Реальное распознавание речи в Amazon SageMaker AI и vLLM: как собрать голосовое приложение со стримингом

Голосовые агенты, сервисы живых субтитров, аналитика контакт-центров и инструменты доступности зависят от распознавания речи в реальном времени: приложение непрерывно отправляет аудио и одновременно получает обратно текст транскрипции по одному постоянному соединению. Обычный подход request-response здесь не подходит, потому что распознавание не может начаться, пока не получена вся аудиозапись, а это добавляет задержку и ломает ощущение работы в реальном времени.
Начиная с ноября 2025 года можно непрерывно передавать данные в обоих направлениях между клиентами и контейнерами с моделями с помощью двунаправленного стриминга Amazon SageMaker AI для real-time inference. vLLM теперь позволяет распознавать аудио в реальном времени через Realtime API, где для двунаправленного стриминга между клиентом и сервером используются WebSocket.
В этом материале мы объединяем эти две возможности. Показано, как развернуть Voxtral-Mini-4B-Realtime-2602, компактную модель Mistral AI для распознавания речи в реальном времени, на конечной точке SageMaker AI с использованием контейнера vLLM и двунаправленного стриминга. В результате получается полностью управляемый сервис speech-to-text, в котором аудио поступает внутрь, а транскрипция возвращается обратно в реальном времени. Пример можно повторить по материалам из GitHub-репозитория.
Ключевые возможности, необходимые для голосовых AI-приложений
Построение production-решения для голосового AI — будь то голосовой агент, сервис живых субтитров или pipeline аналитики контакт-центра — требует набора инфраструктурных компонентов, которые работают вместе в условиях жестких ограничений по задержке. Amazon SageMaker AI и vLLM закрывают разные части этого стека, а вместе дают end-to-end решение, которое убирает лишнюю инженерную работу. Ниже перечислено, что нужно таким приложениям и как это реализуют отдельные компоненты:
- Модель распознавания речи в реальном времени с эффективным GPU-serving. В основе любого голосового AI-приложения лежит speech-to-text (ASR) модель, которая обрабатывает аудио инкрементально и выдает токены транскрипции по мере поступления звука, а не после завершения записи. vLLM обслуживает такие модели через Realtime API — нативную конечную точку WebSocket по адресу
/v1/realtime, которая поддерживает несколько speech-моделей, а также использует piecewise CUDA graph execution, чтобы снижать накладные расходы на запуск GPU-ядeр и тем самым уменьшать задержку на токен во время потокового распознавания. Поскольку vLLM — open source, вы сохраняете полный контроль над конфигурацией модели, quantization и настройками compilation без vendor lock-in на слое обслуживания. - Инфраструктура двунаправленного стриминга. Обычные request-response API заставляют клиента сначала выгрузить весь аудиофайл, и только потом сервер начинает обработку. Голосовым приложениям нужен постоянный full-duplex-канал, по которому клиент стримит аудио, а сервер одновременно возвращает транскрипцию. SageMaker AI решает это с помощью нативного двунаправленного стриминга HTTP/2 на порту 8443, автоматически выполняя bridge между HTTP/2 event stream-протоколом на стороне клиента и WebSocket на стороне контейнера. Вам не нужно строить или обслуживать этот слой перевода протоколов — SageMaker AI делает это прозрачно.
- Обработка и кодирование аудио. Сырые аудиоданные с микрофонов или телеком-систем приходят в разных форматах и с разными sample rate. До попадания в модель их нужно пересэмплировать (обычно до 16 kHz mono PCM16), разбить на подходящие по размеру фрагменты и закодировать в base64 для передачи. Эту конвертацию выполняет клиентский pipeline, а протокол задает Realtime API vLLM: base64 PCM16-фрагменты поступают по WebSocket, а токены транскрипции возвращаются обратно, при этом двунаправленный поток SageMaker AI переносит оба направления одновременно.
- Управление соединением и отказоустойчивость. SageMaker AI поддерживает WebSocket-соединения с ping/pong keepalive-кадрами, проверяет здоровье контейнера и дает мониторинг на уровне endpoint через Amazon CloudWatch. Это обеспечивает production-наблюдаемость и устойчивость соединения без собственной инструментации.
