ToolSimulator: масштабное тестирование tool-calling для AI-агентов в Strands Evals

ToolSimulator — это фреймворк для симуляции инструментов с поддержкой LLM внутри Strands Evals, который позволяет тщательно и безопасно тестировать AI-агентов, полагающихся на внешние инструменты, в масштабе. Вместо того чтобы рисковать живыми API-вызовами, которые могут раскрывать персональные данные (PII), запускать нежелательные действия или вынуждать использовать статические моки, не работающие в многошаговых сценариях, можно применять LLM-симуляции ToolSimulator для проверки поведения агентов. Инструмент доступен уже сейчас как часть Strands Evals Software Development Kit (SDK) и помогает рано находить ошибки интеграции, проверять пограничные случаи и выпускать production-ready агентов с уверенностью.
В этом материале вы узнаете, как:
|
Требования перед началом
Перед началом убедитесь, что у вас есть следующее:
- Python 3.10 или новее в вашей среде
- установленный Strands Evals SDK:
pip install strands-evals - базовое знакомство с Python, включая декораторы и аннотации типов
- понимание AI-агентов и концепций tool-calling (API-вызовы, схемы функций)
- знание Pydantic полезно для продвинутых примеров схем, но не обязательно для старта
- учетная запись AWS не требуется для локального запуска ToolSimulator
Почему тестирование инструментов усложняет процесс разработки
Современные AI-агенты не только рассуждают. Они вызывают API, обращаются к базам данных, используют сервисы Model Context Protocol (MCP) и взаимодействуют с внешними системами, чтобы выполнять задачи. Поведение вашего агента зависит не только от его рассуждений, но и от того, что возвращают эти инструменты. При тестировании таких агентов на живых API возникают три проблемы, которые замедляют разработку и подвергают системы риску.
Три проблемы, которые создают живые API:
- Внешние зависимости тормозят работу. Живые API вводят rate limits, могут быть недоступны и требуют сетевого подключения. Когда вы запускаете сотни тестов, эти ограничения делают всестороннее тестирование практически невозможным.
- Изоляция тестов становится рискованной. Реальные вызовы инструментов вызывают реальные побочные эффекты. Во время тестирования можно случайно отправить настоящие письма, изменить production-базы данных или забронировать реальные авиабилеты. Тесты агента не должны взаимодействовать с системами, против которых они проверяются.
- Конфиденциальность и безопасность создают барьеры. Многие инструменты работают с чувствительными данными, включая записи пользователей, финансовую информацию и PII. Запуск тестов на живых системах без необходимости раскрывает эти данные и создает риски несоответствия требованиям.
Почему статические моки не подходят
В качестве альтернативы можно рассмотреть статические моки. Они работают для простых, предсказуемых сценариев, но требуют постоянного сопровождения по мере развития API. И что еще важнее, они плохо справляются с многоходовыми stateful-процессами, которые выполняют реальные агенты.
Рассмотрим агента для бронирования авиабилетов. Сначала он ищет рейсы одним вызовом инструмента, затем проверяет статус бронирования другим. Второй ответ должен зависеть от того, что сделал первый вызов. Жестко заданный ответ не может отразить базу данных, состояние которой меняется между вызовами. Статические моки этого не умеют.
Чем ToolSimulator отличается
ToolSimulator решает эти задачи с помощью трех ключевых возможностей, которые вместе дают безопасное и масштабируемое тестирование агентов без потери реалистичности.
- Адаптивная генерация ответов. Результаты инструментов отражают то, что агент действительно запросил, а не фиксированный шаблон. Когда агент ищет рейсы из Сиэтла в Нью-Йорк, ToolSimulator возвращает правдоподобные варианты с реалистичными ценами и временем, а не общий заглушечный ответ.
- Поддержка stateful-процессов. Многие реальные инструменты сохраняют состояние между вызовами. Операция записи должна влиять на последующие чтения. ToolSimulator поддерживает согласованное общее состояние между вызовами инструментов, поэтому можно безопасно тестировать взаимодействие с базами данных, процессы бронирования и многошаговые сценарии, не затрагивая production-системы.
