Amazon SageMaker AI теперь поддерживает оптимизированные рекомендации для инференса generative AI

Компании спешат выводить модели generative AI в production, чтобы запускать интеллектуальные ассистенты, инструменты генерации кода, системы создания контента и клиентские приложения. Но внедрение таких моделей в production по-прежнему занимает недели: нужно подбирать GPU-конфигурации, применять оптимизации и вручную проводить бенчмаркинг, откладывая получение ценности от моделей.
Сегодня Amazon SageMaker AI поддерживает оптимизированные рекомендации для инференса generative AI. Предоставляя проверенные оптимальные конфигурации развертывания вместе с метриками производительности, Amazon SageMaker AI позволяет разработчикам моделей сосредоточиться на создании точных моделей, а не на управлении инфраструктурой.
Мы оценили несколько инструментов бенчмаркинга и выбрали NVIDIA AIPerf, модульный компонент NVIDIA Dynamo, потому что он предоставляет подробные, согласованные метрики и поддерживает разные типы рабочих нагрузок из коробки. Его CLI, управление конкуренцией и параметры датасета дают нам гибкость для быстрого итеративного тестирования в разных сценариях с минимальной подготовкой.
«С интеграцией модульных компонентов открытого фреймворка распределенного инференса NVIDIA Dynamo непосредственно в Amazon SageMaker AI AWS упрощает для компаний развертывание generative AI-моделей с уверенностью. AWS внесла значительный вклад в развитие AIPerf благодаря тесному сотрудничеству и техническим доработкам. Интеграция NVIDIA AIPerf показывает, как стандартизированный бенчмаркинг может убрать недели ручного тестирования и передать пользователям проверенные, готовые к развертыванию конфигурации».
— Eliuth Triana, менеджер по Developer Relations в NVIDIA.
Проблема: путь от модели до production занимает недели
Развертывание моделей в масштабе требует production inference endpoints, которые соответствуют четким целям по производительности: SLA по задержке, целевому уровню пропускной способности или ограничению по стоимости. Для этого нужно найти правильное сочетание типа GPU-инстанса, serving container, стратегии параллелизма и техник оптимизации — и все это должно быть настроено под конкретную модель и характер трафика.

Пространство решений невероятно велико. Для одного развертывания приходится выбирать из более чем дюжины типов GPU-инстансов, нескольких serving containers, разных степеней параллелизма и растущего набора техник оптимизации, таких как speculative decoding. Все это влияет друг на друга, и нет проверенных рекомендаций, которые сузили бы поиск. Единственный способ найти правильную конфигурацию — тестировать, и именно здесь начинаются основные затраты. Команды выделяют инстансы, разворачивают модель, проводят load tests, анализируют результаты и повторяют цикл снова. На одну модель уходит от двух до трех недель, а также требуются экспертиза в GPU-инфраструктуре, serving frameworks и performance optimization, которой у большинства команд нет внутри компании.
Многие команды начинают вручную: выбирают несколько типов инстансов, разворачивают модель, запускают load tests, сравнивают latency, throughput и cost, затем повторяют процесс. Более зрелые команды часто автоматизируют часть процесса с помощью benchmarking tools, deployment templates или CI/CD pipelines. Но даже при скриптованных рабочих нагрузках объем работы остается значительным. Нужно тестировать и проверять скрипты, выбирать, какие конфигурации бенчмаркить, настраивать среду бенчмаркинга, интерпретировать результаты и искать баланс между latency, throughput и cost.
Командам часто приходится принимать критически важные инфраструктурные решения, не зная, существует ли более качественный и более экономичный вариант. В итоге они склоняются к over-provisioning, выбирая более дорогую GPU-инфраструктуру, чем нужно, и запускают конфигурации, которые не используют вычислительные ресурсы полностью. Риск недопроизводительности в production гораздо выше, чем перерасход на вычисления. Результат — впустую потраченные GPU-расходы, которые накапливаются с каждой новой моделью и каждым месяцем работы endpoint.