Иными словами, vLLM дает высокопроизводительное open-source обслуживание моделей с нативным WebSocket-стримингом, а SageMaker AI оборачивает это в managed-инфраструктуру с bridge протоколов, health monitoring и operational tooling. Вместе они позволяют перейти от speech-модели на Hugging Face к production-ready сервису распознавания речи в реальном времени без создания собственной streaming-инфраструктуры и без управления GPU-серверами.
Обзор решения
К концу этого walkthrough у вас будет:
- Пользовательский Docker-контейнер на базе SageMaker AI vLLM Deep Learning Container с включенным двунаправленным стримингом.
- Конечная точка SageMaker AI, на которой запущена Voxtral-Mini-4B-Realtime-2602.
- Python-клиент, который отправляет аудиофайлы на endpoint и получает транскрипцию в реальном времени с помощью SageMaker AI bidirectional streaming SDK.
- Живой демо-режим на базе Gradio, который распознает речь прямо во время разговора.
Решение соединяет три уровня:

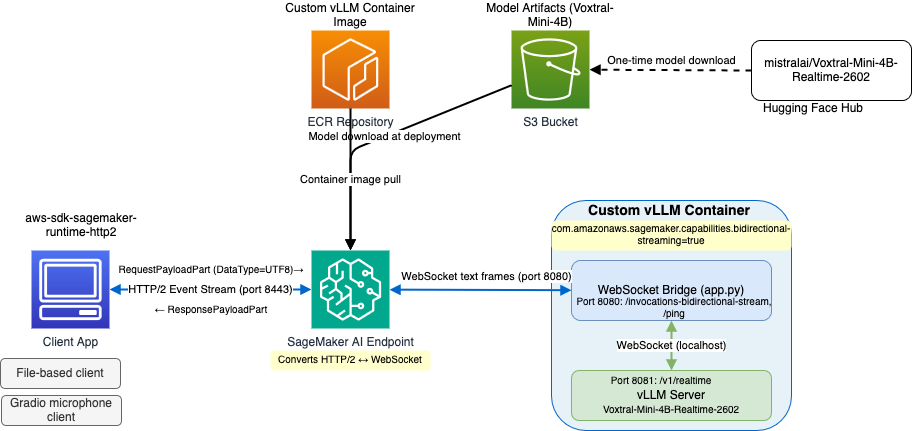
Client to SageMaker AI: ваше приложение подключается к runtime endpoint SageMaker AI на порту 8443 по HTTP/2, который поддерживает мультиплексированный двунаправленный стриминг. Каждое JSON-сообщение в протоколе vLLM Realtime, например input_audio_buffer.append или transcription.delta, отправляется внутри RequestPayloadPart с DataType, установленным в «UTF8». Это сообщает SageMaker AI, что данные нужно передавать как WebSocket text frame. Ответные сообщения приходят как события ResponsePayloadPart.
SageMaker AI to Docker Container: SageMaker AI автоматически выполняет bridge между HTTP/2 event stream и WebSocket-протоколами. Он устанавливает WebSocket-соединение с контейнером по адресу ws://localhost:8080/invocations-bidirectional-stream — именно этот путь SageMaker AI ожидает для двунаправленного стриминга — и передает data frames в обоих направлениях. Когда в клиенте задано DataType="UTF8", bridge отправляет WebSocket text frames в контейнер.
Docker Container: внутри контейнера легкий FastAPI-bridge (app.py) слушает порт 8080 по пути /invocations-bidirectional-stream. Когда он получает WebSocket-соединение от SageMaker AI, он открывает второе WebSocket-соединение к Realtime API vLLM по адресу ws://localhost:8081/v1/realtime и пересылает сообщения в обоих направлениях. Bridge выполняет преобразование маршрута между ожидаемым путем SageMaker AI и нативной конечной точкой vLLM, а text frames проходят без изменений. Сервер vLLM работает на порту 8081 и предоставляет Realtime API по стандартной WebSocket-окончании /v1/realtime без необходимости патчить исходный код. Bridge также проксирует health-check /ping к health endpoint vLLM, удовлетворяя hosting contract SageMaker AI.
