Преобразование текста в SQL на Amazon Bedrock: граф знаний, SQL и ответы за секунды
Построение решения text-to-SQL с использованием Amazon Bedrock может снять одно из самых устойчивых узких мест в компаниях, работающих с данными: задержку между постановкой бизнес-вопроса и получением понятного ответа, основанного на данных. Вам наверняка знакома проблема, когда разовый запрос оказывается в очереди позади более приоритетной работы. Решение text-to-SQL дополняет уже существующую команду — бизнес-пользователи самостоятельно отвечают на типовые аналитические вопросы, освобождая технические ресурсы для сложных и ценных инициатив по всей организации. Вопросы вроде «Каков наш рост выручки год к году по сегментам клиентов?» становятся доступны каждому, не создавая дополнительной нагрузки для технических команд.
Многие организации обнаруживают, что доступ к аналитическим инсайтам остается серьезным узким местом в процессе принятия бизнес-решений. Традиционный подход требует либо изучения синтаксиса SQL, либо ожидания технических ресурсов, либо использования готовых дашбордов, которые могут не отвечать на ваш конкретный вопрос.
В этом посте мы показываем, как построить естественное решение text-to-SQL с помощью Amazon Bedrock, которое преобразует бизнес-вопросы в запросы к базе данных и возвращает actionable-ответы. Модель возвращает не только сырой SQL, но и выполненные результаты, синтезированные в понятный естественный текст, — за секунды, а не часы. Мы проведем вас через архитектуру, стратегии реализации и уроки, полученные при внедрении этого решения в масштабе. К концу материала вы поймете, как создать собственную систему text-to-SQL, которая сокращает разрыв между бизнес-вопросами и доступом к данным.
Почему традиционная бизнес-аналитика не справляется
Стоит отметить, что такие инструменты, как Amazon Quick, уже эффективно закрывают многие потребности self-service-аналитики, включая запросы на естественном языке к дашбордам и автоматическую генерацию инсайтов. Эти инструменты отлично подходят, когда ваши аналитические задачи хорошо укладываются в структурированные дашборды, curated-наборы данных и управляемые процессы отчетности. Кастомное решение text-to-SQL становится особенно полезным, когда пользователям нужно выполнять запросы по сложным многотабличным схемам с глубокой бизнес-логикой организации, отраслевой терминологией и разовыми вопросами, которые не поддерживаются преднастроенными наборами данных дашбордов.
Построение решения text-to-SQL выявляет три фундаментальные проблемы, которые выходят за рамки традиционных инструментов Business Intelligence (BI):
- Барьер SQL-экспертизы блокирует быстрый анализ. Большинство бизнес-пользователей не обладают техническими знаниями SQL, необходимыми для доступа к сложным данным. Простые вопросы часто требуют соединения нескольких таблиц, временных расчетов и иерархических агрегаций. Такая зависимость создает узкие места: бизнес-пользователи ждут индивидуальные отчеты, а аналитики тратят ценное время на повторяющиеся запросы вместо стратегического анализа.
- Даже современные BI-системы имеют границы гибкости. Современные BI-инструменты достигли заметного прогресса в запросах на естественном языке и self-service-аналитике. Однако эти возможности обычно лучше всего работают в рамках заранее подготовленных семантических слоев, управляемых наборов данных или смоделированных дашбордов. Когда бизнес-пользователям нужно выйти за пределы curated-областей, выполнить разовые соединения, расчеты «на лету» с учетом специфики организации или запросить сырые таблицы хранилища данных вне семантического слоя, они по-прежнему сталкиваются с ограничениями, требующими вмешательства технических специалистов. Кастомное решение text-to-SQL закрывает этот разрыв, работая напрямую со схемой вашего хранилища данных и динамически получаемым бизнес-контекстом, а не полагаясь на преднастроенные семантические модели.
- Контекст и семантическое понимание создают разрывы в переводе. Даже при наличии доступа к SQL преобразование бизнес-терминологии в корректные запросы к базе данных остается сложной задачей. Термины вроде attainment, pipeline и forecast могут иметь уникальную логику расчета, особые требования к источникам данных и бизнес-правила, которые различаются от организации к организации. Понимание того, какие таблицы соединять, как определены метрики и какие фильтры применять, требует глубоких внутренних знаний, которые большинству пользователей недоступны.
Когда вы строите собственное решение, подумайте, как система будет кодировать этот глубокий бизнес-контекст — стратегические принципы, правила сегментации клиентов и операционные процессы, — чтобы пользователи могли принимать более быстрые решения на основе данных, не понимая сложных схем баз данных или синтаксиса SQL.