Как работают оптимизированные рекомендации для инференса generative AI
Вы приносите свою generative AI-модель, определяете ожидаемые шаблоны трафика и задаете одну цель производительности: optimize for cost, minimize latency или maximize throughput. Далее SageMaker AI берет процесс на себя в три этапа.
Этап 1: сужение пространства конфигураций
SageMaker AI анализирует архитектуру модели, ее размер и требования к памяти, чтобы определить типы инстансов и стратегии параллелизма, которые реально могут достичь вашей цели. Вместо проверки всех возможных комбинаций он сужает поиск до конфигураций, которые действительно стоит оценивать, среди выбранных вами типов инстансов (до трех).
Этап 2: применение оптимизаций, соответствующих цели
В зависимости от выбранной цели производительности SageMaker AI применяет к каждой кандидатной конфигурации такие техники оптимизации, как:
- Для целей по throughput он обучает модели speculative decoding, например EAGLE 3.0, которые позволяют генерировать несколько токенов за один forward pass, значительно увеличивая число токенов в секунду.
- Для целей по latency он настраивает compute kernels, чтобы сократить время обработки одного токена и уменьшить time to first token.
- Tensor parallelism применяется в зависимости от размера модели и возможностей инстанса, распределяя модель по доступным GPU для работы с моделями, которые не помещаются в память одного GPU.
Вам не нужно знать, какая техника подходит именно для вашей цели. SageMaker AI выбирает и применяет оптимизации автоматически.
Этап 3: бенчмаркинг и выдача ранжированных рекомендаций
SageMaker AI бенчмаркит каждую оптимизированную конфигурацию на реальной GPU-инфраструктуре с использованием NVIDIA AIPerf, измеряя time to first token, inter-token latency, P50/P90/P99 request latency, throughput и cost. В результате вы получаете набор ранжированных, готовых к развертыванию рекомендаций с подтвержденными метриками для каждой конфигурации и каждого типа инстанса. Ниже показано, как выглядит этот workflow с точки зрения пользователя через SageMaker AI APIs.
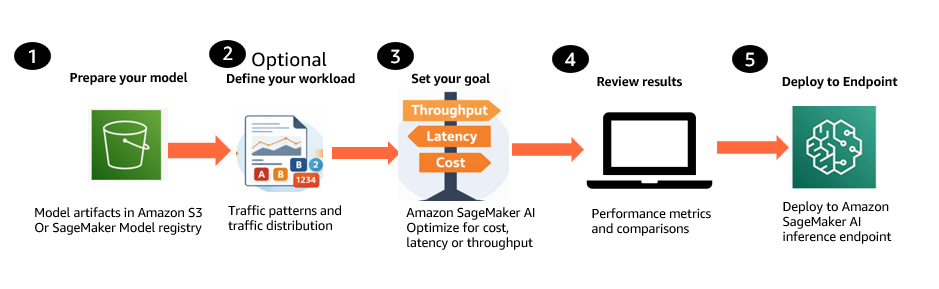
- Подготовьте модель. Загрузите свою generative AI-модель из Amazon Simple Storage Service (Amazon S3) или SageMaker Model Registry, включая форматы checkpoint Hugging Face с весами SafeTensor, базовые модели, а также собственные или дообученные модели, обученные на ваших данных.
- Определите рабочую нагрузку (необязательно). Опишите ожидаемые шаблоны трафика, включая распределения входных и выходных токенов и уровни конкуренции. Эти данные можно передать inline или использовать репрезентативный датасет из Amazon S3.
- Задайте цель оптимизации. Выберите одну цель: optimize for cost, minimize latency или maximize throughput. Выберите до трех типов инстансов для сравнения.
- Просмотрите ранжированные рекомендации. SageMaker AI возвращает готовые к развертыванию конфигурации с подтвержденными метриками, такими как Time to First Token, inter-token latency, P50/P90/P99 request latency, throughput и прогнозы стоимости. Сравните рекомендации и выберите наиболее подходящую.
- Разверните выбранную конфигурацию. Разверните выбранную конфигурацию в SageMaker inference endpoint программно через API.
