Speculative decoding на AWS Trainium и vLLM ускоряет декодирование LLM до 3x

Практические бенчмарки показывают более низкую межтокенную задержку при развертывании моделей Qwen3 с помощью vLLM, Kubernetes и AWS AI Chips.
Speculative decoding на AWS Trainium может ускорить генерацию токенов до 3 раз для декод-ориентированных нагрузок, помогая снизить стоимость одного выходного токена и повысить пропускную способность без потери качества ответа. Если вы создаете ИИ-помощники для написания текстов, кодовые агенты или другие генеративные приложения, ваши рабочие нагрузки, вероятно, генерируют гораздо больше токенов, чем потребляют, поэтому стадия decode становится основным источником затрат на инференс. Во время авторегрессивного декодирования токены генерируются последовательно, из-за чего аппаратные ускорители упираются в пропускную способность памяти и используются неэффективно. Это повышает стоимость генерации каждого токена. Speculative decoding устраняет это узкое место: небольшая draft-модель предлагает сразу несколько токенов, а целевая модель проверяет их за один проход вперед. Меньшее число последовательных шагов decode означает меньшую задержку и более высокую загрузку железа, что помогает сократить затраты на инференс.
В этой статье вы узнаете:
- Как работает speculative decoding и почему он помогает снизить стоимость одного сгенерированного токена на AWS Trainium2
- Как включить speculative decoding с vLLM на Trainium
- Какая методология бенчмаркинга использовалась для оценки производительности
- Как подбирать draft-модель и размер окна speculative tokens под свои нагрузки
- Как пошагово воспроизвести результаты с помощью Qwen3
Что такое speculative decoding?
Speculative decoding ускоряет авторегрессивную генерацию, используя две модели:
- draft-модель быстро предлагает n кандидатов токенов.
- target-модель проверяет их за один проход вперед.
Для более глубокого разбора механики, включая принятие и отклонение токенов, speculation на основе EAGLE и общие концепции speculative decoding, см. пост Inferentia2этот разбор SageMaker EAGLE на AWS Inferentia2, этот разбор SageMaker EAGLE и это введение. Здесь мы сосредотачиваемся на двух параметрах, которыми вы реально управляете: draft-модели и num_speculative_tokens.
Draft- и target-модели должны использовать один и тот же tokenizer и vocabulary, потому что speculative decoding работает с идентификаторами токенов, которые target-модель проверяет напрямую. Мы рекомендуем выбирать модели из одной архитектурной семьи, потому что их предсказания следующего токена чаще совпадают. Можно сочетать модели с разной архитектурой, если у них общий tokenizer, но более низкое совпадение между draft- и target-моделью снижает долю принятых токенов и почти убирает выигрыш в производительности.
Когда target-модель принимает токены, предложенные draft-моделью, они фиксируются без полной стоимости последовательных шагов decode. Основной параметр, которым вы управляете, — num_speculative_tokens, то есть сколько токенов draft-модель предлагает за один раз. Увеличение этого значения позволяет пропускать больше последовательных шагов decode за один проход проверки, напрямую снижая межтокенную задержку при высоком уровне принятия.
Прирост производительности возникает из двух эффектов. Во-первых, speculative decoding уменьшает число шагов decode target-модели, а значит, снижает число обращений к памяти KV cache. (KV cache хранит ранее вычисленные тензоры ключей и значений, чтобы модель не пересчитывала внимание для прошлых токенов. Каждый шаг decode читает весь кэш из памяти, поэтому decode становится ограниченным пропускной способностью памяти.) Во-вторых, speculative decoding повышает утилизацию железа во время декодирования. В обычном авторегрессивном декодировании каждый шаг decode генерирует только один новый токен: ускоритель запускает дорогие матричные ядра ради работы всего на один токен, и двигатель вычислительных элементов остается недогруженным. Во время проверки target-модель обрабатывает сразу n токенов, амортизируя обращения к памяти и превращая последовательность маленьких неэффективных вычислений по одному токену в более плотную по вычислениям нагрузку. Если задать num_speculative_tokens слишком низким, выигрыш в скорости будет ограничен.
