-difference-estimation
- [17] The stepped wedge cluster randomised trial: what it is and when it should be used — https://eprints.whiterose.ac.uk/id/eprint/142728/3/MJA_Stepped_wedge_design__5_submitted.pdf
- [18] What Is Total Cost of Ownership (TCO)? | IBM — https://www.ibm.com/think/topics/total-cost-of-ownership
- [19] Life-Cycle Cost Analysis (LCCA) | WBDG — Whole Building Design Guide — https://www.wbdg.org/resources/life-cycle-cost-analysis-lcca
- [20] [31] [36] [43] Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile — https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
- [21] FedEx Virtual Assistant — https://opusresearch.net/pdfs/FedEx_IAConf_SF_2017.pdf?utm_source=chatgpt.com
- [23] AI Will Reshape More Jobs Than It Replaces | BCG — https://web-assets.bcg.com/pdf-src/prod-live/ai-will-reshape-more-jobs-than-it-replaces.pdf
- [26] [32] [33] FedEx Virtual Assistant — v2 with speaker notes_final — https://opusresearch.net/pdfs/FedEx_IAConf_SF_2017.pdf
- [27] myDHLi: A New Generative AI-Powered Assistant — https://www.dhl.com/us-en/home/global-forwarding/latest-news-and-webinars/mydhli-generative-ai-logistics.html?utm_source=chatgpt.com
- [28] AI-Based Customer Service Assistant Viva Sweden — https://www.dhl.com/se-en/home/freight/help-center-for-european-road-and-rail/welcome-to-viva.html
- [30] Maersk.com ChatBot Guide — https://www.maersk.com/~/media_sc9/maersk/local-information/files/asia-pacific/malaysia/chatbot-guidebook-updated.pdf?utm_source=chatgpt.com
- [34] [35] Klarna AI assistant handles two-thirds of customer service … — https://www.klarna.com/international/press/klarna-ai-assistant-handles-two-thirds-of-customer-service-chats-in-its-first-month/?utm_source=chatgpt.com
- [42] Artificial Intelligence Risk Management Framework (AI RMF 1.0) — https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf?utm_source=chatgpt.com
- [44] AI Test, Evaluation, Validation and Verification (TEVV) | NIST — https://www.nist.gov/ai-test-evaluation-validation-and-verification-tevv
- [45] For increased usability and efficiency, myDHLi meets GenAI — https://group.dhl.com/en/media-relations/press-releases/2024/for-increased-usability-and-efficiency-mydhli-meets-genai.html
- [46] Tracking support | UPS — https://filexfer.ups.com/us/en/support/tracking-support
- [47] Email FedEx / customer support — https://www.fedex.com/en-us/customer-support/email-fedex.html