Amazon Nova 2 Sonic: генератор разговорных подкастов в реальном времени на базе Bedrock
Искусственный интеллект
Создание разговорных подкастов в реальном времени с Amazon Nova 2 Sonic
Авторы контента и организации сегодня сталкиваются с постоянной проблемой: как производить высококачественный аудиоконтент в больших объемах. Традиционное производство подкастов требует значительных затрат времени на исследования, планирование, запись и монтаж, а также существенных ресурсов, включая студийное пространство, оборудование и голосовой талант. Эти ограничения замедляют реакцию организаций на новые темы и мешают масштабировать выпуск контента. Amazon Nova 2 Sonic — это современная модель понимания и генерации речи, которая обеспечивает естественный, похожий на человеческий разговорный ИИ с низкой задержкой и лучшим в отрасли соотношением цены и производительности. Она поддерживает потоковое распознавание речи, следование инструкциям, вызов инструментов и кросс-модальное взаимодействие, которое бесшовно переключается между голосом и текстом. Поддерживая семь языков и контекстные окна до 1 млн токенов, разработчики могут использовать Amazon Nova 2 Sonic для создания голосовых приложений для поддержки клиентов, интерактивного обучения и голосовых ассистентов.
В этой публикации показано, как построить автоматизированный генератор подкастов, который создает увлекательные беседы между двумя ИИ-ведущими на любую тему, демонстрируя возможности потоковой передачи Nova Sonic, фильтрацию контента с учетом стадии генерации и генерацию аудио в реальном времени.
Что такое Amazon Nova 2 Sonic?
Amazon Nova 2 Sonic обрабатывает речевой ввод и выдает речевой ответ и текстовые расшифровки, создавая похожие на человеческие разговоры с богатым контекстным пониманием. Amazon Nova 2 Sonic предоставляет потоковый API для многоходовых разговоров в реальном времени с низкой задержкой, поэтому разработчики могут создавать голосовые приложения, в которых речь управляет навигацией по приложению, автоматизацией рабочих процессов и выполнением задач.
Модель доступна через Amazon Bedrock и может интегрироваться с ключевыми возможностями Amazon Bedrock, включая Guardrails, Agents, multimodal RAG и Knowledge Bases, обеспечивая бесшовную совместимость по всей платформе.
Ключевые возможности:
- Потоковое понимание речи — обрабатывать речь и отвечать в реальном времени с низкой задержкой
- Следование инструкциям — выполнять сложные многошаговые голосовые команды
- Вызов инструментов — вызывать внешние функции и API во время разговора
- Кросс-модальное взаимодействие — бесшовно переключаться между голосовым и текстовым вводом/выводом
- Мультиязычная поддержка — нативная поддержка английского, французского, итальянского, немецкого, испанского, португальского и хинди
- Большое контекстное окно — до 1 млн токенов для сохранения расширенного контекста разговора
Понимание проблемы
Подкасты пережили взрывной рост, превратившись из нишевого формата в массовый. Этот рост обусловлен уникальной способностью подкастов передавать информацию во время многозадачной деятельности (в дороге, во время тренировок, домашних дел), обеспечивая преимущество по доступности, с которым не может сравниться визуальный контент.
Однако традиционное производство подкастов сталкивается со структурными трудностями:
Масштабируемость контента: живым ведущим требуется много времени на исследования, планирование, запись и постпродакшн, что ограничивает частоту и объем выпуска.
Последовательность: у людей-ведущих бывают конфликты в расписании, болезни, разный уровень энергии и ограничения по доступности, из-за чего график публикаций становится нерегулярным.
Персонализация: традиционные подкасты следуют модели «один размер для всех» и не могут в реальном времени адаптировать контент под интересы или уровень знаний конкретного слушателя.
Эффективность ресурсов: качественное производство требует значительных постоянных инвестиций в таланты, оборудование, ПО для монтажа и операционные накладные расходы.
Доступ к экспертам: привлечение знающих ведущих по самым разным темам остается сложной и дорогой задачей, ограничивая широту и глубину контента.