Как это работает: опыт пользователя
Прежде чем переходить к архитектуре, посмотрим, как это выглядит с точки зрения пользователя.
Бизнес-пользователь вводит вопрос в разговорный интерфейс, например: «Как в этом году меняется выручка по сравнению с прошлым годом по нашим ключевым сегментам клиентов?» За кулисами система за считанные секунды делает следующее:
- Понимает вопрос. Определяет, является ли он простым поиском одного факта или сложным запросом, который нужно разбить на части. В данном случае система распознает, что «динамика выручки», «сравнение год к году» и «ключевые сегменты клиентов» требуют разных шагов получения данных.
- Извлекает бизнес-контекст. Система выполняет поиск по графу знаний, который кодирует специфические для вашей организации определения метрик, бизнес-терминологию, связи между таблицами и правила работы с данными. Она знает, что означает выручка в вашей среде, в каких таблицах она хранится и как определяется сегмент клиента.
- Генерирует и проверяет SQL. Система создает структурированный SQL-запрос, проверяет его на корректность и безопасность с помощью детерминированных проверок и выполняет его в вашем хранилище данных. Если проверка находит проблему, система автоматически вносит правки и повторяет попытку без участия человека.
- Синтезирует ответ. Сырые результаты запроса преобразуются обратно в естественно-языковой рассказ с поддерживающими данными, давая пользователю и вывод, и прозрачность, необходимую для доверия к нему.
В результате бизнес-пользователи получают ответы на сложные аналитические вопросы за секунды или минуты с полной видимостью логики, лежащей в основе ответа. Аналитики освобождаются от повторяющейся работы с запросами и могут сосредоточиться на более ценной стратегической аналитике.
Обзор решения
Чтобы обеспечить такой опыт, решение объединяет три ключевые возможности:
- фундаментальные модели (FM) в Amazon Bedrock для понимания естественного языка и генерации SQL;
- Graph Retrieval-Augmented Generation (GraphRAG) для извлечения бизнес-контекста;
- высокопроизводительные хранилища данных для быстрого выполнения запросов.
Amazon Bedrock играет центральную роль в этой архитектуре, предоставляя и слой инференса больших языковых моделей (LLM), и среду оркестрации агентов. Amazon Bedrock дает доступ к широкому набору FM, поэтому команды могут выбирать и менять модели в зависимости от меняющихся требований к производительности, стоимости и задержке без перестройки архитектуры системы.
Как показано на архитектурной схеме,
- Amazon Bedrock AgentCore Runtime выступает центральным уровнем оркестрации, размещая агент-супервизор, который координирует весь поток работы. Он маршрутизирует пользовательские вопросы, вызывает GraphRAG Search Tool для получения контекста, обеспечивает Row-Level Security, запускает генерацию и валидацию SQL и выполняет запросы к базе данных (Amazon Redshift). Runtime поддерживает несколько точек входа, включая протоколы MCP и HTTP, что позволяет интегрировать решение как в встраиваемые аналитические интерфейсы вроде AWS Quick Sight, так и в пользовательские веб-интерфейсы.
- Amazon Bedrock AgentCore также предоставляет встроенную observability, отправляя трассировки выполнения агентов и метрики производительности в Amazon CloudWatch для мониторинга, отладки и непрерывной оптимизации. Эта управляемая среда снимает с команды непрофильную тяжелую работу по созданию собственной агентной инфраструктуры, позволяя сосредоточиться на бизнес-логике, тонкой настройке промптов и обогащении доменных знаний.
