Capacity-aware inference в Amazon SageMaker AI: автоматический fallback по типам инстансов для inference endpoints

По мере того как организации масштабируют generative AI-нагрузки в production, обеспечение надежных GPU-ресурсов становится одной из самых устойчивых операционных проблем. Большим языковым моделям (LLM) и multimodal-архитектурам нужны определенные типы инстансов, и когда такой емкости нет, endpoint не может обслужить ни одного запроса.
При создании endpoint для real-time inference в Amazon SageMaker AI раньше нужно было выбрать один тип инстанса. Если на нем не хватало capacity, endpoint не доходил до состояния running. Приходилось менять конфигурацию, выбирать другой тип инстанса и повторять попытки, пока provision не удастся.
Сегодня Amazon SageMaker AI представляет capacity aware instance pool для новых и существующих inference endpoints. Вы задаете приоритетный список типов инстансов, а SageMaker AI автоматически проходит по этому списку, когда capacity ограничена при создании, во время scale-out и во время scale-in. Ваш endpoint разворачивается на доступной AI Infrastructure без ручного вмешательства. Эта возможность доступна для Single Model Endpoints, endpoints на основе Inference Component и Asynchronous Inference endpoints.
В этой статье показано, как работают instance pools и как начать использовать их при создании нового endpoint или миграции существующего.
Проблема
Когда вы разворачиваете модель в inference endpoint SageMaker AI — real-time или asynchronous — вы указываете один тип инстанса. Если у этого типа нет доступной capacity, endpoint не создается. Это ограничение проявляется на каждом этапе жизненного цикла endpoint.
Создание endpoint срывается из-за capacity. Если предпочитаемый тип инстанса недоступен, SageMaker AI возвращает ошибку Insufficient Capacity. Чтобы получить работающий endpoint, приходится вручную перебирать альтернативы, а каждая попытка отнимает значительное время до того, как станет известен результат.
Autoscaling не может увеличить флот. Когда срабатывает событие scale-out, а у вашего типа инстанса недостаточно capacity, autoscaler бесконечно повторяет попытку с тем же типом. Трафик продолжает расти, а endpoint остается того же размера.
Scale-down не учитывает приоритет. При одном типе инстанса нет понятия предпочтительного или fallback-оборудования. Каждый инстанс может быть удален без различия.
Observability агрегирована и не дает действий. Метрики Amazon CloudWatch собираются на уровне endpoint. При расследовании проблемы с latency или capacity метрики показывают, что что-то не так, но не указывают, какой именно тип инстанса является причиной.
Как это работает: instance pools на основе приоритетов
Вы определяете ранжированный список типов инстансов, называемый instance pools, в конфигурации endpoint. SageMaker AI автоматически проходит по этому списку всякий раз, когда capacity ограничена.
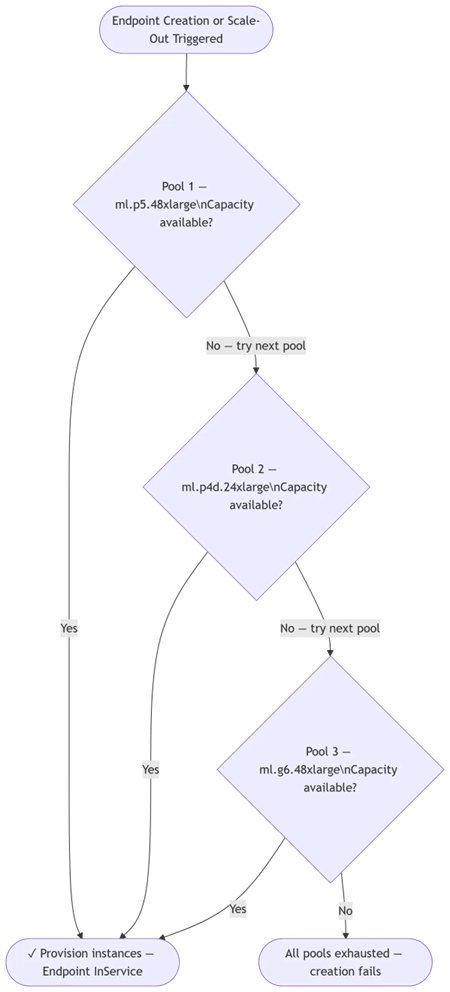
Ваши endpoints поднимаются. SageMaker AI пробует ваш первый выбор. Если capacity недоступна, он сразу пробует второй вариант, затем третий. Ручной retry не нужен. Ваш endpoint достигает InService на первом доступном AI infrastructure за несколько минут.
