AWS представила мультимодальные MLLM-оценщики для image-to-text задач в Strands Evals

Если вы строите визуальные сценарии покупок, системы понимания изображений или документов, а также анализ графиков, вам нужен способ проверить, действительно ли ответ модели опирается на исходное изображение. Текстовый evaluator не может понять, точно ли подпись описывает картинку, совпадает ли извлеченная сумма по счету с документом или не придумал ли экранный summary кнопку, которой на странице не было. Gartner прогнозирует, что к 2030 году 80% корпоративного ПО станет мультимодальным — против менее чем 10% в 2024 году. Без автоматизированной мультимодальной оценки вам придется выбирать между дорогой ручной проверкой и ненадежными текстовыми прокси.
Сегодня мы объявляем о четырех новых оценщиках на основе multimodal large language model (MLLM)-as-a-Judge для image-to-text задач в Strands Evals software development kit (SDK): Overall Quality, Correctness, Faithfulness и Instruction Following. Каждый evaluator оценивает image-to-text-вывод относительно исходного изображения. Он отправляет изображение напрямую в мультимодальный judge-модель вместе с запросом, ответом и, при наличии, эталонным ответом. Judge возвращает счет, основанный на изображении, а также строку с рассуждением, которую можно использовать для отладки. Эти evaluators можно использовать как прямую замену текстовым judges в существующем рабочем процессе Strands Evals Case → Experiment → Report и подключать их к непрерывной интеграции (CI), чтобы автоматически ловить визуальные галлюцинации, фактические ошибки и нарушения инструкций.
В этой статье вы узнаете, как:
- настроить четыре мультимодальных evaluator и запускать их на image-to-text задаче;
- переключаться между reference-based и reference-free оценкой с одним и тем же evaluator;
- писать собственную мультимодальную рубрику для доменных критериев;
- выбирать judge-модель в Amazon Bedrock, балансируя точность, стоимость и задержку;
- применять приемы промпт-дизайна, которые улучшили совпадение оценок judge и человека в наших экспериментах.
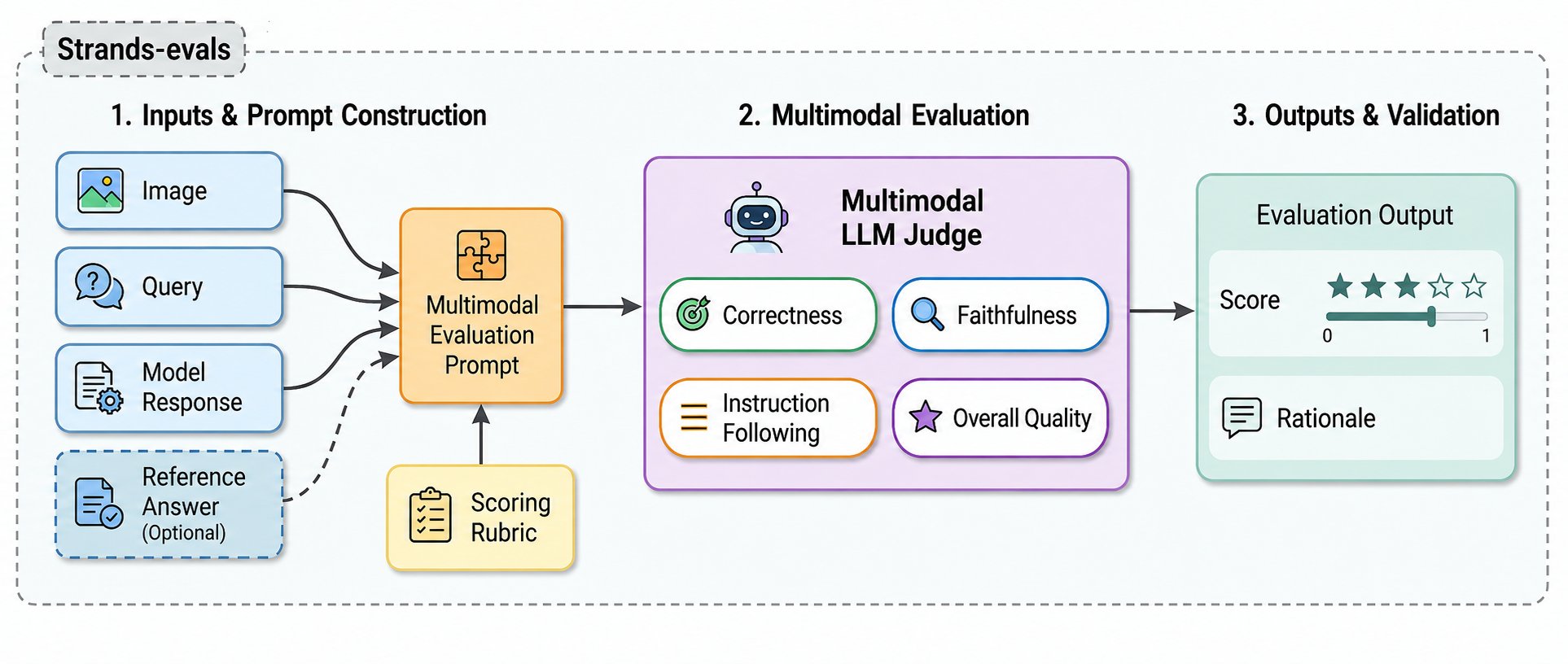
Рисунок 1: Обзор фреймворка мультимодального judge. При наличии изображения (или изображения документа), текстового запроса и сгенерированного моделью ответа фреймворк строит prompt для мультимодальной оценки, применяет MLLM-based judge и возвращает score (Likert 1–5 или бинарный) вместе с объяснением. Фреймворк поддерживает как reference-based, так и reference-free оценку и интегрируется с Strands Evals для управления кейсами и отчетности.
Требования
Чтобы следовать этому разбору, вам потребуется:
- Python 3.10 или новее, установленный в окружении.
- Установить
strands-agents-evalsдля evaluator’ов, а такжеstrands-agentsдля целевого агента, используемого в примере. - Аккаунт AWS с доступом к Amazon Bedrock.