Следующая диаграмма иллюстрирует, как работает этот процесс:
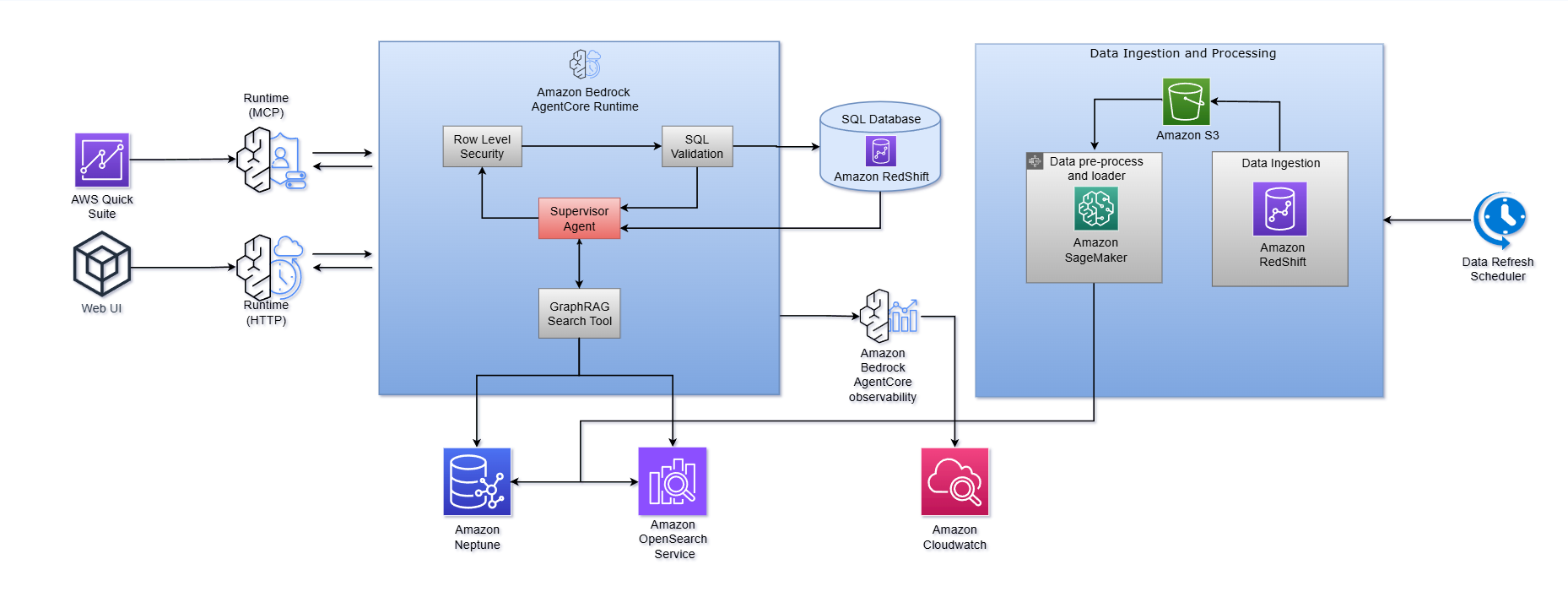
Архитектура работает как оркестрированная мультиагентная система с пятью ключевыми этапами:
Этап 1: Анализ и декомпозиция вопроса
Когда поступает вопрос, процессор вопросов сначала классифицирует его. Простые, атомарные, фактические вопросы вроде «Какой был общий доход в Q4?» направляются напрямую в пайплайн извлечения данных. Сложные или многосоставные вопросы разбиваются на самостоятельные, независимые подзапросы, которые могут обрабатываться параллельно разными командами агентов. Именно этот этап декомпозиции позволяет системе справляться со сложными аналитическими вопросами, охватывающими несколько доменов данных, периодов времени или бизнес-измерений.
Этап 2: Граф знаний и извлечение контекста GraphRAG
Именно здесь система устраняет барьер контекста, и это ее главное отличие от наивных подходов text-to-SQL.
Граф знаний, построенный на Amazon Neptune и Amazon OpenSearch Service, служит семантическим фундаментом. Он хранит онтологию таблиц вашей организации и фиксирует связи между бизнес-сущностями, метриками, терминологией и организационными иерархиями. Важно, что этот граф обогащается предметными знаниями от владельцев таблиц и экспертов, включая описания, бизнес-определения метрик, сопоставления терминов и классификационные теги, загружаемые из структурированных конфигурационных файлов.
Когда система обрабатывает вопрос, она выполняет облегченный GraphRAG-поиск, который работает в три этапа:
- векторный поиск (с использованием Amazon OpenSearch Service): находит семантически релевантные значения столбцов, имена столбцов и описания таблиц, соответствующие понятиям из вопроса пользователя;
- обход графа (с использованием Amazon Neptune): следует по связям в графе знаний — от найденных значений к родительским столбцам, а затем к родительским таблицам — чтобы составить полную картину того, какие данные релевантны и как они связаны;
- оценка релевантности и фильтрация: ранжирует и структурирует извлеченный контекст так, чтобы генератор SQL получил именно ту информацию, которая ему нужна: нужные таблицы, нужные столбцы, нужные пути соединения и нужную бизнес-логику.
Граф знаний и связанные с ним данные регулярно обновляются, чтобы отражать изменения схемы, новые таблицы и эволюцию бизнес-определений. Чем богаче этот контекстный слой, тем точнее становится последующая генерация SQL.