Дополнительные возможности: вы также можете бенчмаркить существующие production endpoints, чтобы проверить текущую производительность или сравнить ее с новыми конфигурациями. SageMaker AI может использовать существующие machine learning (ML) Reservations (Flexible Training Plans) без дополнительной стоимости вычислений или автоматически выделять on-demand compute.
Ценообразование
За создание оптимизированных рекомендаций для инференса generative AI дополнительная плата не взимается. Клиенты оплачивают стандартные вычислительные расходы за optimization jobs, которые создают оптимизированные конфигурации, и за endpoints, выделяемые во время бенчмаркинга. Клиенты с существующими ML Reservations (Flexible Training Plans) могут запускать бенчмаркинг на зарезервированной мощности без дополнительной платы, то есть единственной стоимостью остается сам optimization job.
Начать работу с оптимизированными рекомендациями для инференса generative AI можно всего за несколько API-вызовов SageMaker AI.
Подробные walkthrough по API, примеры кода и sample notebooks см. в документации SageMaker AI и в sample notebooks на GitHub.
Встроенная строгость бенчмаркинга
Каждая рекомендация SageMaker AI основана на реальных измерениях, а не на оценках или симуляциях. Внутри SageMaker AI бенчмаркит каждую конфигурацию на реальной GPU-инфраструктуре с помощью NVIDIA AIPerf — open-source инструмента бенчмаркинга, который измеряет ключевые inference-метрики, включая time to first token, inter-token latency, throughput и requests per second.
AWS внесла вклад в AIPerf, чтобы укрепить статистическую основу результатов бенчмаркинга. Эти доработки включают отчетность по confidence при нескольких прогонах, что позволяет измерять разброс между повторными тестами и оценивать качество результата с помощью статистически обоснованных confidence intervals. Это выводит вас за рамки хрупких однократных замеров к результатам, которым можно доверять при принятии решений о выборе модели, размере инфраструктуры и регресcиях производительности. AWS также добавила adaptive convergence и early stopping, благодаря чему бенчмарки могут завершаться, как только метрики стабилизируются, а не всегда выполняться фиксированное число попыток. Это снижает стоимость бенчмаркинга и ускоряет получение результата без потери строгости. Для более широкого сообщества инференса это повышает качество методологии бенчмаркинга за счет повторяемости, статистической уверенности и анализа с учетом распределения, а не только заголовочных чисел одного прогона.
Оптимизации в действии
Чтобы понять, как эти оптимизации, привязанные к цели, работают на практике, рассмотрим реальный пример. Клиент, разворачивающий GPT-OSS-20B на одном инстансе ml.p5en.48xlarge (H100), выбирает maximize throughput как цель производительности. SageMaker AI определяет speculative decoding как оптимизацию, подходящую для этой цели, обучает draft model EAGLE 3.0, применяет ее к serving configuration и бенчмаркит как базовую, так и оптимизированную конфигурацию на реальной GPU-инфраструктуре.
