Amazon SageMaker AI получил инстансы G7e с NVIDIA RTX PRO 6000 Blackwell для инференса генеративного ИИ

По мере роста спроса на генеративный ИИ разработчикам и компаниям нужны более гибкие, экономичные и мощные ускорители. Сегодня AWS объявляет о доступности инстансов G7e, работающих на GPU NVIDIA RTX PRO 6000 Blackwell Server Edition на Amazon SageMaker AI.
Можно развертывать узлы с 1, 2, 4 и 8 GPU RTX PRO 6000, причем каждый GPU предоставляет 96 ГБ памяти GDDR7. Запуск дает возможность использовать однопроцессорный GPU-инстанс G7e.2xlarge для размещения мощных open source foundation models (FM), таких как GPT-OSS-120B, Nemotron-3-Super-120B-A12B (вариант NVFP4) и Qwen3.5-35B-A3B, что делает решение экономичным и производительным. Это особенно подходит тем, кто хочет снизить затраты без потери качества инференса. Ключевые характеристики инстансов G7e:
- Вдвое больше памяти GPU по сравнению с инстансами G6e, что позволяет разворачивать large language models (LLM) в FP16 вплоть до:
- модели с 35 млрд параметров на одном GPU-узле (G7e.2xlarge)
- модели с 150 млрд параметров на узле с 4 GPU (G7e.24xlarge)
- модели с 300 млрд параметров на узле с 8 GPU (G7e.48xlarge)
- Пропускная способность сети до 1600 Gbps
- До 768 ГБ памяти GPU на G7e.48xlarge
Инстансы Amazon Elastic Compute Cloud (Amazon EC2) G7e — это заметный шаг вперед в GPU-ускоренном облачном инференсе. Они обеспечивают до 2,3x более высокую производительность инференса по сравнению с предыдущим поколением G6e. Каждый GPU в G7e дает пропускную способность 1 597 ГБ/с, что вдвое превышает память на GPU у G6e и в четыре раза больше, чем у G5. Сетевые возможности масштабируются до 1 600 Gbps с EFA на крупнейшем размере G7e — это в 4 раза больше, чем у G6e, и в 16 раз больше, чем у G5, — открывая сценарии низколатентного многоузлового инференса и дообучения, которые ранее были практически недоступны на инстансах серии G. В следующей таблице показана поэтапная эволюция на уровне конфигурации с 8 GPU:
| Характеристика | G5 (g5.48xlarge) | G6e (g6e.48xlarge) | G7e (g7e.48xlarge) |
| GPU | 8x NVIDIA A10G | 8x NVIDIA L40S | 8x NVIDIA RTX PRO 6000 Blackwell |
| Память GPU на один GPU | 24 ГБ GDDR6 | 48 ГБ GDDR6 | 96 ГБ GDDR7 |
| Общая память GPU | 192 ГБ | 384 ГБ | 768 ГБ |
| Пропускная способность памяти GPU | 600 ГБ/с на GPU | 864 ГБ/с на GPU | 1 597 ГБ/с на GPU |
| vCPU | 192 | 192 | 192 |
| Системная память | 768 GiB | 1 536 GiB | 2 048 GiB |
| Пропускная способность сети | 100 Gbps | 400 Gbps | 1 600 Gbps (EFA) |
| Локальное хранилище NVMe | 7,6 ТБ | 7,6 ТБ | 15,2 ТБ |
| Инференс по сравнению с G6e | Базовый уровень | ~1x | До 2,3x |
С 768 ГБ суммарной памяти GPU на одном инстансе G7e может размещать модели, которым раньше требовались многоузловые конфигурации на G5 или G6e, снижая операционную сложность и межузловую задержку. В сочетании с поддержкой точности FP4 на Tensor Cores пятого поколения и NVIDIA GPUDirect RDMA поверх EFAv4 инстансы G7e становятся предпочтительным выбором для развертывания LLM, multimodal AI и agentic inference workloads в AWS.