Если задать его слишком высоким, возрастает вероятность ранних отклонений, что тратит вычисления draft-модели впустую и увеличивает стоимость проверки target-модели. Это значение настраивают, балансируя вычисления draft-модели и стоимость проверки на основе наблюдаемой доли принятия.
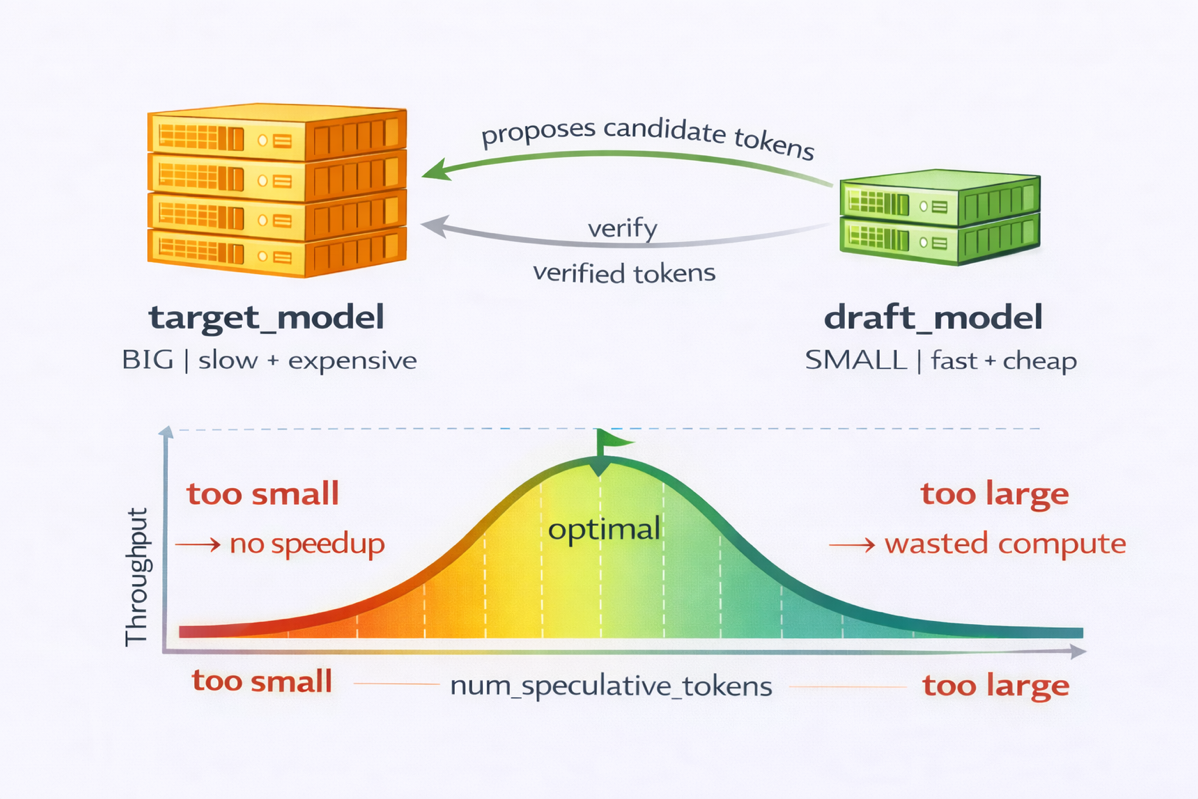
Рисунок 1. Компромиссы конфигурации speculative decoding
Чтобы проиллюстрировать эти компромиссы, мы сравнили draft-модели Qwen3-0.6B и Qwen3-1.7B. Меньшая модель 0.6B работала быстрее, но ее доля принятия была примерно на 60% ниже, чего оказалось достаточно, чтобы нивелировать экономию вычислений. Qwen3-1.7B дала лучший баланс скорости и принятия.
Для num_speculative_tokens мы оценивали значения от 5 до 15. Меньшие настройки, например 5, давали ограниченный прирост скорости. Более широкие окна, например 15, повышали число отклонений и ухудшали производительность. Лучшая конфигурация сильно зависела от структуры промпта. Мы тестировали как структурированные промпты, такие как повторения, числовые последовательности и простой код, так и открытые текстовые запросы на естественном языке. Лучший баланс показала связка Qwen3-1.7B с 7 speculative tokens. Полные детали настройки см. в разделе Lessons learned.
