Тонкая настройка с подкреплением в Amazon Bedrock: лучшие практики для датасетов, функций вознаграждения и гиперпараметров

Искусственный интеллект
Reinforcement fine-tuning on Amazon Bedrock: лучшие практики
Вы можете использовать reinforcement fine-tuning (RFT) в Amazon Bedrock, чтобы настраивать Amazon Nova и поддерживаемые модели с открытым исходным кодом, определяя, как выглядит «хороший» результат, — без необходимости в больших размеченных наборах данных. Обучаясь на сигналах вознаграждения, а не на статических примерах, RFT обеспечивает прирост точности до 66% по сравнению с базовыми моделями при меньших затратах на кастомизацию и меньшей сложности. В этой публикации рассматриваются лучшие практики RFT в Amazon Bedrock — от проектирования набора данных и стратегии функции вознаграждения до настройки гиперпараметров для таких сценариев, как генерация кода, структурированное извлечение и модерация контента.
В этой статье мы разберем, где RFT наиболее эффективен, используя датасет GSM8K для математического рассуждения как конкретный пример. Затем мы пройдемся по лучшим практикам подготовки данных и проектирования функции вознаграждения, покажем, как отслеживать ход обучения с помощью метрик Amazon Bedrock, и завершим практическими рекомендациями по настройке гиперпараметров, основанными на экспериментах с несколькими моделями и сценариями использования.
Сценарии RFT: где RFT особенно силен?
Reinforcement Fine-Tuning (RFT) — это метод кастомизации модели, который улучшает поведение foundation model (FM) с помощью сигналов вознаграждения. По сравнению с supervised fine-tuning (SFT) он не обучается напрямую на корректных ответах (размеченных парах I/O). Вместо этого RFT использует набор входных данных и функцию вознаграждения. Функция вознаграждения может быть основана на правилах, на другой обученной модели-оценщике или на большой языковой модели (LLM) в роли судьи. Во время обучения модель генерирует кандидатные ответы, а функция вознаграждения оценивает каждый ответ. На основе вознаграждения веса модели обновляются так, чтобы повысить вероятность генерации ответов, получающих высокую оценку. Этот итеративный цикл — генерация образцов, оценка ответов и обновление весов — помогает модели выучить, какие поведенческие паттерны ведут к лучшим результатам. RFT особенно полезен, когда желаемое поведение можно оценить, но трудно продемонстрировать — либо потому, что разметка данных слишком затратна, либо потому, что статические примеры не отражают требуемое для задачи рассуждение. В первую очередь он хорош в двух областях:
- задачи, где корректность можно автоматически проверить правилом или тестом;
- субъективные задачи, где другую модель можно эффективно использовать для оценки качества ответа.
К первой категории относятся генерация кода, который должен проходить тесты, математическое рассуждение с проверяемыми ответами, структурированное извлечение данных, которое должно строго соответствовать схемам, или вызовы API/инструментов, которые должны корректно парситься и выполняться. Поскольку критерии успеха можно напрямую преобразовать в сигналы вознаграждения, модель способна находить более сильные стратегии, чем те, которым может научить небольшой набор размеченных примеров. Этот подход известен как Reinforcement Learning with Verifiable Rewards (RLVR).
Кроме того, RFT подходит для субъективных задач, таких как модерация контента, чат-боты, творческое письмо или суммаризация, где трудно определить корректность в количественном виде. В этом случае модель-судья, руководствующаяся подробной рубрикой оценки, может выступать в роли функции вознаграждения. Она выставляет оценки на основе критериев, которые было бы непрактично кодировать в виде статических пар обучения. Такой подход называется Reinforcement Learning with AI Feedback (RLAIF).
Для RFT в Amazon Bedrock вы можете реализовать как rule-based, так и model-based подходы в виде пользовательской функции AWS Lambda, которую Amazon Bedrock вызывает в ходе цикла обучения.
Сравнение этих двух подходов показано на следующей диаграмме:
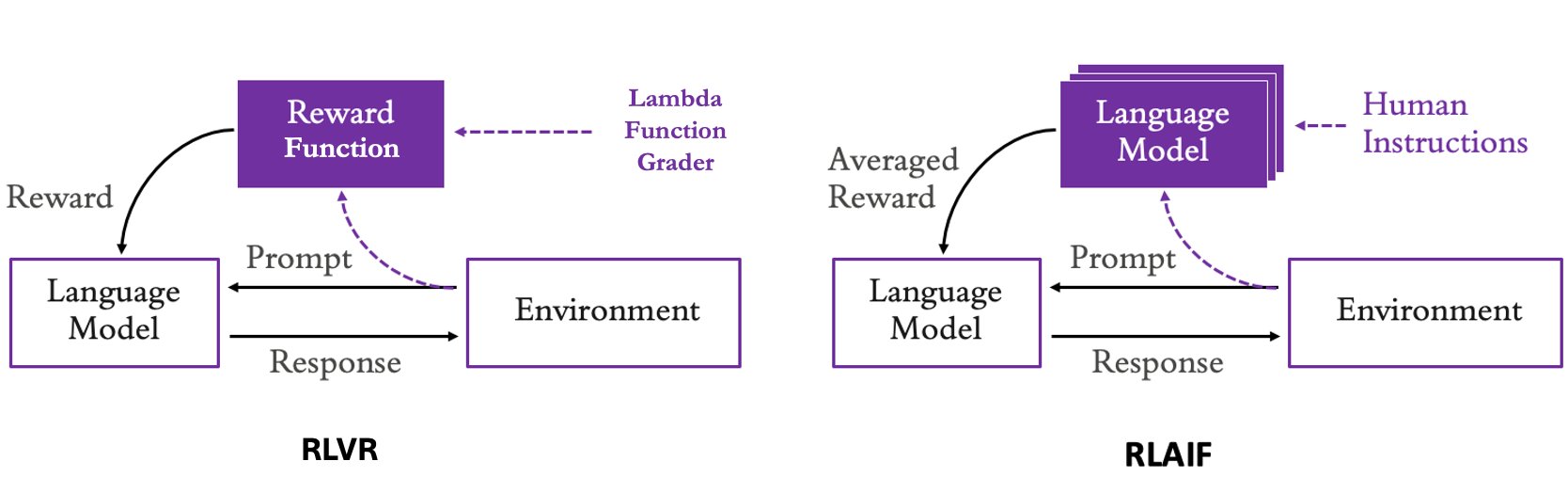
Ниже приведены несколько распространенных сценариев, которые можно решать с помощью RLVR, RLAIF или их комбинации.