- Проверка схем. Обычно разработчики добавляют слой постобработки, который парсит сырой вывод инструмента в структурированный формат. Если инструмент возвращает некорректный ответ, этот слой ломается. ToolSimulator валидирует ответы по схемам Pydantic, которые вы задаете, и выявляет некорректные ответы до того, как они попадут к агенту.
Как работает ToolSimulator
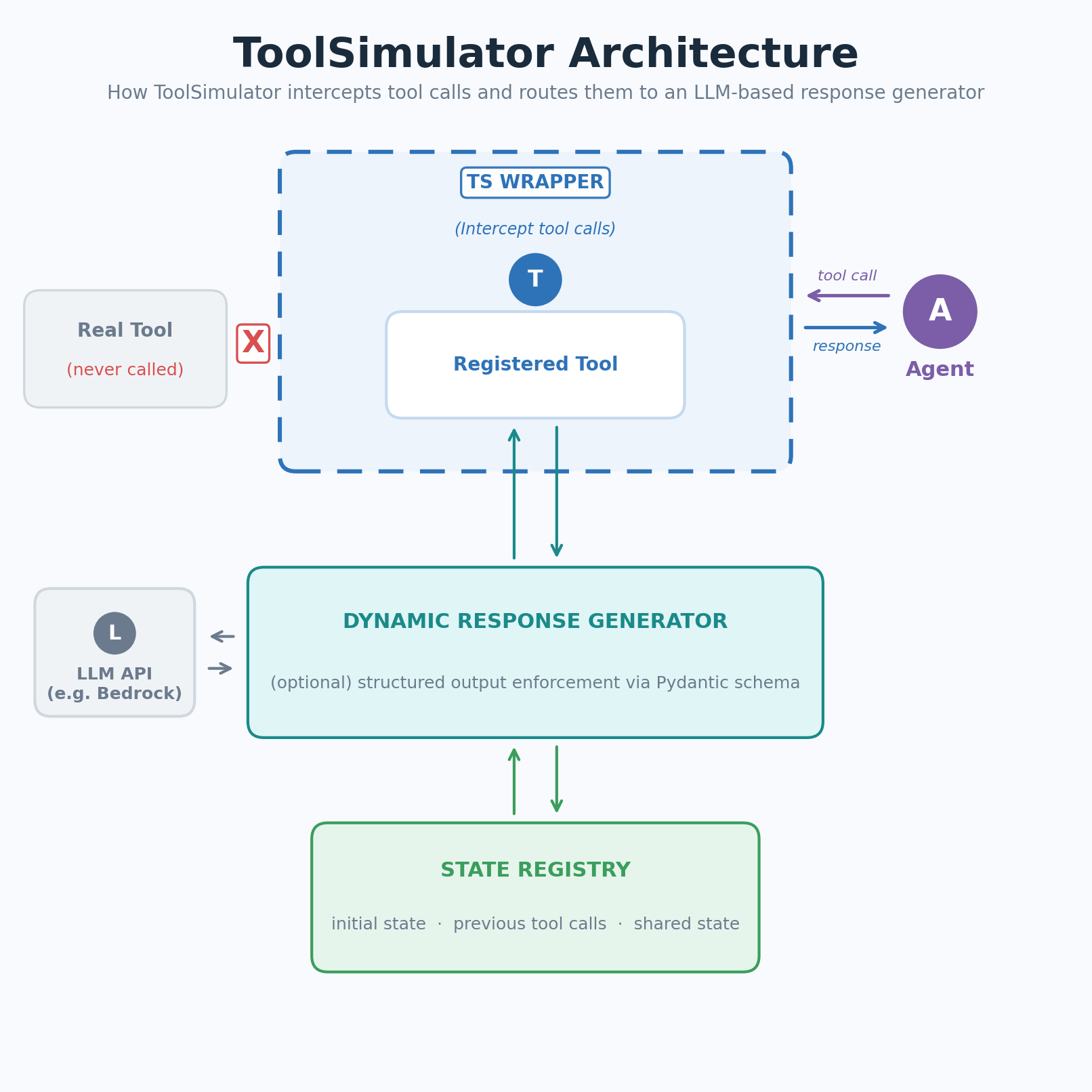
ToolSimulator перехватывает вызовы зарегистрированных инструментов и направляет их в генератор ответов на основе LLM. Генератор использует схему инструмента, входные данные вашего агента и текущее состояние симуляции, чтобы создать реалистичный и контекстно уместный ответ. Ручные fixtures не нужны.
