Vanguard построила Virtual Analyst на основе AI-ready data и AWS

Vanguard — глобальная инвестиционная управляющая компания, предлагающая широкий набор инвестиций, консультаций, пенсионных сервисов и аналитики частным инвесторам, институциональным клиентам и финансовым специалистам. Мы работаем по уникальной модели, принадлежащей инвесторам, и придерживаемся простого принципа: выступать за всех инвесторов, относиться к ним справедливо и давать им наилучшие шансы на инвестиционный успех.
Когда финансовым аналитикам Vanguard нужно было запрашивать сложные наборы данных, они сталкивались с неудобной реальностью: даже на базовые вопросы приходилось писать сложные SQL-запросы и нередко ждать ответа от команд данных несколько дней. Эта проблема не уникальна для Vanguard: conversational AI может масштабируемо давать аналитикам ответы почти сразу. Но для внедрения conversational AI недостаточно выбрать подходящую foundation model — нужна инфраструктура AI-ready data.
В этом материале вы узнаете, как Vanguard создала решение Virtual Analyst, опираясь на восемь принципов AI-ready data, какие сервисы AWS легли в основу реализации и каких измеримых бизнес-результатов компания добилась.
Проблема: когда AI сталкивается со сложностью корпоративных данных
Аналитикам Vanguard и бизнес-заказчикам был нужен более быстрый и прямой доступ к финансовым данным для принятия решений. Существующий процесс требовал знаний SQL и поддержки команд данных, а типичные запросы выполнялись по несколько дней. Инфраструктуре данных не хватало семантического контекста и управления метаданными, чтобы инструменты на базе AI могли формировать точные и бизнес-значимые выводы.
По мере развития проекта Virtual Analyst команда поняла, что создание эффективного conversational AI — это не задача машинного обучения, а задача архитектуры данных. Даже самые совершенные foundation models нуждаются в правильной основе данных, чтобы выдавать надежные результаты. Это привело к фундаментальному изменению подхода: вместо концентрации только на возможностях AI Vanguard решила строить то, что назвала AI-ready data.
Необходимость совместной работы: разрушение силосов
Создание Virtual Analyst требовало того, с чем многие организации сталкиваются с трудом: заставить традиционно изолированные команды работать вместе. Vanguard объединила инженеров данных, бизнес-аналитиков, специалистов по комплаенсу, команды безопасности и бизнес-заказчиков. Каждая группа принесла критически важную экспертизу:
- Инженеры данных понимали техническую инфраструктуру
- Бизнес-аналитики знали семантический смысл финансовых метрик
- Команды комплаенса помогали соблюдать регуляторные требования
- Бизнес-пользователи давали практический контекст того, как именно будут использоваться инсайты.
Это межфункциональное взаимодействие стало основой для AI благодаря формированию четко определенной межфункциональной операционной модели, в которой модели ответственности, семантические определения и стандарты качества были понятны и применялись всеми участниками. Команда поняла, что без ясных моделей владения, семантических определений и стандартов качества, которые были бы понятны всем командам и в которых они могли бы участвовать, у AI-решения не будет прочной основы. Проект Virtual Analyst стал катализатором новых процессов и фреймворков, которые дают пользу далеко за пределами первоначального сценария AI. На следующем рисунке показан blueprint AI-ready data, разработанный для архитектуры Virtual Analyst.
