Мультиязычная аудиотранскрипция на масштабах с Parakeet-TDT и AWS Batch
Многие организации архивируют крупные медиатеки, анализируют записи контакт-центров, готовят обучающие данные для AI или обрабатывают видео по запросу для субтитров. Когда объем данных заметно растет, стоимость управляемых сервисов автоматического распознавания речи (ASR) может быстро стать главным ограничением масштабирования.
Чтобы решить эту задачу по стоимости и масштабируемости, мы используем модель NVIDIA Parakeet-TDT-0.6B-v3, развернутую через AWS Batch на инстансах с GPU. Архитектура Token-and-Duration Transducer в Parakeet-TDT одновременно предсказывает текстовые токены и их длительность, чтобы интеллектуально пропускать тишину и избыточную обработку. Это помогает добиться скорости инференса, на порядки превышающей реальное время. Платя только за короткие всплески вычислений, а не за всю длительность аудио, можно транскрибировать данные в масштабе за доли цента за час аудио на основе бенчмарков, описанных в этом материале.
В этом посте мы показываем, как построить масштабируемый событийно-ориентированный конвейер транскрибации, который автоматически обрабатывает аудиофайлы, загруженные в Amazon Simple Storage Service (Amazon S3), а также как использовать Amazon EC2 Spot Instances и buffered streaming inference, чтобы еще сильнее снизить затраты.
Возможности модели
Parakeet-TDT-0.6B-v3, выпущенная в августе 2025 года, — это мультиязычная ASR-модель с открытым исходным кодом, которая обеспечивает высокую точность на 25 европейских языках, автоматическое определение языка и гибкую лицензию CC-BY-4.0. Согласно публичным метрикам NVIDIA, модель сохраняет word error rate (WER) на уровне 6,34% в чистых условиях и 11,66% WER при 0 dB SNR, а также поддерживает аудио длительностью до трех часов в режиме local attention.