Ваши endpoints остаются в работе. Когда срабатывает auto scaling и предпочтительный тип инстанса ограничен по capacity, SageMaker AI масштабируется вверх на следующем доступном типе из списка приоритетов, и трафик продолжает идти.
Флот постепенно смещается к предпочитаемому оборудованию. Во время scale-in SageMaker AI сначала удаляет инстансы с самым низким приоритетом (fallback). На последующих событиях scale-out он снова в первую очередь пробует тип с самым высоким приоритетом. По мере того как предпочитаемое оборудование становится доступным, флот естественным образом со временем возвращается к нему, без ручного вмешательства.
Вы видите все. Теперь каждая существующая метрика CloudWatch включает измерение InstanceType, поэтому можно отслеживать latency, throughput, GPU utilization и количество инстансов по каждому типу внутри одного endpoint.
Подробнее см. в документации Amazon SageMaker AI и в примерном notebook на GitHub.
Подходящая модель для каждого типа инстанса
Fallback-тип инстанса часто отличается объемом GPU-памяти, вычислительными возможностями и архитектурой. Модель, оптимизированная для высокопамятного multi-GPU-инстанса, не обязательно запустится на более компактном single-GPU fallback. Есть два способа сопоставить каждый тип инстанса в вашем списке pool с правильно настроенной моделью.
Вариант 1: использовать собственные оптимизированные модели
Если целевые типы инстансов вам уже известны, подготовьте отдельные model artifacts для каждого из них. Для основного high-end-инстанса можно использовать tensor parallelism на нескольких GPU. Для fallback среднего уровня можно применить speculative decoding для ускорения inference. Для fallback с самым низким приоритетом можно использовать INT4 quantization, чтобы уложиться в меньший объем памяти.
Создайте отдельную модель SageMaker AI для каждой конфигурации и укажите ее через ModelNameOverride в каждом элементе InstancePools (для Single Model Endpoints) или в поинстансных Specifications (для endpoints на основе InferenceComponent). Когда SageMaker AI переходит на pool с более низким приоритетом, он разворачивает модель, подготовленную для этого оборудования.
Вариант 2: использовать рекомендации по inference в SageMaker AI
Если вы не хотите вручную оптимизировать каждую аппаратную цель, рекомендации по inference в SageMaker AI могут сгенерировать для вас конфигурации под конкретное оборудование. Передайте базовую модель, и SageMaker AI создаст оптимизированные конфигурации для целевых типов инстансов, используя такие техники, как speculative decoding и quantization.
Задача рекомендаций возвращает по одному результату на каждый целевой тип инстанса. Каждый результат включает ModelPackageArn и InferenceSpecificationName в ответе AIRecommendationModelDetails, указывая конфигурацию для конкретного оборудования. Вы создаете по одной модели SageMaker AI на каждый результат, используя оба поля, а затем ссылаетесь на каждую модель через ModelNameOverride в соответствующем элементе pool — тот же шаблон, что и в варианте 1, но с оптимизацией на стороне сервиса.
MODEL_PACKAGE_ARN = "arn:aws:sagemaker:us-west-2:123456789012:model-package/MyModelPkgGroup/1"
# Создайте по одной модели на каждый тип инстанса, используя оба поля из AIRecommendationModelDetails.
sm.create_model(
ModelName="my-llm-for-p5",
PrimaryContainer={
"ModelPackageName": MODEL_PACKAGE_ARN,
"InferenceSpecificationName": "p5-48xlarge-optimized",
},
ExecutionRoleArn="arn:aws:iam::123456789012:role/SageMakerRole",
)
sm.create_model(
ModelName="my-llm-for-g6",
PrimaryContainer={
"ModelPackageName": MODEL_PACKAGE_ARN,
"InferenceSpecificationName": "g6-48xlarge-optimized",
},
ExecutionRoleArn="arn:aws:iam::123456789012:role/SageMakerRole",
)