Этап 3: Структурированная генерация SQL и валидация
Система использует возможности function calling в Amazon Bedrock для создания SQL-запросов в виде структурированных данных. Это обеспечивает строгие форматы вывода, снимает необходимость в хрупкой постобработке или сложных регулярных выражениях и существенно повышает надежность.
Сгенерированные запросы затем проходят через детерминированные SQL-валидаторы, работающие на уровне Abstract Syntax Tree (AST). Эти валидаторы заранее выявляют потенциально рискованные операции и запросы, которые синтаксически корректны, но семантически опасны (например, неограниченные сканы, отсутствие фильтров, некорректная логика агрегации). Если валидатор находит проблему, он возвращает подробную обратную связь с объяснением ошибки и предложением исправления.
Чтобы еще больше повысить устойчивость, весь цикл оборачивается в облегченного агента генерации SQL, который автоматически повторяет попытки, пока не получит корректный и исполнимый запрос или не исчерпает настраиваемый лимит повторов. Такой подход призван обеспечить значительно более высокую надежность, чем один только prompt engineering.
Этап 4: Параллельные вычисления на этапе тестирования
Для неоднозначных или сложных вопросов система может одновременно генерировать несколько возможных ответов или цепочек рассуждений, отправляя один и тот же вопрос параллельным агентам. Результаты затем синтезируются методом большинства голосов, и выбирается наиболее надежный вариант. Это особенно полезно для вопросов, которые можно интерпретировать по-разному, и заметно повышает как точность, так и устойчивость.
Этап 5: Синтез ответа
Наконец, сырые результаты запроса, включая числа, data frame и журналы выполнения, синтезируются в естественно-языковые повествования, которые пользователь получает как actionable-ответы. Полная прозрачность запроса сохраняется: пользователи могут в любой момент изучить сгенерированный SQL и исходные данные, что повышает доверие к результатам системы.
Ключевые стратегии для результатов production-качества
Одной архитектуры недостаточно. Следующие стратегии, полученные при внедрении решения в масштабе, необходимы для достижения точности, безопасности и отзывчивости, которых требует production-использование.
Позвольте конечным пользователям формировать промпты
Даже у опытных пользователей часто различаются базовые трактовки неоднозначных терминов и ожидания относительно ответов на расплывчатые вопросы. Мы рекомендуем создать интерфейс настройки, например веб-приложение, чтобы владельцы таблиц и назначенные power users могли настраивать промпты в рамках управляемых ограничений. Настройки должны проходить через validation guardrails, которые обеспечивают соблюдение политик контента, ограничивают попытки prompt injection и гарантируют, что изменения остаются в рамках утвержденных шаблонов и параметров. Это помогает избежать неограниченных свободных текстовых модификаций, при этом по-прежнему включая в систему доменные знания и предпочтения. Такая возможность настройки оказывается критически важной для достижения нюансированного понимания, которого требуют разные бизнес-домены. Ваша система должна учитывать эти различия, а не навязывать универсальный подход.
Рассматривайте валидацию SQL как критичный для безопасности слой
Один лишь prompt engineering не может устранить ошибки, из-за которых SQL синтаксически корректен, но семантически неверен. Эти ошибки особенно опасны, потому что они возвращают правдоподобные результаты, которые могут незаметно подорвать доверие пользователей или привести к неверным решениям. Поскольку SQL — это четко определенный язык, детерминированные валидаторы могут поймать широкий класс таких ошибок еще до того, как запрос попадет в базу данных. Во внутренних тестах этот слой валидации эффективно предотвращал серьезные ошибки в сгенерированных запросах. Сделайте его обязательным механизмом безопасности.
Агрессивно оптимизируйте задержку
Пользователи, привыкшие к conversational AI, ожидают почти мгновенных ответов. Хотя получение живых данных и выполнение вычислений по своей природе занимает больше времени, чем ответ из статической базы знаний, задержку все равно нужно активно управлять как ключевым аспектом пользовательского опыта. Анализ производительности показывает, что workflow состоит из нескольких шагов, и суммарное время на этих шагах дает наибольший потенциал для оптимизации по сравнению с самим временем выполнения SQL.
Для оптимизации сосредоточьтесь на:
- Параллельном выполнении агентов — обрабатывайте многосоставные вопросы одновременно, а не последовательно. Это может значительно сократить общее время сложных запросов.