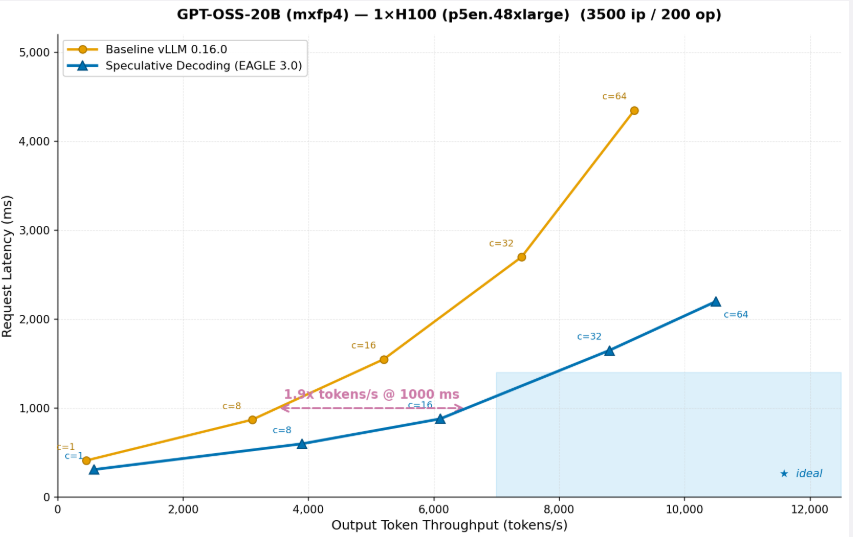
График показывает, что после оптимизации throughput для модели OSS-20B тот же инстанс может обслуживать в 2 раза больше токенов при той же request latency. После оптимизации throughput тот же инстанс обеспечивает 2x больше tokens/s при latency 1 000 мс, а это означает, что вы можете обслуживать вдвое больше пользователей на том же оборудовании, фактически сокращая cost инференса на токен вдвое. Именно такую оптимизацию SageMaker AI применяет автоматически, когда вы выбираете цель по throughput. Вам не нужно знать, что speculative decoding — правильная техника, или как обучать draft model, или как настраивать ее под вашу модель и оборудование. SageMaker AI делает все end to end и возвращает подтвержденные результаты как часть ранжированных рекомендаций.
Польза для клиентов
Эффективность затрат и прозрачность: понятные сравнения цена/производительность между выбранными вами типами инстансов позволяют правильно подобрать размер инфраструктуры вместо того, чтобы автоматически брать самый дорогой вариант. Вместо over-provisioning из-за страха недопроизводительности вы можете выбрать конфигурацию, которая дает нужную производительность по подходящей цене. Экономия накапливается с каждой новой моделью и каждым месяцем работы endpoint.
Быстрее до production: команды быстрее итератируют, тестируют больше конфигураций и раньше доходят до production. Каждый день, сэкономленный на развертывании, — это день, когда ваша инвестиция в generative AI начинает приносить пользу клиентам.
Уверенность в production: каждая рекомендация подкреплена реальными измерениями на реальной GPU-инфраструктуре с использованием NVIDIA AIPerf, а не оценками или симуляциями. Развертывайте решение, зная, что конфигурация была проверена на вашей конкретной модели и рабочей нагрузке с точностью на уровне percentile, соответствующей production-условиям.
Сценарии использования
- Проверка перед развертыванием: оптимизируйте и бенчмаркните новую модель до того, как принять решение о production-развертывании. Знайте, как именно она будет работать, прежде чем инвестировать в масштабирование.
- Проверка регрессий после обновлений: проверяйте производительность после обновления контейнера, апгрейда framework или выпуска новой версии serving library. Убедитесь, что ваша конфигурация по-прежнему оптимальна, прежде чем выкатывать ее в production.
- Правильный размер при изменении условий: когда шаблоны трафика меняются или появляются новые типы инстансов, запускайте оптимизированные рекомендации для инференса generative AI за часы, а не начинайте заново недельный ручной процесс.
- Сравнение моделей: сравнивайте производительность и стоимость разных вариантов модели на разных типах инстансов, чтобы сделать обоснованный выбор до production-развертывания.
- Оптимизация затрат: бенчмаркните существующие production endpoints, чтобы выявить избыточно выделенную инфраструктуру. Используйте результаты для right-sizing и снижения регулярных расходов на инференс.