- Локально настроенные AWS credentials, например через
aws configureили роль AWS Identity and Access Management (AWS IAM), с разрешением Amazon BedrockInvokeModelдля judge-модели. - Знакомство с рабочим процессом Strands Evals
Case→Experiment→Report. Если вы раньше не работали со Strands Evals, посмотрите launch blog post для быстрого обзора.
Почему текстовые judges пропускают image-grounded сбои
Представьте, что вы уже выпустили модель, которая читает счета, суммирует дашборды или озвучивает скриншоты. Прогон текста через text-only LLM-as-a-Judge дает вам какой-то сигнал — текст звучит гладко, структура аккуратная, — но он пропускает именно те сбои, которые важны:
- модель уверенно называет тренд на графике, которого на самом деле там нет;
- она галлюцинирует продукт, метку или человека, которых нет на изображении;
- она отвечает не на тот вопрос или отвечает на правильный вопрос в неверном формате.
Текстовый judge читает вывод и одобряет его, не проверяя изображение. Истина находится в изображении, а judge ее никогда не видит.
Даже если вы получаете низкий балл от holistic judge, который просто просит «оценить общее качество», сам счет не объясняет, что именно сломалось. Ошибка может быть фактической, придуманной деталью или игнорированием инструкции. Эти три типа сбоев требуют трех разных исправлений, поэтому сведение их к одному баллу только усложняет отладку.
Четыре evaluator’а для image-to-text задач
Четыре evaluator’а нацелены на самую распространенную мультимодальную категорию. Вход — изображение (или документ-изображение) вместе с текстом, выход — текст. Эта категория включает генерацию подписей к изображениям, visual question answering, интерпретацию графиков и инфографики, извлечение полей из документов, OCR и суммаризацию скриншотов. Таблица ниже показывает, какие сбои ловит каждый из четырех новых evaluator’ов.
| Evaluator | Score | Основной вопрос | Что он ловит | |
| 1 | Overall Quality | Likert 1–5 | Насколько хорош ответ в целом? | Плохая релевантность, неточность, поверхностные ответы, недостаточная полнота |
| 2 | Correctness | Binary | Фактически ли ответ верен и полон с учетом изображения и запроса? | Фактические ошибки, неверные атрибуты, счета, позиции, пропуски |
| 3 | Faithfulness | Binary | Опирается ли ответ на изображение без галлюцинаций? | Придуманные объекты, неподтвержденные выводы, утечка внешних знаний |
| 4 | Instruction Following | Binary | Соблюдает ли ответ ограничения запроса? | Нарушение формата, неверные счетчики, оффтопик, игнорирование рамок задачи |
Каждый evaluator поддерживает два режима. Reference-based режим сравнивает ответ с эталонным и полезен, когда у вас есть размеченные тестовые наборы. Reference-free режим оценивает только по изображению и является единственным вариантом, когда система работает с живыми изображениями без доступной истины.