| Сценарий использования | Сигнал вознаграждения |
| Генерация кода для production-сервисов | Прохождение unit-тестов, linting и проверки во время выполнения |
| Оркестрация инструментов и API | Успешное завершение сквозной задачи, например booking-flows, пайплайнов получения данных |
| Сложное математическое и алгоритмическое рассуждение | Правильные финальные ответы и/или промежуточные шаги проверки |
| Структурированное извлечение и преобразование данных | Валидация схемы, точные совпадения, штрафы за некорректный вывод |
| Генерация SQL / запросов к базам данных | Результаты запросов, совпадающие с ожидаемыми ответами или удовлетворяющие свойствам выполнения |
| Agentic workflows | Комбинация RLVR и RLAIF; RLVR — для корректности вызовов инструментов; RLAIF — для завершения задачи, например по полезности, корректности или устойчивости |
GSM8K: как RFT помогает улучшить решения математических задач
Чтобы показать, как reinforcement fine-tuning работает на практике, рассмотрим конкретный пример: улучшение способности модели решать задачи на математическое рассуждение. RFT полезен для математических задач, потому что решения часто можно объективно проверить, а значит, можно создать четкие сигналы вознаграждения, которые направляют модель к правильному рассуждению и структурированным ответам. Давайте посмотрим на пример из набора данных GSM8K (Grade School Math 8K):
Tina зарабатывает 18,00 долларов в час. Если она работает больше 8 часов за смену, ей положены сверхурочные, которые оплачиваются по ставке почасовая ставка + половина почасовой ставки. Если она работает по 10 часов в день 5 дней, сколько денег она заработает?
Посмотрим, как мог бы выглядеть идеальный ответ:
<begin_internal_thought>
Мне нужно найти общую оплату за 5 дней смен по 10 часов. Поскольку каждый день она работает больше 8 часов, нужно разделить день на обычные и сверхурочные часы, вычислить ставку сверхурочных (1,5x от обычной), а затем умножить на 5 дней.
</end_internal_thought>
<begin_of_solution>
Ставка сверхурочных: $18.00 + (1/2 × $18.00) = $27.00/час
Дневной заработок (10 часов):
Обычные (8 часов): 8 × $18 = $144
Сверхурочные (2 часа): 2 × $27 = $54
Итого за день: $198
Итого за 5 дней: 5 × $198 = $990
\boxed{990}
</end_of_solution>Здесь видно, что задача разбита на логические шаги и показывает понятные пути рассуждения, а не только финальный ответ. Кроме того, нам хотелось бы, чтобы модель отвечала именно в таком формате и чтобы ответ точно совпадал с эталонным решением. Другие методы дообучения, такие как SFT, хуже справляются с математическим рассуждением, потому что они в первую очередь учатся распознавать шаблоны обучающих данных, а не действительно рассуждать. Такие модели могут запоминать шаблоны решений, но часто проваливаются при столкновении с новыми вариациями задачи.
Поскольку в RFT можно определить функции вознаграждения, точные ответы вроде $990 можно объективно оценивать, одновременно начисляя частичные баллы за правильные промежуточные шаги рассуждения. Это позволяет модели находить корректные пути решения и одновременно учиться соблюдать требуемую структуру; во многих случаях сильные результаты достигаются на сравнительно небольших наборах данных (примерно 100–1000 примеров).
Лучшие практики подготовки данных
RFT требует тщательно подготовленных наборов данных, чтобы добиться эффективных результатов. В Amazon Bedrock обучающие данные для RFT предоставляются в виде файла JSONL, при этом каждая запись должна соответствовать формату OpenAI chat completion.
Рекомендации по размеру набора данных
RFT поддерживает размеры наборов данных от 100 до 10 000 обучающих примеров, хотя требования зависят от сложности задачи и конструкции функции вознаграждения. Задачи, связанные со сложным рассуждением, специализированными доменами или широким спектром применения, обычно выигрывают от больших наборов данных и более сложной функции вознаграждения. Для первых экспериментов рекомендуется начать с небольшого набора (100–200 примеров), чтобы проверить, что ваши промпты и функция вознаграждения дают содержательные сигналы обучения и что базовая модель может демонстрировать измеримый рост вознаграждения. Имейте в виду, что в некоторых доменах настройка только на небольших наборах может давать ограниченную обобщающую способность и нестабильные результаты при изменении формулировок промпта. Типичные реализации на 200–5000 примеров обеспечивают лучшее обобщение и более стабильное поведение при вариациях промптов. Для более сложных задач рассуждения, специализированных доменов или продвинутых функций вознаграждения 5000–10 000 примеров могут улучшить устойчивость на разнообразных входах.