Используя разговорные возможности ИИ Amazon Nova Sonic, организации могут устранить эти ограничения и создавать новые интерактивные и персонализированные аудиоформаты, которые масштабируются глобально без традиционных ограничений человеческих ресурсов.
Обзор решения
Nova Sonic Live Podcast Generator демонстрирует, как создавать естественные беседы между ИИ-ведущими на любую тему с помощью speech-to-speech-модели Amazon Nova Sonic. Пользователь вводит тему через веб-интерфейс, а приложение формирует многораундовый диалог с чередующимися спикерами, который транслируется в реальном времени.
Ключевые функции
- Генерация аудио в реальном времени с низкой задержкой
- Естественный диалог туда-обратно в нескольких репликах
- Фильтрация контента с учетом стадии генерации, которая удаляет дублирующееся аудио
- Простой веб-интерфейс с обновлениями живого разговора
- Поддержка одновременных пользователей через архитектуру AsyncIO
- Несколько голосовых персон под разные сценарии использования
Требования
Чтобы реализовать это решение, необходимо выполнить следующие условия:
- Аккаунт AWS с доступом к Amazon Bedrock и модели Amazon Nova 2 Sonic
- Python 3.8 или более поздней версии
- Веб-фреймворк Flask и AsyncIO
- Настроенные учетные данные AWS (access key, secret key, регион AWS)
- Среда разработки с менеджером пакетов pip
Детали реализации
Подробные примеры кода и полное руководство по реализации доступны в GitHub.
Обзор архитектуры
Решение построено на архитектуре Flask с потоковой обработкой и реактивной обработкой событий и предназначено для демонстрации возможностей Amazon Nova Sonic в качестве proof of concept и учебного примера.
Диаграмма системной архитектуры
Следующая диаграмма иллюстрирует архитектуру потоковой передачи в реальном времени:
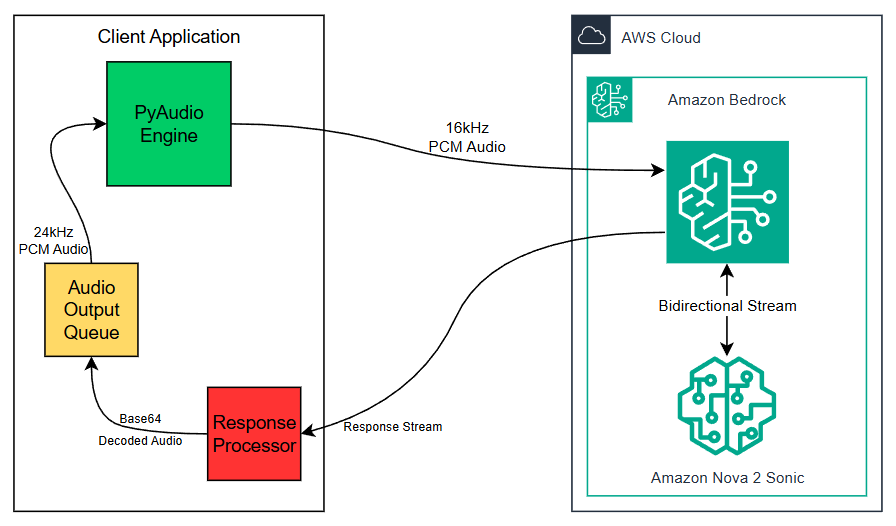
Компоненты архитектуры
Архитектура использует многоуровневый подход с четким разделением ответственности:
Клиентское приложение содержит три тесно связанные компонента, которые управляют всем жизненным циклом аудио:
- PyAudio Engine захватывает ввод с микрофона в формате 16kHz PCM и передает его в Amazon Bedrock. Он также получает готовое к воспроизведению аудио из Audio Output Queue в формате 24kHz PCM, обрабатывая вывод на динамики в реальном времени.