В список 25 поддерживаемых языков входят болгарский, хорватский, чешский, датский, нидерландский, английский, эстонский, финский, французский, немецкий, греческий, венгерский, итальянский, латышский, литовский, мальтийский, польский, португальский, румынский, словацкий, словенский, испанский, шведский, русский и украинский. Это помогает избавиться от необходимости использовать отдельные модели или языковую настройку для международных европейских рынков. Для развертывания в AWS модели нужны GPU-совместимые инстансы с минимум 4 ГБ VRAM, хотя 8 ГБ обеспечивают лучшую производительность. По результатам наших тестов, инстансы G6 (NVIDIA L4 GPU) дают лучшее соотношение цены и производительности для задач инференса. Модель также хорошо работает на G5 (A10G), G4dn (T4), а для максимальной пропускной способности — на P5 (H100) или P4 (A100).
Архитектура решения
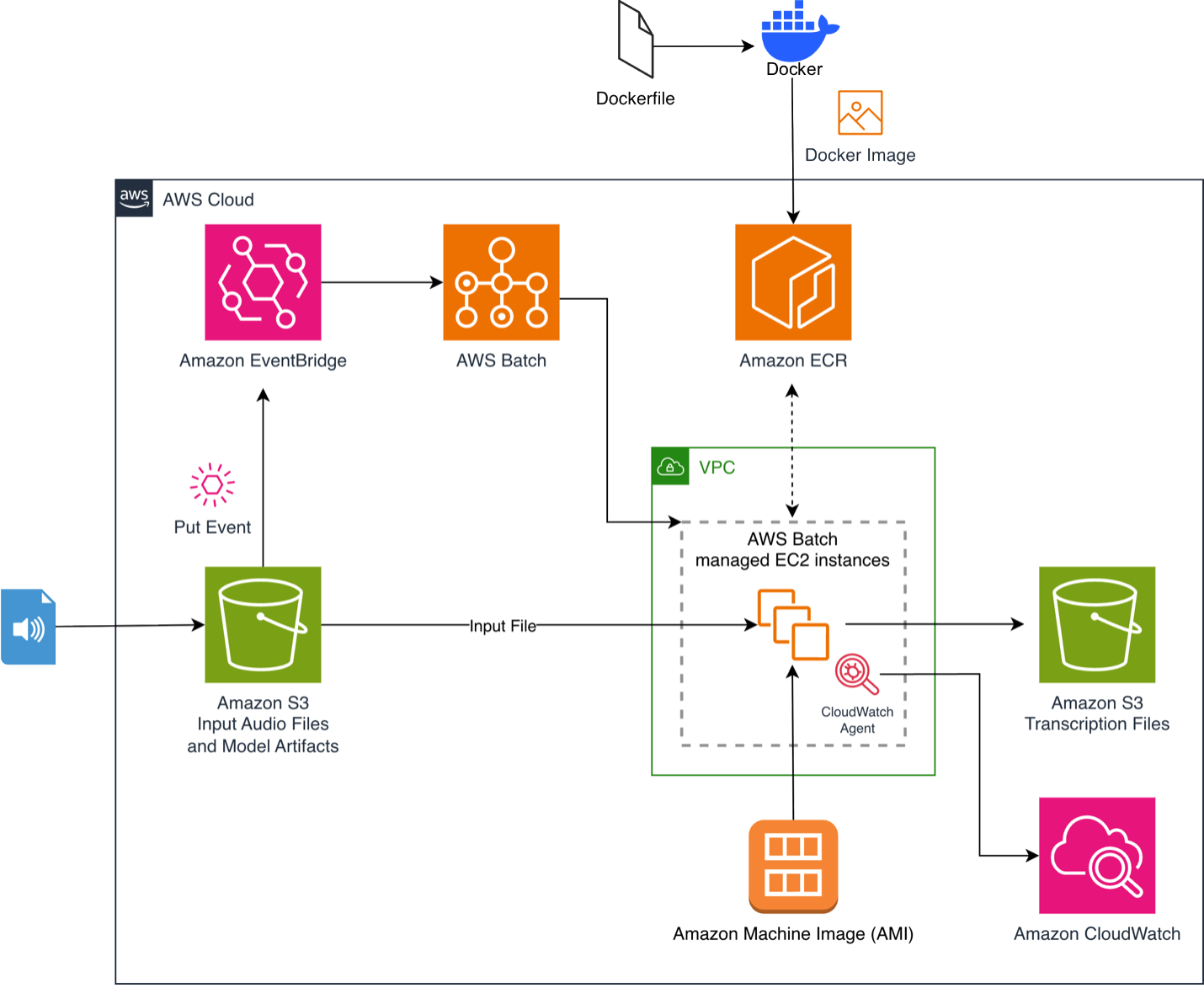
Процесс начинается, когда вы загружаете аудиофайл в S3 bucket. Это запускает правило Amazon EventBridge, которое отправляет задачу в AWS Batch. AWS Batch выделяет вычислительные ресурсы с GPU, а подготовленные инстансы забирают наш контейнерный образ с предзагруженной моделью из Amazon Elastic Container Registry (Amazon ECR). Сценарий инференса скачивает файл, обрабатывает его, а затем загружает JSON-транскрипт с временными метками в выходной S3 bucket. Архитектура масштабируется до нуля в простое, поэтому расходы возникают только во время активных вычислений.
Для более глубокого разбора общих архитектурных компонентов см. наш предыдущий материал Транскрибация аудио Whisper на базе AWS Batch и AWS Inferentia.
Предварительные требования
- Создайте AWS account, если у вас его еще нет, и войдите в систему. Создайте пользователя через AWS IAM Identity Center с полными правами администратора, как описано в Add users.
- Установите AWS Command Line Interface (AWS CLI) на локальную машину разработки и создайте профиль для администратора, как описано в Set up the AWS CLI.
- Установите Docker на локальном компьютере.
- Клонируйте GitHub repository на локальный компьютер.