Дополнительную информацию о требованиях к данным см. в документации Amazon Bedrock.
Принципы качества набора данных
Качество обучающих данных фундаментально определяет результаты RFT. При подготовке набора данных учитывайте следующие принципы:
1. Распределение промптов
Убедитесь, что набор данных отражает весь диапазон промптов, с которыми модель столкнется в продакшене. Смещенный набор данных может привести к плохому обобщению или нестабильному поведению во время обучения.
2. Возможности базовой модели
RFT предполагает, что базовая модель уже демонстрирует базовое понимание задачи. Если модель не может получить ненулевое вознаграждение на ваших промптах, сигнал обучения будет слишком слабым для эффективного обучения. Простая проверка — сгенерировать несколько ответов базовой модели (например, при temperature ≈ 0.6) и убедиться, что выходы создают содержательные сигналы вознаграждения.
3. Четкий дизайн промпта
Промпты должны ясно передавать ожидания и ограничения. Неоднозначные инструкции приводят к несогласованным сигналам вознаграждения и ухудшению обучения. Структура промпта также должна соответствовать парсингу функции вознаграждения. Например, можно требовать финальный ответ после определенного маркера или использовать code blocks для программных задач, а также придерживаться структуры промптов, знакомой базовой модели по предобучению.
4. Надежные эталонные ответы
По возможности включайте эталонный ответ, который отражает желаемый паттерн вывода, форматирование и критерии корректности. Эталонные ответы служат опорой для расчета вознаграждения и уменьшают шум в сигнале обучения. Например, для математических задач это может быть корректный числовой ответ, а для кодовых задач — unit-тесты или пары input-output.
Также полезно проверять эталонные ответы, подтверждая, что ответ, совпадающий с ground truth, получает максимальный балл вознаграждения.
5. Согласованные сигналы вознаграждения внутри данных
Поскольку RFT полностью полагается на сигналы вознаграждения для направления обучения, качество этих сигналов критически важно. Ваш набор данных и функция вознаграждения должны работать вместе, чтобы обеспечивать согласованные и хорошо различимые оценки. Это означает, что сильные ответы должны стабильно получать более высокие оценки, чем слабые, на схожих входах. Если функция вознаграждения не может четко различить хорошие и плохие ответы или если похожие ответы получают сильно различающиеся оценки, модель может выучить неправильные паттерны или вовсе не улучшиться.
В следующем разделе вы узнаете, что нужно учитывать при написании функции вознаграждения.
Подготовка функции вознаграждения
Функции вознаграждения играют центральную роль в RFT, поскольку они оценивают и ранжируют ответы модели, назначая более высокое вознаграждение предпочтительным выходам и более низкое — менее желательным. Эта обратная связь направляет модель к улучшению поведения во время обучения. Для объективных задач, таких как математическое рассуждение, ответ, который дает правильное решение, может получать вознаграждение 1, а неверный ответ — 0. Ответ с частично правильной цепочкой рассуждения и неверным финальным выводом может получить вознаграждение 0.8 (в зависимости от того, насколько сильно вы хотите штрафовать неправильный финальный ответ). Для субъективных задач функция вознаграждения кодирует желаемые качества. Например, в суммаризации она может учитывать достоверность, полноту и ясность. Дополнительные сведения о настройке функции вознаграждения см. в статье о настройке функций вознаграждения для моделей Amazon Nova.
Проектирование вознаграждения для проверяемых задач
Для задач, которые можно детерминированно проверить, например математического рассуждения или программирования, самый простой подход — программно проверять корректность. Эффективные функции вознаграждения обычно оценивают и форматные ограничения, и целевые показатели качества. Проверки формата гарантируют, что ответы можно надежно распарсить и оценить. Метрики качества определяют, верен ли результат. Вознаграждение может быть реализовано с помощью бинарных сигналов (правильно/неправильно) или непрерывного скоринга — в зависимости от задачи.
Для задач математического рассуждения в стиле GSM8K функции вознаграждения также должны учитывать, как модели выражают числовые ответы. Модели могут форматировать числа с запятыми, символами валюты, процентами или включать ответ в объяснительный текст. Чтобы решить эту проблему, ответы следует нормализовать, удаляя символы форматирования, и использовать гибкое извлечение, которое сначала предпочитает структурированные форматы, а затем переходит к сопоставлению по шаблонам. Такой подход помогает вознаграждать правильное рассуждение, а не наказывать за стилистические варианты оформления. Полную реализацию функции вознаграждения для GSM8K можно найти в репозитории amazon-bedrock-samples на GitHub.
Проектирование вознаграждения для непроверяемых задач
Такие задачи, как суммаризация, творческое письмо или семантическое согласование, требуют судьи на основе LLM, чтобы приблизительно оценить субъективные предпочтения. В этом случае промпт для судьи фактически и есть функция вознаграждения: он определяет, какие поведенческие паттерны поощряются и как оцениваются ответы. Практичный промпт для судьи должен четко задавать цель оценки и включать краткую рубрику с числовой шкалой, отражающей качества, которые модель должна улучшить.