- Response Processor получает необработанный поток ответа, возвращаемый Amazon Nova Sonic, декодирует аудиополезную нагрузку в Base64 и передает декодированное аудио в Audio Output Queue.
- Audio Output Queue выступает буфером между Response Processor и PyAudio Engine, сглаживая ответы с переменной задержкой и обеспечивая плавное, непрерывное воспроизведение аудио в 24kHz PCM.
Облако AWS — вся связь с моделью проходит через Amazon Bedrock, который посредничает в двунаправленном потоке событий с Amazon Nova Sonic:
- Amazon Bedrock получает исходящий аудиопоток 16kHz PCM от PyAudio Engine и направляет его в модель. Он же возвращает поток ответа модели клиенту.
- Amazon Nova Sonic получает аудиоввод через двунаправленный поток, выполняет speech-to-speech-вывод в реальном времени и возвращает поток ответа, содержащий синтезированное аудио, закодированное в Base64 PCM с частотой 24kHz.
Примечание об архитектуре для продакшена: В этой реализации для демонстрации используются Flask и PyAudio. PyAudio не обеспечивает встроенную компенсацию эха и лучше подходит для воспроизведения звука на стороне сервера. Для продакшн-веб-приложений рекомендуются JavaScript-библиотеки для работы со звуком (Web Audio API) или WebRTC, которые обеспечивают нативную обработку в браузере с лучшей компенсацией эха и меньшей задержкой. См. репозиторий GitHub для шаблонов продакшн-архитектуры.
Ключевые технические инновации
Интеграция с Amazon Bedrock
В основе системы лежит BedrockStreamManager — пользовательский компонент, который управляет постоянными соединениями с моделью Amazon Nova 2 Sonic. Этот менеджер обрабатывает сложности взаимодействия с потоковым API, включая инициализацию, отправку сообщений и обработку ответов. Учетные данные AWS, настроенные через переменные окружения, обеспечивают безопасный доступ к foundation model (FM). Полный код доступен в репозитории GitHub
# Инициализация BedrockStreamManager для каждого хода беседы
manager = BedrockStreamManager(
model_id='amazon.nova-sonic-v1:0',
region='us-east-1'
)
# Настройка голосовой персоны (Matthew или Tiffany)
manager.START_PROMPT_EVENT = manager.START_PROMPT_EVENT.replace(
'"matthew"', f'"{voice}"'
)
# Инициализация потокового соединения
await manager.initialize_stream()Реактивный потоковый конвейер
Приложение использует RxPy (Reactive Extensions for Python) для реализации observable-подхода к обработке потоков данных в реальном времени. Эта реактивная архитектура обрабатывает аудиофрагменты и текстовые токены по мере их поступления от Amazon Nova Sonic, а не ждет завершения ответа.
# Подписка на поток событий от BedrockStreamManager
manager.output_subject.subscribe(on_next=capture)
# Функция capture обрабатывает события в реальном времени
def capture(event):
if 'textOutput' in event['event']:
text = event['event']['textOutput']['content']
text_parts.append(text)
if 'audioOutput' in event['event']:
audio_chunks.append(event['event']['audioOutput']['content'])output_subject в BedrockStreamManager выступает центральной шиной событий, поэтому несколько подписчиков могут одновременно реагировать на потоковые события. Такое решение снижает задержку и улучшает пользовательский опыт за счет немедленной обратной связи.
Фильтрация контента с учетом стадии генерации
Одно из ключевых технических новшеств в этой реализации — механизм фильтрации с учетом стадии. Amazon Nova 2 Sonic генерирует контент в нескольких стадиях: SPECULATIVE (предварительная) и FINAL (полированная). Приложение реализует интеллектуальную логику фильтрации, которая отслеживает события contentStart на наличие метаданных о стадии генерации. Оно захватывает только контент стадии FINAL, чтобы удалить дублирующееся или предварительное аудио и предотвратить аудиоартефакты, обеспечивая чистый, естественно звучащий результат.