Что поддерживает NeuronX Distributed Inference (NxD Inference)
AWS Neuron — это SDK для AWS AI chips. NeuronX Distributed Inference (NxDI) — это его библиотека для масштабируемого высокопроизводительного инференса LLM на Trainium и Inferentia. NxDI нативно поддерживает speculative decoding на Trainium в четырех режимах:
- Vanilla speculative decoding — draft- и target-модели компилируются отдельно. Самый простой способ начать.
- Fused speculation — draft- и target-модели компилируются вместе для лучшей производительности. Этот режим мы используем в статье.
- EAGLE speculation — draft-модель использует hidden-state context target-модели, чтобы повысить долю принятия.
- Medusa speculation — несколько небольших prediction heads работают параллельно и предлагают токены, снижая накладные расходы draft-модели.
Полную документацию см. в руководстве по Speculative Decoding и в руководстве по EAGLE Speculative Decoding. В этом посте используется fused speculation, где draft-модель (Qwen3-1.7B) и target-модель (Qwen3-32B) компилируются вместе с enable_fused_speculation=true для оптимальной производительности на Neuron.
Как начать использовать speculative decoding на AWS Trainium
Мы разворачиваем два inference-сервиса vLLM на инстансах Trainium в одном кластере Amazon Elastic Kubernetes Service (Amazon EKS), оставляя все одинаковым, кроме метода декодирования, чтобы изолировать влияние на производительность. Базовый сервис (qwen-vllm) обслуживает Qwen3-32B со стандартным декодированием. Сервис speculative decoding (qwen-sd-vllm) обслуживает ту же target-модель Qwen3-32B, добавляя draft-модель Qwen3-1.7B с num_speculative_tokens=7.
Оба сервиса работают с одинаковыми настройками на Trn2 (trn2.48xlarge), с тем же распределением ускорителей, tensor parallelism, который распределяет веса модели по нескольким NeuronCore, чтобы вмещать большие модели, длиной последовательности, лимитами batching и образом Neuron DLC. Единственное отличие — добавление draft-модели Qwen3-1.7B и num_speculative_tokens=7 для speculative-сервиса. Полные детали конфигурации см. на рисунке 2.
Чтобы сравнить две конфигурации при одинаковой нагрузке, мы использовали llmperf для генерации одинаковых паттернов трафика на оба endpoint. Мы собирали телеметрию инфраструктуры с помощью CloudWatch Container Insights и публиковали пользовательские метрики на уровне запросов — TTFT, межтокенную задержку и end-to-end latency — в дашборды CloudWatch для сравнения рядом.
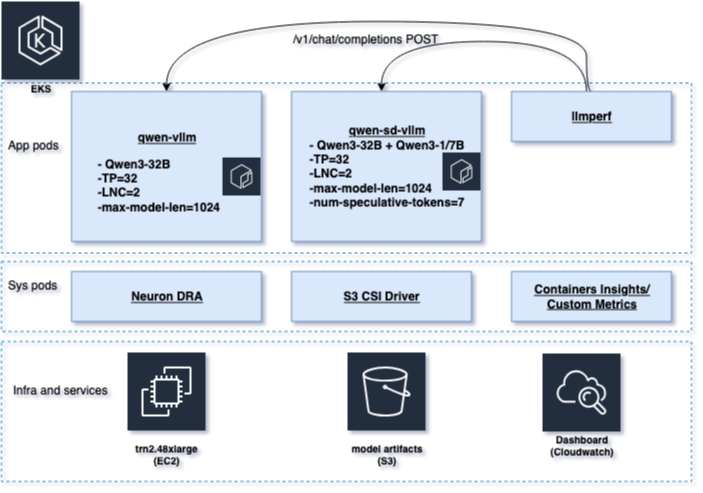
Рисунок 2. Системная архитектура
Методика бенчмаркинга
Мы использовали LLMPerf для запуска структурированных, декод-ориентированных тестовых сценариев против развертываний baseline и speculative decoding. Бенчмарки запускались внутри Kubernetes pod, qwen-llmperf-pod.yaml, который отправлял параллельные запросы к обоим endpoint и вел журнал метрик задержки на уровне токенов. Наши сценарии варьировались от сильно структурированных промптов, таких как повторяющиеся последовательности, числовые продолжения и простые шаблоны кода, до открытых завершений на естественном языке, покрывая как лучший, так и худший сценарий для speculative decoding. Полный набор промптов доступен в репозитории samples.