Протокол Realtime API
Realtime API предоставляет потоковую передачу аудио и распознавание речи через WebSocket, позволяя выполнять real-time speech-to-text по мере записи звука. Перед отправкой аудио нужно закодировать его как base64 PCM16 с sample rate 16 kHz и mono-каналом. Последовательность сообщений в протоколе выглядит так:
- Клиент подключается к
ws://host/v1/realtime. - Сервер отправляет событие
session.created. - Клиент при необходимости отправляет
session.updateс моделью и параметрами. - Клиент отправляет
input_audio_buffer.commit, когда готов передать аудио. - Клиент отправляет события
input_audio_buffer.appendс фрагментами base64 PCM16. - Сервер отправляет события
transcription.deltaс инкрементальным текстом. - Сервер отправляет
transcription.doneс финальной транскрипцией и статистикой использования. - Повторять с шага 5 для следующей реплики.
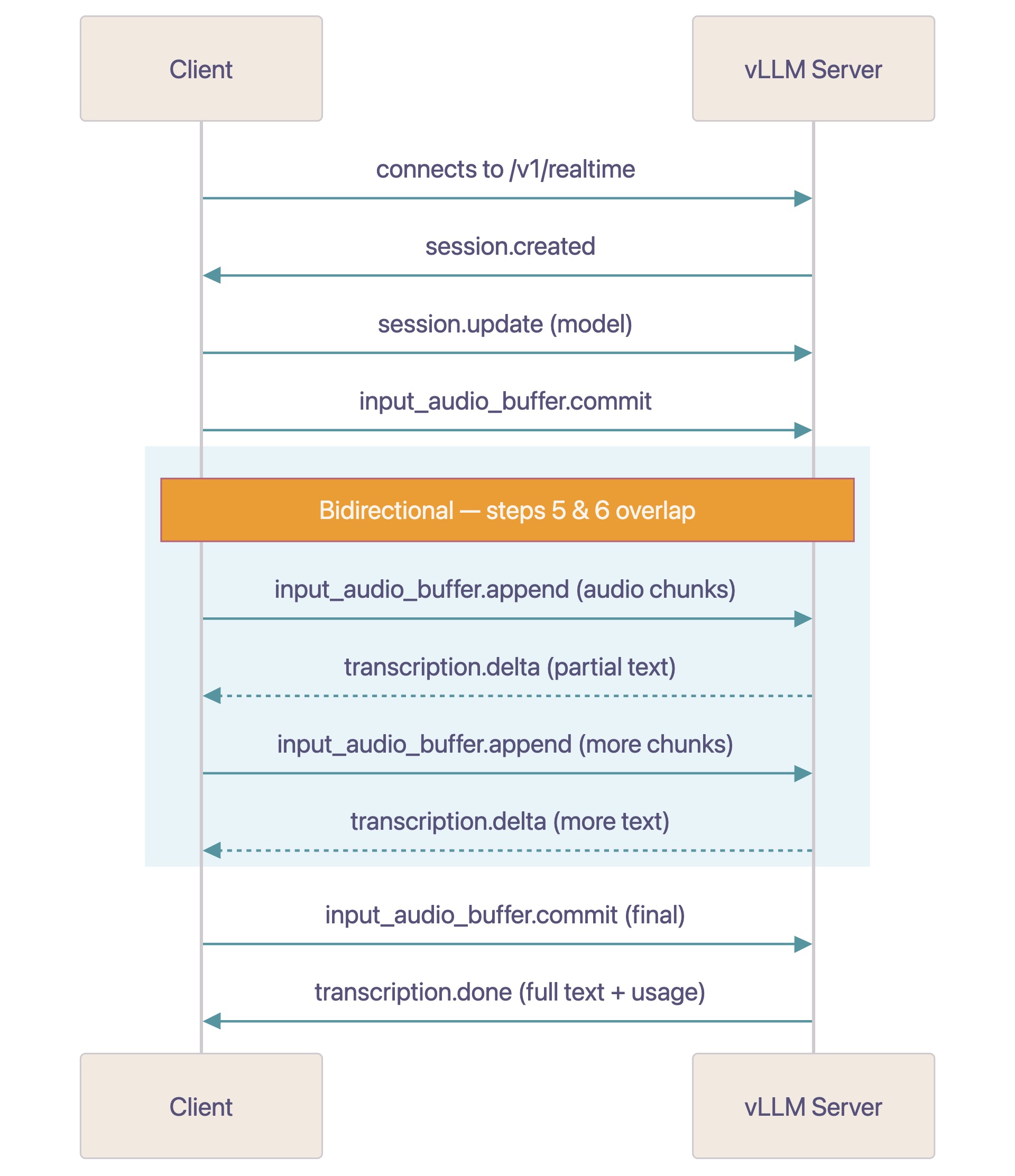
Модель начинает распознавание, как только получает достаточно аудиоконтекста, и отправляет токены transcription.delta обратно клиенту, пока клиент продолжает посылать аудиофрагменты. Не нужно ждать, пока будет отправлено все аудио, чтобы начать получать результаты. При необходимости клиент может отправить input_audio_buffer.commit с final=True, чтобы сигнализировать о завершении ввода аудио; это полезно при потоковой передаче аудиофайлов.
