Amazon Quick добавил источник данных Amazon S3 Tables для Apache Iceberg и near real-time аналитики
Организации все чаще стремятся сочетать аналитику и AI, чтобы ускорять получение инсайтов и принятие решений. Amazon Quick — унифицированный сервис аналитики и принятия решений на базе agentic AI — объединяет визуализацию данных, взаимодействие на естественном языке и автоматизацию с помощью агентов в едином управляемом опыте. Благодаря этому бизнес-пользователи могут исследовать данные, получать инсайты и предпринимать действия без специализированных знаний в области machine learning (ML).
Параллельно современные архитектуры данных смещаются в сторону масштабируемых data lake на открытых табличных форматах, таких как Apache Iceberg, которые обеспечивают лучшую производительность, экономичность и управляемость. Однако анализ больших массивов данных часто требует перемещения их в data warehouse или OLAP-системы, что добавляет задержку, затраты и операционную сложность. Хотя существующие режимы запросов — такие как Direct Query и SPICE (Super-fast, Parallel, In-memory Calculation Engine) в связке с data warehouse — закрывают большинство аналитических сценариев, заказчики по-прежнему ищут более удобный способ анализировать большие почти实时овые наборы данных прямо из своих data lake.
Чтобы решить эту задачу, Amazon Quick добавляет Amazon S3 Tables (таблицы Apache Iceberg) в качестве нового источника данных. Теперь клиенты могут напрямую выполнять запросы и визуализировать таблицы Apache Iceberg, хранящиеся в S3 table bucket, без промежуточных слоев данных. Такой подход дает дополнительный выбор архитектуры, особенно когда нужно сократить перемещение данных, повысить производительность и сохранить защищенный, управляемый единый источник истины.
В этой статье мы рассматриваем, как Amazon Quick и S3 Tables работают вместе, чтобы обеспечить near real-time аналитику и упростить современные архитектуры данных.
Преимущества прямого подключения к S3 Tables:
Direct Query и SPICE для S3 Tables — новая возможность Amazon Quick, которая позволяет напрямую использовать таблицы Apache Iceberg в Amazon S3 table bucket без промежуточных уровней запросов. Эта функция особенно полезна для компаний, которые строят современную архитектуру данных на основе открытого формата Apache Iceberg и хотят использовать свой data lake как «центральный источник истины», получая высокопроизводительную аналитику без сложных data pipeline и без накладных расходов на перемещение данных между разрозненными системами.
Ключевые преимущества:
- Упрощенная архитектураУстраняет необходимость в отдельных data warehouse или OLAP-слоях, позволяя выполнять прямые запросы к данным в data lake и снижая операционную сложность и инфраструктурные накладные расходы.
- Инсайты near real-timeМинимизирует перемещение данных и зависимость от pipeline, чтобы дашборды и аналитика отражали самые актуальные данные.
- Масштабируемая производительностьПоддерживает запросы к крупным наборам данных, хранящимся в Amazon S3 table bucket, без необходимости в курировании данных, репликации или ограничениях по размеру, обеспечивая бесшовное масштабирование.
Обзор решения
С этим запуском Amazon Quick теперь поддерживает запросы к data lake через режимы SPICE или Direct Query. В этой статье мы сосредоточимся на Direct Query, хотя при создании набора данных можно выбрать и SPICE.
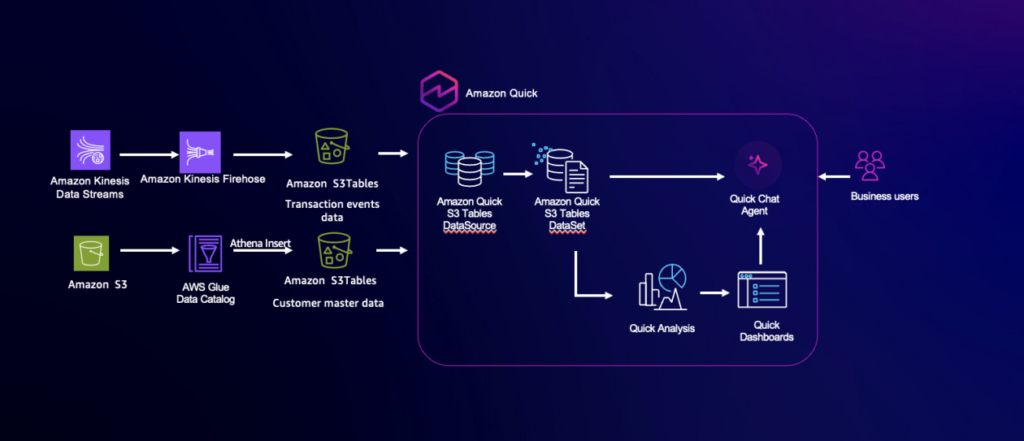
Решение обеспечивает near real-time аналитику и принятие решений для AnyCompany Corp. — глобальной финансовой организации, обрабатывающей карточные транзакции в нескольких регионах. Данные о транзакциях поступают из разных источников, включая POS-системы, мобильные банковские приложения, IoT-устройства для платежей и онлайн-шлюзы. Чтобы обеспечить обнаружение мошенничества, мониторинг коэффициента одобрения и быстрый доступ к прикладным инсайтам, решение использует сочетание потокового приема данных, data lake на открытом табличном формате и AI-аналитики.