Рабочий процесс состоит из трех шагов: пометить и зарегистрировать инструменты, при необходимости задать симуляции контекст, а затем позволить ToolSimulator подменять ответы инструментов во время работы агента.
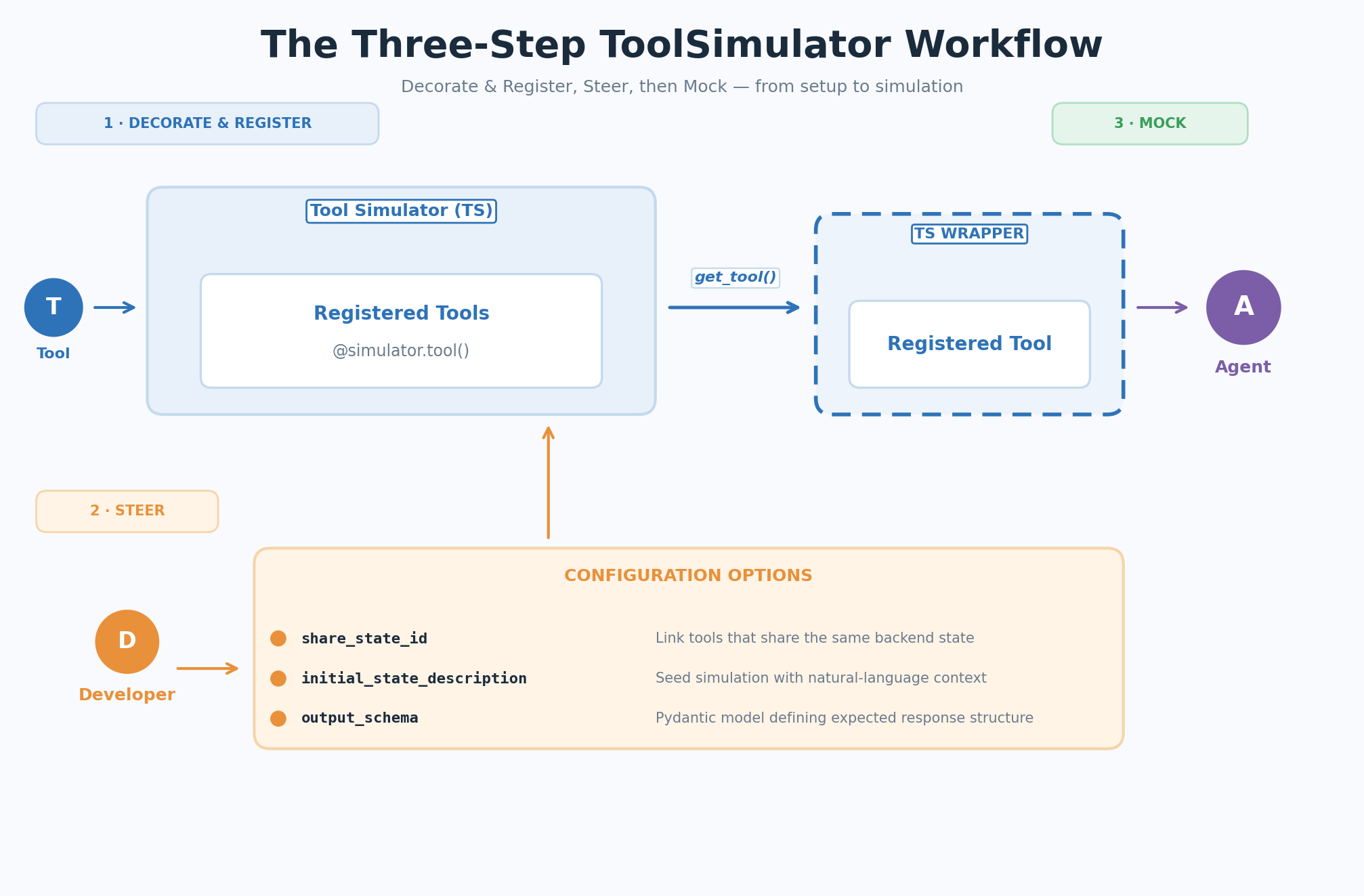
Начало работы с ToolSimulator
Следующие разделы проводят вас через каждый шаг workflow ToolSimulator — от первоначальной настройки до запуска первой симуляции.