def capture(event):
nonlocal is_final_stage
if 'event' in event:
# Определение стадии генерации по событию contentStart
if 'contentStart' in event['event']:
content_start = event['event']['contentStart']
if 'additionalModelFields' in content_start:
additional_fields = json.loads(content_start['additionalModelFields'])
stage = additional_fields.get('generationStage', 'FINAL')
is_final_stage = (stage == 'FINAL')
# Захватывать контент только на стадии FINAL
if is_final_stage:
if 'textOutput' in event['event']:
text = event['event']['textOutput']['content']
if text and '{ "interrupted" : true }' not in text:
text_parts.append(text)
if 'audioOutput' in event['event']:
audio_chunks.append(event['event']['audioOutput']['content'])Фильтрация работает на трех уровнях:
- Фильтр прерванного контента — удаляет отмененный контент, проверяя маркеры прерывания.
- Дедупликация текста — отфильтровывает точные дубликаты текста между стадиями SPECULATIVE и FINAL.
- Дедупликация аудио по хэшу — отфильтровывает дублирующиеся аудиофрагменты с использованием хеш-отпечатков.
Эта фильтрация выполняется в реальном времени внутри callback-функции capture, которая подписывается на поток вывода и выборочно обрабатывает события в зависимости от стадии генерации.
Примечание: Показанные фрагменты кода упрощены для наглядности. Переменная is_final_stage должна быть определена во внешней области видимости. Полные production-ready-реализации см. в репозитории GitHub.
Управление беседой
Система реализует модель беседы по очередям с несколькими раундами диалога. Каждый ход следует устойчивому шаблону естественного разговора:
- История разговора — приложение сохраняет контекст беседы через переменные, специфичные для каждого спикера, чтобы каждый участник мог ссылаться на сказанное ранее.
- Динамическая генерация промптов — промпты формируются динамически на основе роли спикера и контекста беседы, например Matthew (ведущий) представляет темы и задает уточняющие вопросы, а Tiffany (эксперт) дает содержательные ответы.
- Свежий поток на каждый ход — приложение создает новый экземпляр
BedrockStreamManagerдля каждого хода спикера, предотвращая загрязнение состояния между ходами и обеспечивая чистые аудиопотоки.
Модель асинхронного выполнения
Чтобы справиться с блокирующей природой воспроизведения аудио и вызовов API модели, приложение создает новый цикл событий asyncio для каждого запроса на генерацию подкаста. Благодаря этому несколько пользователей могут одновременно генерировать подкасты, не блокируя друг друга. Цикл управляет инициализацией потока, отправкой промптов, синхронизацией воспроизведения аудио и очисткой, поддерживая одновременную работу при четком разделении пользовательских сессий.
Обзор потока данных
Система следует упрощенному потоку от пользовательского ввода до аудиовывода. Пользователь вводит тему, бэкенд организует ходы беседы с динамической генерацией промптов, Amazon Nova 2 Sonic генерирует речевые ответы через потоковый API, а фильтрация с учетом стадии следит за тем, чтобы в аудиоконвейер для воспроизведения попадал только отшлифованный контент FINAL.
Подробные примеры кода и полное руководство по реализации доступны в GitHub.
Сценарии использования
Архитектура Amazon Nova 2 Sonic позволяет автоматизировать создание интерактивного аудиоконтента в разных отраслях. Оркестрируя диалог нескольких экземпляров conversational AI, организации могут создавать увлекательный, естественно звучащий контент в больших масштабах.
Интерактивное обучение и обмен знаниями
Организациям сложно создавать увлекательный контент, который помогает людям учиться и запоминать информацию — будь то обучение студентов или сотрудников. Экземпляры Amazon Nova 2 Sonic могут имитировать классные обсуждения или сократические диалоги, когда один экземпляр задает вопросы, а другой дает объяснения и примеры.