Промпты для судьи также должны возвращать структурированный результат, например JSON или размеченный формат, содержащий финальный балл и необязательное объяснение, чтобы значения вознаграждения можно было надежно извлекать во время обучения, сохраняя при этом наблюдаемость того, как был оценен каждый ответ. Пример функции вознаграждения, использующей AI feedback, можно посмотреть в скрипте PandaLM reward function на GitHub.
Сочетание проверяемых вознаграждений с AI feedback
Функции вознаграждения для проверяемых задач также можно дополнить AI feedback, чтобы оценивать качество решения шире, чем просто числовая корректность. Например, LLM в роли судьи может анализировать цепочку рассуждения, проверять промежуточные вычисления или оценивать ясность объяснений, формируя сигнал вознаграждения, который учитывает и корректность, и качество рассуждения.
Итерации над дизайном вознаграждения
Функции вознаграждения часто требуют доработки. Ранние версии могут давать шумные сигналы, либо в ходе цикла обучения модель может научиться эксплуатировать слабые места функции вознаграждения, чтобы получать высокий балл, не осваивая нужное поведение. Поэтому важно уточнять логику вознаграждения на основе наблюдаемого поведения модели. Перед запуском полноценных обучающих задач также полезно тестировать функции вознаграждения отдельно, используя примеры промптов и известные ответы, чтобы убедиться, что логика оценки дает стабильные и содержательные сигналы.
Оценка прогресса обучения: сигналы того, что модель учится
После того как данные и функция вознаграждения готовы, можно запускать обучение RFT через Amazon Bedrock API или через консоль. Точный рабочий процесс зависит от предпочитаемой среды разработки. Раздел Create and manage fine-tuning jobs for Amazon Nova models в руководстве пользователя Amazon Bedrock содержит пошаговые инструкции для обоих вариантов. После начала обучения критически важно отслеживать метрики. Эти сигналы показывают, является ли функция вознаграждения осмысленной и учится ли модель полезному поведению, а не переобучается или не скатывается к тривиальным стратегиям. На следующем изображении показаны метрики обучения одного из наших прогонов GSM8K, демонстрирующие здоровую динамику обучения.
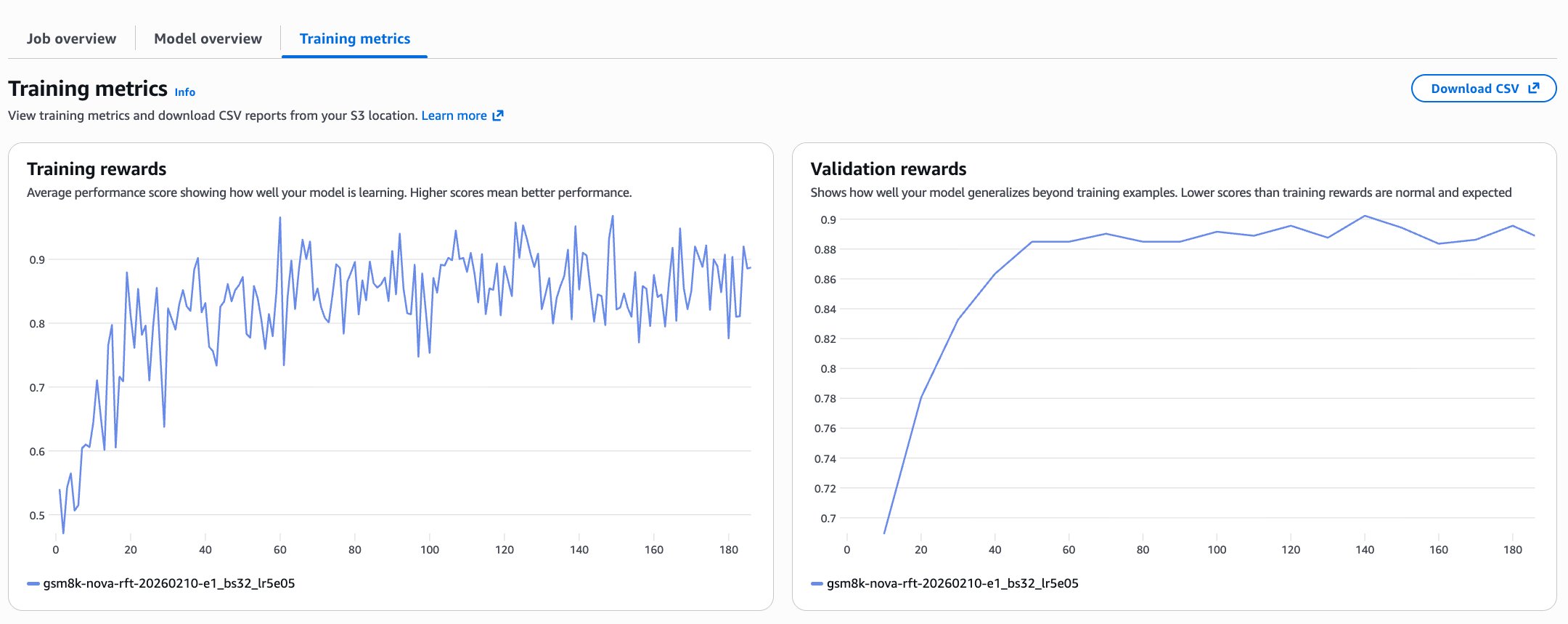
График training rewards показывает среднее значение вознаграждения на каждом шаге обучения. Разброс ожидаем, потому что входные промпты в батче выбираются случайно, а значит, сложность батчей различается. Кроме того, модель исследует разные стратегии, что тоже приводит к вариативности. Главное — общий тренд: вознаграждение растет примерно с 0.5 до 0.8–0.9, что указывает на то, что модель сходится к более высоким оценкам. Validation rewards дают более ясный сигнал, поскольку вычисляются на отложенном наборе данных. Здесь видно резкое улучшение примерно в первые 40 шагов, затем плато около 0.88, что говорит о том, что модель обобщает, а не запоминает обучающие примеры. Validation rewards, которые идут близко к training rewards, обычно означают, что переобучение не происходит.