Предварительные требования
- Аккаунт AWS с правами SageMaker AI (SageMaker AI permissions), включая
sagemaker:InvokeEndpoint*для двунаправленного стриминга. - Окружение Docker (SageMaker AI Studio с включенным Docker или локальная машина).
- Python 3.12+.
- Доступ к модели Voxtral-Mini-4B-Realtime-2602 на Hugging Face.
- Пакет Python aws-sdk-sagemaker-runtime-http2 для вызова API двунаправленного стриминга.
Сборка пользовательского контейнера vLLM
Мы начинаем с SageMaker AI vLLM Deep Learning Container и добавляем три вещи: Docker-label для двунаправленного стриминга, WebSocket-bridge, который переводит между ожидаемыми маршрутами SageMaker AI и нативными путями API vLLM, а также entrypoint, запускающий оба процесса.
Dockerfile
FROM public.ecr.aws/deep-learning-containers/vllm:0.17.1-gpu-py312-cu129-ubuntu22.04-sagemaker-v1.0-soci
# Сообщаем SageMaker AI, что контейнер поддерживает двунаправленный стриминг
LABEL com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true
WORKDIR /opt/ml/code
# Устанавливаем зависимости bridge
COPY requirements.txt .
RUN pip install --upgrade --no-cache-dir -r requirements.txt
# WebSocket-bridge: маршрутизирует /invocations-bidirectional-stream → /v1/realtime
COPY app.py .
COPY sagemaker-entrypoint.sh entrypoint.sh
RUN chmod +x entrypoint.sh
ENTRYPOINT ["./entrypoint.sh"]
HEALTHCHECK --interval=30s --timeout=10s --start-period=120s --retries=3 \
CMD curl -f http://localhost:8080/ping || exit 1
Docker-label com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true сообщает SageMaker AI, что контейнер поддерживает двунаправленный стриминг. Без этого label SageMaker AI не будет устанавливать WebSocket-соединения с контейнером.
Bridge (app.py) — это небольшое приложение FastAPI, которое слушает порт 8080 на стороне SageMaker AI и перенаправляет WebSocket-соединения к /v1/realtime vLLM на внутреннем порту 8081. Оно также проксирует health-check /ping к /health vLLM.
VLLM_WS_URL = "ws://localhost:8081/v1/realtime"
@app.websocket("/invocations-bidirectional-stream")
async def websocket_bridge(sm_ws: WebSocket):
await sm_ws.accept()
async with websockets.connect(VLLM_WS_URL) as vllm_ws:
async def sm_to_vllm():
"""Передача SageMaker AI → vLLM."""
while True:
message = await sm_ws.receive()
if "text" in message and message["text"]:
await vllm_ws.send(message["text"])
elif "bytes" in message and message["bytes"]:
# Резервный вариант для клиентов не в UTF8
await vllm_ws.send(message["bytes"].decode("utf-8"))
async def vllm_to_sm():
"""Передача vLLM → SageMaker AI."""
async for msg in vllm_ws:
if isinstance(msg, str):
await sm_ws.send_text(msg)
elif isinstance(msg, bytes):
await sm_ws.send_bytes(msg)
await asyncio.gather(sm_to_vllm(), vllm_to_sm())
Поскольку клиент задает DataType="UTF8", SageMaker AI передает в bridge text frames, а тот отправляет их напрямую в vLLM по адресу /v1/realtime, без преобразования типа фрейма. Декодирование bytes в sm_to_vllm — это запасной путь для клиентов, которые не задают DataType.
Развертывание на конечной точке SageMaker AI
Мы развертываем решение на real-time endpoint SageMaker AI, который будет обслуживать запросы.