Сборка контейнерного образа
В репозитории есть Docker file, который собирает облегченный контейнерный образ, оптимизированный для производительности инференса. В качестве базы образ использует Amazon Linux 2023, устанавливает Python 3.12 и заранее кэширует модель Parakeet-TDT-0.6B-v3 во время сборки, чтобы уменьшить задержку загрузки во время выполнения:
FROM public.ecr.aws/amazonlinux/amazonlinux:2023
WORKDIR /app
# Install system dependencies, Python 3.12, and ffmpeg
RUN dnf update -y && \
dnf install -y gcc-c++ python3.12-devel tar xz && \
ln -sf /usr/bin/python3.12 /usr/local/bin/python3 && \
python3 -m ensurepip && \
python3 -m pip install --no-cache-dir --upgrade pip && \
dnf clean all && rm -rf /var/cache/dnf
# Install Python dependencies and pre-cache the model
COPY ./requirements.txt requirements.txt
RUN pip install -U --no-cache-dir -r requirements.txt && \
rm -rf ~/.cache/pip /tmp/pip* && \
python3 -m compileall -q /usr/local/lib/python3.12/site-packages
COPY ./parakeet_transcribe.py parakeet_transcribe.py
# Cache model during build to eliminate runtime download
RUN python3 -c "from nemo.collections.asr.models import ASRModel; \
ASRModel.from_pretrained('nvidia/parakeet-tdt-0.6b-v3')"
CMD ["python3", "parakeet_transcribe.py"]
Публикация в Amazon ECR
В репозитории есть скрипт updateImage.sh, который определяет среду выполнения (CodeBuild или EC2), собирает контейнерный образ, при необходимости создает репозиторий ECR, включает сканирование уязвимостей и загружает образ. Запустите его так:./updateImage.sh
Развертывание решения
Решение использует шаблон AWS CloudFormation (deployment.yaml) для подготовки инфраструктуры. Скрипт buildArch.sh автоматизирует развертывание: он определяет ваш AWS Region, собирает сведения о VPC, подсетях и security group и развертывает стек CloudFormation:
./buildArch.shВнутри он выполняет:
aws cloudformation deploy --stack-name batch-gpu-audio-transcription \
--template-file ./deployment.yaml \
--capabilities CAPABILITY_IAM \
--region ${AWS_REGION} \
--parameter-overrides VPCId=${VPC_ID} SubnetIds="${SUBNET_IDS}" \
SGIds="${SecurityGroup_IDS}" RTIds="${RouteTable_IDS}"
Шаблон CloudFormation создает вычислительную среду AWS Batch с G6 и G5 GPU-инстансами, очередь задач, определение задания, ссылающееся на ваш ECR-образ, входной и выходной S3 buckets с включенными уведомлениями EventBridge. Он также создает правило EventBridge, которое запускает задачу Batch при загрузке в S3, конфигурацию агента Amazon CloudWatch для мониторинга GPU/CPU/памяти и IAM-роли с политиками минимально необходимых прав. AWS Batch позволяет выбирать GPU-образы Amazon Linux 2023, указывая ImageType: ECS_AL2023_NVIDIA в конфигурации вычислительной среды.
Кроме того, можно развернуть решение напрямую из консоли AWS CloudFormation, используя ссылку запуска из README репозитория.
Настройка Spot instances
Amazon EC2 Spot Instances помогают еще сильнее снизить расходы, запуская рабочие нагрузки на незадействованных EC2-ресурсах со скидкой до 90% в зависимости от типа инстанса. Чтобы включить Spot Instances, мы изменяем вычислительную среду в deployment.yaml:
DefaultComputeEnv:
Type: AWS::Batch::ComputeEnvironment
Properties:
Type: MANAGED
State: ENABLED
ComputeResources:
AllocationStrategy: SPOT_PRICE_CAPACITY_OPTIMIZED
Type: SPOT
BidPercentage: 100
InstanceTypes:
- "g6.xlarge"
- "g6.2xlarge"
- "g5.xlarge"
MinvCpus: !Ref DefaultCEMinvCpus
MaxvCpus: !Ref DefaultCEMaxvCpus
# ... remaining configuration unchanged
Вы можете включить это, задав UseSpotInstances=Yes в parameter-overrides при выполнении aws cloudformation deploy. Стратегия распределения SPOT_PRICE_CAPACITY_OPTIMIZED выбирает пулы Spot Instance, которые наименее подвержены прерываниям и при этом имеют минимально возможную цену. Диверсификация типов инстансов (G6 xlarge, G6 2xlarge, G5 xlarge) может улучшить доступность Spot. Установка MinvCpus: 0 гарантирует, что среда масштабируется до нуля в простое, и вы не платите между рабочими нагрузками. Поскольку ASR-задачи являются статeless и idempotent, они хорошо подходят для Spot. Если инстанс будет возвращен, AWS Batch автоматически повторит задачу (в определении задания настроено до 2 попыток повторного запуска).
Управление памятью для длинного аудио
Потребление памяти моделью Parakeet-TDT линейно масштабируется с длительностью аудио. Энкодер Fast Conformer должен вычислять и хранить признаки для всего аудиосигнала, из-за чего возникает прямая зависимость: при удвоении длительности аудио потребление VRAM примерно удваивается. Согласно model card, при полном attention модель может обрабатывать до 24 минут при наличии 80GB VRAM.
NVIDIA решает эту проблему с помощью режима local attention, который поддерживает до 3 часов аудио на 80 GB A100:
# Enable local attention for long audio
asr_model.change_attention_model("rel_pos_local_attn", [128, 128])
asr_model.change_subsampling_conv_chunking_factor(1) # auto select
asr_model.transcribe(["input_audio.wav"])
Это может немного снизить точность, поэтому мы рекомендуем тестировать на вашем сценарии использования.