Сценарии использования, для которых G7e подходит лучше всего
Сочетание плотности памяти, пропускной способности и сетевых возможностей делает G7e подходящим для широкого спектра современных задач генеративного ИИ:
- Чат-боты и conversational AI — низкий TTFT и высокая пропускная способность G7e сохраняют отзывчивость интерактивных сценариев даже при высокой одновременной нагрузке.
- Agentic и tool-calling workflows — четырехкратное улучшение пропускной способности CPU-to-GPU делает G7e особенно эффективным для Retrieval Augmented Generation (RAG) и agentic workflows, где критична быстрая подача контекста из retrieval stores.
- Генерация текста, суммаризация и long-context inference — 96 ГБ памяти на GPU позволяют хранить большие KV caches для длинных контекстов документов, уменьшая усечение и обеспечивая более глубокое рассуждение на длинных входах.
- Генерация изображений и vision models — там, где более ранние инстансы сталкиваются с out-of-memory errors на крупных multimodal models, удвоенная память G7e устраняет эти ограничения.
- Physical AI и научные вычисления — вычислительные возможности Blackwell, поддержка FP4 и функции spatial computing (DLSS 4.0, RT cores четвертого поколения) расширяют применимость до digital twins, 3D simulation и инференса physical AI моделей.
Пошаговое развертывание
Требования
Чтобы попробовать это решение с помощью SageMaker AI, нужны следующие предварительные условия:
- Аккаунт AWS, в котором будут находиться все ваши ресурсы AWS.
- Роль AWS Identity and Access Management (IAM) для доступа к Amazon SageMaker AI. Подробнее о том, как IAM работает с SageMaker AI, см. в разделе Identity and Access Management for Amazon SageMaker AI.
- Доступ к Amazon SageMaker Studio или к SageMaker notebook instance, либо к среде разработки (IDE) вроде PyCharm или Visual Studio Code. Для простого развертывания и инференса рекомендуется использовать Amazon SageMaker Studio.
- Квота на один экземпляр ml.g7e.2xlarge [или больше] для endpoint usage Amazon SageMaker AI. Запросить увеличение квоты можно через консоль Service Quotas.
Развертывание
Можно клонировать репозиторий и использовать пример ноутбука, доступный здесь.
Тесты производительности
Чтобы измерить эволюционный прирост, AWS провела бенчмарк Qwen3-32B (BF16) на инстансах G6e и G7e при одинаковой нагрузке: примерно 1 000 входных токенов и около 560 выходных токенов на запрос. Это типичный профиль для задач суммаризации или исправления документов. В обеих конфигурациях использовался нативный контейнер vLLM с включенным prefix caching.
Набор тестов, использованный для получения результатов, доступен в примере Jupyter notebook. Он состоит из трех шагов: (1) развернуть модель на endpoint SageMaker AI с помощью нативного контейнера vLLM, (2) провести нагрузочное тестирование при уровнях concurrency от 1 до 32 одновременных запросов и (3) проанализировать результаты, чтобы получить следующие таблицы производительности.
Базовый уровень G6e: ml.g6e.12xlarge [4x L40S, $13.12/ч]
С 4 GPU L40S и степенью tensor parallelism 4 G6e обеспечивает высокую пропускную способность на запрос: 37,1 tok/s при одиночной конкуренции и 21,5 tok/s при C=32.
| C | Success | p50 (с) | p99 (с) | tok/s | RPS | Agg tok/s | $/M tokens |
|---|---|---|---|---|---|---|---|
| 1 | 100% | 16.1 | 16.3 | 37.1 | 0.07 | 37 | $38.09 |
| 8 | 100% | 19.8 | 20.2 | 30.3 | 0.42 | 242 | $5.85 |
| 16 | 100% | 23.1 | 23.5 | 26.0 | 0.73 | 416 | $3.41 |
| 32 | 100% | 26.0 | 29.2 | 21.5 | 1.21 | 686 | $2.06 |
G7e: ml.g7e.2xlarge [1x RTX PRO 6000 Blackwell, $4.20/ч]
G7e запускает ту же 32-миллиардную модель на одном GPU со степенью tensor parallelism 1. Хотя tok/s на запрос ниже, чем у 4-GPU конфигурации G6e, картина по затратам радикально отличается.