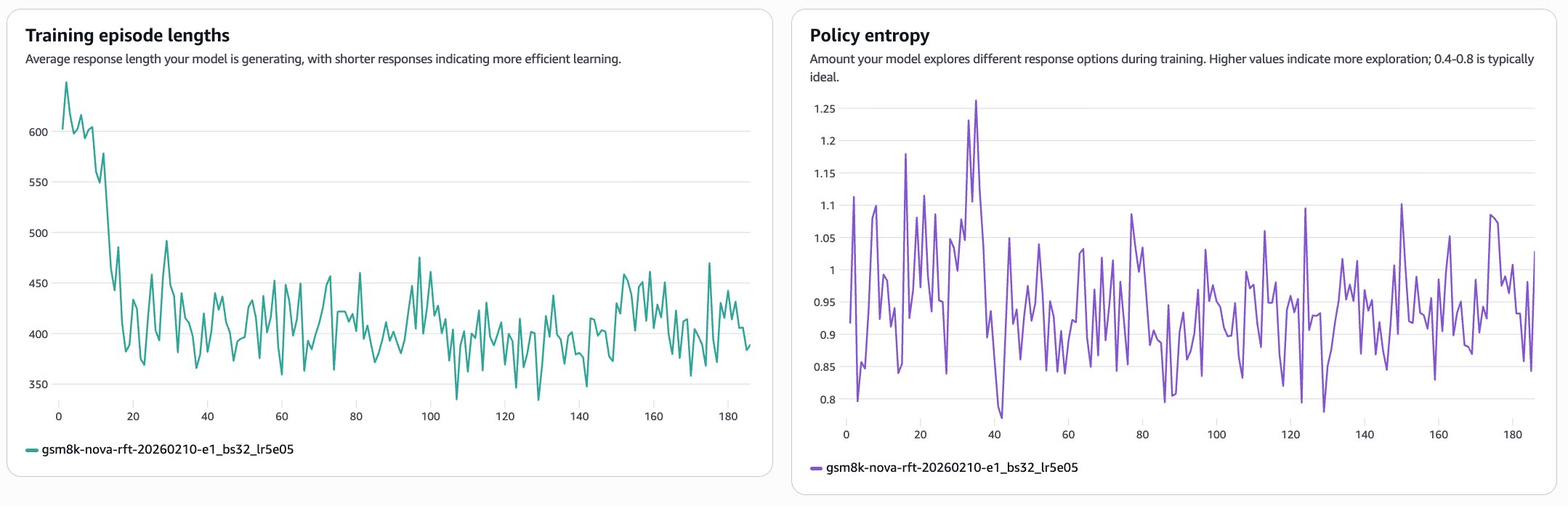
Training episode length измеряет среднюю длину ответа. Снижение примерно с 625 токенов до ~400 токенов говорит о том, что модель учится приходить к правильному ответу более эффективно, выдавая меньше избыточных рассуждений по мере обучения. Policy entropy измеряет, насколько активно модель исследует разные стратегии ответа в ходе обучения. Значения в диапазоне 0.8–1.1 указывают на здоровое исследование. Если entropy падает почти до нуля, это было бы признаком преждевременной конвергенции; устойчивое значение entropy, напротив, означает, что модель продолжает исследовать пространство решений и улучшаться.
Рекомендации по настройке гиперпараметров
В этом разделе мы рассмотрим практические рекомендации по настройке гиперпараметров для Amazon Bedrock RFT. Эти советы основаны на серии внутренних экспериментов, которые мы проводили на нескольких моделях и сценариях использования. Среди них были задачи рассуждения, такие как GSM8K, а также другие структурированные и генеративные рабочие нагрузки. Хотя эффективные значения зависят от задачи, закономерности, наблюдаемые в этих экспериментах, дают полезную отправную точку при настройке RFT-задач. Дополнительную информацию о гиперпараметрах, которые можно настроить перед запуском задачи RFT-кastомизации, см. в официальной документации boto3.
EpochCount
Длительность обучения и epochCount требуют настройки в зависимости от размера набора данных и поведения модели. На небольших наборах данных часто наблюдается продолжение улучшения в течение 6–12 эпох, тогда как на более крупных наборах оптимальные результаты могут достигаться за 3–6 эпох. Эта зависимость нелинейна, и для предотвращения переобучения при сохранении достаточной адаптации модели необходимо внимательно отслеживать validation metrics.