Пример: Virtual Analyst
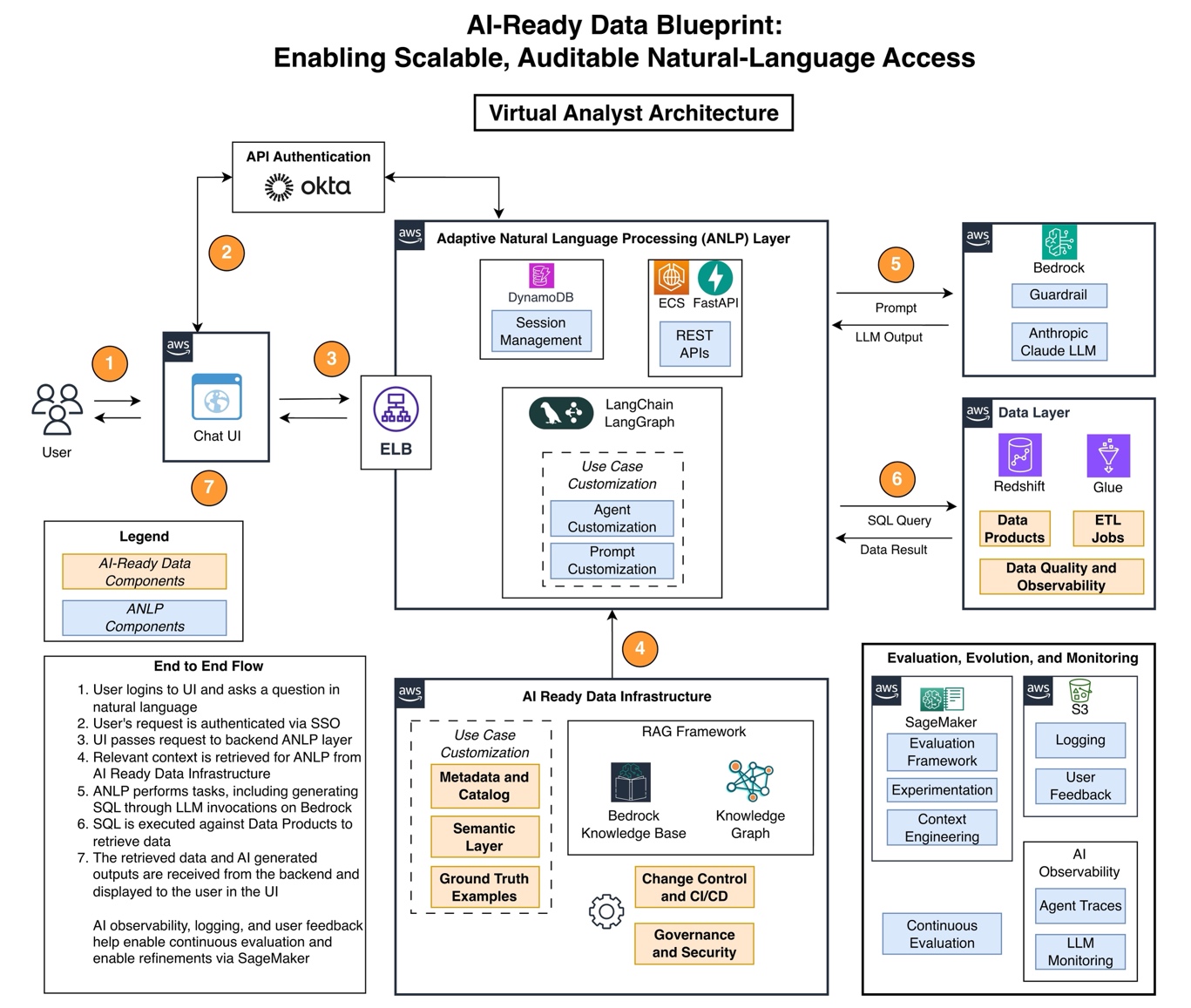
Архитектура отражает одну конкретную реализацию, зависящую от контекста, и ее следует рассматривать как иллюстративную, а не предписывающую.
Vanguard выбрала AWS за его комплексный набор интегрированных сервисов. AWS предлагает богатый функционал для построения архитектур AI-ready data — от расширенной аналитики Amazon Redshift до автоматического каталогизирования данных в AWS Glue и доступа к foundation models через Amazon Bedrock. Кроме того, функции безопасности и соответствия требованиям AWS отвечали строгим стандартам финансовой отрасли. Virtual Analyst использует:
- Amazon Bedrock для foundation models, которые обеспечивают понимание естественного языка
- Amazon Bedrock Guardrails для защиты входных и выходных данных AI и охраны чувствительных финансовых данных Vanguard
- Amazon Elastic Container Service (Amazon ECS) для масштабируемой вычислительной инфраструктуры
- Amazon DynamoDB для хранения истории диалога в горизонтально масштабируемой архитектуре с минимальной задержкой
- Amazon Simple Storage Service (Amazon S3) для хранения
- Amazon SageMaker для экспериментов
- Amazon Redshift для централизованного хранилища данных
- AWS Glue для каталогизации данных и запуска множества задач extract, transform, load (ETL), которые консолидируют точные данные
Восемь принципов AI-ready data
В ходе работы над Virtual Analyst Vanguard выделила восемь принципов, которые опираются на существующие базовые возможности работы с данными, такие как data platforms, integration и interoperability, и расширяют их для поддержки AI-ready data. Эти принципы появились из реальных проблем, с которыми команда столкнулась, пытаясь заставить AI-системы надежно работать с корпоративными данными в масштабе.