События транзакций передаются в Amazon Kinesis Data Streams и доставляются через Amazon Data Firehose в Amazon S3 table bucket. Благодаря нативному коннектору S3 Tables в Quick бизнес-пользователи могут выполнять запросы к data lake near real-time и анализировать данные с помощью взаимодействия на естественном языке, избавляясь от зависимости от пакетной обработки. Такой единый подход позволяет мгновенно выявлять, например, региональные тренды мошенничества и уровни одобрения, повышая операционную прозрачность и ускоряя принятие решений на основе данных.
Обзор архитектуры
Архитектура состоит из четырех основных слоев: приема данных, хранения, запросов и аналитики. В этой статье мы сосредоточимся на слоях query и analytics. События транзакций из распределенных платежных систем поступают в реальном времени через Amazon Kinesis Data Streams, формируя масштабируемый потоковый слой с низкой задержкой. Эти события непрерывно доставляются в Amazon S3 table bucket в формате Apache Iceberg, создавая высокопроизводительный data lake, который поддерживает как потоковые, так и аналитические нагрузки. Если раньше данные можно было запрашивать через Amazon Athena, то Amazon Quick позволяет выполнять прямые near real-time запросы к S3 Tables и использовать AI-аналитику на естественном языке. Бизнес-пользователи могут изучать живые наборы данных, строить визуализации и получать инсайты — например, определять регионы с высоким уровнем мошенничества за последний час — без технической подготовки. Такая архитектура помогает принимать решения, опираясь на самые актуальные данные, и поддерживает быстрые и точные бизнес-действия.
Требования
Чтобы следовать примеру из этой статьи, убедитесь, что у вас уже есть следующее:
- Ваш streaming pipeline, включая слои приема и хранения данных, уже настроен, а данные доступны в Amazon S3 table bucket.
- Подписка Amazon Quick Enterprise.
Шаги реализации
Ниже приведены шаги, которые позволяют предоставить бизнес-пользователям доступ к таблицам Apache Iceberg для аналитических и conversational-нагрузок Amazon Quick:
Шаг 1: Включите доступ к S3 Tables для Amazon Quick
Начнем с настройки Amazon Quick для доступа к S3 Tables, чтобы их можно было автоматически обнаруживать при создании источника данных.
- В правом верхнем углу выберите имя своей учетной записи и нажмите Manage account.
- В левом меню, в разделе Permissions, выберите AWS Resources.
- В разделе Allow access and auto discovery for these resources выберите Amazon S3 Tables.
- Нажмите Select S3 table buckets, затем выберите нужный S3 table bucket с примером данных для этой статьи и нажмите Finish. (В этой статье используется bucket s3table-datasamples.)
- Убедитесь, что выбран параметр Amazon S3 bucket, затем нажмите Save.
Этот шаг добавляет необходимые разрешения в роль Amazon Quick и позволяет экземплярам Amazon Quick успешно обнаруживать данные в конкретном S3 table bucket при создании источника данных.
Шаг 2: Создайте источник данных Amazon Quick с использованием S3 Tables
Теперь создадим источник данных Amazon Quick, указывающий на bucket s3table-datasamples. Этот bucket содержит две таблицы: измерение customer и transaction_events. Таблица измерения customer является файловой и содержит вымышленные данные банковских клиентов, а transaction_events представляет вымышленные потоковые данные по транзакциям по кредитным картам, связанные с этими клиентами.