Бенчмарк inference endpoints
AI benchmark job запускает тесты производительности для ваших SageMaker AI inference endpoints с использованием заранее заданной конфигурации рабочей нагрузки. Используйте benchmark jobs, чтобы измерять производительность вашей инфраструктуры инференса generative AI до и после оптимизации. Когда benchmark job завершен, результаты сохраняются в указанном вами Amazon S3 output location. После завершения benchmark job все результаты записываются в ваш S3 output path в папку output, как показано на скриншоте ниже:
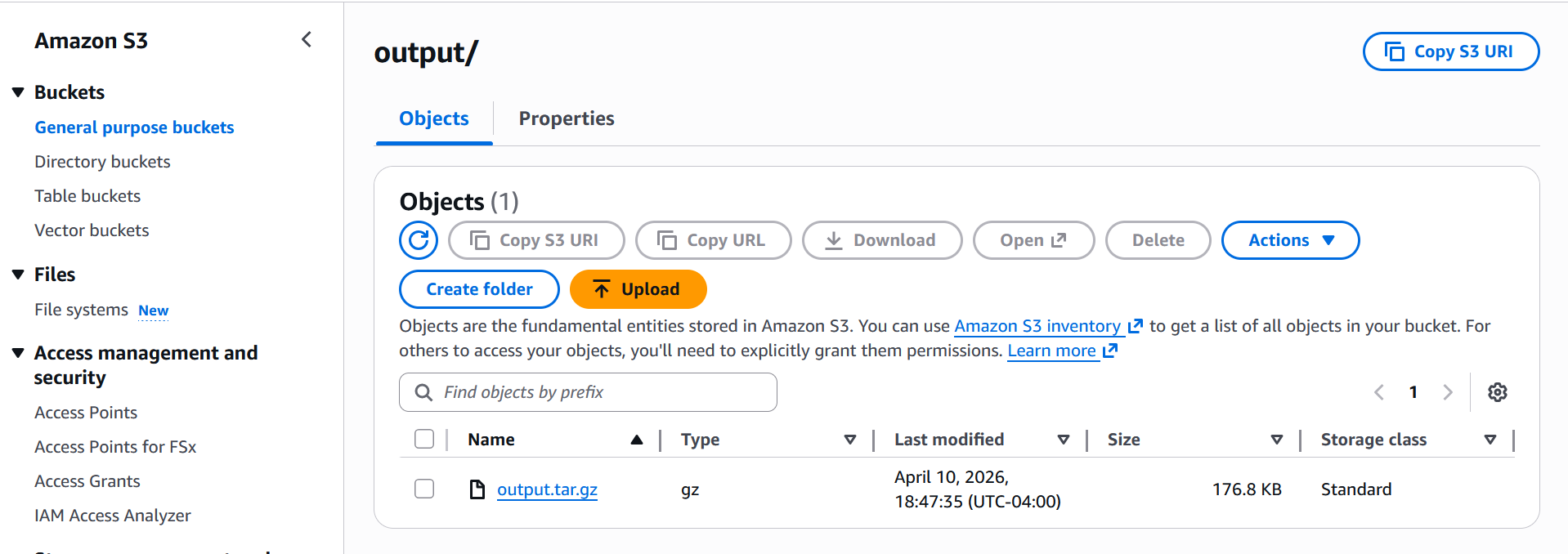
После загрузки и распаковки zip-файла вывода вы получите следующие файлы:
output/
├── profile_export_aiperf.json # агрегированные метрики
├── profile_export_aiperf.csv # те же метрики в CSV
├── profile_export.jsonl # сырые данные по каждому запросу
├── inputs.json # промпты, отправленные во время прогона
├── benchmark_summary.txt # сводка завершения
├── MANIFEST.txt # индекс всех файлов с размерами
├── plot_generation.log # журнал генерации графиков
├── plots/
│ ├── ttft_timeline.png # TTFT по каждому запросу во времени
│ ├── ttft_over_time.png # TTFT, агрегированный по длительности прогона
│ ├── summary.txt # список сгенерированных графиков
│ └── aiperf_plot.log # трассировка генерации графиков
└── logs/
└── aiperf.log # полный журнал выполнения AIPerf
Основной результат — profile_export_aiperf.json, а его CSV-эквивалент profile_export_aiperf.csv — оба содержат одни и те же агрегированные метрики: перцентили задержки (p50, p90, p99), throughput выходных токенов, time-to-first-token (TTFT) и inter-token latency (ITL). Это те числа, которые вы будете использовать для оценки того, как модель показала себя под имитируемой нагрузкой.
Кроме того, profile_export.jsonl дает вам сырые данные по каждому запросу: каждый индивидуальный запрос записан со своей задержкой, количеством токенов и временной меткой. Это полезно, если вы хотите провести собственный анализ или найти выбросы, которые могут скрываться за агрегированными статистиками.