| C | Success | p50 (с) | p99 (с) | tok/s | RPS | Agg tok/s | $/M tokens |
|---|---|---|---|---|---|---|---|
| 1 | 100% | 27.2 | 27.5 | 22.0 | 0.04 | 22 | $21.32 |
| 8 | 100% | 28.7 | 28.9 | 20.9 | 0.28 | 167 | $2.81 |
| 16 | 100% | 30.3 | 30.6 | 19.9 | 0.53 | 318 | $1.48 |
| 32 | 100% | 33.2 | 33.3 | 18.5 | 0.99 | 592 | $0.79 |
Что говорят цифры
При производственной конкуренции (C=32) G7e достигает $0.79 за миллион выходных токенов, что означает 2,6-кратное снижение стоимости по сравнению с $2.06 у G6e. Это объясняется двумя факторами: существенно более низкой почасовой ставкой G7e ($4.20 против $13.12) и способностью сохранять стабильную пропускную способность под нагрузкой. Однопроцессорная архитектура G7e также масштабируется более плавно. Задержка увеличивается на 22% от C=1 до C=32 (с 27.2 с до 33.2 с), тогда как у G6e рост составляет 62% (с 16.1 с до 26.0 с). При степени tensor parallelism 1 отсутствуют:
- накладные расходы на синхронизацию между GPU
- операции all-reduce на каждом слое transformer
- фрагментация KV cache между GPU
- узкое место в коммуникации NVLink
По мере роста concurrency и насыщения GPU отсутствие координационных накладных расходов делает задержку предсказуемой. Для чувствительных к задержке задач при низкой concurrency 4-GPU параллелизм G6e по-прежнему дает более быстрые отдельные ответы. Для production deployments, оптимизирующих cost per token at scale, G7e — очевидный выбор, а в следующем разделе показано, что сочетание G7e с EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency) speculative decoding дает еще больший эффект.
Совместные тесты: G7e + EAGLE speculative decoding
Улучшения аппаратной части G7e сами по себе значительны, но сочетание с EAGLE speculative decoding дает накопительный эффект. EAGLE ускоряет декодирование LLM, предсказывая несколько будущих токенов на основе собственных скрытых представлений модели, а затем проверяя их за один проход forward. Это обеспечивает идентичное качество вывода при генерации нескольких токенов за шаг. Подробный разбор EAGLE на SageMaker AI, включая настройку optimization job и workflow Base vs Trained EAGLE, см. в материале Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inference.
В этом разделе измеряется совокупный прирост от базового уровня до G7e + EAGLE3 на Qwen3-32B в BF16. Нагрузка бенчмарка использует примерно 1 000 входных токенов и около 560 выходных токенов на запрос, что соответствует задачам суммаризации или исправления документов. EAGLE3 включается с помощью community-trained speculator размером около 1.56 ГБ с параметром num_speculative_tokens=4.