Buffered streaming inference
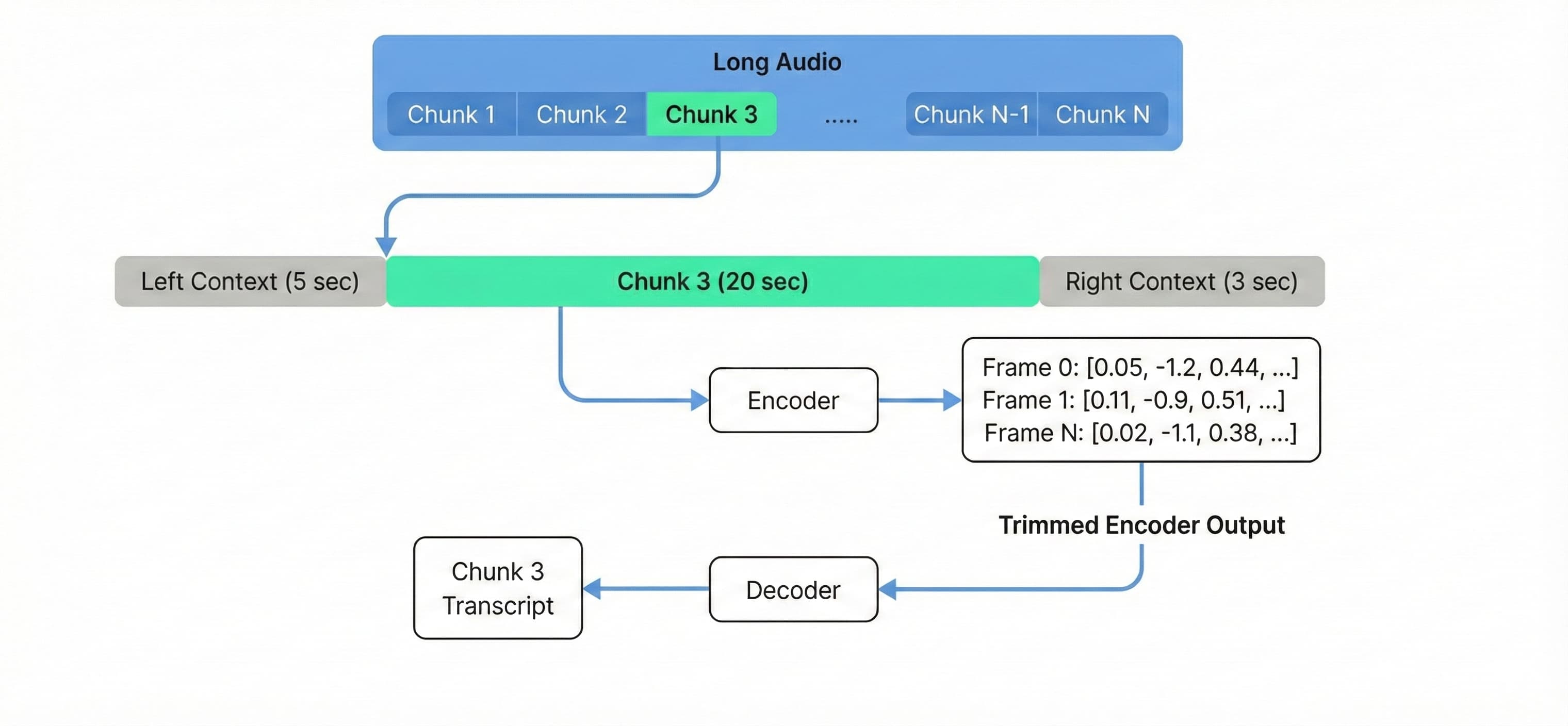
Для аудио, которое превышает 3 часа, или для экономичной обработки длинных файлов на стандартном оборудовании вроде g6.xlarge, мы используем buffered streaming inference. Адаптированная из примера NVIDIA NeMo’s streaming inference example, эта техника обрабатывает аудио перекрывающимися фрагментами, а не загружает весь контекст в память.
Мы настраиваем фрагменты по 20 секунд с 5 секундами левого контекста и 3 секундами правого контекста, чтобы сохранять качество транскрибации на границах фрагментов (обратите внимание, что при изменении этих параметров точность может снижаться, поэтому экспериментируйте, чтобы найти оптимальную конфигурацию. Уменьшение chunk_secs увеличивает время обработки):
# Streaming inference loop
while left_sample < audio_batch.shape[1]:
# add samples to buffer
chunk_length = min(right_sample, audio_batch.shape[1]) - left_sample
# [Logic to manage buffer and flags omitted for brevity]
buffer.add_audio_batch_(...)