# Затем укажите каждую модель через ModelNameOverride в соответствующем элементе pool — см. раздел Setting up ниже.
Автомасштабирование на смешанном флоте
Auto scaling следует той же логике приоритетов, которую вы задаете при создании. Scale-out сначала пробует pool с самым высоким приоритетом, а если capacity недоступна, переходит к следующему pool. Scale-in сначала удаляет инстансы с самым низким приоритетом, сохраняя предпочитаемое оборудование по мере сокращения флота.
Построение взвешенной метрики масштабирования
Поскольку ваш флот содержит типы инстансов с разной пропускной способностью, стандартные агрегированные метрики могут искажать реальную загрузку. Представьте, что p5 обслуживает 18 одновременных запросов, а g6 — 7; усреднение этих значений до 12,5 не отражает реальную нагрузку ни на один из типов.
Теперь можно использовать CloudWatch metric math, чтобы построить взвешенную метрику на основе коэффициентов использования по типам. Каждый член делит наблюдаемую concurrency у типа на его максимальную capacity, давая значение от 0,0 до 1,0. Усреднение этих коэффициентов дает сигнал загрузки для всего флота в той же шкале 0,0–1,0, что и TargetValue. Если установить TargetValue равным 0.7, это означает: масштабироваться вверх, когда взвешенное среднее превышает 70 процентов capacity по всем типам инстансов во флоте.
aas = boto3.client("application-autoscaling")
aas.put_scaling_policy(
PolicyName="weighted-utilization-scaling",
ServiceNamespace="sagemaker",
ResourceId="endpoint/my-heterog-endpoint/variant/primary",
ScalableDimension="sagemaker:variant:DesiredInstanceCount",
PolicyType="TargetTrackingScaling",
TargetTrackingScalingPolicyConfiguration={
"TargetValue": 0.7, # scale out above 70% weighted fleet utilization
"CustomizedMetricSpecification": {
"Metrics": [
{
"Id": "p5_concurrency",
"MetricStat": {
"Metric": {
"Namespace": "AWS/SageMaker",
"MetricName": "ConcurrentRequestsPerModel",
"Dimensions": [
{"Name": "EndpointName", "Value": "my-heterog-endpoint"},
{"Name": "VariantName", "Value": "primary"},
{"Name": "InstanceType", "Value": "ml.p5.48xlarge"},
],
},
"Stat": "Average",
},
"ReturnData": False,
},
{
"Id": "g6_concurrency",
"MetricStat": {
"Metric": {
"Namespace": "AWS/SageMaker",
"MetricName": "ConcurrentRequestsPerModel",
"Dimensions": [
{"Name": "EndpointName", "Value": "my-heterog-endpoint"},
{"Name": "VariantName", "Value": "primary"},
{"Name": "InstanceType", "Value": "ml.g6.48xlarge"},
],
},
"Stat": "Average",
},
"ReturnData": False,
},
{
"Id": "weighted_utilization",
# Коэффициент использования по типу: наблюдаемая concurrency / max_capacity, затем усреднение
"Expression": "(p5_concurrency / 20 + g6_concurrency / 8) / 2",
"ReturnData": True,
},
],
},
},
)
В этом выражении 20 и 8 — максимальные значения concurrency, измеренные для каждого типа инстанса. В примере p5 обслуживает до 20 запросов, а g6 — до 8. Замените эти значения на максимумы, которые вы измерите для своей модели во время load testing. В таблице ниже показано, как метрика реагирует на разные уровни трафика:
| Уровень трафика | Запросы на p5 | Запросы на g6 | Взвешенная утилизация | Действие |
| Низкий | 5 | 2 | (0.25 + 0.25) / 2 = 0.25 | Scale in |
| Умеренный | 12 | 5 | (0.60 + 0.63) / 2 = 0.61 | Оставить без изменений |
| Высокий | 18 | 7 | (0.90 + 0.88) / 2 = 0.89 | Scale out |
| На целевом уровне | 14 | 6 | (0.70 + 0.75) / 2 = 0.73 | Почти целевой уровень — оставить без изменений |
Примечание: для workloads, где все типы инстансов имеют близкую пропускную способность, существующая scaling policy работает без изменений. Взвешенная метрика загрузки особенно полезна, когда участники pool заметно различаются по GPU capacity.