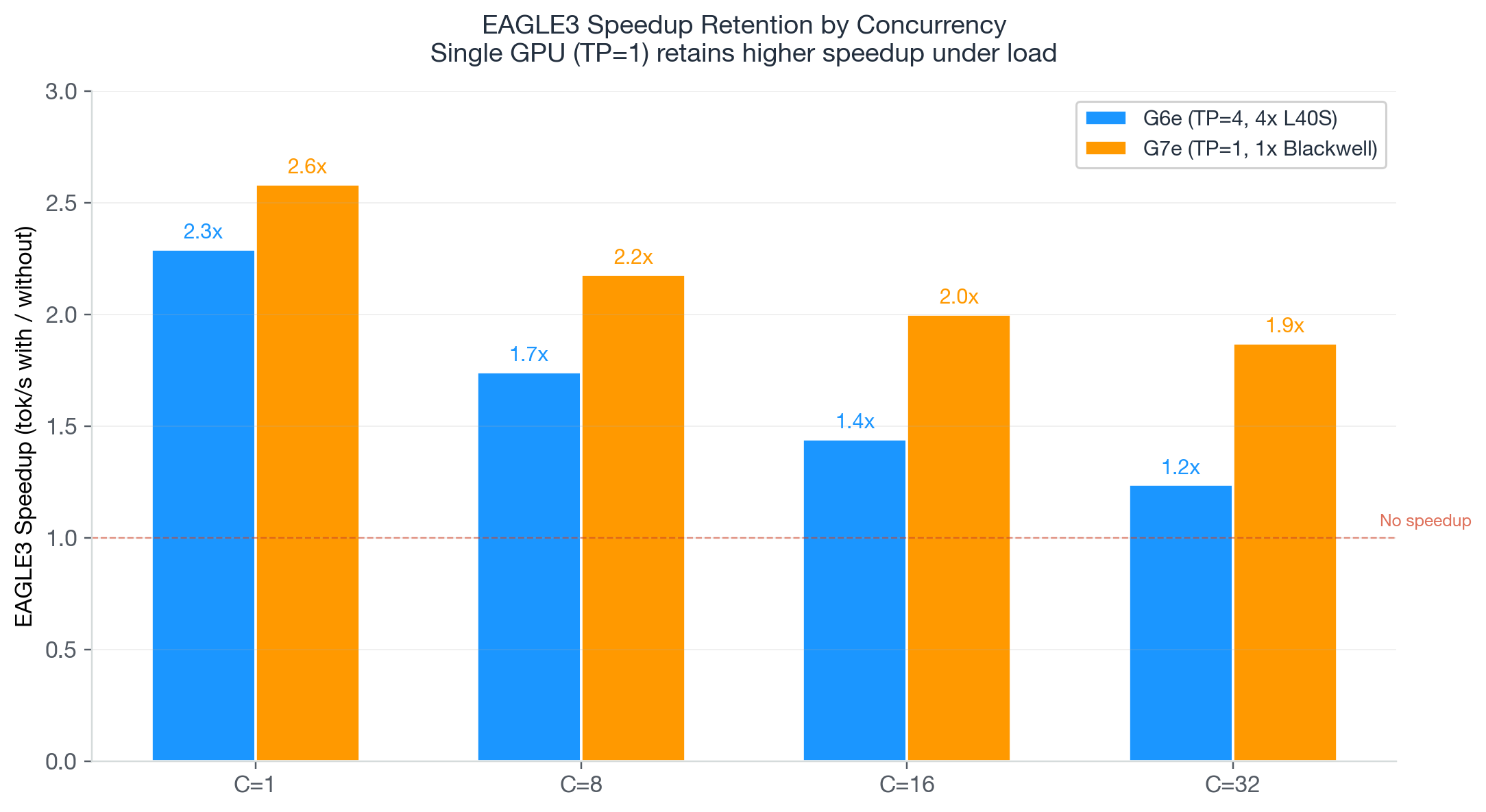
G7e + EAGLE3 обеспечивает 2,4-кратный прирост пропускной способности и 75% снижение затрат по сравнению с базовым уровнем предыдущего поколения. При $0.41 за миллион выходных токенов это также в 4 раза дешевле, чем G6e + EAGLE3 ($1.72), несмотря на более высокую пропускную способность.
Включение EAGLE3
Для production deployments с дообученными моделями набор инструментов SageMaker AI EAGLE optimization toolkit может обучать собственные EAGLE heads на ваших данных, еще больше повышая acceptance rate speculative decoding и пропускную способность по сравнению с community speculators.