Настройка окружения модели и развертывание модели
Переменные окружения SM_VLLM_* задают параметры сервера vLLM:
vllm_env = {
"SM_VLLM_MAX_MODEL_LEN": "45000",
"SM_VLLM_COMPILATION_CONFIG": '{"cudagraph_mode": "PIECEWISE"}'
}
Voxtral-Mini-4B поддерживает до 262 144 токенов контекста. Здесь мы задаем MAX_MODEL_LEN=45000, чего достаточно, чтобы в live-режиме записывать примерно один час аудио (3600 секунд / 0,08 секунды на токен). Это значение нужно подбирать под ожидаемую длительность аудио. Параметр COMPILATION_CONFIG с cudagraph_mode: PIECEWISE дает CUDA graph-оптимизацию и повышает пропускную способность inference.
Следующий фрагмент кода создает endpoint SageMaker AI:
# Создаем модель
voxtral_model = Model.create(
model_name=model_name,
primary_container=ContainerDefinition(
image=inference_image,
model_data_source=ModelDataSource(
s3_data_source=S3ModelDataSource(
s3_uri=f"{model_artifact}/",
s3_data_type="S3Prefix",
compression_type="None",
)
),
environment=vllm_env
),
execution_role_arn=role,
)
# Создаем конфигурацию endpoint
endpoint_config = EndpointConfig.create(
endpoint_config_name=endpoint_config_name,
production_variants=[
ProductionVariant(
variant_name="AllTraffic",
model_name=model_name,
initial_variant_weight=1.0,
instance_type=instance_type,
initial_instance_count=1,
model_data_download_timeout_in_seconds=health_check_timeout,
)
]
)
# Создаем endpoint
endpoint = Endpoint.create(
endpoint_name=endpoint_name,
endpoint_config_name=endpoint_config_name
)
endpoint.wait_for_status("InService")
Тестирование с двунаправленным стримингом
Когда endpoint запущен, мы вызываем его с помощью Python SDK aws-sdk-sagemaker-runtime-http2. Этот SDK общается через HTTP/2 event streams на порту 8443 runtime endpoint SageMaker AI.
Потоковая передача аудио и получение транскрипции
Репозиторий включает полный клиент sagemaker_bidi_client.py, который оборачивает bidirectional streaming SDK в класс SageMakerRealtimeClient. Когда запускается transcribe_audio(), он сначала отправляет событие session.update для выбора модели, а затем передает аудиофайл кусками PCM16 по 4 KB. Receive loop работает как фоновая asyncio.Task, а основная coroutine отправляет аудиофрагменты так, чтобы оба направления HTTP/2-потока были активны одновременно.
Ключевая деталь, делающая это перекрытие заметным, — await asyncio.sleep(chunk_duration) после каждой отправки. Эта пауза синхронизирует передачу с воспроизведением в реальном времени (~128 мс на кусок 4 KB при 16 kHz) и отдает управление event loop, чтобы receive task успевал обрабатывать события transcription.delta, пока новые аудиоданные еще передаются. Без этого уступа chunks отправлялись бы быстрее, чем модель успевает генерировать вывод, и взаимодействие выглядело бы последовательным, хотя underlying stream остается двунаправленным. На стороне приема цикл разворачивается по типу события: обычные события ResponseStreamEventPayloadPart несут JSON-сообщения (session.created, transcription.delta, transcription.done), а ResponseStreamEventModelStreamError и ResponseStreamEventInternalStreamFailure обрабатываются отдельно, чтобы ошибки уровня модели и платформы выводились с понятной диагностикой, а не терялись в пути payload.
Запуск клиента
python sagemaker_bidi_client.py ./audio.wav \
--region us-east-1
На выходе транскрипция появляется в реальном времени по мере отправки аудио. Delta-токены выводятся посимвольно, пока аудиофрагменты продолжают передаваться в фоне.
Демо с микрофоном в Gradio
Клиент на основе файла удобен для тестирования, но самая низкая задержка при двунаправленном стриминге достигается на живом аудио. В репозитории есть микрофонный клиент на базе Gradio (sagemaker_bidi_microphone_client.py), который захватывает звук с микрофона и передает его в SageMaker AI в реальном времени:
python sagemaker_bidi_microphone_client.py \
--endpoint-name \
--region us-east-1
Микрофонный клиент использует те же настройки DataType="UTF8" и тот же протокол vLLM Realtime API, что и файловый клиент. Он захватывает аудио из браузера через потоковый audio input Gradio, пересэмплирует его до 16 kHz PCM16, кодирует каждый фрагмент в base64 и отправляет через двунаправленный поток SageMaker AI. Текст транскрипции обновляется в интерфейсе по мере речи, не дожидаясь окончания фразы.