Мониторинг флота
Все существующие метрики CloudWatch теперь включают новое измерение InstanceType: ModelLatency, ConcurrentRequestsPerModel, GPUUtilization, InstanceCount и InvocationsPerInstance — с разбивкой по типу оборудования внутри одного endpoint. Можно строить dashboards и alarms, отслеживающие каждый тип инстанса отдельно.
DescribeEndpoint возвращает текущее количество инстансов по каждому pool, так что вы всегда знаете состав флота:
response = sm.describe_endpoint(EndpointName="my-heterog-endpoint")
pools = response["ProductionVariants"][0]["InstancePools"]
Пример вывода:
[
{"InstanceType": "ml.p5.48xlarge", "CurrentInstanceCount": 4},
{"InstanceType": "ml.g6.48xlarge", "CurrentInstanceCount": 2},
]
Маршрутизация трафика
Для endpoints с instance pools рекомендуется включать маршрутизацию Least Outstanding Requests (LOR), задав RoutingConfig в ProductionVariant. LOR направляет каждый входящий запрос на инстанс с наименьшим числом in-flight requests на копию модели. Поскольку инстансы большей емкости обрабатывают запросы быстрее, они быстрее освобождают очередь и в устойчивом состоянии сохраняют меньшее число in-flight requests. Это означает, что они естественным образом получают пропорционально больше трафика без ручной настройки весов:
"RoutingConfig": {"RoutingStrategy": "LEAST_OUTSTANDING_REQUESTS"}
Без этой настройки endpoint по умолчанию использует маршрутизацию RANDOM, которая распределяет запросы равномерно независимо от нагрузки инстанса. Это менее оптимально, когда участники pool заметно различаются по throughput capacity. Полные детали см. в RoutingConfig в справочнике API ProductionVariant.
Обновления и откаты
Поддерживаются как blue/green, так и rolling deployments.
Blue/green deployments поднимают полностью новый (green) флот, используя ту же логику fallback по приоритетам, прежде чем переключить трафик. Если health checks проходят, трафик переключается. Если они не проходят, автоматический rollback сохраняет blue-флот, а endpoint остается InService на всем протяжении.
Rolling deployments обновляют флот батчами с настраиваемым размером — от 5 до 50 процентов инстансов за раз, требуя меньше дополнительной capacity, чем полный blue/green fleet, что особенно важно для больших моделей или GPU-типов инстансов с высоким спросом. SageMaker AI применяет логику fallback по приоритетам при подготовке каждого нового батча. Если во время baking period срабатывает CloudWatch alarm, трафик автоматически откатывается. См. Use rolling deployments для деталей настройки.
Требования
Перед началом убедитесь, что у вас есть:
- Аккаунт AWS с IAM-разрешениями
sagemaker:CreateEndpointConfig,sagemaker:CreateEndpointиsagemaker:UpdateEndpoint - Как минимум одна модель SageMaker с artifacts в Amazon S3
- Boto3 версии 1.43.1 или новее (для поддержки
InstancePoolsв Python SDK) - По желанию — отдельные optimized model artifacts для каждого целевого типа инстанса или ModelPackage из SageMaker AI inference recommendations
Поддержка instance pool для inference endpoints SageMaker AI доступна во всех коммерческих регионах AWS. Начать можно через AWS Management Console, AWS Command Line Interface (AWS CLI) или AWS SDK.
Рабочий процесс настройки endpoint с instance pool
Есть два способа настроить instance pool: для нового Amazon SageMaker AI endpoint или для уже существующего Amazon SageMaker AI endpoint.