Ценообразование
Инстансы G7e в Amazon SageMaker AI тарифицируются по стандартной цене SageMaker AI inference для выбранного типа инстанса и длительности использования. Дополнительной платы за токен или запрос при обслуживании на G7e нет.
Optimization jobs EAGLE выполняются на обучающих инстансах SageMaker AI и тарифицируются по стандартной ставке training instance на время выполнения задания. Полученные улучшенные артефакты модели хранятся в Amazon Simple Storage Service (Amazon S3) по стандартным тарифам хранения. После развертывания улучшенной модели дополнительная плата за EAGLE-ускоренный инференс не взимается. Вы оплачиваете только стандартную стоимость endpoint instance.
В следующей таблице показаны цены по требованию для ключевых размеров инстансов G7e, G6e и G5 в регионе US East (N. Virginia) для справки. Строки G7e выделены.
| Инстанс | GPU | Память GPU | Типичный сценарий использования |
| ml.g5.2xlarge | 1 | 24 ГБ | Небольшие LLM (≤7B FP16); разработка и тестирование |
| ml.g5.48xlarge | 8 | 192 ГБ | Обслуживание крупных LLM с несколькими GPU на G5 |
| ml.g6e.2xlarge | 1 | 48 ГБ | LLM среднего размера (≤14B FP16) |
| ml.g6e.12xlarge | 2 | 96 ГБ | Крупные LLM (≤36B FP16); базовый уровень предыдущего поколения |
| ml.g6e.48xlarge | 8 | 384 ГБ | Очень крупные LLM (≤90B FP16) |
| ml.g7e.2xlarge | 1 | 96 ГБ | Крупные LLM (≤70B FP8) на одном GPU |
| ml.g7e.24xlarge | 4 | 384 ГБ | Очень крупные LLM; высокопроизводительный сервис |
| ml.g7e.48xlarge | 8 | 768 ГБ | Максимальная пропускная способность; крупнейшие модели |
Снизить затраты на инференс можно и с помощью Amazon SageMaker Savings Plans, которые дают скидку до 64% в обмен на обязательство по стабильному объему использования. Они хорошо подходят для production inference endpoints с предсказуемым трафиком.
Очистка ресурсов
Чтобы избежать лишних расходов после завершения тестирования, удалите SageMaker endpoints, созданные в ходе walkthrough. Это можно сделать через консоль SageMaker AI или с помощью Python SDK, как показано в Amazon SageMaker AI Developer Guide.
Если вы запускали optimization job EAGLE, удалите также выходные артефакты из Amazon S3, чтобы избежать постоянных расходов на хранение.
Заключение
Инстансы G7e в Amazon SageMaker AI представляют следующий крупный шаг в экономичном инференсе генеративного ИИ. Архитектура GPU Blackwell обеспечивает в 2 раза больше памяти на GPU, в 1,85 раза более высокую пропускную способность памяти и до 2,3x более высокую производительность инференса по сравнению с G6e. Это позволяет ранее много-GPU workloads эффективно запускать на одном GPU и повышает потолок пропускной способности для каждой GPU-конфигурации. В сочетании со speculative decoding EAGLE в SageMaker AI улучшения складываются еще сильнее. Ускорение EAGLE, зависящее от пропускной способности памяти, напрямую выигрывает от увеличенной пропускной способности G7e, а большая емкость памяти G7e позволяет draft heads EAGLE сосуществовать с более крупными моделями без давления на память. Вместе аппаратные и программные улучшения дают прирост пропускной способности, который напрямую превращается в снижение стоимости одного выходного токена при масштабировании.
Переход от G5 к G6e к G7e, дополненный оптимизацией EAGLE, представляет собой почти непрерывный путь совместной аппаратно-программной оптимизации — путь, который продолжает улучшаться по мере эволюции моделей и накопления данных производственного трафика, возвращаемых в повторное обучение EAGLE.
Материал — перевод статьи с английского.
Оригинал: Accelerate Generative AI Inference on Amazon SageMaker AI with G7e Instances