Ограничения и рекомендации
Realtime API vLLM ожидает аудио в виде base64-кодированного PCM16 с частотой 16 kHz и mono. Если исходное аудио имеет другой формат или sample rate, его нужно преобразовать до отправки. Voxtral-Mini-4B-Realtime-2602 — модель на 4B параметров, она помещается на одном GPU, поэтому для размещения достаточно инстанса ml.g6.4xlarge (1x NVIDIA L4).
SageMaker AI поддерживает WebSocket-соединение с помощью ping/pong-кадров каждые 60 секунд, и соединение закрывается, если 5 последовательных ping остаются без ответа. Для длительных сессий клиент должен уметь переподключаться, а не исходить из того, что поток будет открыт бесконечно. Размер чанка и темп передачи также стоит подбирать под ваш сценарий. В этом примере используются аудиочанки по 4 KB, что соответствует примерно 128 мс аудио при 16 kHz PCM16. Меньшие чанки снижают задержку, но увеличивают накладные расходы на сообщение; более крупные чанки улучшают throughput ценой дополнительной задержки. Подходящее значение зависит от требований вашего приложения к latency.
Очистка ресурсов
Чтобы избежать постоянных затрат, удалите ресурсы, созданные в ходе этого walkthrough, когда завершите тестирование. Endpoint SageMaker AI тарифицируется по underlying instance все время, пока он находится в service, поэтому его удаление — самый важный шаг. В сопровождающем notebook есть ячейка очистки, которая удаляет endpoint, endpoint configuration и model. Если вам больше не нужен пользовательский образ контейнера в Amazon Elastic Container Registry (Amazon ECR) или артефакты модели, загруженные в Amazon Simple Storage Service (Amazon S3), удалите эти ресурсы отдельно, чтобы прекратить расходы на хранение.
Заключение
В этой статье мы показали, как развернуть Voxtral-Mini-4B-Realtime-2602 от Mistral AI для распознавания речи в реальном времени на Amazon SageMaker AI, объединив Realtime WebSocket API vLLM с возможностью двунаправленного стриминга SageMaker AI.
Инфраструктура двунаправленного стриминга SageMaker AI выступает прозрачным bridge между HTTP/2 event stream на стороне клиента и WebSocket на стороне контейнера. С таким bridge серверы моделей, которые поддерживают WebSocket-based text-frame API, например Realtime API vLLM, можно размещать за managed-инфраструктурой SageMaker AI с минимальной адаптацией. Все, что нужно, — это Docker-label, переназначение маршрута и стандартный hosting contract SageMaker AI.
Этот подход выходит далеко за рамки speech-to-text. Сценарии, которым нужна непрерывная двусторонняя коммуникация, например voice agents, перевод в реальном времени, интерактивная генерация аудио или многоходовой streaming dialogue, могут использовать ту же архитектуру. Мы показали это и на файловом клиенте для тестирования, и на живом микрофонном клиенте на базе Gradio для интерактивного использования.
Следующие шаги
Разверните собственную модель, совместимую с Realtime API, на endpoint SageMaker AI с двунаправленным стримингом через vLLM. Полный notebook, файловый клиент и демо с микрофоном доступны на GitHub, чтобы помочь вам начать. Дальше можно развивать решение по нескольким направлениям:
Расширьте демо на Gradio до полноценного приложения. Используйте живой микрофонный клиент как основу и добавьте, например, экспорт транскрипта или последующее резюмирование, передавая output распознавания в text LLM.
Настройте endpoint под ваши цели по задержке и стоимости. Экспериментируйте с типами инстансов, размером чанков и настройками compilation vLLM, чтобы найти баланс для своей нагрузки.
Разверните другую real-time модель. Замените Voxtral-Mini-4B-Realtime-2602 на другую модель, поддерживаемую Realtime API vLLM, обновив model artifact и идентификатор модели, передаваемый в клиентах sagemaker_bidi_client.py и sagemaker_bidi_microphone_client.py.
Узнайте больше о двунаправленном стриминге SageMaker AI. Изучите документацию, чтобы понять полный contract HTTP/2 event stream и применить его к сценариям вроде voice agents или интерактивной генерации аудио.
Материал — перевод статьи с английского.
Оригинал: Build real-time voice applications with Amazon SageMaker AI and vLLM