- Если вы создаете новый endpoint, схема ниже объясняет рабочий процесс:
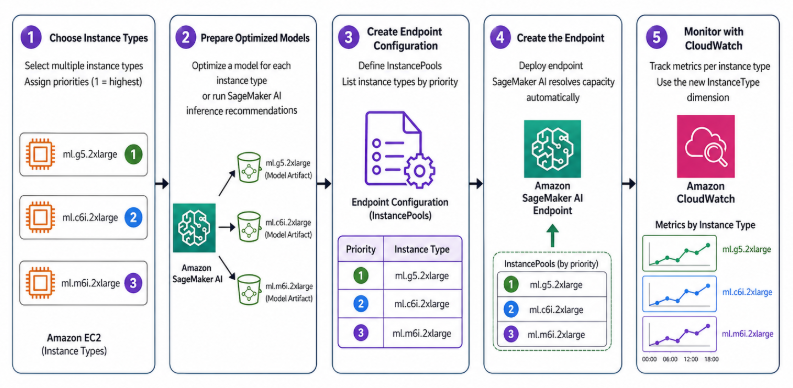
- Выберите типы инстансов и назначьте приоритеты (1 — самый высокий).
- Подготовьте оптимизированную модель для каждого типа инстанса или запустите SageMaker AI inference recommendations, чтобы получить их.
- Создайте конфигурацию endpoint с
InstancePools, в котором перечислены ваши приоритеты. - Создайте endpoint. SageMaker AI автоматически решит вопрос с capacity.
- Настройте per-type мониторинг CloudWatch с использованием нового измерения
InstanceType.
- Если вы мигрируете существующий endpoint, схема ниже объясняет рабочий процесс:
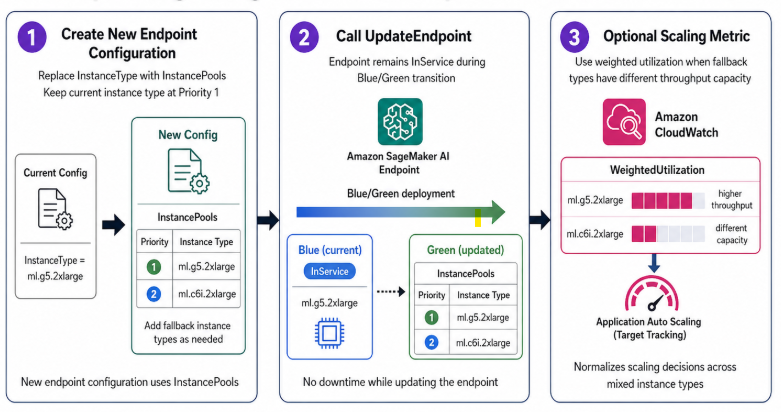
- Создайте новую конфигурацию endpoint: замените
InstanceTypeнаInstancePools, оставив текущий тип инстанса наPriority: 1. - Вызовите
UpdateEndpoint; ваш endpoint останетсяInServiceво время blue/green transition. - При необходимости добавьте взвешенную метрику утилизации, если fallback-тип инстанса заметно отличается по throughput capacity.
- Создайте новую конфигурацию endpoint: замените
Настройка
Переход на instance pools требует одного изменения в конфигурации endpoint: замените единственное поле InstanceType в ProductionVariant списком InstancePools. Модель, policies масштабирования и dashboards мониторинга продолжат работать без изменений.
Миграция существующего endpoint
До: один тип инстанса:
import boto3
sm = boto3.client("sagemaker")
sm.create_endpoint_config(
EndpointConfigName="my-config",
ProductionVariants=[{
"VariantName": "primary",
"ModelName": "my-llm",
"InitialInstanceCount": 2,
"InstanceType": "ml.g6e.48xlarge", # один тип — без fallback по capacity
}],
)
После: instance pools, упорядоченные по приоритету:
sm.create_endpoint_config(
EndpointConfigName="my-config-v2",
ProductionVariants=[{
"VariantName": "primary",
"ModelName": "my-llm",
"InitialInstanceCount": 2,
"VariantInstanceProvisionTimeoutInSeconds": 1200, # см. примечание ниже
"InstancePools": [
{"InstanceType": "ml.g6e.48xlarge", "Priority": 1}, # ваш текущий тип
{"InstanceType": "ml.g6.48xlarge", "Priority": 2}, # та же семья, первый fallback
{"InstanceType": "ml.p4d.24xlarge", "Priority": 3}, # более широкий fallback
],
}],
)
Ваш endpoint остается InService во время blue/green transition.