- В левом верхнем углу выберите Amazon Quick, чтобы перейти на домашнюю страницу Quick.
- В меню выберите Datasets, затем перейдите на вкладку Data sources и нажмите Create data source.
- На следующем экране выберите Amazon S3 Tables (Apache Iceberg tables) в качестве типа источника данных, затем нажмите Next.
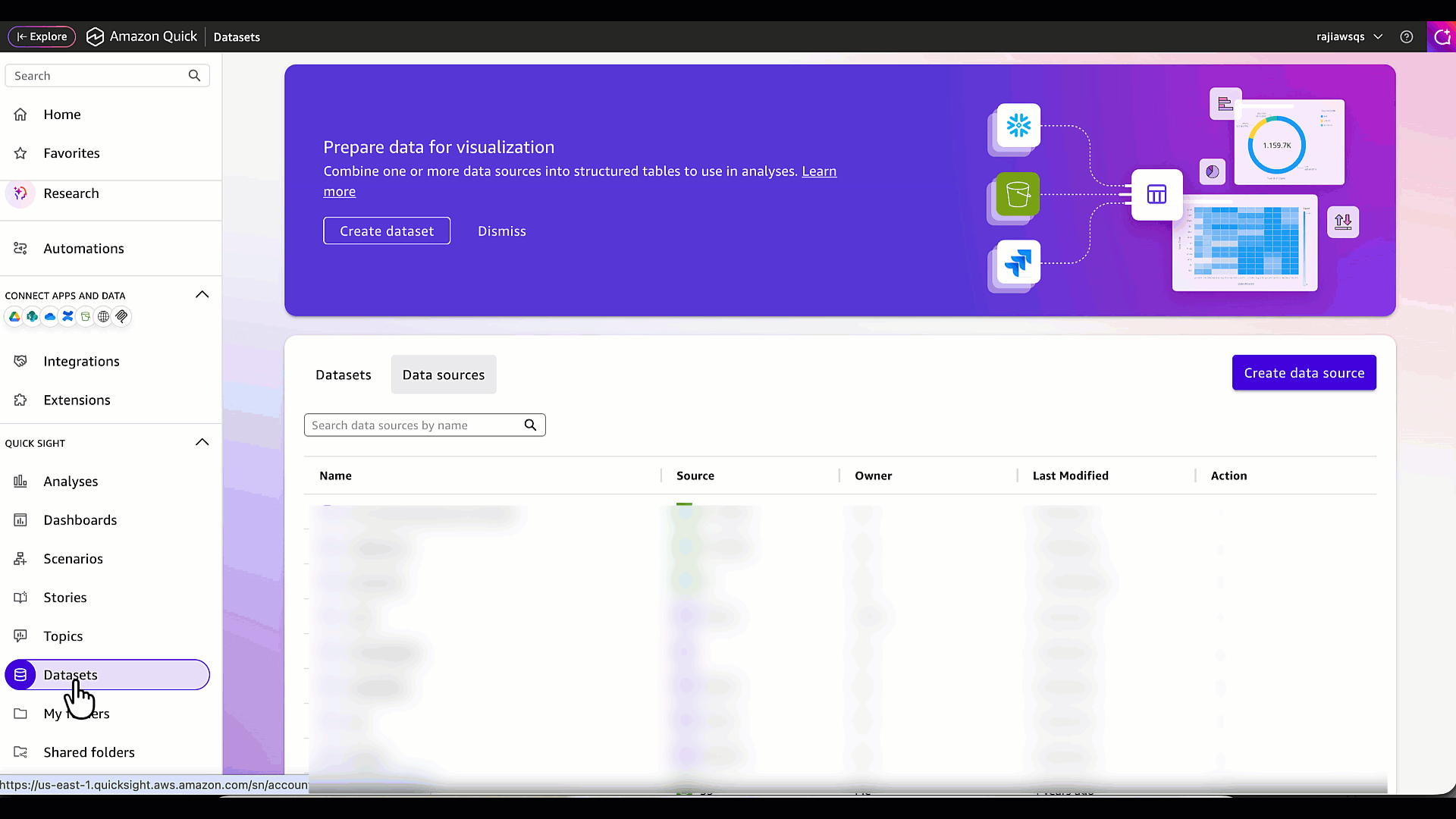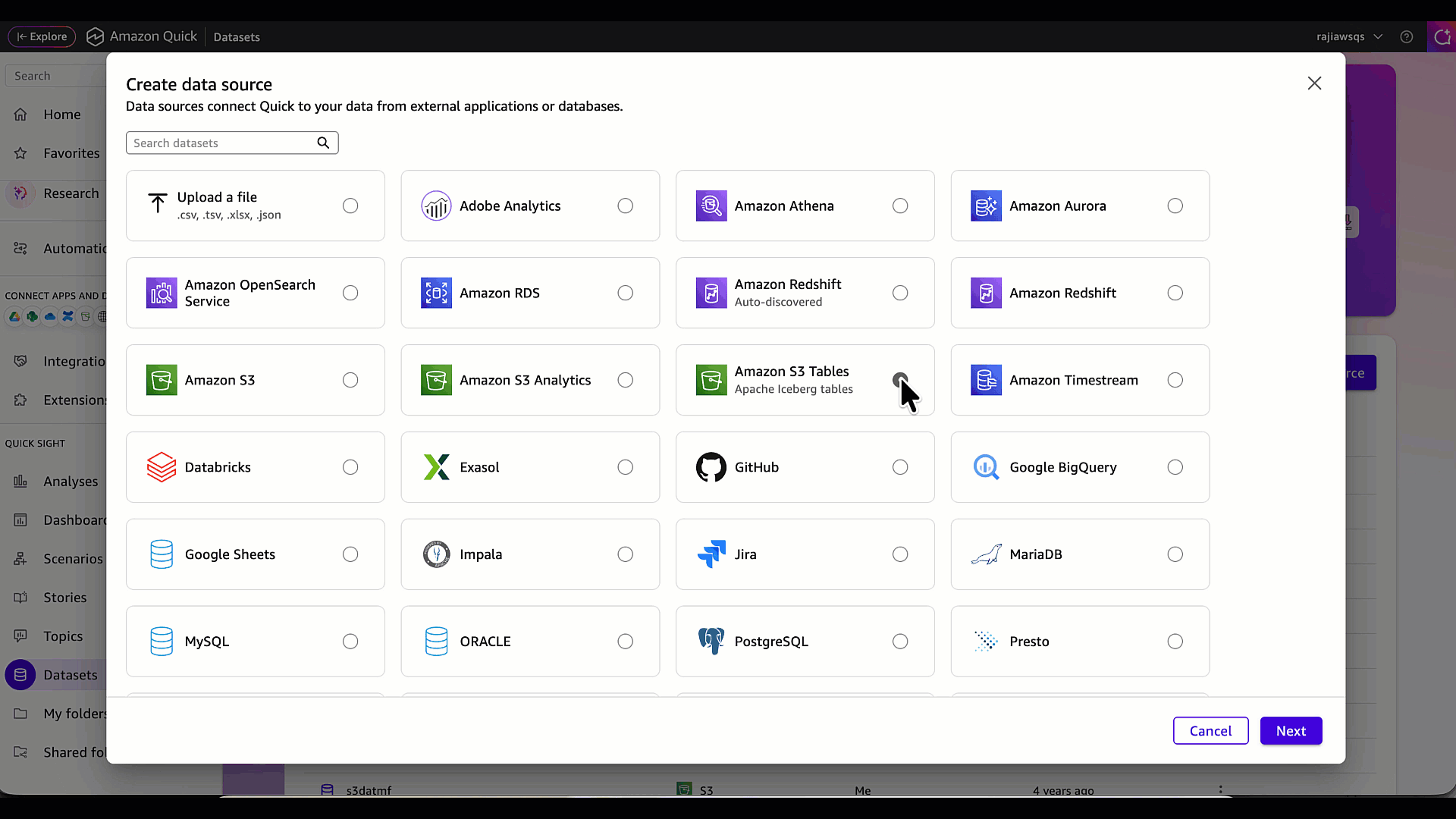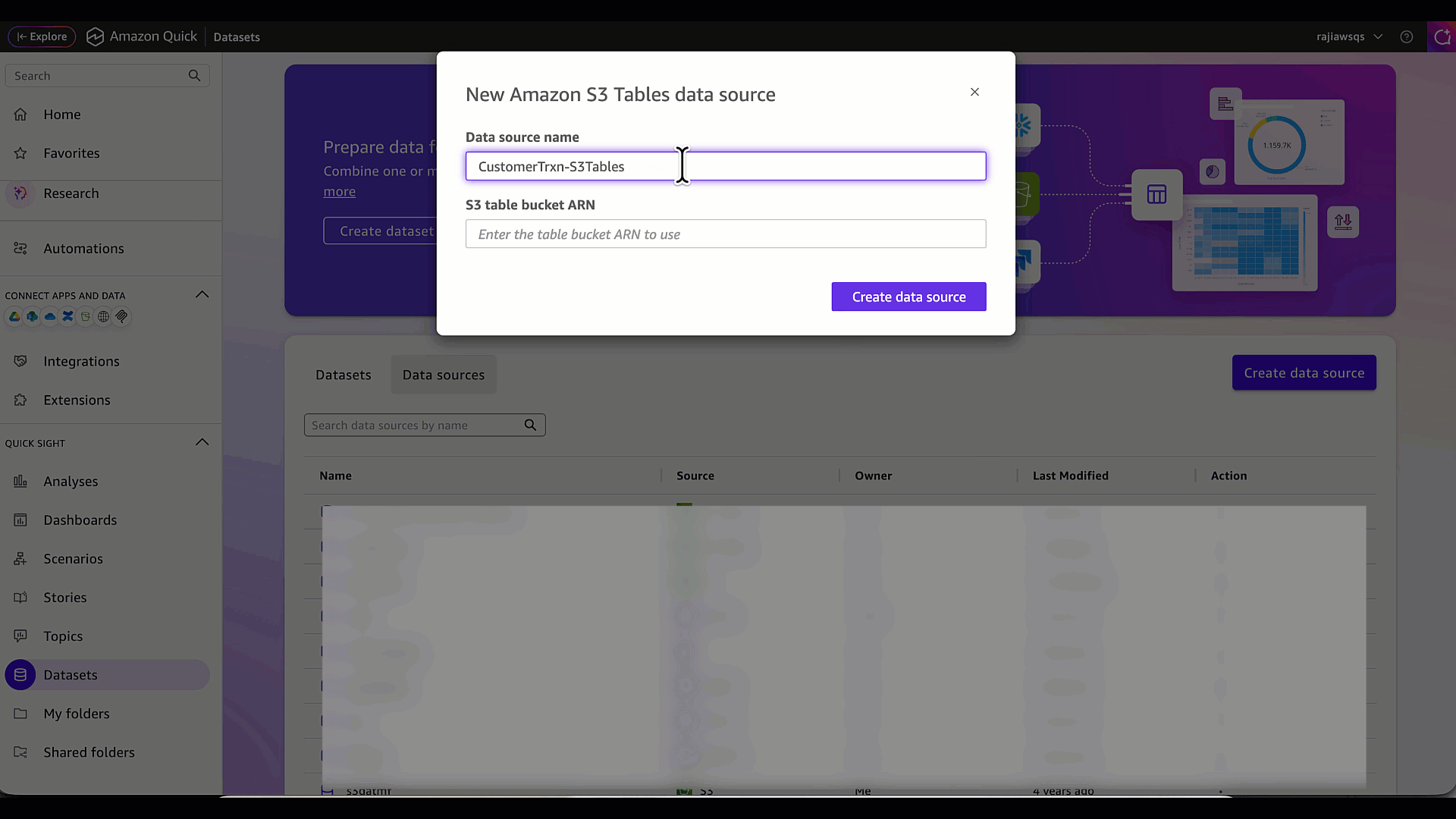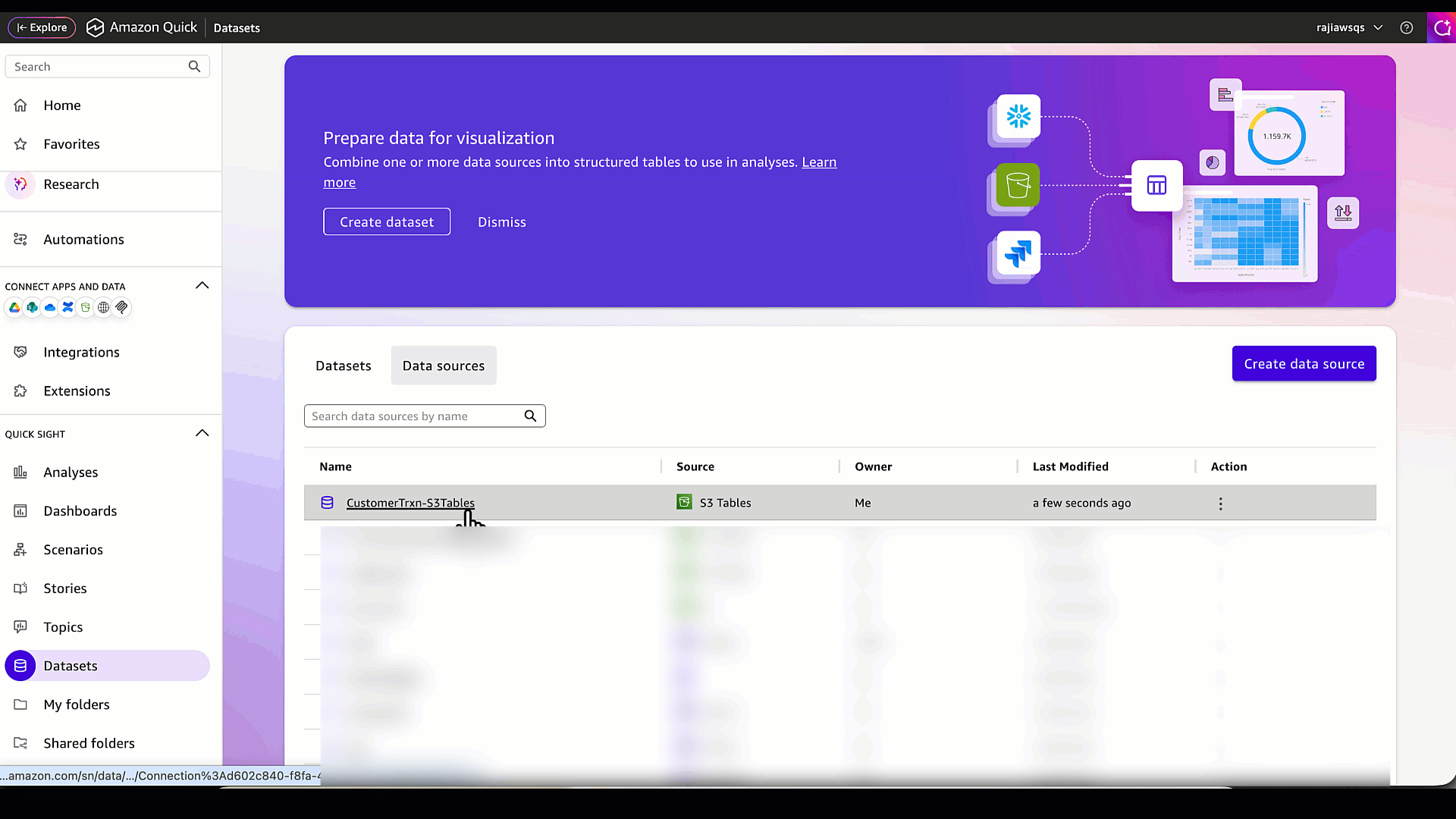