Пошаговый разбор: оценка задачи чтения графика
Чтобы сделать API конкретным, вы пройдете один Case. Вход — столбчатый график средней выручки на одного платящего стримингового подписчика по регионам (U.S./Canada, EMEA, Asia Pacific, Latin America). Система под тестом — простой vision agent, который отвечает на узкий вопрос по графику. Затем вы запускаете четыре мультимодальных evaluator’а в одном и том же Experiment. У них общий базовый класс MultimodalOutputEvaluator, а изображения передаются через ImageData.
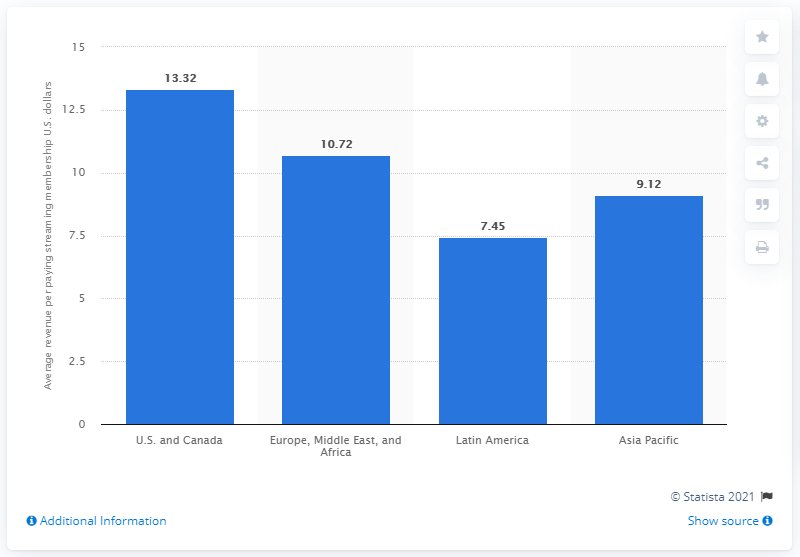
Рисунок 2: Средняя выручка на одного платящего стримингового подписчика по регионам (Statista). Системе под тестом задан grounded-вопрос по этому графику.
Шаг 1. Определите Case и evaluator’ы. Case помещает изображение и инструкцию в MultimodalInput, а наличие expected_output включает reference-based judging для evaluator’ов, которые это поддерживают.
from strands import Agent
from strands_evals import Case, Experiment
from strands_evals.evaluators import (
MultimodalOverallQualityEvaluator,
MultimodalCorrectnessEvaluator,
MultimodalFaithfulnessEvaluator,
MultimodalInstructionFollowingEvaluator,
)
from strands_evals.types import ImageData, MultimodalInput
cases = [
Case[MultimodalInput, str](
name="revenue-chart-1",
input=MultimodalInput(
media=ImageData(source="revenue_chart.jpeg"),
instruction="Which region has the highest average revenue? "
"State the region name and the dollar amount shown in the chart.",
),
expected_output="U.S. and Canada has the highest at $13.32.",
metadata={"dataset": "ChartQA"},
),
]
evaluators = [
MultimodalOverallQualityEvaluator(), # Likert 1-5
MultimodalCorrectnessEvaluator(), # Binary
MultimodalFaithfulnessEvaluator(), # Binary
MultimodalInstructionFollowingEvaluator(), # Binary
]
Шаг 2. Подключите задачу и запустите эксперимент. Функция task получает каждый Case, запускает vision model на изображении плюс инструкции и возвращает строку ответа, которую нужно оценить.