Шаг 1: Пометить и зарегистрировать
Создайте экземпляр ToolSimulator, затем оберните функцию инструмента декоратором @simulator.tool(), чтобы зарегистрировать ее для симуляции. Реальный код функции может оставаться пустым. ToolSimulator перехватывает вызовы до того, как они попадут в реализацию:
from strands_evals.simulation.tool_simulator import ToolSimulator
tool_simulator = ToolSimulator()
@tool_simulator.tool()
def search_flights(origin: str, destination: str, date: str) -> dict:
"""Search for available flights between two airports on a given date."""
pass # Реальная реализация во время симуляции не вызывается
Шаг 2: Steer (необязательная настройка)
По умолчанию ToolSimulator автоматически выводит, как должен вести себя каждый инструмент, на основе его схемы и docstring. Для старта дополнительная настройка не требуется. Когда нужен больший контроль, можно использовать три необязательных параметра для настройки поведения симуляции:
share_state_id: связывает инструменты, которые используют один и тот же backend, под общим ключом состояния. Изменения состояния, сделанные одним инструментом, например setter-ом, сразу видны последующим вызовам другого инструмента, например getter-а.initial_state_description: задает симуляцию естественным языком, описывающим уже существующее состояние. Более богатый контекст дает более реалистичные и согласованные ответы.output_schema: модель Pydantic, определяющая ожидаемую структуру ответа. ToolSimulator генерирует ответы, строго соответствующие этой схеме.
Шаг 3: Mock
Когда агент вызывает зарегистрированный инструмент, wrapper ToolSimulator перехватывает вызов и передает его в динамический генератор ответов. Генератор валидирует параметры агента по схеме инструмента, создает ответ, соответствующий output_schema, и обновляет реестр состояния, чтобы последующие вызовы видели согласованный мир.
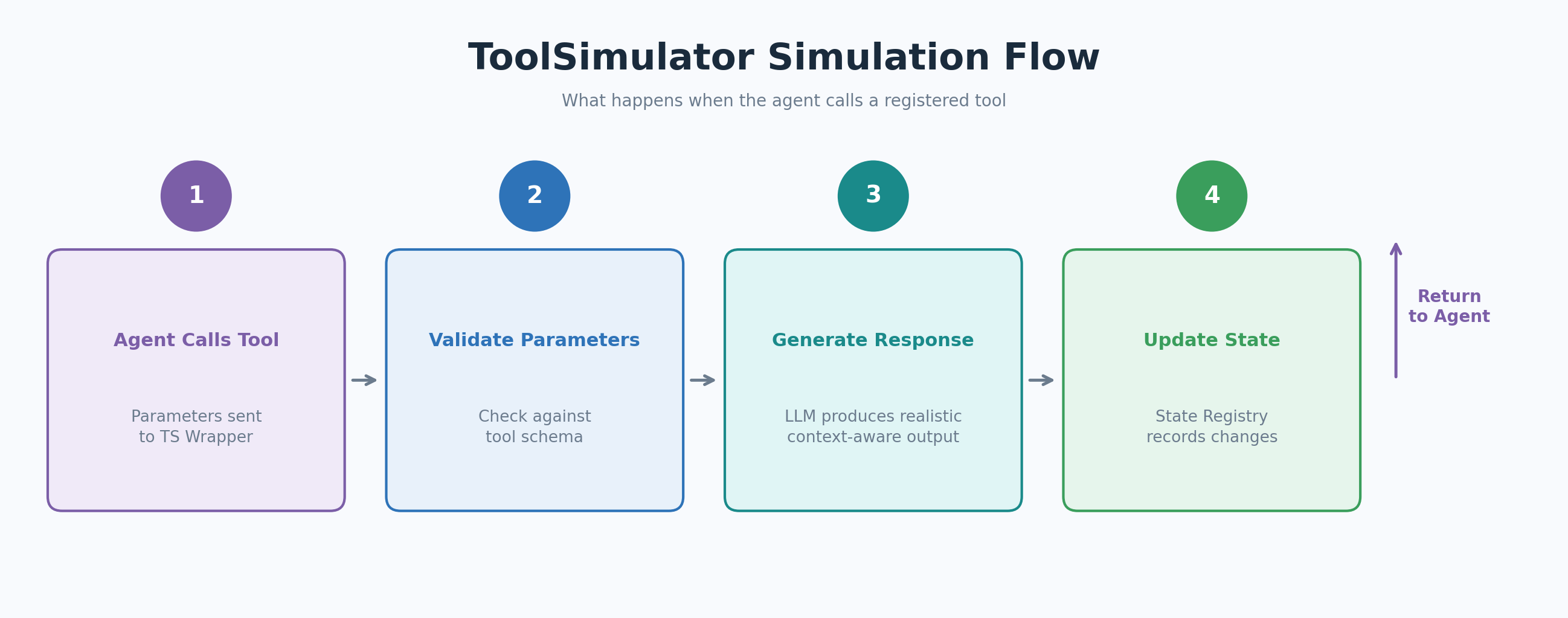
Следующий пример симулирует инструмент поиска рейсов, подключенный к ассистенту по поиску авиабилетов:
from strands import Agent
from strands_evals.simulation.tool_simulator import ToolSimulator
# 1. Создаем экземпляр симулятора
tool_simulator = ToolSimulator()
# 2. Регистрируем инструмент для симуляции с контекстом начального состояния
@tool_simulator.tool(
initial_state_description="Flight database: SEA->JFK flights available at 8am, 12pm, and 6pm. Prices range from $180 to $420.",