# Encode using full buffer [left-chunk-right]
encoder_output, encoder_output_len = asr_model(
input_signal=buffer.samples,
input_signal_length=buffer.context_size_batch.total(),
)
# Decode only chunk frames (constant memory usage)
chunk_batched_hyps, _, state = decoding_computer(...)
# Advance sliding window
left_sample = right_sample
right_sample = min(right_sample + context_samples.chunk, audio_batch.shape[1])
Обработка аудио с фиксированными размерами фрагментов отделяет использование VRAM от общей длительности аудио, позволяя одному инстансу g6.xlarge обрабатывать 10-часовой файл с тем же потреблением памяти, что и 10-минутный.
Чтобы развернуть решение с включенным buffered streaming, задайте параметр EnableStreaming=Yes.
aws cloudformation deploy \
–stack-name batch-gpu-audio-transcription \
–template-file ./deployment.yaml \
–capabilities CAPABILITY_IAM \
–parameter-overrides EnableStreaming=Yes \
VPCId=your-vpc-id SubnetIds=your-subnet-ids SGIds=your-sg-ids RTIds=your-rt-ids
Тестирование и мониторинг
Чтобы проверить решение в масштабе, мы провели эксперимент с 1000 одинаковыми аудиофайлами длительностью 50 минут из NASA preflight crew news conference, распределенными по 100 инстансам g6.xlarge, где каждый обрабатывал по 10 файлов.
Развертывание включает конфигурацию агента Amazon CloudWatch, который собирает показатели загрузки GPU, энергопотребления, использования VRAM, загрузки CPU, потребления памяти и использования диска с интервалом 10 секунд. Эти метрики отображаются в пространстве имен CWAgent, что позволяет строить панели мониторинга для наблюдения в реальном времени.
Анализ производительности и затрат
Чтобы проверить эффективность архитектуры, мы провели бенчмаркинг системы на нескольких длинных аудиофайлах.
Модель Parakeet-TDT-0.6B-v3 показала чистую скорость инференса 0,24 секунды на минуту аудио. Однако полный конвейер включает накладные расходы на загрузку модели в память, загрузку аудио, предварительную обработку входных данных и постобработку результата. Из-за этих накладных расходов оптимальная экономия достигается на длинном аудио, чтобы максимизировать время полезной обработки.
Результаты бенчмарка (g6.xlarge):
- Длительность аудио: 3 часа 25 минут (205 минут)
- Общая длительность задачи: 100 сек
- Эффективная скорость обработки: 0,49 секунды на минуту аудио
- Структура затрат
На основе цен в регионе us-east-1 для инстанса g6.xlarge можно оценить стоимость обработки одной минуты аудио.
| Модель ценообразования | Почасовая стоимость (g6.xlarge)* | Стоимость за минуту аудио |
|---|---|---|
| On-Demand | ~$0.805 | $0.00011 |
| Spot Instances | ~$0.374 | $0.00005 |
*Цены являются оценочными и основаны на тарифах us-east-1 на момент публикации. Стоимость Spot варьируется по Availability Zone и может изменяться.
Это сравнение подчеркивает экономическое преимущество self-hosted подхода для высоконагруженных сценариев, обеспечивая ценность для крупномасштабной транскрибации по сравнению с управляемыми API-сервисами.
Очистка ресурсов
Чтобы избежать будущих списаний, удалите ресурсы, созданные этим решением:
- Очистите все S3 buckets (входной, выходной и logs).
- Удалите стек CloudFormation:
aws cloudformation delete-stack --stack-name batch-gpu-audio-transcription
- При желании удалите репозиторий ECR и контейнерные образы.
Подробные инструкции по очистке см. в разделе cleanup section в README репозитория.
Заключение
В этом материале мы показали, как построить конвейер транскрибации аудио, который обрабатывает данные в масштабе за доли цента в час. Сочетая модель NVIDIA Parakeet-TDT-0.6B-v3 с AWS Batch и EC2 Spot Instances, можно транскрибировать аудио на 25 европейских языках с автоматическим определением языка и снизить затраты по сравнению с альтернативными решениями. Техника buffered streaming inference расширяет эти возможности на аудио разной длительности на стандартном оборудовании, а событийно-ориентированная архитектура автоматически масштабируется с нуля для обработки переменных нагрузок.
Чтобы начать, изучите пример кода в GitHub repository.
Материал — перевод статьи с английского.
Оригинал: Cost-effective multilingual audio transcription at scale with Parakeet-TDT and AWS Batch