sm.update_endpoint(
EndpointName="my-endpoint",
EndpointConfigName="my-config-v2",
)
Примечание: VariantInstanceProvisionTimeoutInSeconds — новое поле, добавленное вместе с поддержкой instance pool. Оно задает общий временной интервал для получения инстансов из pool: SageMaker AI продолжает повторять попытки при ошибке Insufficient Capacity в пределах этого окна и переходит к следующему pool после истечения тайм-аута. Допустимый диапазон — 300–3600 секунд. 1200 секунд — разумная отправная точка для крупных GPU-инстансов. Этот таймер покрывает только procurement инстансов; загрузка модели и запуск контейнера регулируются отдельными полями ModelDataDownloadTimeoutInSeconds и ContainerStartupHealthCheckTimeoutInSeconds. Чтобы развернуть разную оптимизированную модель для каждого типа инстанса, добавьте ModelNameOverride к любому элементу pool. Варианты конфигурации моделей описаны в предыдущем разделе.
Endpoints на основе InferenceComponent
sm.create_inference_component(
InferenceComponentName="my-ic",
EndpointName="my-heterogeneous-endpoint",
VariantName="primary",
Specifications=[
{
"InstanceType": "ml.p5.48xlarge",
"ModelName": "my-model-p5-optimized",
"ComputeResourceRequirements": {
"NumberOfAcceleratorDevicesRequired": 8,
"MinMemoryRequiredInMb": 65536,
},
},
{
"InstanceType": "ml.g6.48xlarge",
"ModelName": "my-model-g6-optimized",
"ComputeResourceRequirements": {
"NumberOfAcceleratorDevicesRequired": 8,
"MinMemoryRequiredInMb": 32768,
},
},
],
RuntimeConfig={"CopyCount": 4},
)
Asynchronous Inference endpoints
Instance pools работают так же для Asynchronous Inference endpoints. Добавьте блок AsyncInferenceConfig в вызов CreateEndpointConfig вместе с определением InstancePools — логика приоритетного provisioning и fallback применяется идентично. Это особенно полезно для asynchronous workloads, которые масштабируются до нуля инстансов: когда endpoint снова масштабируется вверх, чтобы обработать очередь запросов, SageMaker AI сначала использует ваш доступный pool с наивысшим приоритетом, обеспечивая устойчивый cold start без ручного вмешательства.
Заключение
Instance Pools в Amazon SageMaker AI позволяют задавать приоритетный список типов инстансов для inference endpoints, а SageMaker AI автоматически управляет capacity в соответствии с этим порядком.
Во время создания endpoint, scale-out и scale-in SageMaker AI проходит по вашим предпочтительным типам инстансов, поэтому не нужно вручную повторять развертывание, когда первый выбранный вариант оборудования недоступен. Начать просто: замените InstanceType на InstancePools в конфигурации endpoint и вызовите UpdateEndpoint. Ваши существующие модели, policies autoscaling и dashboards мониторинга продолжат работать без серьезных изменений.
Благодаря метрикам CloudWatch по каждому типу инстанса и подробным счетчикам pool из DescribeEndpoint вы также получаете четкое отображение в реальном времени того, какие типы инстансов обеспечивают работу флота. Если вы оптимизируете стоимость, управляете ограничениями GPU capacity или строите устойчивые asynchronous pipelines, способные cold start с нуля, Instance Pools дают гибкость и автоматизацию, чтобы ML inference работал стабильно и с меньшими операционными издержками.
Эта возможность доступна уже сегодня без дополнительной платы. Вы оплачиваете фактически развернутые типы инстансов по тем же тарифам, что и обычный endpoint с одним типом. Подробнее см. в документации Amazon SageMaker AI и в примерном notebook на GitHub.
Материал — перевод статьи с английского.
Оригинал: Capacity-aware inference: Automatic instance fallback for SageMaker AI endpoints