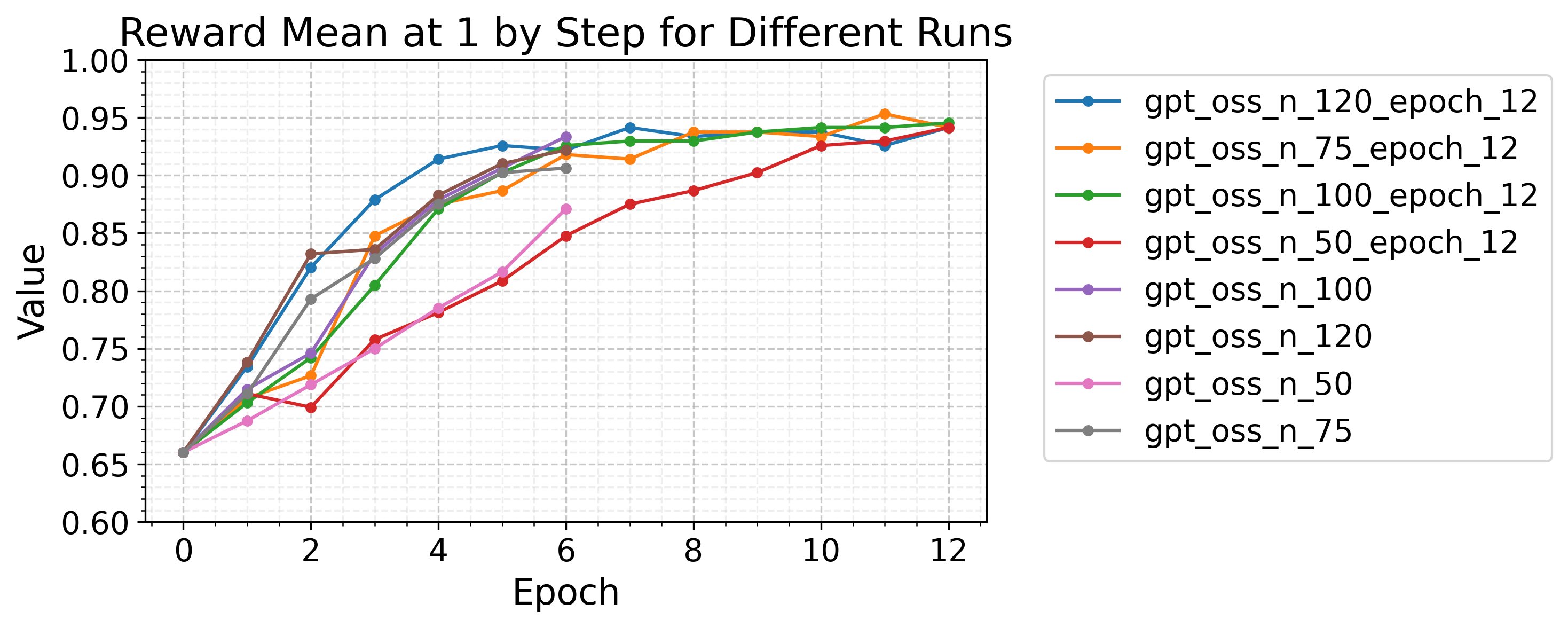
BatchSize
Этот параметр определяет, сколько промптов обрабатывается до того, как обновленная модель сгенерирует новый раунд кандидатных ответов (rollouts). Например, при batchSize 128 модель обрабатывает, обновляет и генерирует новые rollouts для 128 промптов за раз, пока не пройдет весь набор данных. Общее число раундов rollouts равно размеру (отфильтрованного) набора данных, деленному на batchSize.
batchSize 128 хорошо подходит для большинства сценариев и моделей. Увеличьте его, если loss ведет себя нестабильно или вознаграждение не растет. Уменьшите, если итерации занимают слишком много времени.