Мы создали sample notebook в Github, в котором бенчмаркится openai/gpt-oss-20b, развернутая на инстансе ml.g6.12xlarge (4× NVIDIA L40S GPUs) и обслуживаемая через контейнер vLLM как Inference Component. Он имитирует реалистичную рабочую нагрузку с помощью синтетических промптов: 300 запросов при 10 одновременных пользователях, примерно по 500 входных и 150 выходных токенов на запрос, чтобы измерить, как модель работает под этой нагрузкой.
Развертывание модели из рекомендаций
После завершения AI Recommendation Job на выходе получается SageMaker Model Package — версионированный ресурс, который объединяет все конфигурации развертывания, специфичные для инстансов, в один артефакт.
Чтобы развернуть модель, сначала преобразуйте Model Package в Deployable Model, вызвав CreateModel с параметрами ModelPackageName и InferenceSpecificationName для нужного вам инстанса, затем создайте endpoint configuration и выполните развертывание как стандартный SageMaker real-time endpoint или Inference Component.
- Выберите рекомендацию, которую хотите развернуть
Формулы и расчет
resp = client.describe_ai_recommendation_job( AIRecommendationJobName="my-recommendation-job" ) rec = resp["Recommendations"][0] model_package_arn = rec["ModelDetails"]["ModelPackageArn"] inference_spec_name = rec["ModelDetails"]["InferenceSpecificationName"] instance_type = rec["InstanceDetails"][0]["InstanceType"] print(f"Model Package : {model_package_arn}") print(f"Inference Spec: {inference_spec_name}") print(f"Instance Type : {instance_type}") - Преобразуйте Model Package → Deployable Model
Формулы и расчет
sm.create_model( ModelName="oss20b-deployable-model", ModelPackageName=model_package_arn, InferenceSpecificationName=inference_spec_name, ExecutionRoleArn="arn:aws:iam::123456789012:role/SageMakerExecutionRole", ) - Создайте endpoint config
Формулы и расчет
sm.create_endpoint_config( EndpointConfigName="oss20b-endpoint-config", ProductionVariants=[ { "VariantName": "AllTraffic", "ModelName": "oss20b-deployable-model", "InstanceType": instance_type, "InitialInstanceCount": 1, } ], ) - Разверните и дождитесь завершения
Формулы и расчет
sm.create_endpoint( EndpointName="oss20b-endpoint", EndpointConfigName="oss20b-endpoint-config", )
В качестве альтернативы, если вы хотите использовать Inference Components вместо single-model endpoint, вы можете обратиться к notebook за подробностями. Такая схема означает, что один Recommendation Job создает один Model Package с несколькими InferenceSpecifications — по одному на каждый оцененный тип инстанса. Поэтому вы можете выбрать конфигурацию, соответствующую вашей цели по latency, throughput или cost, и развернуть ее напрямую без повторного запуска job.
Как начать
Возможность доступна уже сегодня в семи регионах AWS: US East (N. Virginia), US West (Oregon), US East (Ohio), Asia Pacific (Tokyo), Europe (Ireland), Asia Pacific (Singapore) и Europe (Frankfurt). Доступ осуществляется через SageMaker AI APIs.
Вывод
В этом материале мы показали, как оптимизированные рекомендации для инференса generative AI в Amazon SageMaker AI сокращают время развертывания с недель до часов. С этой возможностью вы можете сосредоточиться на создании точных моделей и продуктов, которые важны вашим клиентам, а не на настройке инфраструктуры. Каждая конфигурация проверяется на реальной GPU-инфраструктуре на вашей конкретной модели и рабочей нагрузке, поэтому вы можете развертывать решение уверенно и выполнять right-sizing с ясным пониманием происходящего.
Чтобы узнать больше, посетите документацию SageMaker AI и попробуйте sample notebooks на GitHub.
Материал — перевод статьи с английского.
Оригинал: Amazon SageMaker AI now supports optimized generative AI inference recommendations