)
def search_flights(origin: str, destination: str, date: str) -> dict:
"""Search for available flights between two airports on a given date."""
pass
# 3. Создаем агента с симулированным инструментом и запускаем его
flight_tool = tool_simulator.get_tool("search_flights")
agent = Agent(
system_prompt="You are a flight search assistant.",
tools=[flight_tool],
)
response = agent("Find me flights from Seattle to New York on March 15.")
print(response)
# Ожидаемый вывод: Структурированный список симулированных рейсов SEA->JFK со временем
# и ценами, согласованными с переданным initial_state_description.
Продвинутое использование ToolSimulator
Следующие разделы описывают три расширенные возможности, которые дают больше контроля над симуляцией: запуск независимых экземпляров для параллельного тестирования, настройку общего состояния для многоходовых сценариев и принудительное соблюдение пользовательских схем ответов.
Запуск независимых экземпляров симулятора
Можно создавать несколько экземпляров ToolSimulator рядом друг с другом. Каждый экземпляр поддерживает собственный реестр инструментов и состояние, поэтому в одном кодовой базе можно запускать параллельные конфигурации экспериментов:
simulator_a = ToolSimulator()
simulator_b = ToolSimulator()
# У каждого экземпляра независимые реестр инструментов и состояние --
# это удобно для сравнения поведения агента в разных конфигурациях инструментов.
Настройка общего состояния для многоходовых сценариев
Для stateful-инструментов, таких как getter-ы и setter-ы в базе данных, ToolSimulator поддерживает согласованное общее состояние между вызовами инструментов. Используйте share_state_id, чтобы связать инструменты, работающие с одним backend, и initial_state_description, чтобы задать симуляции уже существующий контекст:
@tool_simulator.tool(
share_state_id="flight_booking",
initial_state_description="Flight booking system: SEA->JFK flights available at 8am, 12pm, and 6pm. No bookings currently active.",
)
def search_flights(origin: str, destination: str, date: str) -> dict:
"""Search for available flights between two airports on a given date."""
pass
@tool_simulator.tool(
share_state_id="flight_booking",
)
def get_booking_status(booking_id: str) -> dict:
"""Retrieve the current status of a flight booking by booking ID."""