agent = Agent(callback_handler=None)
task_output = None
def run_task(case):
global task_output
image = case.input.media
messages = [
{"image": {"format": image.format or "png", "source": {"bytes": image.to_bytes()}}},
{"text": case.input.instruction},
]
task_output = str(agent(messages))
return task_output
reports = await Experiment(cases=cases, evaluators=evaluators).run_evaluations_async(
task=run_task, max_workers=1,
)
Поскольку каждый Case выше содержит MultimodalInput с медиа, четыре evaluator’а включают изображение в judge prompt. Чтобы проверить, действительно ли модальность изображения дает вклад на ваших данных, замените MultimodalInput на обычную строку (например, текстовое описание изображения) и запустите снова. Тот же evaluator будет оценивать только по тексту.
Шаг 3. Изучите Report. Каждый Report содержит per-case scores, test_passes и reasons:
print(f"Task Output:\n{task_output}\n")
print("=" * 50)
for name, report in zip(
["Quality", "Correctness", "Faithfulness", "Instruction"], reports,
):
reason = report.reasons[0] if report.reasons else ""
status = "PASS" if report.test_passes[0] else "FAIL"
print(f"{name}: {report.scores[0]:.2f} [{status}]")
print(f" Reason: {reason}\n")
Запуск на графике выше дает следующий transcript:
Task Output:
According to the chart, the U.S. and Canada region has the highest average
revenue per paying streaming membership at $13.32.
==================================================
Quality: 1.00 [PASS]
Reason: The response correctly identifies U.S. and Canada as the highest
revenue region at $13.32, directly addressing both parts of the instruction.
The answer is factually accurate based on the chart data and provides
appropriate context.
Correctness: 1.00 [PASS]
Reason: The factual claims are accurate. U.S. and Canada is correctly
identified as the region with the highest bar in the chart, and $13.32 is
the exact dollar amount visible on that bar. No factual errors found.
Faithfulness: 1.00 [PASS]
Reason: The response is fully grounded in the image. Each claim can be
directly verified against the chart. U.S. and Canada shows $13.32 and is
visibly the highest bar. No hallucinations detected.
Instruction: 1.00 [PASS]
Reason: Response perfectly follows instruction by stating both required
elements: region name (U.S. and Canada) and dollar amount ($13.32). Matches
expected output factually with no constraint violations.
Здесь важно две вещи. Во-первых, каждый evaluator возвращает строку reason дополнительно к score, и это критично для отладки. Если прогон падает в CI, вы видите почему без повторного запуска. Во-вторых, один и тот же Case был оценен четырьмя независимыми judges — одним Likert и тремя binary — в одном Experiment, поэтому ваш workflow остается тем же, что и при одиночном evaluator в текстовом Strands Evals.
Собственные рубрики. Для доменных критериев базовый класс принимает произвольную строку rubric:
from strands_evals.evaluators import MultimodalOutputEvaluator
medical_eval = MultimodalOutputEvaluator(rubric="""Rate diagnostic accuracy:
- 1.0: All findings correctly identified with proper terminology.
- 0.5: Key findings identified but imprecise terminology.
- 0.0: Critical findings missed or misidentified.""")
Что мы узнали: три вопроса дизайна
Q1. Нужно ли judge видеть изображение?
Естественный вопрос: может ли text-only LLM judge, если вместо изображения дать ему подробное автоматически сгенерированное описание картинки, заменить мультимодальный judge? Мы сравнили MLLM-as-a-Judge (изображение плюс текст) с LLM-as-a-Judge, которому в тот же prompt подавались длинные и короткие описания изображения.
Вывод: мультимодальный judge лучше совпадал с оценками людей, чем любой из текстовых вариантов. А если учесть дополнительный вызов LLM для генерации описания изображения, текстовый путь не становится заметно дешевле или быстрее. Если у вас есть доступ к мультимодальному judge, используйте его напрямую.
Q2. Какую модель в Amazon Bedrock использовать в роли judge?
Мы протестировали несколько MLLM, доступных в Amazon Bedrock, как judges и использовали совпадение с человеческими оценками, стоимость на запрос и задержку, чтобы выбрать стандартный вариант. Anthropic Claude Sonnet 4.6 в Amazon Bedrock показал лучшее соотношение точности и стоимости в наших прогонах, и мы используем его как модель judge по умолчанию для мультимодальных evaluator’ов. Два более общих наблюдения также стабильно подтверждались на всех моделях, которые мы пробовали. Во-первых, более крупные reasoning-capable модели были надежнее в роли judges, чем меньшие. Во-вторых, среди моделей этого класса более дорогие premium-варианты не давали измеримого прироста точности по сравнению с моделями среднего уровня для этой задачи.