Для наглядности мы сосредотачиваем анализ на двух репрезентативных типах промптов: сильно структурированном детерминированном промпте (повторяющаяся генерация текста) и открытом промпте. Эти два случая показывают как лучший, так и худший сценарий работы speculative decoding.
Pod запускал llmperf с контролируемыми длинами входа и выхода и temperature=0.0, чтобы нагрузить детерминированные пути декодирования. Мы логировали и публиковали в CloudWatch метрики, включая межтокенную задержку, TTFT, throughput и end-to-end latency.
Результаты
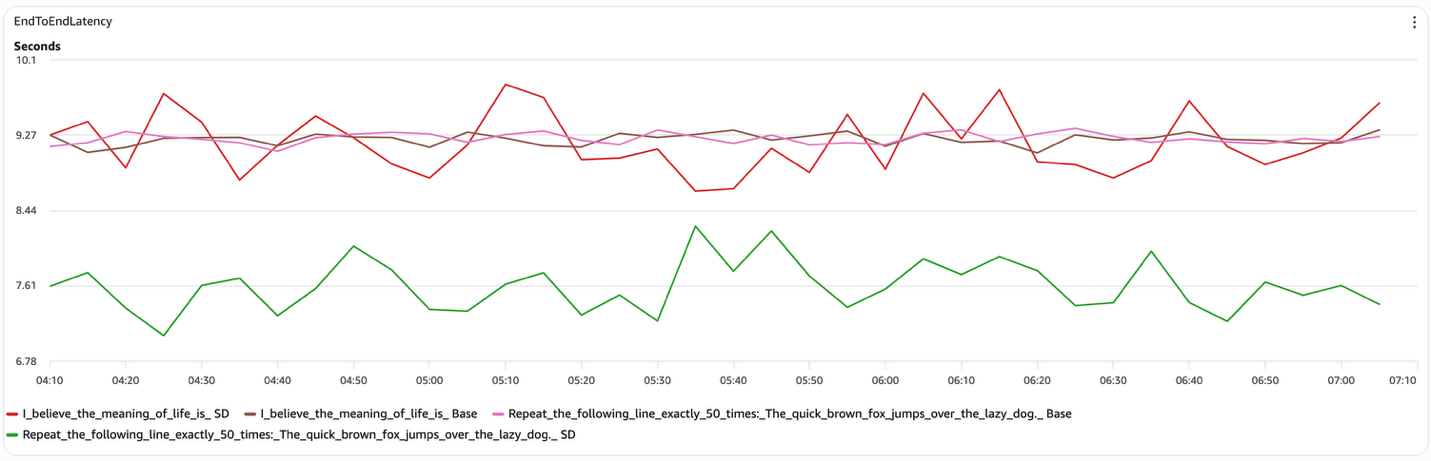
Рисунок 3. End-to-end latency при speculative decoding
Speculative decoding снижает задержку избирательно: его эффективность сильно зависит от структуры промпта, и эта зависимость стабильно проявляется во всех измеряемых метриках. Вот чего можно ожидать для каждого типа промпта:
- Структурированные промпты, например «Повтори следующую строку дословно 50 раз». Speculative decoding дает заметное снижение end-to-end latency. Когда draft-модель надежно предсказывает то, что сгенерировала бы target-модель, система пропускает существенную долю шагов decode target-модели. В наших тестах межтокенная задержка снизилась примерно до 15 мс на токен по сравнению с примерно 45 мс для открытых промптов, а кривая speculative decoding оставалась стабильно ниже baseline на всем протяжении прогона.