pass
# Оба инструмента используют состояние "flight_booking".
# Когда вызывается search_flights, get_booking_status видит те же данные
# о доступности рейсов в последующих вызовах.
Проверяйте состояние до и после выполнения агента, чтобы убедиться, что взаимодействия с инструментами привели к ожидаемым изменениям:
initial_state = tool_simulator.get_state("flight_booking")
# ... запускаем агента ...
final_state = tool_simulator.get_state("flight_booking")
# Проверяем не только финальный результат, но и всю последовательность вызовов инструментов.
|
Совет: Заполнение состояния на основе реальных данных Поскольку |
Принудительное соблюдение пользовательской схемы ответа
По умолчанию ToolSimulator выводит структуру ответа из docstring и type hints инструмента. Для инструментов, следующих строгим спецификациям, таким как OpenAPI или MCP-схемы, определите ожидаемый ответ как модель Pydantic и передайте ее через output_schema:
from pydantic import BaseModel, Field
class FlightSearchResponse(BaseModel):
flights: list[dict] = Field( ..., description="List of available flights with flight number, departure time, and price" )
origin: str = Field(..., description="Origin airport code")
destination: str = Field(..., description="Destination airport code")
status: str = Field(default="success", description="Search operation status")
message: str = Field(default="", description="Additional status message")
@tool_simulator.tool(output_schema=FlightSearchResponse)
def search_flights(origin: str, destination: str, date: str) -> dict:
"""Search for available flights between two airports on a given date."""
pass
# ToolSimulator строго валидирует параметры и возвращает только корректные JSON-ответы,
# соответствующие схеме FlightSearchResponse.
Интеграция с evaluation-пайплайнами Strands
ToolSimulator естественно встраивается в evaluation-фреймворк Strands Evals. Следующий пример показывает полный пайплайн — от настройки симуляции до отчета об эксперименте — с использованием GoalSuccessRateEvaluator для оценки качества агента в задачах с вызовами инструментов:
from typing import Any
from pydantic import BaseModel, Field
from strands import Agent
from strands_evals import Case, Experiment
from strands_evals.evaluators import GoalSuccessRateEvaluator
from strands_evals.simulation.tool_simulator import ToolSimulator
from strands_evals.mappers import StrandsInMemorySessionMapper
from strands_evals.telemetry import StrandsEvalsTelemetry
# Настраиваем telemetry и tool simulator
telemetry = StrandsEvalsTelemetry().setup_in_memory_exporter()
memory_exporter = telemetry.in_memory_exporter
tool_simulator = ToolSimulator()
# Определяем схему ответа
class FlightSearchResponse(BaseModel):
flights: list[dict] = Field( ..., description="Available flights with number, departure time, and price" )
origin: str = Field(..., description="Origin airport code")
destination: str = Field(..., description="Destination airport code")
status: str = Field(default="success", description="Search operation status")
message: str = Field(default="", description="Additional status message")
# Регистрируем инструменты для симуляции
@tool_simulator.tool(
share_state_id="flight_booking",
initial_state_description="Flight booking system: SEA->JFK flights at 8am, 12pm, and 6pm. No bookings currently active.",
output_schema=FlightSearchResponse,
)
def search_flights(origin: str, destination: str, date: str) -> dict[str, Any]:
"""Search for available flights between two airports on a given date."""
pass
@tool_simulator.tool(share_state_id="flight_booking")
def get_booking_status(booking_id: str) -> dict[str, Any]:
"""Retrieve the current status of a flight booking by booking ID."""
pass
# Определяем задачу оценки
def user_task_function(case: Case) -> dict:
initial_state = tool_simulator.get_state("flight_booking")
print(f"[State before]: {initial_state.get('initial_state')}")
search_tool = tool_simulator.get_tool("search_flights")
status_tool = tool_simulator.get_tool("get_booking_status")
agent = Agent(
trace_attributes={ "gen_ai.conversation.id": case.session_id, "session.id": case.session_id },
system_prompt="You are a flight booking assistant.",
tools=[search_tool, status_tool],
callback_handler=None,
)
agent_response = agent(case.input)
print(f"[User]: {case.input}")
print(f"[Agent]: {agent_response}")
final_state = tool_simulator.get_state("flight_booking")
print(f"[State after]: {final_state.get('previous_calls', [])}")
finished_spans = memory_exporter.get_finished_spans()
mapper = StrandsInMemorySessionMapper()
session = mapper.map_to_session(finished_spans, session_id=case.session_id)
return {"output": str(agent_response), "trajectory": session}
# Определяем тестовые случаи, запускаем эксперимент и отображаем отчет
test_cases = [
Case( name="flight_search", input="Find me flights from Seattle to New York on March 15.", metadata={"category": "flight_booking"}, ),
]
experiment = Experiment[str, str](
cases=test_cases,
evaluators=[GoalSuccessRateEvaluator()]
)
reports = experiment.run_evaluations(user_task_function)
reports[0].run_display()
Функция задачи извлекает симулированные инструменты, создает агента, запускает взаимодействие и возвращает как результат агента, так и полную telemetry-траекторию. Траектория дает evaluators вроде GoalSuccessRateEvaluator доступ к полной последовательности вызовов инструментов и обращений к модели, а не только к финальному ответу.