- Введите имя источника данных, например CustomerTrxn-S3Tables, и укажите ARN S3 table bucket. В этом примере это ARN bucket s3table-datasamples.
- Нажмите Create data source.
Убедитесь, что источник данных успешно создан.
Шаг 3: Соберите набор данных в Amazon Quick
На этом шаге мы используем ранее созданный источник данных для сборки набора данных.
- Выберите источник данных (CustomerTrxn-S3Tables), созданный на предыдущем шаге, и нажмите Create dataset.
- Выберите namespace, который автоматически подставляется для вашего источника данных, затем выберите таблицу из списка и нажмите Edit/Preview data.В этом примере namespace s3table-data содержит две таблицы. Мы начнем с таблицы измерения customer.
- На вкладке Preview просмотрите данные, загруженные из S3 Tables.
- Чтобы добавить еще одну таблицу, выберите Add data в меню. В этом примере мы добавим таблицу
transaction_events. - На экране Add data выберите Data source в раскрывающемся списке.
- Выберите
CustomerTrxn-S3Tablesиз списка Select a data source, затем нажмите Select. - Из списка таблиц выберите
transaction_eventsи нажмите Select.
- Свяжите две таблицы, нажав значок плюса (+) рядом с таблицей customer_master и выбрав Join.
- Настройте join с использованием столбца customer_id:
- Выберите вариант Inner Join.
- В качестве правой таблицы выберите transaction_events.
- Выберите customer_id в качестве ключа соединения в левой и правой таблицах.
- Задайте имя для join, например TrxnJoin, чтобы было проще различать его при работе с несколькими таблицами.