- Открытые промпты, например «Я считаю, что смысл жизни заключается в». Speculative decoding не дает стабильного выигрыша. Draft-модель часто расходится с target-моделью, вызывая отклонения токенов, которые нивелируют потенциальные преимущества. Кривые end-to-end latency для speculative и baseline в значительной степени совпадают, а межтокенная задержка держится около 45 мс на токен для обеих конфигураций.
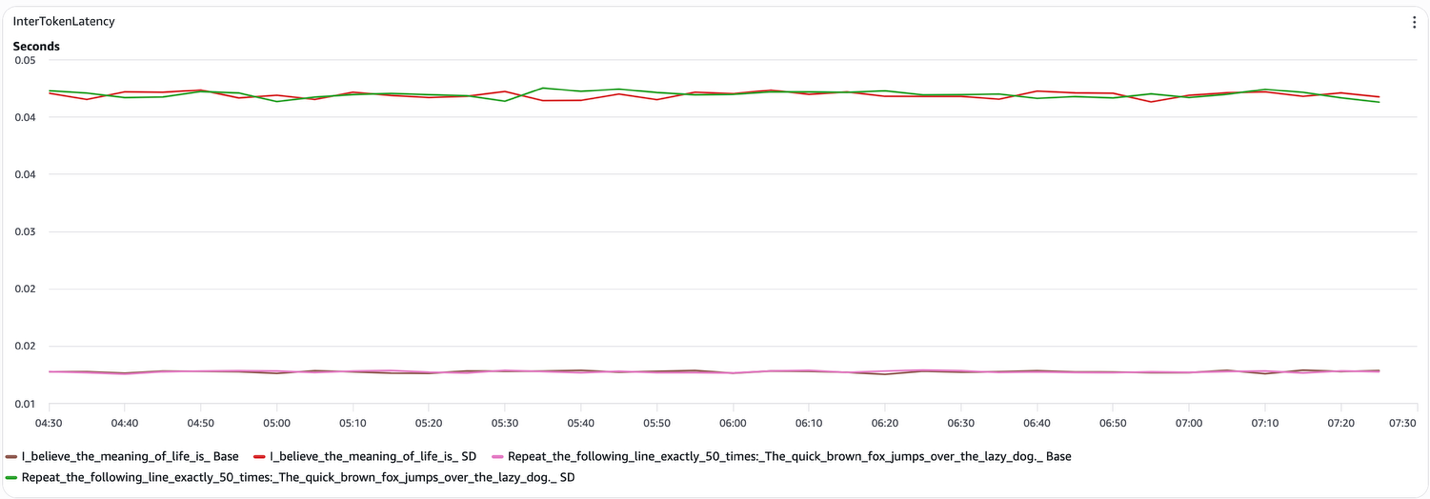
Рисунок 4. Межтокенная задержка при speculative decoding (decode)
TTFT (Time to First Token) практически не меняется между конфигурациями (рисунок 5). TTFT определяется в основном стадией prefill, где модель кодирует входной контекст. Speculative decoding не меняет эту стадию, поэтому задержка prefill ни не улучшается, ни не ухудшается.