Лучшие практики для симуляционного тестирования
Следующие практики помогут извлечь максимум из ToolSimulator в разработке и оценке:
- Начинайте с конфигурации по умолчанию для широкого покрытия. Добавляйте переопределения только для тех инструментальных окружений, которые нужно контролировать точно. Настройки по умолчанию рассчитаны на реалистичное поведение без дополнительной подготовки.
- Задавайте насыщенные значения
initial_state_descriptionдля stateful-инструментов. Чем больше контекста вы задаете, тем реалистичнее и согласованнее будут симулированные ответы. Указывайте диапазоны данных, количество сущностей и контекст связей. - Используйте
share_state_idдля инструментов, работающих с одним backend, чтобы операции записи были видны последующим чтениям. Это критично для тестирования многоходовых сценариев вроде бронирования, управления корзиной или обновления баз данных. - Применяйте
output_schemaдля инструментов, следующих строгим спецификациям, таким как OpenAPI или MCP-схемы. Проверка схем ловит некорректные ответы до того, как они попадут к агенту и сломают слой постобработки. - Проверяйте последовательности взаимодействий с инструментами, а не только финальные ответы. Анализируйте изменения состояния до и после выполнения агента, чтобы подтвердить, что вызовы происходили в правильном порядке и приводили к нужным переходам состояния.
- Начинайте с малого и расширяйте покрытие. Сначала берите самые частые сценарии взаимодействия с инструментами, затем добавляйте edge cases по мере взросления практики оценки. Симуляционное тестирование дополняйте точечными живыми API-тестами для критичных production-путей.
Заключение
ToolSimulator меняет подход к тестированию AI-агентов, заменяя рискованные живые API-вызовы интеллектуальными адаптивными симуляциями. Теперь можно безопасно проверять сложные stateful-workflow в масштабе, раньше находить ошибки интеграции и выпускать production-ready агентов с уверенностью. Сочетание ToolSimulator с evaluation-пайплайнами Strands Evals дает полную видимость поведения агента без необходимости управлять тестовой инфраструктурой или рисковать реальными побочными эффектами.
Следующие шаги
Начните безопасно тестировать своих AI-агентов уже сегодня. Установите ToolSimulator следующей командой:
pip install strands-evals
Чтобы продолжить изучение ToolSimulator и Strands Evals, выполните следующие шаги:
- прочитайте документацию Strands Evals, чтобы изучить все параметры настройки, включая продвинутое управление состоянием и пользовательские evaluators
- попробуйте пример, чтобы увидеть ToolSimulator в действии. Расширьте пример, добавив больше инструментов и протестировав многошаговые сценарии агента
- изучите Amazon Bedrock для выбора LLM-backend, который обеспечивает генерацию ответов ToolSimulator
- узнайте об AWS Lambda для серверless-стратегий развертывания агентов, которые хорошо сочетаются с тестированием на основе ToolSimulator
- присоединяйтесь к форумам сообщества Strands, чтобы задавать вопросы, делиться настройками оценки и общаться с другими разработчиками агентов
| Поделитесь обратной связью. Нам было бы интересно узнать, как вы используете ToolSimulator. Делитесь отзывами, сообщайте о проблемах и предлагайте функции через GitHub-репозиторий Strands Evals или форумы сообщества. |
Материал — перевод статьи с английского.
Оригинал: ToolSimulator: scalable tool testing for AI agents