- Назовите набор данных в левом верхнем углу, например CxTrxn_S3TableData.
- Убедитесь, что в правом верхнем углу выбран режим Direct Query mode. Это важно, чтобы полностью использовать near real-time доступ к данным из S3 Tables. При желании можно выбрать режим SPICE mode, если вам больше подходят плановые обновления данных, а не near real-time доступ.
- Нажмите Save & Publish.
Шаг 4: Взаимодействуйте с набором данных через чат Amazon Quick
Теперь начнем общаться с этим набором данных, чтобы получать инсайты на естественном языке. Для этого мы используем чат по умолчанию с именем “My Assistant”.
- На домашней странице Amazon Quick выберите Chat agents в левом меню, а затем My Assistant.
- Нажмите Chat рядом с My Assistant.
- В разделе All data and apps нажмите Add и выберите Datasets. Затем выберите набор данных CxTrxn_S3TableData. Нажмите Save.
- В панели чата введите: Show the total number of transactions occurred so far in this month и нажмите Send.
- Обратите внимание на ответ чата, в котором показано общее число транзакций за текущий месяц. Затем попросим агента разбить показатель по дням.
- В панели чата введите: break it down by day using ingestion timestamp и нажмите Send.
- Просмотрите дневную разбивку, которую предоставил агент. В нашем примере — с 1 апреля по 17 апреля.

Шаг 5: Покажите взаимодействие пользователя с потоковыми данными в реальном времени
Далее мы проверим near real-time отзывчивость чата, передав новые транзакционные данные потоком. В этой демонстрации мы используем AWS Lambda как producer для Kinesis Data Stream, а затем сохраняем входящие данные в S3 table bucket как S3 Tables — в формате Apache Iceberg — через Firehose. По мере поступления новых данных количество транзакций будет автоматически обновляться в чате без каких-либо действий со стороны конечного пользователя. Это демонстрирует бесшовный near real-time доступ к данным без ручного вмешательства и сложной архитектуры. Мы несколько раз запускаем эту Lambda-функцию, чтобы передать новые события транзакций.
Если вы хотите самостоятельно создать источник потоковых данных для этой демонстрации, обратитесь к официальной документации AWS или соответствующим публикациям AWS, где есть подробные инструкции.
Теперь проверим недавно переданные данные в нашем чат-агенте.
- Вернитесь к My Assistant в той же чат-сессии, введите новый запрос: “Show the total number of transactions occurred so far in this month, include all recent streaming data and break it down by ingestion timestamp.” и нажмите Send.
- My Assistant выполняет запрос к набору данных CxTrxn_S3TableData через Direct Query и возвращает недавно загруженные записи за 18 апреля. Это показывает, что недавно переданные потоковые данные доступны без ручного обновления набора данных.

Очистка ресурсов
Если вам больше не нужны ресурсы, развернутые в рамках этого решения, и вы хотите избежать дальнейших затрат, рекомендуем очистить среду и удалить соответствующие компоненты, удалив все ресурсы, связанные с Amazon Quick, а также отказавшись от подписки на учетную запись Amazon Quick.
Заключение
В этой статье мы рассмотрели, как новый источник данных Amazon Quick для Amazon S3 Tables обеспечивает near real-time аналитику и одновременно упрощает современные архитектуры данных. За счет прямого запроса таблиц Apache Iceberg в Amazon S3 он убирает промежуточные слои, сокращает перемещение данных и сохраняет единый управляемый источник истины. Кроме того, можно использовать чат на естественном языке, например My Assistant, чтобы получать актуальные инсайты без ручного обновления и технических накладных расходов.
В результате получается единый AI-powered аналитический опыт, в котором данные, инсайты и действия объединяются бесшовно в near real-time. Организации могут работать быстрее, принимать более качественные решения и раскрывать полную ценность своих данных, сохраняя при этом архитектуру более простой, масштабируемой и экономичной. Если ваш сценарий — типичная аналитическая задача с плановыми обновлениями данных и не требует near real-time доступа, режим SPICE mode остается подходящим вариантом. Подробнее о функции см. Создание набора данных с использованием Amazon S3 Tables.
Для дополнительных обсуждений и помощи с ответами на вопросы посетите сообщество Amazon Quick.
Материал — перевод статьи с английского.
Оригинал: From data lake to AI-ready analytics: Introducing new data source with S3 Tables in Amazon Quick