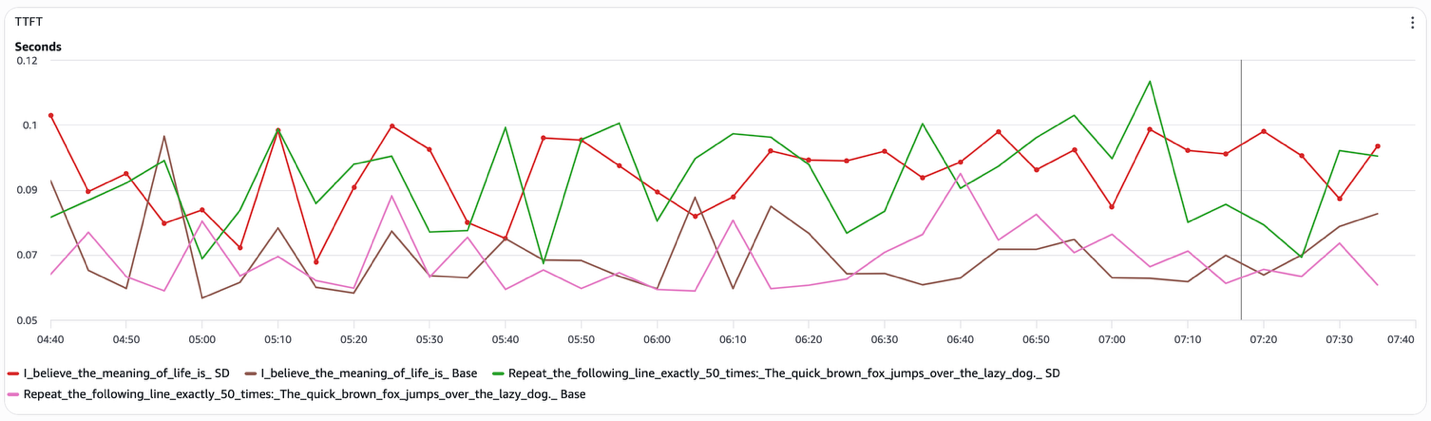
Рисунок 5. TTFT при speculative decoding (prefill)
В совокупности эти результаты показывают, что speculative decoding улучшает общую задержку за счет уменьшения числа выполняемых шагов decode target-модели, а не за счет ускорения самого шага decode или стадии prefill. Это объясняет, почему выигрыш виден в end-to-end latency для структурированных промптов, но отсутствует в inter-token latency и TTFT, а также почему speculative decoding возвращается к базовому поведению при открытой генерации.
Как воспроизвести результаты
Мы предоставляем end-to-end примеры кода и конфигурации Kubernetes в репозитории AWS Neuron EKS samples. Репозиторий включает:
- манифесты Kubernetes для развертывания baseline vLLM и speculative decoding vLLM-сервисов на Trn2
- пример флагов конфигурации vLLM для включения fused speculative decoding
- примерные скрипты бенчмаркинга
llmperf, используемые для генерации нагрузки и сбора метрик - инструкции по подключению модельных checkpoint и скомпилированных артефактов через S3 CSI Driver
- рекомендации по настройке Neuron DRA, tensor parallelism и размещения NeuronCore
Эти примеры позволяют воспроизвести ту же экспериментальную конфигурацию, которая использовалась в статье, — от развертывания модели до бенчмаркинга и сбора метрик.
Вывод
Декод-ориентированные LLM-нагрузки ограничены последовательной природой авторегрессивной генерации. Speculative decoding снимает это узкое место на AWS Trainium2, уменьшая число шагов decode target-модели, необходимых для генерации полного ответа, и тем самым фактически увеличивая число токенов, генерируемых за один проход вперед. Для нагрузок, где пространство выхода предсказуемо, например генерация кода, структурированное извлечение данных, шаблонная генерация отчетов или синтез конфигурационных файлов, это может напрямую привести к более низкой стоимости одного выходного токена и более высокой пропускной способности без потери качества. Speculative decoding не является универсальной оптимизацией. Его эффективность зависит от структуры промпта, качества draft-модели и настройки параметров speculation. При применении к подходящим нагрузкам он дает заметное снижение задержки и затрат в inference-системах на базе Trainium.
Следующие шаги
Чтобы начать использовать speculative decoding на AWS Trainium, изучите эти ресурсы:
- Страница продукта AWS Trainium — информация о типах инстансов Trainium, возможностях и ценах.
- Руководство разработчика NeuronX Distributed Inference — полная документация по NxDI, включая параметры настройки speculative decoding.
- Руководство по функции NxDI Speculative Decoding — справочник по включению vanilla, fused, EAGLE и Medusa speculation modes.
- Документация vLLM — как настроить vLLM для production-serving LLM.
- Документация Amazon EKS — начните работать с Kubernetes на AWS для развертывания и масштабирования inference-сервисов.
- Репозиторий AWS Neuron EKS samples — end-to-end примеры кода для воспроизведения бенчмарков из статьи.
- Документация Amazon CloudWatch — настройка дашбордов и пользовательских метрик для мониторинга inference-endpoint.
Материал — перевод статьи с английского.
Оригинал: Accelerating decode-heavy LLM inference with speculative decoding on AWS Trainium and vLLM