Определите четкие модели данных и операционную модель
Более высокое качество данных требует четкой ответственности. Владельцы data product отвечают за соответствие бизнес-целям, а инженерные стюарды должны поддерживать техническое качество. Service-level agreements (SLAs) по свежести данных и допустимому отклонению при сверке, а также формализованные модели поддержки для downstream-потребителей помогут сделать data product повторно используемыми, хорошо управляемыми и ориентированными на результат. Назначайте и бизнес-владельца, и технического владельца каждому критически важному data asset и фиксируйте их обязанности письменно.
Определите меры управления и безопасности
Заранее подключайте команды комплаенса и безопасности, чтобы выстроить управление корпоративной идентификацией, ролевой доступ к данным, авторизацию на уровне запросов и политики хранения. Vanguard реализовала логирование событий авторизации, чтобы соответствовать регуляторным требованиям и одновременно поддерживать гибкость бизнеса. Сопоставьте существующие политики доступа к данным с новой AI-системой и при необходимости внедрите row-level и column-level security.
Постройте каталог метаданных, объединяющий технический и бизнес-контекст
Реализуйте единый system of record для метаданных и каталог как control plane, который централизует и технические, и бизнес-метаданные, предоставляя к ним доступ через API. Во многих организациях технические метаданные ведутся полноценно, но отсутствует связанный бизнес-контекст, из-за чего возникает рассогласование между технической реализацией и бизнес-требованиями. Технические метаданные включают описания таблиц и столбцов с типами данных, lineage данных через преобразования, синонимы и категориальные индикаторы, а также карты связей между наборами данных. Этот слой определяют технические эксперты предметной области и data stewards. Начните с наиболее часто используемых наборов данных и последовательно документируйте их технические метаданные, прежде чем расширяться на другие источники. Версионируйте метаданные и измеряйте точность сопоставления, чтобы поддерживать обнаруживаемость и точность. Бизнес-метаданные фиксируют бизнес-определения и правила для конкретных атрибутов, отраслевую терминологию и онтологии, информацию о владельцах бизнеса и контекст использования. Бизнес-пользователи и эксперты предметной области вносят вклад в этот слой через совместные процессы управления. Единый каталог объединяет эти два типа метаданных, позволяя AI-системам формировать точные запросы, соответствующие и технической структуре, и бизнес-смыслу.
Реализуйте semantic layer, чтобы операционализировать бизнес-метаданные
Semantic layer превращает бизнес-метаданные, определенные в каталоге, в удобные для пользователя формы, преобразуя сложные структуры данных в практичные представления. Этот слой реализации переводит бизнес-определения, правила и онтологии в исполняемую логику, которая стандартизирует то, как организация определяет ключевые метрики и связи между различными элементами данных. Когда такой слой внедрен, бизнес-аналитики могут выражать свое понимание связей в данных на естественном языке, который затем интерпретируется и преобразуется в структурированные SQL-запросы. За счет применения бизнес-определений и связей, задокументированных в каталоге метаданных, semantic layer повышает единообразие запросов, снижает риск ошибок и упрощает генерацию SQL. Например, semantic layer Vanguard поддерживает определение customer lifetime value во всех подразделениях и системах, реализуя бизнес-правила, заданные бизнес-пользователями. Работайте с бизнес-заказчиками, чтобы задокументировать 20 наиболее часто используемых метрик вашей организации, включая их точные определения и методы расчета.
Создайте примеры ground truth
Примеры ground truth — еще один критически важный компонент. Они представляют собой набор пар вопрос–SQL, которые показывают, какие запросы могут задавать пользователи. Создайте библиотеку пар вопрос–SQL, иллюстрирующих разные пользовательские запросы и их корректные переводы в структуру базы данных. Vanguard собрала более 50 exemplars, которые выполняют три функции: few-shot prompts для AI-модели, evaluation benchmarks для измерения точности относительно заранее известных правильных ответов и regression testing, чтобы убедиться, что новые изменения не ломают существующую функциональность. Эти примеры помогают AI-системе обучаться через in-context learning. Начните с 20–30 примеров, покрывающих самые распространенные шаблоны запросов, а затем расширяйте набор на основе отзывов пользователей и обнаруженных крайних случаев.