LearningRate
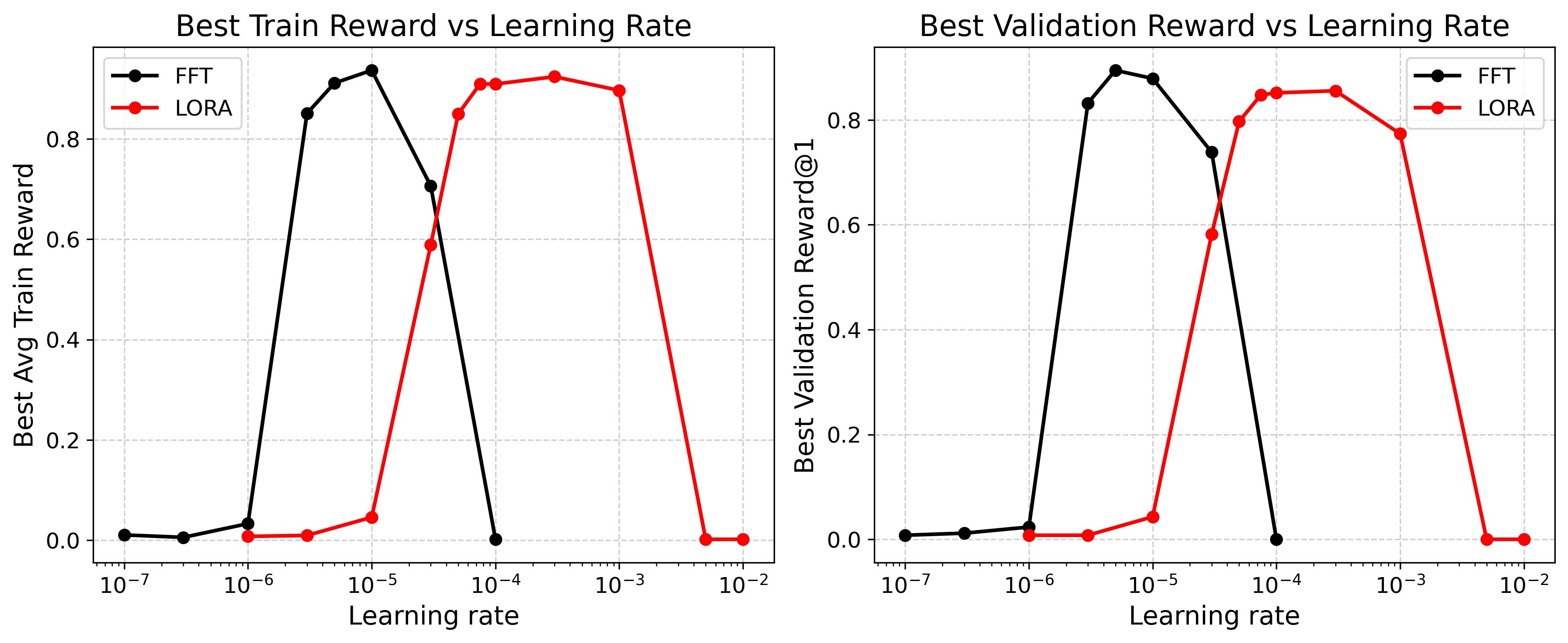
В Amazon Bedrock RFT мы выполняем параметроэффективный RFT с помощью адаптеров Low Rank Adaptation (LoRA) с рангом 32. Для широкого круга сценариев learning rate 1e-4 стабильно показывает сильные результаты. В следующем эксперименте мы провели sweep learning rate на семь порядков величины на модели Qwen3-1.7B с использованием датасета GSM8K (1K обучающих примеров, 256 тестовых примеров), выполнив одну эпоху с batch size 64, group size 16 и LoRA rank 1. Как показано на следующем рисунке, оптимальный learning rate для LoRA лежит примерно в диапазоне 1e-4–1e-3, то есть примерно на порядок выше, чем для full fine-tuning (FFT). Даже при rank 1 LoRA достигает примерно 5.5% от лучшего validation reward FFT при примерно том же времени выполнения. На практике RFT на базе LoRA обычно более терпим к настройкам и хорошо работает в более широком диапазоне learning rate, чем FFT, хотя оба подхода могут схлопнуться вне оптимальных диапазонов. Мы рекомендуем внимательно следить за кривыми вознаграждения и снижать learning rate, если они начинают колебаться или схлопываться.
Длина промпта и длина ответа
maxPromptLength определяет максимальную допустимую длину входного промпта в наборе данных. Промпты, превышающие это ограничение, отфильтровываются во время обучения. Если в вашем наборе данных есть необычно длинные промпты или другие выбросы, задайте подходящее значение, которое исключит выбросы, но сохранит большинство примеров. В противном случае можно установить значение, равное длине самого длинного промпта в наборе данных. С другой стороны, inferenceMaxTokens определяет максимальную длину ответа для любого rollout или ответа, сгенерированного во время RL-обучения. Этот параметр можно использовать, чтобы управлять тем, будет ли итоговая модель генерировать развернутые ответы или короткие формулировки. Мы рекомендуем выбирать значение исходя из требований вашей задачи. Слишком большое значение может увеличить время обучения, а слишком маленькое — ухудшить качество модели. Для задач, не требующих сложного рассуждения, обычно достаточно максимальной длины ответа 1024. Для более сложных задач, таких как программирование или длинные генеративные тексты, предпочтительнее более высокий верхний предел — более 4096.
Раннее завершение и интервал оценки
Наш сервис RFT предоставляет две функции, которые повышают эффективность обучения и качество модели. EarlyStopping (включен по умолчанию) автоматически останавливает обучение, когда улучшения производительности выходят на плато, предотвращая переобучение и сокращая ненужные вычислительные затраты. Система непрерывно отслеживает validation metrics и завершает обучение, когда определяет, что дальнейшие итерации вряд ли дадут значимое улучшение. Параметр evalInterval определяет, как часто модель оценивает свое качество на validation dataset во время обучения. Этот гиперпараметр автоматически вычисляется как min(10, data_size/batch_size), обеспечивая как минимум одну оценку на эпоху при разумной частоте. Для наборов данных, где data_size значительно превышает 10×batch_size, оценки обычно выполняются каждые 10 шагов, что дает достаточную детализацию мониторинга без лишних накладных расходов.
Метрики RFT и что они означают
Amazon Bedrock предоставляет несколько обучающих метрик через Amazon CloudWatch и консоль Amazon Bedrock, которые дают ясную картину того, идет ли задача RFT так, как ожидается. Понимание того, что означает каждая метрика и на какие аномалии обращать внимание, помогает обнаружить проблему раньше, чем ждать окончания неудачного прогона.
Training и validation rewards
Training reward — это среднее значение вознаграждения на эпизодах, на которых выполняется обучение. Validation reward — та же метрика, но на отложенном наборе промптов, которые не участвуют в вычислении градиентов. В здоровом прогоне train reward должен устойчиво расти в начале, а validation reward — подниматься медленнее, но в том же направлении.