Рекомендуемый вариант по умолчанию: Anthropic Claude Sonnet 4.6.
Q3. Какие решения в prompt-дизайне действительно важны?
Мы отключали по очереди несколько осей prompt-дизайна относительно нашего финального рекомендованного prompt. Выводы, которые обобщились на все прогоны:
- Просите judge сначала рассуждать, а потом ставить score. Это было самым сильным по эффекту решением в наших измерениях. Вывод только со score дешевле и самосогласованнее, но согласованность с человеческими оценками заметно падает. Если запомнить только одну вещь, то это она.
- Добавьте несколько разнообразных calibration examples. Совпадение оценок последовательно улучшалось по мере перехода от zero-shot к нескольким примерам.
- Используйте детальную многоаспектную рубрику — например, visual accuracy, instruction adherence, completeness, coherence — вместо одного общего prompt. Разделение аспектов не дает одному расплывчатому score поглотить разные виды ошибок.
Бонус: reference-based против reference-free
Добавление эталонного ответа в prompt judge помогает evaluator’ам, ориентированным на содержимое. Overall Quality, Correctness и Faithfulness лучше совпадали с человеческой оценкой, когда reference был доступен. Для Instruction Following эффект был обратным. Добавление reference отвлекало judge от проверки структурных ограничений — формата, объема, порядка, количества, — которые определяются только запросом и ответом.
Общее правило: используйте reference для метрик, завязанных на содержании, и не используйте его для структурных метрик вроде instruction following.
Лучшие практики
На основе наших экспериментов и интеграционной работы мы рекомендуем:
- По умолчанию начинайте с
MultimodalOverallQualityEvaluatorдля быстрых sanity checks, а затем добавляйте точечные binary evaluator’ы — Correctness, Faithfulness, Instruction Following — по мере диагностики конкретных типов сбоев. - Сначала используйте Claude Sonnet 4.6 в роли judge, а к меньшим reasoning-capable MLLM в Amazon Bedrock переходите только если стоимость или задержка критичнее точности. Маленьких моделей для judgment лучше избегать.
- Сохраняйте формат вывода reason+score. Вывод только score заманчив с точки зрения стоимости, но совпадение с человеческими оценками заметно падает.
- Используйте reference для correctness, faithfulness и overall quality, если он доступен. Для instruction following reference пропускайте.
Заключение
Четыре новых evaluator’а на базе MLLM-as-a-Judge в Strands Evals переводят оценку image-to-text из дорогой ручной проверки или ненадежных текстовых прокси в автоматизированный, основанный на изображении scoring. Overall Quality, Correctness, Faithfulness и Instruction Following нацелены на разные типы сбоев, поддерживают как reference-based, так и reference-free оценку и возвращают диагностическое объяснение вместе с каждым score. На нашей отложенной validation split все четыре evaluator’а хорошо совпадали с человеческой оценкой на разных типах изображений. Это первый шаг к более широкой мультимодальной оценке в Strands Evals. В будущем планируются step-level evaluation для multimodal tool use и agent trajectories, а также дополнительные комбинации модальностей, такие как text-to-image, video-to-text и audio-to-text.
Начните оценивать свои image-to-text agents уже сегодня. Установите Strands Evals командой:
pip install strands-agents-evals
Затем изучите материалы ниже:
- Прочитайте документацию Strands Evals для полного обзора рабочего процесса
Case→Experiment→Report. - Ознакомьтесь с справочником по мультимодальным evaluator’ам для полного API, включая
MultimodalInput,ImageData, встроенные rubrics и четыре удобных подкласса. - Попробуйте пример мультимодального evaluator’а в репозитории документации Strands Agents.
- Поделитесь отзывами и запросами на новые функции в GitHub Issues.
Материал — перевод статьи с английского.
Оригинал: Multimodal evaluators: MLLM-as-a-judge for image-to-text tasks in Strands Evals