Внедрите автоматические проверки качества данных
Vanguard настроила инструменты observability для мониторинга надежности данных с помощью автоматических проверок:
- Distributional checks — обнаружение аномалий в паттернах данных, например резких всплесков или падений значений
- Referential checks — проверка того, что связи между таблицами остаются корректными, например каждый заказ ссылается на действительного клиента
- Reconciliation checks — подтверждение согласованности данных между системами, например когда итоги совпадают между источником и хранилищем
- Freshness checks — подтверждение, что обновления данных происходят по расписанию
Установите процессы управления изменениями
Относитесь к семантическим определениям, exemplars и конфигурациям как к коду под version control. Процессы change control и continuous integration and deployment (CI/CD) рассматривают семантические определения, exemplars и конфигурации pipeline как код в рамках непрерывной интеграции со staged deployments и gated approvals. Такой подход требует одобрения заинтересованных сторон для изменений, влияющих на KPI или SLA, и одновременно позволяет безопасно и быстро внедрять улучшения. Формализованный процесс управления изменениями необходим для управления динамической природой ландшафта данных и помогает Virtual Analyst эффективно адаптироваться к изменениям. Начните хранить определения данных в системе контроля версий, такой как Git, и требуйте peer review перед выводом изменений в production.
Создайте механизмы непрерывной оценки
Наконец, используйте процессы непрерывной оценки и улучшения, определяя бизнес-метрики, включая сэкономленные часы аналитиков, ускорение time-to-insight, удовлетворенность пользователей и, где возможно, измеримое влияние на выручку или прибыль. Система поддерживает непрерывные regression suites и циклы обратной связи от пользователей, чтобы обновлять примеры и семантику, а также автоматические оповещения о деградации модели и отслеживание влияния на бизнес. Определите 3–5 ключевых метрик, важных для ваших бизнес-заказчиков, и зафиксируйте базовые значения до запуска AI-системы.
Результаты: от эксперимента к корпоративной возможности
Фокус на AI-ready data принес измеримые результаты:
- Сокращение time-to-insight с нескольких дней до нескольких минут для сложных финансовых запросов благодаря Virtual Analyst
- Возможность для бизнес-пользователей получать данные самостоятельно, без знаний SQL
- Высокая точность AI-генерируемых SQL-запросов благодаря реализации каталога метаданных и semantic layer
- Снижение нагрузки на команды данных при выполнении рутинных аналитических запросов
- Создание повторно используемого фреймворка, который теперь внедряется в нескольких бизнес-подразделениях Vanguard.
Что дальше
Vanguard оценивает возможности того, как knowledge graphs и Retrieval-Augmented Generation (RAG) могут дополнительно усилить Virtual Analyst. Knowledge graphs могут дать явные связи между сущностями, canonical resolution и междоменный контекст, что заметно улучшит fuzzy matching, join inference и explainability для генерируемых запросов. Системы RAG, использующие Amazon Bedrock Knowledge Bases, могут применять библиотеку exemplars для повышения точности и одновременно заложить основу для интеллектуальных механизмов обратной связи, которые будут постепенно улучшать качество и надежность модели.
Вывод: от AI-проекта к преобразованию данных
В этом материале мы показали, как Vanguard установила новые стандарты и способы работы, запустившие трансформацию ее аналитических возможностей и сделавшие данные стратегическим активом. То, что начиналось как AI-проект, показало, какая основа нужна организации для внедрения AI-возможностей, что и демонстрируют эти восемь принципов. Успешный AI — это не только более совершенные алгоритмы, но и более качественная база данных, которая поддерживает AI в масштабе предприятия. Сочетание интегрированных сервисов данных и AI от AWS вместе с дисциплинированными практиками data product помогает организациям превращать возможности моделей в надежные бизнес-результаты, на которые руководители могут опираться при принятии критически важных решений.
Материал — перевод статьи с английского.
Оригинал: Building AI-ready data: Vanguard’s Virtual Analyst journey