Train и validation episode lengths
Эти метрики отражают среднее число токенов, генерируемых на ответ. Используйте их, чтобы выявлять verbosity hacking. Если длина ответов резко растет вместе с вознаграждением, модель могла выучить, что «длиннее = лучше», независимо от качества. В задачах рассуждения, таких как Chain Of Thought (CoT), постепенный рост — это нормально (модель учится думать), но резкий вертикальный скачок обычно означает цикл или сбой. В некоторых случаях вы увидите постепенное снижение, и это тоже допустимо. Это может означать, что сначала модель больше исследовала путь к ответу, а затем нашла более короткие, но все еще вознаграждаемые траектории.
Policy entropy
Policy entropy показывает, насколько модель уверена в своих ответах. Высокая entropy означает, что модель не уверена и продолжает исследовать, а низкая — что она сходится к более стабильным ответам. В здоровом обучении обычно ожидается плавное снижение от исходного уровня к устойчивому плато по мере обучения. Резкое падение почти до нуля — тревожный сигнал: обычно это значит, что модель схлопнулась в повторение одного и того же ответа вместо рассуждения над задачами. С другой стороны, постоянно высокий и почти не меняющийся уровень говорит о том, что модель игнорирует сигнал вознаграждения и не учится на обратной связи.
Gradient norm
Это величина (L2 norm) градиентов, применяемых к модели на каждом обновлении. В стабильном прогоне она колеблется в разумном диапазоне с отдельными всплесками; устойчивый рост или экстремальные пики могут указывать на проблемы с learning rate, масштабированием вознаграждения или численной стабильностью.
Распространенные ошибки
Даже хорошо настроенные RFT-задачи могут столкнуться со сбоями, которые не всегда очевидны по одним только метрикам. Две наиболее распространенные проблемы — reward hacking, когда модель учится обманывать функцию вознаграждения вместо улучшения реальной задачи, и нестабильность вознаграждения, когда высокая дисперсия сигнала мешает процессу обучения. Обе проблемы решаемы, но устранять их легче, если знать, на что смотреть.
Reward hacking
Это происходит, когда policy учится использовать слабые места в функции вознаграждения, чтобы максимизировать оценку, не улучшая качество. Вы увидите, что training rewards стабильно растут, а оценки human evaluation ухудшаются или выходят на плато. Чтобы снизить риск, убедитесь, что функция вознаграждения учитывает все аспекты поведения, которые вы хотите зафиксировать с помощью fine-tuning. Если нет — изучите генерации модели и доработайте функцию вознаграждения. При необходимости используйте строгие штрафы за длину в функции вознаграждения.
Дисперсия вознаграждения и нестабильность
Даже при хорошем среднем значении вознаграждения сильные колебания оценок для похожих входов создают шумный сигнал, который дестабилизирует обучение. Это проявляется в дерганых кривых вознаграждения и сильно колеблющихся метриках loss. Первая линия защиты — строгая нормализация: стандартизируйте вознаграждения (нулевое среднее, единичная дисперсия) внутри каждого батча, обрезайте экстремальные выбросы и убедитесь, что вывод функции вознаграждения детерминирован (без dropout), чтобы оптимизатор получал последовательный и стабильный сигнал обучения.
Заключение
В этой статье мы показали, как применять Reinforcement Fine-Tuning (RFT) в Amazon Bedrock для улучшения качества модели с помощью обучения на обратной связи. На примере набора данных GSM8K для математического рассуждения мы показали, где RFT наиболее эффективен, как структурировать обучающие наборы данных и как проектировать функции вознаграждения, которые надежно оценивают ответы модели. Мы также разобрали, как отслеживать прогресс обучения с помощью метрик Bedrock и предложили практические рекомендации по настройке гиперпараметров, основанные на экспериментах с несколькими моделями и сценариями использования. Вместе эти компоненты образуют базовую основу для успешных RFT-процессов. Когда данные хорошо структурированы, функции вознаграждения отражают правильное понимание качества, а метрики обучения внимательно мониторятся, RFT может существенно улучшить производительность модели как в проверяемых задачах (например, рассуждение, кодирование и структурированное извлечение), так и в субъективных задачах с использованием AI feedback.
Следующие шаги
Готовы начать кастомизацию с RFT в Amazon Bedrock? Войдите в консоль Amazon Bedrock или ознакомьтесь с официальной API-документацией AWS и создайте свою первую задачу обучения RFT с использованием моделей с открытым исходным кодом, которые были дообучены для этого сценария использования.
Чтобы начать:
- Изучите документацию: Посетите подробные руководства и туториалы: Создать задачу reinforcement fine-tuning
- Попробуйте sample notebooks: Получите готовые к запуску примеры в репозитории AWS Samples на GitHub
- Экспериментируйте со своими рабочими нагрузками — примените практики подготовки данных, проектирования вознаграждения и настройки гиперпараметров, описанные в этой статье, к своим сценариям использования.
Благодарность
Спасибо участникам команды Amazon Bedrock Applied Scientist — Zhe Wang и Wei Zhu, чья экспериментальная работа послужила основой для многих лучших практик, перечисленных в этой публикации.
Материал — перевод статьи с английского.
Оригинал: Reinforcement fine-tuning on Amazon Bedrock: Best practices