- Высокопроизводительном аналитическом хранилище — используйте столбцовые базы данных, которые хорошо справляются с нагрузками BI, основанными на агрегациях.
- Оптимизации токенов — минимизируйте количество входных и выходных токенов на взаимодействие агента за счет оптимизации промптов и стандартизации формата ответа. Сокращайте зависимость от tool-calling agentic framework, где каждый вызов заставляет агента заново поглощать растущий контекст.
При таких оптимизациях в нашем развертывании простые SQL-запросы обычно генерируются примерно за 3–5 секунд. Фактическое время ответа будет зависеть от таких факторов, как производительность хранилища данных, сложность запроса, выбор модели и размер графа знаний. Мы рекомендуем проводить бенчмаркинг в вашей собственной среде, чтобы установить реалистичные целевые показатели задержки для интерактивной бизнес-аналитики.
Заложите безопасность и governance с самого начала
Внедрите интеграцию Row-Level Security (RLS), чтобы пользователи видели только те данные, к которым у них есть доступ. Система поддерживает составные таблицы прав доступа, которые обеспечивают политики контроля доступа из существующих организационных систем. Когда пользователь отправляет запрос, соответствующие RLS-фильтры автоматически внедряются в сгенерированный SQL перед выполнением. Для пользователя это прозрачно, но enforcement остается строгим. Проектируйте этот слой так, чтобы он поддерживал жесткие стандарты управления данными, не создавая трения для пользовательского опыта.
Результаты внедрения и эффект
Если следовать архитектуре и стратегиям, описанным в этом посте, решение text-to-SQL может существенно улучшить доступность данных и аналитическую продуктивность:
- Ускорение работы позволяет отвечать на сложные бизнес-вопросы за минуты вместо часов или дней, как это бывает при традиционном подходе. Вопросы, требующие соединения нескольких таблиц, временных расчетов и иерархических агрегаций, которые раньше нуждались в разработке индивидуального SQL, становятся доступны через естественный язык.
- Демократизация аналитики помогает нетехническим бизнес-пользователям в продажах, финансовом планировании и на уровне executive leadership выполнять сложный анализ данных без знания SQL. Это обычно снижает нагрузку на команды data engineering, позволяя им сосредоточиться на стратегических инициативах, а не на повторяющихся запросах.
- Работа со сложными запросами поддерживает многомерный анализ выручки со следующими возможностями:
- автоматическая сегментация;
- динамика год к году и месяц к месяцу с объяснением отклонений;
- клиентская аналитика на детальном уровне с паттернами использования;
- анализ отклонений прогноза с сравнением с целевыми показателями;
- кросс-функциональный бенчмаркинг по периодам времени и бизнес-единицам.
Что дальше
Решения text-to-SQL на базе Amazon Bedrock — это заметный шаг вперед в том, как сделать аналитику данных доступной для бизнес-пользователей. Мультиагентная архитектура с использованием Amazon Bedrock Agents поддерживает сложную декомпозицию запросов и параллельную обработку, а графы знаний обеспечивают бизнес-контекст и семантическое понимание. Вместе эти компоненты дают точную, быструю и доступную аналитику, которая помогает бизнес-пользователям принимать решения на основе данных без технических барьеров.
Когда вы строите собственное решение, подумайте о расширении покрытия графа знаний на дополнительные бизнес-домены, оптимизации задержки ответа с помощью продвинутых стратегий кэширования и интеграции с большим числом корпоративных источников данных. Amazon Bedrock Guardrails предлагают расширенную валидацию и механизмы безопасности вывода, которые стоит изучить, а Amazon Bedrock Flows предоставляют сложные паттерны оркестрации для agentic-workflow.
Гибкость FM, возможности оркестрации агентов и интеграция с knowledge base, доступные через Amazon Bedrock, продолжают развиваться, делая анализ данных все более интуитивным и мощным для бизнес-пользователей по всей организации.
Чтобы создать собственное решение text-to-SQL, изучите Руководство пользователя Amazon Bedrock, примите участие в Amazon Bedrock Workshop и ознакомьтесь с нашим руководством по созданию генеративных AI-агентов с Amazon Bedrock. За последними новостями см. What’s New with AWS.
Благодарности
Мы выражаем искреннюю благодарность нашим исполнительным спонсорам и наставникам, чье видение и руководство сделали эту инициативу возможной: Aizaz Manzar, Director of AWS Global Sales; Ali Imam, Head of Startup Segment; и Akhand Singh, Head of Data Engineering.
Материал — перевод статьи с английского.