Для учебных заведений это создает динамичные учебные сценарии, учитывающие разные стили и темпы обучения. Для компаний это превращает внутренние коммуникации (политики, процедуры, организационные изменения) в разговорные форматы, которые сотрудники могут потреблять в режиме многозадачности. Интеграция с Retrieval Augmented Generation (RAG) и Amazon Bedrock Knowledge Bases поддерживает актуальность контента и его соответствие учебной программе или требованиям организации, а разговорный формат повышает запоминаемость информации и уменьшает количество дополнительных вопросов.
Локализация многоязычного контента
Глобальным организациям нужна единая коммуникация на разных рынках при уважении культурных нюансов. Поддержка Amazon Nova Sonic для английского, французского, итальянского, немецкого, испанского, португальского и хинди позволяет создавать локализованный аудиоконтент с естественно звучащими беседами. Модель может генерировать обсуждения, адаптированные под рынок, которые учитывают язык, культурные отсылки и стили общения, выходя за рамки простого перевода и создавая культурно релевантный контент, находящий отклик у местной аудитории.
Возможности polyglot voice — отдельные голоса, которые могут переключаться между языками внутри одного разговора, — обеспечивают продвинутые возможности code-switching и естественную обработку смешанных языковых предложений. Это особенно ценно для многоязычной поддержки клиентов и глобального командного взаимодействия.
Комментарий к продуктам и обзоры
Ecommerce-платформам нужны увлекательные способы помочь клиентам понять сложные продукты. Экземпляры Amazon Nova 2 Sonic могут генерировать разговорные обзоры продуктов, где один участник задает типичные вопросы клиентов, а другой отвечает на основе спецификаций, отзывов пользователей и технической документации. Это создает доступный контент, который помогает клиентам оценивать товары через естественный диалог, а интеграция с каталогами продуктов обеспечивает точность.
Лидерство мнений и отраслевой анализ
Консалтинговым и профессиональным сервисным компаниям нужно регулярно публиковать контент, чтобы укреплять лидерство мнений, но подготовка аналитики требует значительных затрат времени. Экземпляры Amazon Nova 2 Sonic могут вести экспертные обсуждения отраслевых трендов или рыночного анализа, где один участник оспаривает предположения, а другой отстаивает позицию данными. Это позволяет организациям переупаковывать существующие исследования в доступный аудиоконтент, который доходит до занятых руководителей, предпочитающих аудиоформаты.
Характеристики производительности
- Задержка: потоковая передача с низкой задержкой и немедленным воспроизведением аудио
- Длительность подкаста: гибкая длительность в зависимости от числа реплик (обычно 2–5 минут)
- Одновременные пользователи: поддержка нескольких параллельных генераций подкаста через AsyncIO
- Качество звука: синтез речи профессионального уровня с естественной интонацией и темпом
- Поддержка языков: английский, французский, итальянский, немецкий, испанский, португальский и хинди
- Контекстное окно: до 1 млн токенов для расширенного контекста разговора
Заключение
Amazon Nova 2 Sonic — это современная модель понимания и генерации речи, которая обеспечивает естественный, похожий на человеческий conversational AI-опыт. Описанная в этой статье архитектура дает практическую основу для создания разговорных AI-приложений. Независимо от того, идет ли речь об оптимизации поддержки клиентов, создании образовательного контента или генерации материалов для лидерства мнений, показанные здесь паттерны применимы во множестве сценариев.
Благодаря расширенной языковой поддержке, возможностям polyglot voice, улучшенной телеком-интеграции и кросс-модальному взаимодействию Amazon Nova 2 Sonic дает организациям инструменты для создания глобальных голосовых приложений в больших масштабах.
Чтобы начать работу с Amazon Nova Sonic, перейдите на страницу продукта Amazon Nova. Для полной документации изучите руководство пользователя Amazon Nova 2 Sonic.
Узнать больше
- Страница продукта Amazon Nova 2 Sonic
- Документация Amazon Bedrock
- Руководство пользователя Amazon Nova 2 Sonic
- Блог AWS: представляем Amazon Nova Sonic
- Репозиторий GitHub: официальные примеры AWS
Материал — перевод статьи с английского.
Оригинал: Building real-time conversational podcasts with Amazon Nova 2 Sonic